This article is based on years of TCP network programming experience of youzan middleware team. The purpose of this article is to avoid various unintended behaviors of applications due to various network anomalies, which can cause unintended effects and affect system stability and reliability.
This document does not cover the basics of TCP, but mainly summarizes some of the problems that may be encountered in TCP network programming practice, as well as the corresponding practice-proven solutions. Although many of the details in this document are mainly for Linux systems, most of the recommendations are suitable for all systems.
A total of 16 recommendations are summarized in this document, and they are described below one by one.
1. server-side listeners set SO_REUSEADDR option
When restarting a server-side application, we may encounter an error message like `address already in use’, which means that the address is already in use and the application cannot be restarted quickly and successfully. The old process is closed and exited, why does it still report address already in use?
Let’s understand the following two points.
- The existence of a
TIME_WAITstate lasting 2MSL on the active closing side of a TCP connection. - TCP connections are determined by the quadruplet
<local address, local port, remote address, remote port>.
Let’s first briefly review the TIME_WAIT state during TCP connection closure, as follows:
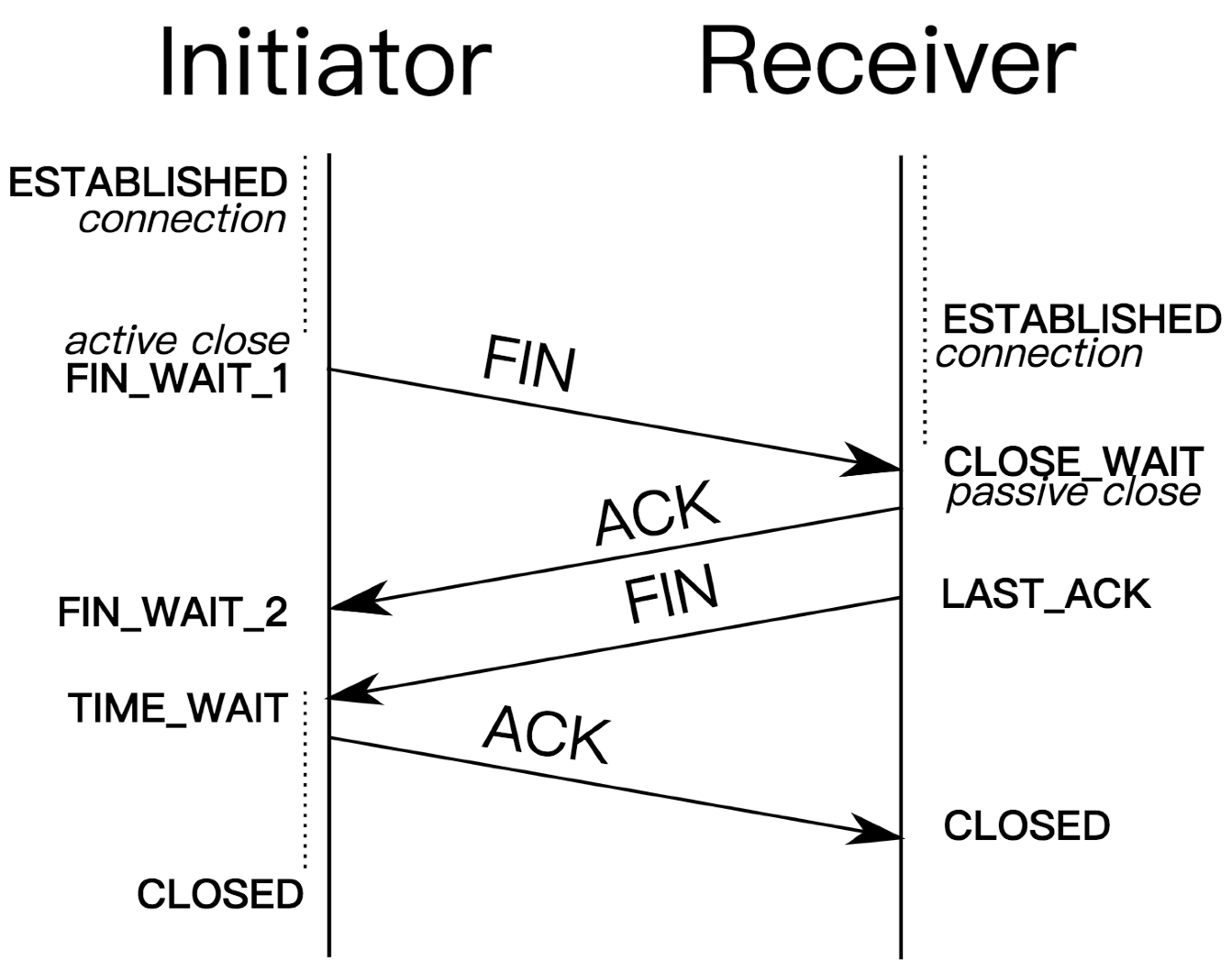
TIME_WAIT exists for two main reasons:
-
Maintains the connection state so that TCP connections can be closed reliably. If the last
ACKsent by the active closing side of the connection is lost, the passive closing side of the connection retransmits the FIN message. If there is no TIME_WAIT and the lastACKis lost, the passive closing end will remain in LAST_ACK for a while and wait for a retransmission; if the active closing end then immediately creates a new TCP connection and happens to use the same quaternion, the connection will fail to be created and will be reset by the other end. -
Wait for all old duplicate, wayward messages of this connection to die out in the network to avoid such messages interfering with new TCP connections of the same quadruplet, whose serial numbers may happen to fall within the reception window of the new connection.
Since the maximum survival time per TCP message is MSL, and a round trip is 2*MSL maximum, TIME_WAIT needs to wait for 2MSL.
When the process shuts down, the process initiates the active closure of the connection and the connection ends up in the TIME_WAIT state. When a new process bind listens to the port, it reports an error because there is a connection corresponding to the local port that is still in the TIME_WAIT state.
In fact, interference is only caused when the new TCP connection and the old TCP connection quaternion are identical and the old maze’s message sequence number falls within the new connection’s receive window. In order to use the TIME_WAIT state of the port, most system implementations now have relevant improvements and extensions.
-
The initial sequence number informed by the new connection SYN is required to be necessarily larger than the sequence number of the old connection in the TIME_WAIT state, which can guarantee to some extent that it will not overlap with the sequence number of messages from the old connection.
-
With the TCP timestamps extension option turned on, the timestamp of the new connection must be larger than the timestamp of the old connection in the TIME_WAIT state, which ensures that the messages of the old connection will not affect the new connection.
Therefore, with the TCP timestamps extension option turned on (net.ipv4.tcp_timestamps = 1), you can safely set the SO_REUSEADDR option to support fast program restarts.
Be careful not to confuse it with the net.ipv4.tcp_tw_reuse system parameter, which only takes effect when the client calls connect to create a connection, and can be used for ports with a TIME_WAIT status of more than 1 second (to prevent the last ACK from being lost); while SO_REUSEADDR takes effect when bind port, and is generally used when the server listens SO_REUSEADDR is effective when the port is binded, and is generally used when the server listens, so it can use the local non-LISTEN state port (another port must also set SO_REUSEADDR), not just the TIME_WAIT state port.
2. establish and comply with the application listening port specification
Each application and each communication protocol should have a fixed and unified listening port, which is convenient to form a consensus within the company, reduce collaboration costs and improve the efficiency of operation and maintenance. For example, for some network ACL control, a standardized and unified port will bring great convenience to operation and maintenance.
The application listening port cannot be within the net.ipv4.ip_local_port_range range, which is used by the operating system to automatically assign local port numbers (no port number is specified when bind or connect), and the default value for Linux systems is [32768, 60999]. Now an application server instance (either VM or K8S Pod, etc.) will locally contain not only the application process itself, but may also include processes such as monitoring collection, sidecar agent, etc. If a port in the range of net.ipv4.ip_local_port_range is selected as the listening port, the corresponding port is likely to have been automatically assigned to TCP connections of other processes before your application process starts, which will cause the listening port binding to fail, thus causing the process to fail to start; of course, if the port that has been assigned is set to SO_ REUSEADDR will not cause your application to fail to bind to the listening port, but these temporary ports are generally not set to SO_REUSEADDR. If you do have a need to listen to ports in the net.ipv4.ip_local_port_range range (such as the default ports of the reserved three-party system), you can set the net.ipv4.ip_local_reserved_ports system parameter to reserve them, and the reserved ports will not be automatically assigned out; however, this will make it more difficult for the operation and maintenance However, this will make the delivery of the system more difficult for operation and maintenance, so it is generally not recommended to do so.
The system value of net.ipv4.ip_local_port_range of Yuzhan is set to [9000, 65535], and the listening ports of all types of applications and communication protocols are standardized, and the listening ports are all less than 9000.
3. Separation of application service port and management port
The service port is the business request processing port, and the management port is the management request processing port for the framework or application (such as service registration online and offline). Take Spring Boot as an example, the application port corresponds to server.port and the management port corresponds to management.port.
The separation of the application’s service port from the management port has the following implications:
-
Avoid business requests and management requests to affect each other, such as thread pooling.
-
Better permission management, ACL control, etc. The management port can generally control the core behavior of the application and requires strict permission management, ACL control, such as allowing only specific IPs to access the management port through the firewall, etc.
Youzan online once encountered a problem: a Dubbo business application provides HTTP service and Dubbo service, the HTTP service port and HTTP management port are the same, one instance of the application deadlocked due to internal logic problems, causing the request blocking timeout, but at this time the service registered health preservation thread is still normal, so the exception service instance is still The client is still sending requests to this instance. At this point, you want to take the instance offline for service registration but keep the process in order to troubleshoot the problem, but all threads in the HTTP thread pool block due to business thread blocking, which in turn causes the management module threads to handle HTTP service registration offline requests and eventually cannot be taken offline normally. Youzan Dubbo framework has separated the application service port from the management port and thread pool isolation to avoid similar problems again. Of course, other mechanisms such as fusion also help to deal with individual instance exceptions, and here we focus on the port separation issue.
4. set timeout for establishing connection
Network congestion, IP unreachability, and when the handshake queue is full may lead to connection establishment blocking and timeout. To avoid unpredictable blocking time on the application, it is recommended to set the timeout time when establishing the connection for timeout control. If no active setting is made, the timeout time is controlled by the default behavior of the system, which is certainly not sufficient for all application scenarios. (Note: When the handshake queue is full, the connection will be reset immediately if the system parameter net.ipv4tcp_abort_on_overflow is set)
Let’s see how the system controls the connection establishment timeout by default?
The first SYN message of TCP three handshakes does not receive ACK, the system will automatically retry the SYN message, the maximum number of retries is controlled by the system parameter net.ipv4.tcp_syn_retries, the default value is 6. The initial RTO is 1s, if SYN ACK is never received, wait for 1s, 2s, 4s, 8s in order. 2s, 4s, 8s, 16s, 32s to initiate retransmission, and the last retransmission waits for 64s before giving up and finally returning ETIMEOUT timeout error after 127s.
It is recommended to adjust the net.ipv4.tcp_syn_retries system parameter for underwriting according to the business scenario of the whole company. There are compliments to set this parameter to 3, i.e., a timeout error can be returned around 15s maximum.
5. Health check of connections using application layer heartbeat
When there is an exception in the TCP connection, we need to sense it as soon as possible and then handle and recover from the exception accordingly. For connection shutdown and reset scenarios like FIN or RST, the application layer is able to sense it quickly. However, for false connections caused by power down of the peer machine, disconnected network cable, abnormal network equipment, etc., the application layer will not sense it for a long time if there are no special measures.
When it comes to network anomaly detection, the first thing that comes to mind is probably TCP Keepalive. The three parameters related to system TCP Keepalive are net.ipv4.tcp_keepalive_time, net.ipv4.tcp_keepalive_intvl, and net.ipv4.tcp_keepalive_probes, with default values of 7200s, 75s, and 9 respectively. 75s, 9, i.e. if no data is received from the other side for 7200s, it will start sending TCP Keepalive messages, and if no response is received within 75s, it will continue to retry until it returns the application layer error message after all 9 retries fail.
Why do we need to implement the application layer heartbeat check? Does the system’s TCP Keepalive not meet the requirement? Yes, the system’s TCP Keepalive can only be used as a basic defense solution, but it cannot meet the needs of high stability and high reliability scenarios. There are several reasons for this:
TCP Keepaliveis an extended option, which may not be supported by all devices.TCP Keepalivemessages may be deliberately filtered or blocked by devices, such as carrier equipment.TCP Keepaliveis unable to detect application layer state, such as process blocking, deadlock, TCP buffer full, etc..TCP Keepaliveis prone to conflict with TCP retransmission control, which can lead to failure.
For the issue of TCP state not reflecting application layer state, here are a few scenarios that are slightly described. The first one is that the successful establishment of a TCP connection does not mean that the application at the other end senses the connection, because the three TCP handshakes are done in the kernel, and although the connection has been established, the other end may not have Accepted at all; therefore, some scenarios are inaccurate to judge the health of the application at the other end only by whether the TCP connection can be established successfully, and this scenario can only detect whether the process is alive. Another is that the local TCP write operation is successful, but the data may still be in the local write buffer, in the network link device, or in the read buffer at the other end, which does not mean that the data is read by the application at the other end.
The focus here is to explain the conflict between TCP KeepAlive and TCP retransmission. Linux systems control the number of TCP timeout retransmissions through the net.ipv4.tcp_retries2 parameter, which affects the TCP timeout time. The initial RTO is TCP_RTO_MIN (200ms), the RTO makes an exponential concession, the maximum RTO is TCP_RTO_MAX (2min), and net.ipv4.tcp_retries2 defaults to 15, roughly 924.6s timeout. The detailed retransmission count, RTO, and timeout time relationship are shown in the following table:
| Number of retransmissions | RTO(Milliseconds) | Total Timeout Time |
|---|---|---|
| 1 | 200 | 0.2 s |
| 2 | 400 | 0.6 s |
| 3 | 800 | 1.4 s |
| 4 | 1600 | 3.0 s |
| 5 | 3200 | 6.2 s |
| 6 | 6400 | 12.6 s |
| 7 | 12800 | 25.4 s |
| 8 | 25600 | 51.0 s |
| 9 | 51200 | 102.2 s |
| 10 | 102400 | 204.6 s |
| 11 | 120000 | 324.6 s |
| 12 | 120000 | 444.6 s |
| 13 | 120000 | 564.6 s |
| 14 | 120000 | 684.6 s |
| 15 | 120000 | 804.6 s |
| 16 | 120000 | 924.6 s |
If there is data in the TCP send buffer that was not sent successfully, TCP will perform a timeout retransmission without triggering TCP Keepalive. In other words, even if the application sets very small TCP Keepalive parameters, such as time=10s, interval=10s, and probes=3, under the net.ipv4.tcp_retries2 default configuration, it may still wait until about 15min to sense the network exception. Some people may not understand why Keepalive is interfered by retransmissions, but it is actually a matter of priority here. the role of TCP maximum retransmission count is higher than the role of Keepalive parameter, and network error messages will not be reported to the application layer if the maximum retransmission count is not reached. If Keepalive is not affected by retransmissions, it will also interfere with those who are concerned about retransmissions, such as why the retransmission is abandoned and the connection is closed before the maximum retransmission count is reached. We can check the timer information of the current connection with the netstat -ot or ss -ot commands.
It is recommended to turn down the net.ipv4.tcp_retries2 parameter according to the actual situation. RFC 1122 recommends that the corresponding timeout be no less than 100s, i.e. at least 8, and the parameter defaults to 10 on some Zan systems.
Therefore, to achieve a network robust application, application layer heartbeat is essential. For HTTP2, gRPC, Dubbo and other protocols support heartbeat, if the application is developed based on these protocols, you can directly use the features of these protocols to implement the application layer heartbeat.
Implementing an application layer heartbeat requires consideration of the following points:
- The heartbeat interval cannot be too small or too large. Too small an interval may be too sensitive to slight jitter and cause over-reaction, which in turn will affect stability and also have some performance overhead; too large an interval will result in higher latency for anomaly detection. The heartbeat can be sent strictly at regular intervals, or the heartbeat can be initiated only when no data is received from the other side for a period of time. The recommended heartbeat interval is 5s~20s.
- Set the continuous failure threshold to avoid instantaneous jitter that causes misclassification, etc. The recommended continuous failure threshold is 2~5.
- Do not use standalone TCP connections for heartbeat checking, because the network paths, TCP buffers, etc. are different for different connections and do not truly reflect the true state of the business communication connection.
6. connection reconnection needs to increase the setback and window jitter
When the network exception is recovered, a large number of clients may initiate TCP reconnection and make application layer requests at the same time, which may cause problems such as server-side overload and network bandwidth exhaustion, resulting in client connection and request processing failure, and then the client triggers a new retry. Without the backoff and window jitter mechanism, the situation may continue and it is difficult to converge quickly.
It is recommended to increase the exponential yield, such as 1s, 2s, 4s, 8s… At the same time, the maximum concession time must be limited (e.g., 64s), otherwise the retry waiting time may become larger and larger, which also leads to rapid convergence. At the same time, in order to reduce a large number of clients to build a connection and request at the same time, it is also necessary to increase the window jitter, the window size can be consistent with the concession wait time, such as: nextRetryWaitTime = backOffWaitTime + rand(0.0, 1.0) * backOffWaitTime.
When performing network exception tests or walkthroughs, the network exception time variable needs to be taken into account, as the impact on the application may be completely different for different durations.
7. The server side needs to limit the maximum number of connections
What is the theoretical maximum number of TCP connections a service port can receive? The server-side IPs and server-side ports in the TCP quadruplet are already fixed, and the theoretical upper limit is the number of available client-side IPs * the number of available client-side ports. Removing some IP classification, port reservation and other details, the theoretical upper limit is 2^32 * 2 ^16 = 2^48.
Of course, the bottleneck of the theoretical upper limit is certainly not reached in reality at the moment. The main resources associated with a TCP socket are memory buffers, file descriptors, etc. Therefore, the actual limit depends mainly on the system memory size and the number of file descriptors limit.
The server side limits the maximum number of connections for two main purposes.
- Avoiding service overload leading to CPU and memory exhaustion.
- Avoid file descriptor exhaustion.
Each socket of TCP connection occupies one FD, and there is a limit to the number of FDs per process and system-wide. The maximum number of FD’s opened by all processes can be viewed by cat /proc/sys/fs/file-max, and if it does not meet the needs of the application, then it needs to be adjusted accordingly.
What are the effects of reaching the FD limit? First of all, it must be impossible to receive new TCP connections; secondly, besides the FD occupied by TCP connections, your application must have internal scenarios that occupy or need to allocate new FD, such as when log file rotation occurs to create a new log file, if the log file creation fails, for applications that rely on local storage (such as KV, MQ and other storage-based applications), it leads to service unavailability. Therefore, it is necessary to reserve a certain number of FD based on the system limit and according to the characteristics of the application, instead of giving all the FD to the client TCP connection to use.
A similar problem was encountered by an application during the online pressure test. During the pressure test, the pressure was relatively high, resulting in higher disk IO pressure and higher request processing delay, causing the client to time out. The client found that the timeout closed the connection and created a new connection to retry, but at this time, the server was not able to recover the socket and FD of the closed connection (CLOSE_WAIT) in time due to the delay caused by IO blocking, resulting in more and more FD consumption, which eventually led to FD exhaustion and the failure of creating new log files, and the application was a storage type application, which strongly depended on the log drop disk, eventually The service becomes unavailable.
In addition to limiting the maximum number of connections on the server side, if the application has a corresponding client SDK, it is best to also do a layer of protection on the client SDK as well.
8. Try not to rely on centralized four-tier load balancers
LVS is a classic centralized four-tier load balancing solution, and there are also various cloud vendors that offer LVS-like products with mostly the same principles. Their advantages we will not talk about here. Using this type of solution may face the following problems.
- The need to change the configuration of the back-end instance list for each application scaling capacity, with high operation and maintenance costs and risks.
- Centralized components are less scalable and easily reach bottlenecks, such as network bandwidth bottlenecks.
- Poor availability of centralized components, with the entire service affected if something goes wrong with the load balancer.
- Four-tier health checks insensitive to back-end instance anomalies and unable to perform application-level health checks.
- The splitting and migration of the load balancer has a greater impact on the application, requiring the application to cooperate with updated configurations, releases, etc., which is more expensive to use.
- A load balancer can potentially drop idle connections that have not communicated for a period of time, causing unintended impacts to the application.
- Client access to the server needs to be relayed through a load balancer, which may have some impact on RT.
It is recommended to replace centralized load balancing solutions with distributed dynamic service registration and discovery and client-side load balancing, such as service registration, service discovery, and load balancing solutions in microservice architecture.
In scenarios where centralized load balancers have to be used, the following issues also need to be noted:
-
Pay attention to choosing the appropriate load balancing algorithm to avoid unbalanced distribution of long connections. For example, if a polling load balancing algorithm is selected, the number of connections to each backend instance is balanced under normal circumstances, but when an instance is restarted, the client will initiate a reconnection after the connection to that instance is disconnected, and the reconnection will be transferred to other instances with a high probability, resulting in fewer connections to the recently started instance and more connections to the earliest started instance. You can consider load balancing the minimum number of connections, increasing the TTL limit for long connections, etc.
-
Note the idle timeout, the load balancer may not send the Close or Reset signal to both ends after the timeout, resulting in a fake connection that cannot communicate. If there is no heartbeat, idle timeout, etc. on both sides of the client and server, the fake connection will always exist and take up system resources; the health check cycle of the application layer or TCP layer needs to be smaller than the idle timeout of the load balancer.
-
Be careful to ensure smoothness when removing the back-end instance. If you remove the back-end instance directly, you may not send Close or Reset signals to both ends, resulting in a false connection that cannot be communicated and is not perceived by the client and server in time. Generally, first adjust the instance weight to 0 to ensure that new connections are no longer assigned to the instance, then wait for existing connections to be released, and finally remove the backend instance completely.
The youzan online environment has encountered problems related to LVS several times, and is also developing a distributed four-tier agent.
9. Be wary of large numbers of CLOSE_WAIT
First of all, I would like to introduce a problem that I once encountered. Online environment alerts suggest a server with a high TCP retransmission, and the retransmission packets are FIN packets after packet capture analysis, and the target IP no longer exists. Check the connection status to find a large number of CLOSE_WAIT status connections. The problem does not persist all the time, but is sporadic. After analyzing the application logs and application code, it was found that the local socket was not closed when a scenario application read EOF. further analysis, the reason is that the client application is deployed by K8S, after release, the old instance is offline, as the client initiates the active closure of the connection, and the IP of the old instance will be recycled soon; the socket that is not closed on the server side will be closed only after a few minutes when GC (Go language application) before the socket recycling closure operation is performed, but at this time, the client IP no longer exists, so the last FIN message is continuously retransmitted until the maximum number of retransmissions is exceeded, thus the problem recovers. When a client application is released again, it will appear again. The problem may have more serious consequences for applications developed in programming languages without a GC mechanism, where the sockets keep leaking, leading to problems such as FD exhaustion and memory depletion.
Therefore, be sure to be alert to the appearance of a large number of CLOSE_WAIT state connections, and when this situation occurs, first exclude some related code. At the same time, during the development process, you must pay attention to close the socket correctly, by some language features for underwriting, such as Go’s defer, Java’s try… .catch… …finally, the RAII mechanism of C++, etc.
10. Reasonable setting of long connection TTL
Long connections reduce the overhead of frequent connection establishment like short connections, including three handshake overhead, slow start overhead, etc. However, there are certain drawbacks: the long connection duration is too long, which may lead to some load balancing problems and other problems that are difficult to converge over a long period of time. For example, in the LVS scenario, as the back-end application instance restarts, for some load balancing algorithms (e.g., polling), it will result in the least number of connections for the latest-started instance and the most number of connections for the earliest-started instance. For some client-side load balancing solutions, a similar problem occurs with long connections when only one node in the back-end cluster needs to be connected, such as a scenario similar to Etcd watch. There are a lot of scenarios using Etcd internally in Youzan, and the early operation and maintenance were particularly cautious every time they changed the Etcd cluster to avoid the unbalanced connections.
The middleware team of Youzan stipulates that the TTL of TCP long connection for any application cannot exceed 2 hours. Of course, this is already a very conservative length, and it is recommended to set the TTL reasonably according to the application scenario.
11. Access to the service via domain name requires regular DNS resolution
DNS is a service discovery mechanism, and applications access other services by configuring DNS, which is intended to address the impact of IP changes of other service instances, but it can still be problematic if not handled properly. When accessing other services through the domain name, you need to update the domain name resolution regularly and re-establish the connection if there is an update in the resolution to avoid the difficulty of convergence when the back-end instance is migrated (IP has changed). Never perform domain name resolution only once when the application is launched. In this case, if you want to achieve fast convergence after a DNS change, you have to restart or release all related applications. Some languages have built-in DNS-related implementations, and you need to pay attention to some of the corresponding parameters and whether the behavior is as expected.
In addition, some applications provide interfaces to get the latest list of cluster members, such as Etcd and Redis, so that even if the client starts up with only one domain name resolution, it can support dynamic changes in the server-side cluster members as long as the list of service cluster members is regularly synchronized from the server side.
12. Reduce the number of network read/write system calls
When we call read/write system functions to read/write data from sockets, each call makes at least two context switches between user and kernel states, which is relatively costly. For this problem, there are two general optimization ideas.
- Use read/write buffers; when reading data, first read from the socket into the buffer at once, then read from the buffer in stages as needed; when writing data, first write to the buffer in stages, and then write to the socket at once when the buffer is full or when all write operations are completed.
- When it is not convenient to merge data into contiguous memory, use readv/writev to read/write multiple segments of memory data at once.
Another advantage for bulk write operations is that you can avoid the delay caused by the Nagle algorithm (which is also generally not recommended to be turned on). If there is no data in the current write buffer, we first write 4 bytes via write, at which point the TCP stack sends it out, and then write 96 bytes via write, at which point, since a message has been sent before, no ACK has been received, and the current sendable data has not reached the MSS, the Nagle algorithm does not allow further messages to be sent and must wait until the previous message’s It must wait until the ACK of the previous message comes back before continuing to send data, which greatly reduces the throughput and increases the latency. If delayed ACK is turned on at the receiver side, the impact is even greater.
Therefore, you should try to read and write network data in bulk to improve performance.
13. Set the TCP buffer size carefully
Generally speaking we do not need to change the TCP default buffer size, but if we do need to set it, we need to consider and evaluate it carefully.
What is the appropriate TCP buffer size? As we know, the transmission speed of TCP is limited by the size of the sending and receiving windows, and the network capacity. The two windows are determined by the buffer size, and if the buffer size matches the network capacity, then the buffer utilization is the highest.
Bandwidth-delay Product (BDP) is used to describe the network transmission capacity. If the maximum bandwidth is 100MB/s and the network delay is 10ms, the network between the client and the server can store a total of 100MB/s * 0.01s = 1MB bytes, and this 1MB is the product of bandwidth and delay, which is the bandwidth-delay product. These 1MB bytes exist for in-flight TCP messages, which are on network devices such as network lines and routers. If the in-flight message exceeds 1MB, it will definitely overload the network and eventually lead to packet loss.
Since the sending buffer determines the upper limit of the sending window, which in turn determines the upper limit of sent but unacknowledged in-flight messages, the sending buffer cannot exceed the bandwidth delay product because there is no way to use the excess for efficient network transmission, and flying bytes larger than the bandwidth delay product will also lead to packet loss, thus triggering network congestion avoidance; moreover, the buffer cannot be smaller than the bandwidth delay product, otherwise it will not be able to bring out the value of high-speed networks.
To summarize: a buffer that is too small will reduce TCP throughput, prevent efficient use of network bandwidth, and lead to higher communication latency; a buffer that is too large will lead to high memory usage of TCP connections and bottlenecks limited by the bandwidth delay product, resulting in memory waste. If the buffer is too small, e.g. 2K, it may also result in fast retransmissions not taking effect, as there may be at most 2 unacknowledged messages and no 3 duplicate ACKs.
Linux system is able to adjust the buffer size automatically according to the system state, and the related parameters are controlled by net.ipv4.tcp_wmem and net.ipv4.tcp_rmem, and the parameters are a 3-tuple, i.e. maximum, initial default, and maximum. However, if you set SOSNDBUF or SORCVBUF directly on the socket, this will turn off the system dynamic adjustment of the buffer, and it is important to perform a full evaluation before doing so.
Therefore, do not set the TCP buffer size easily unless you are very clear about your needs, and unless you have performed sufficient evaluation and verification.
14. network-related parameters support flexible configuration
When the application may have multiple deployment environments and scenarios, it is necessary to adjust the appropriate network-related parameters according to the usage scenarios and network environment, etc. The network conditions of LAN and WAN are very different, which will involve the adjustment of many parameters.
For example, for youzan’s service agent component Tether, there are both sidecar deployment scenarios in the data center and cross-public network gateway deployment scenarios, so it is necessary to adjust the corresponding parameters as needed, otherwise it is difficult to adapt to different network environments. For example, connection timeout, read/write timeout, health check timeout, health check failure threshold, etc. should all support flexible configuration.
15. Reasonable setting of connection pool size
Connection pools are designed differently for different types of protocols. We classify whether a protocol supports connection multiplexing into two categories: non-multiplexing protocols and multiplexing protocols. Non-multiplexing protocols, where a connection sends a request and must wait for the response to return before the connection can send a new request, such as HTTP1.1, Redis, etc.; multiplexing protocols, where the same connection supports sending multiple requests at the same time, such as HTTP2, gRPC, Dubbo, etc.
Let’s first look at how to set the connection pool size for non-multiplexing protocols. The parameters involved in connection pooling are generally: minimum number of connections, maximum number of connections, maximum idle time, connection acquisition timeout, connection acquisition timeout retry count, etc. The main interaction logic between the application and the connection pool is shown below.
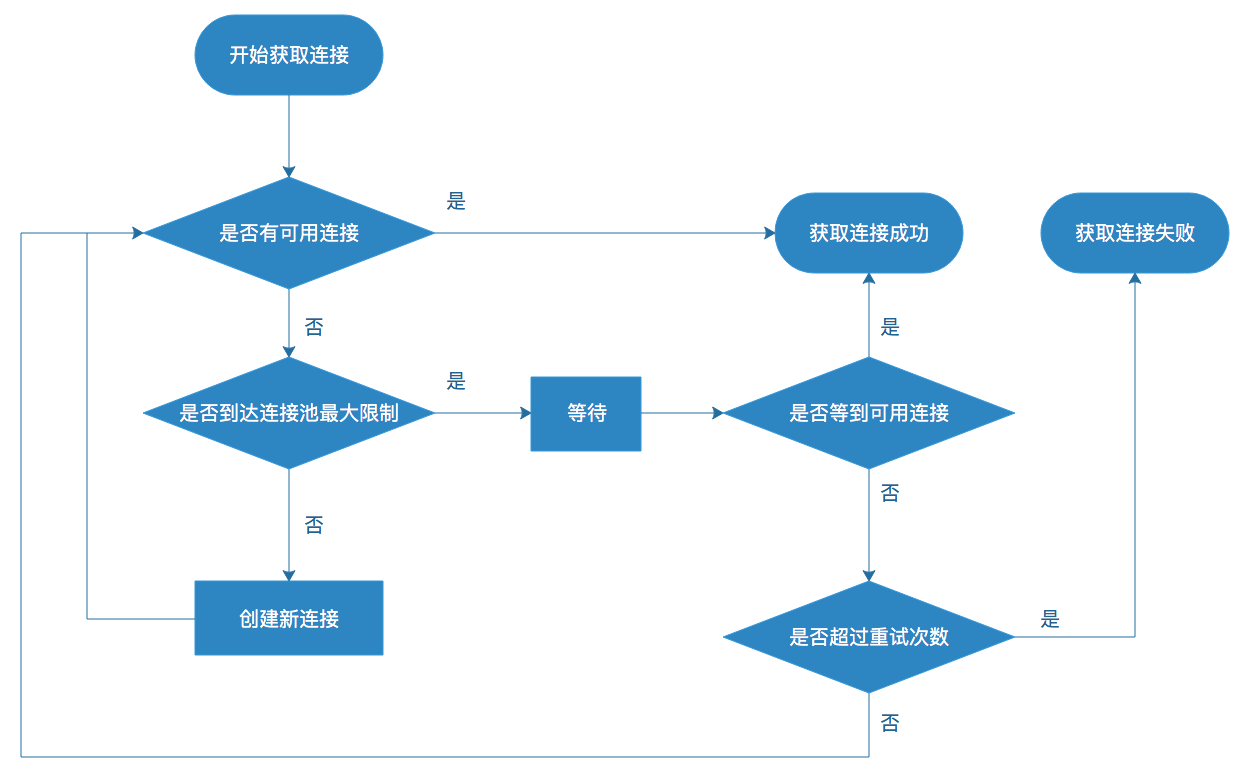
We mainly discuss the minimum number of connections and the maximum number of connections. The reason why the number of connections is not fixed is that there are peaks and valleys in traffic; if the number of fixed connections is too small, the waiting time for requests will be too long during peak traffic periods; if the number of fixed connections is too large, resources will be wasted during low traffic periods. Therefore, the minimum number of connections corresponds to how many connections are appropriate during the low traffic period, and the maximum number of connections corresponds to how many connections are appropriate during the peak traffic period, i.e., the number of connections is related to the traffic size. In addition to the traffic size, it is also necessary to consider the request RT, i.e., the time each request takes to connect. The number of connections required is actually the number of concurrent requests, and here we can use the famous Little’s law (Little’s law) to calculate, L = λW, in this scenario that: concurrency = request QPS * request RT. for example, the low traffic period request QPS is 100, request RT is 0.05s, the number of concurrency is 5, the number of required connections is 5; peak traffic period This type of problem is actually related to queuing theory, but we will not discuss it too much here, if you have more complex requirement scenarios, you can refer to more queuing theory related materials.
Next we move on to look at how the multiplexing protocol sets the connection pool size. The parameters involved in connection pooling are generally: minimum number of connections, maximum number of connections, high water mark for single connection concurrent requests, and low water mark for single connection concurrent requests. When the number of concurrent requests for a single connection is higher than the high water level, if the connection pool does not reach the maximum number of connections, the connection pool is expanded and connections are created; when the number of concurrent requests for a single connection is lower than the low water level, if the connection pool does not reach the minimum number of connections, the connection pool is shrunk and connections are released (the release process needs to be smooth). Since each request is not exclusive to a connection, the request can choose any connection, so here we also face the problem of load balancing and need to ensure that the number of requests being processed on each connection is as close to the average as possible. Generally minimum request load balancing is used, but the time complexity of minimum request load balancing can be high and the simplest implementation requires scanning the entire connection pool. We can use its approximate optimization implementation by selecting two connections at random and choosing the connection with the lowest number of Pending requests; to more closely approximate least requests, we can select 3, 5, or even more connections and take the connection with the lowest number of Pending requests.
16. Improve network metrics monitoring
Monitoring and alerting is required for various key network metrics, including but not limited to:
- Number of TCP connection establishment failures
- TCP message retransmission rate
- Number of TCP connections in each state (especially
ESTABLISHED,TIME_WAIT,CLOSE_WAIT) - Number of TCP active connection closures
- Number of TCP passive closed connections
- Number of connection health check failures
- System and process FD usage
- Connection pool size
If abnormalities in these indicators can be detected early, then problems can be identified as soon as possible, thus reducing the impact of the problem.
Summary
This article summarizes 16 recommendations based on your practical experience in TCP network programming, hoping to help you improve the robustness and reliability of your applications and reduce online problems and failures in TCP network programming.
Reference https://tech.youzan.com/you-zan-tcpwang-luo-bian-cheng-zui-jia-shi-jian/