The MySQL master-slave architecture has been widely used, and the stability of the master-slave replication relationship is a constant concern.
MySQL 5.6 provides a new feature for master-slave replication stability: slave support crash-safe. This feature can solve the problem of relay_log.info bit inaccuracy caused by abnormal power failure in previous versions.
In this article, we will introduce this feature in terms of principle, parameters, and new issues.
Translated with www.DeepL.com/Translator (free version)
1. crash-safe
Before understanding slave crash-safe, let’s analyze the reason why slave crash-unsafe occurs in versions before MySQL 5.6. We know that in a master-slave architecture, slave contains two threads: IO thread and SQL thread. The execution progress (offsets) of both threads are stored in a file.
The IO thread is responsible for pulling
binlogfiles frommasterand saving them to the localrelay-logfile.The SQL thread is responsible for executing duplicate sql and executing the logs recorded by
relay-log.
The working mode of SQL_thread in case of crash-unsafe:
The execution status information of IO thread is stored in master.info file, and the execution status information of SQL thread is stored in relay-log.info file. However, whenever the system crashes, the stored offsets may be inaccurate (note that these files are not written to disk synchronously after being modified). Because applying binlog and updating loci to file are not atomic operations, but two separate steps. For example, SQL thread has applied relay-log.01 with 4 transactions
But the SQL thread updates the bit (relay-log.01,30) to the relay-log.info file, and when the slave instance restarts the sql thread will repeat the transaction trx4, so you will see the more common replication error 1062, error 1032, and error 1033. error 1032.
MySQL 5.5 mitigates this problem with two parameters, sync_master_info=1 and sync_replay_log_info=1 to ensure that the two threads of the Slave synchronize the IO thread and the SQL thread’s current execution loci to the two files once for each write transaction. information of the current execution bit. Of course, the sync operation is not free, and frequent updates to the disk files consume performance.
However, even if sync_master_info=1 and sync_relay_info=1 are set, the problem still occurs because replication information is written after transactions are committed, and if crash occurs between the transaction commit and the OS write file, then relay- log.info may be wrong. When the slave is restarted, the last transaction may be executed twice. The exact impact depends on the specific operation of the transaction. Replication may continue to run like update/delete, or report errors like insert operations, and the consistency of master-slave data may be broken.
2. crash-safe features
2.1. Ensure atomicity of apply log and update loci information operations
From the above analysis, we know that the reason for the slave crash-unsafe is the non-atomicity of the application binlog and update file. MySQL 5.6 guarantees the atomicity of apply binlog transactions and update relay info to slave_relay_log_info.
This means that the SQL thread executes the transaction and updates the mysql.slave_replay_log_info statement into one transaction, and the MySQL system guarantees the atomicity of the transaction. We can simulate the principle of crash-safe by using pseudo-code: the working mode of SQL_thread in the case of crash-safe
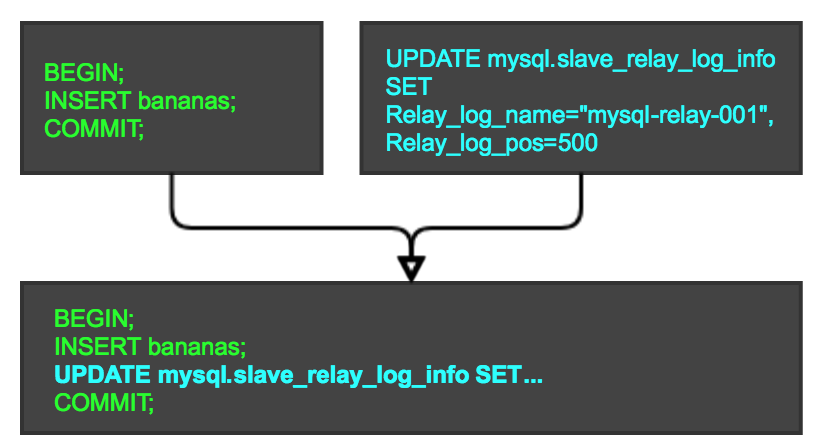
The green one represents the actual business transaction, and the blue one is the sql to update the slave_replay_log_info related bit information executed by MySQL, and then merge the two sql in one transaction, using MySQL transaction mechanism and InnoDB table to guarantee atomicity. There is no problem of inconsistency caused by splitting the actions of applying binlog and updating bit information.
2.2. Recovery action after crash
By setting relay_log_recovery = ON, when the slave encounters an abnormal crash and then restarts, the system will delete the existing relay log, and then the IO thread will pull the binlog of the master from the loci recorded by mysql.slave_replay_log_info again. The starting point of MySQL’s design is:
- The SQL thread apply binlog bits are always less than or equal to the bits pulled from the master by the IO thread.
- The bits logged by SQL thread are the bits of information after the transaction has been executed and committed.
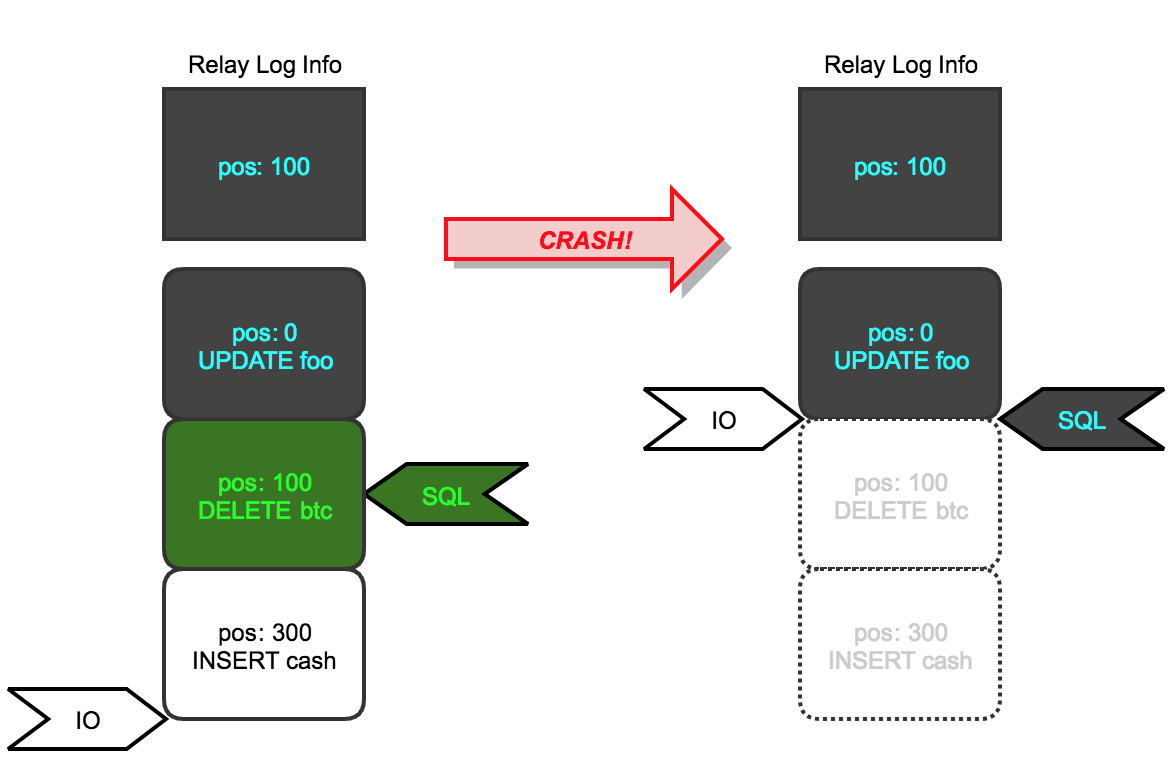
The blue update statement represents a transaction that has been executed and committed, while the green delete statement represents a sql that is being executed and has not been committed. At this time, the relay log info recorded in the slave_replay_log_info table is the bit before the end of the update statement and the beginning of the delete statement (relay_log.01,100). If a system crash occurs, the slave instance will delete the existing relaylog after restarting, and the IO thread will pull the master binlog from (relay_log.01,100), and the SQL thread will also start applying binlog from this binlog. The SQL thread will also start applying the binlog from this binlog.
2.3. crash safe in GTID mode
Unlike loci-based replication, GTID mode uses the new replication protocol COM_BINLOG_DUMP_GTID for replication. As an example
When instance a has a transaction set set_a, and instance b has a transaction set set_b, and set b as a slave of a, the binlog protocol pseudo-algorithm is as follows:
- Instance b points to the master instance a, which establishes a master-slave relationship based on the master-backup protocol
- Instance b sends the GTID information to instance a
UNION(@@global.gtid_executed, Retrieved_gtid_set - last_received_GTID)
- Instance a computes the difference between set_b and set_a, that is, the set of GTIDs that exist in set_a but do not exist with set_b, and determines whether the local binlog of instance a contains all the binlog transactions required by the difference set.
- a If not, it means that instance a has deleted the binlog that instance b needs, and returns an error directly.
- b If all are confirmed to be included, instance a finds the first transaction not in set_b from the local binlog file and sends it to instance b.
- Starting from this transaction, read the file backwards and fetch the binlog in order to send it to instance b.
GTID mode, slave crash-safe operation mechanism
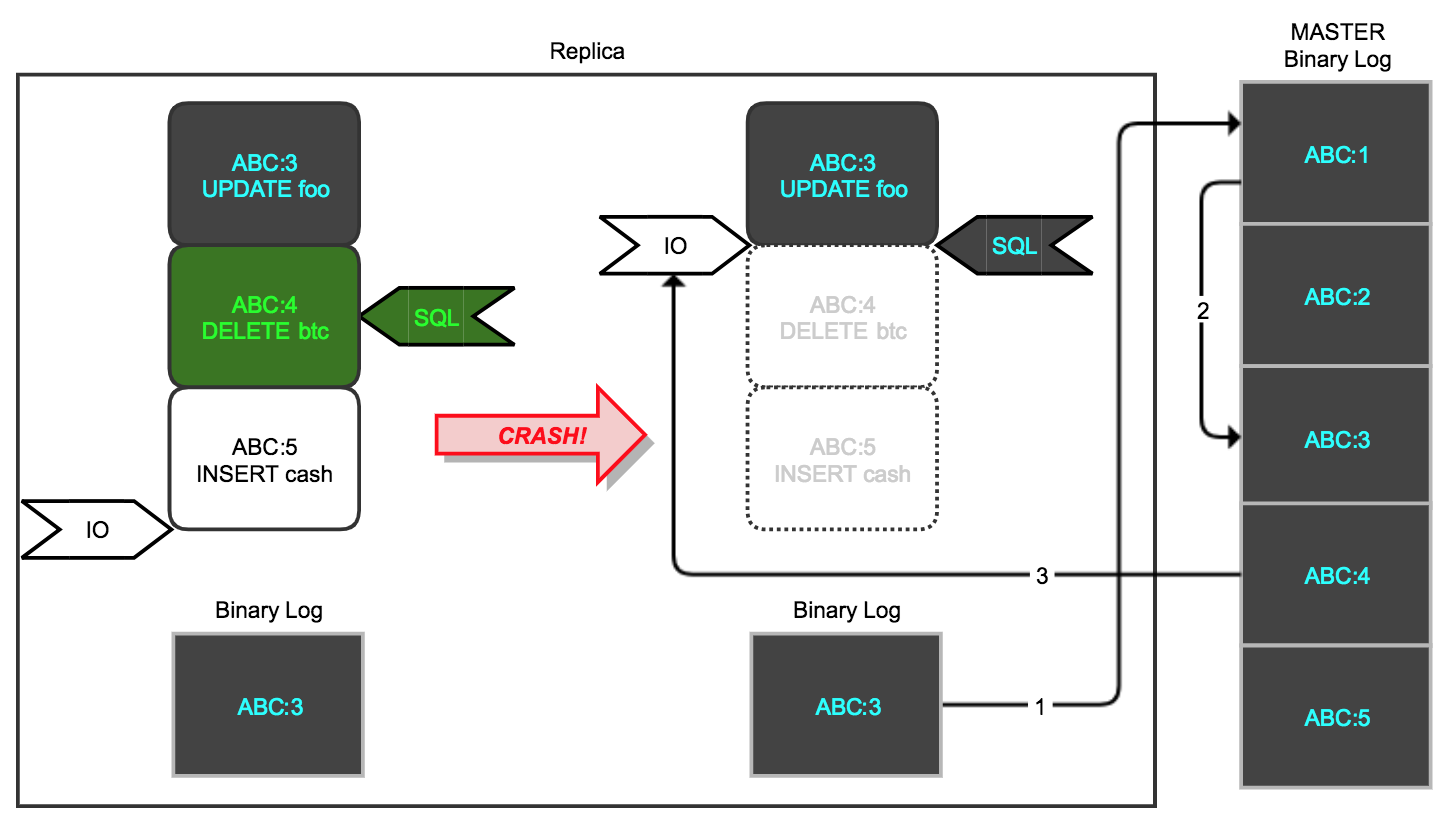
Blue ABC:3 indicates a transaction that has been executed and committed, green ABC:4 indicates a transaction that is being executed, at which point slave crashes, the instance logs gtid_executed=ABC:1-3, and the system restarts relay_log is deleted. slave sends UNION(@@global. gtid_executed, null) to the master, which will send the binlogs after ABC:3 to the slave for further execution.
Note that
The slave restart from the new replication protocol is based on the GTID information in the binlog, and does not depend on mysql.slave_replay_log_info. To ensure that the binlog is dropped in time slave should set double 1 mode sync_binlog = 1 innodb_flush_log_at_trx_commit = 1
2.4. How to enable the crash-safe feature
Enable this feature by configuring two of the following two parameters.
relay_log_info_repository = TABLE relay_log_recovery = ON See here is not a question why there is no master.info related parameters configuration?
In fact, after the crash-safe of slave is enabled, the slave will automatically clear the previous relay-log when it restarts, and the IO thread will start pulling data from the loci recorded in the
mysql.slave_relay_log_infotable, instead of relying on theslave_ master_infotable.
Note: If you are using MySQL 5.6.5 or earlier, the slave_master_info and slave_relay_log_info tables use the MyISAM engine by default. So you also have to modify it to innodb as follows.
2.5. Related parameters
-
After enabling crash-safe, the slave will no longer depend on the parameters related to master info after restarting, so these two parameters will not be discussed too much. However, in order to be consistent with the relay log info storage, it is recommended to store maste-info in the table, and keep sync_master_info as default, set it to a lower value, which will have IO loss in the case of high write pressure.
1master_info_repository =TABLE sync_master_info=0 -
Enables crash-safe required parameters
1relay_log_info_repository = TABLE relay_log_recovery = 1These 2 do not do more to introduce, the front will have been very thorough.
-
relay logrelatedWhen
relay_log_info_repository=file, the frequency of updating bit information depends onsync_relay_log_info = N (N>=0):a When sync_relay_log_info=0, MySQL relies on the OS system for periodic updates.
b When sync_relay_log_info=N (N>0), MySQL server will call fdatasync() to flush the relay-log.info file after every N transactions are executed.
When relay_log_info_repository=table
If mysql.slave_relay_log_info is an innodb storage engine, the sync_relay_log_info setting is automatically ignored for each transactional update.
If mysql.slave_relay_log_info is a non-transactional storage engine, then
a When sync_relay_log_info=0, no update is performed.
b When sync_relay_log_info=N (N>0), MySQL server will call fdatasync() to flush the
relay-log.infofile after every N transactions are executed.sync_relay_log controls the refresh policy of relay-log, similar to sync_binlog, but this parameter has no real meaning when the crash-safe feature is enabled. It is recommended to leave this parameter as default.
3.Other issues
Every coin has its two sides. What are the potential problems associated with turning on crash-safe?
- Restart the slave and pull the relay-log again, a master-multi-slave cluster will put pressure on the IO and bandwidth of the master.
- The master is not available, or the binlog is deleted, the slave cannot find the binlog it needs.
Reference https://tech.youzan.com/shen-ru-qian-chu-mysql-crash-safe/