We are recently doing the technology selection for new business, which involves the selection of messaging middleware; combined with our actual situation we hope it can meet the following requirements.
- Cloud-friendly native support: because the main language is now Go, while being able to be simple enough in terms of operation and maintenance.
- Official SDK support for multiple languages: There is still some Python, Java related code to maintain.
- Preferably with some convenient and useful features, such as: delayed messages, dead letter queues, multi-tenancy, etc.
Of course there are some horizontal scaling, throughput, low latency and other features needless to say, almost all mature messaging middleware can meet these requirements.
Based on the above filtering criteria, Pulsar came into our view.
As the top project under Apache, all the above features are well supported.
Let’s talk about what’s so great about it.
Architecture
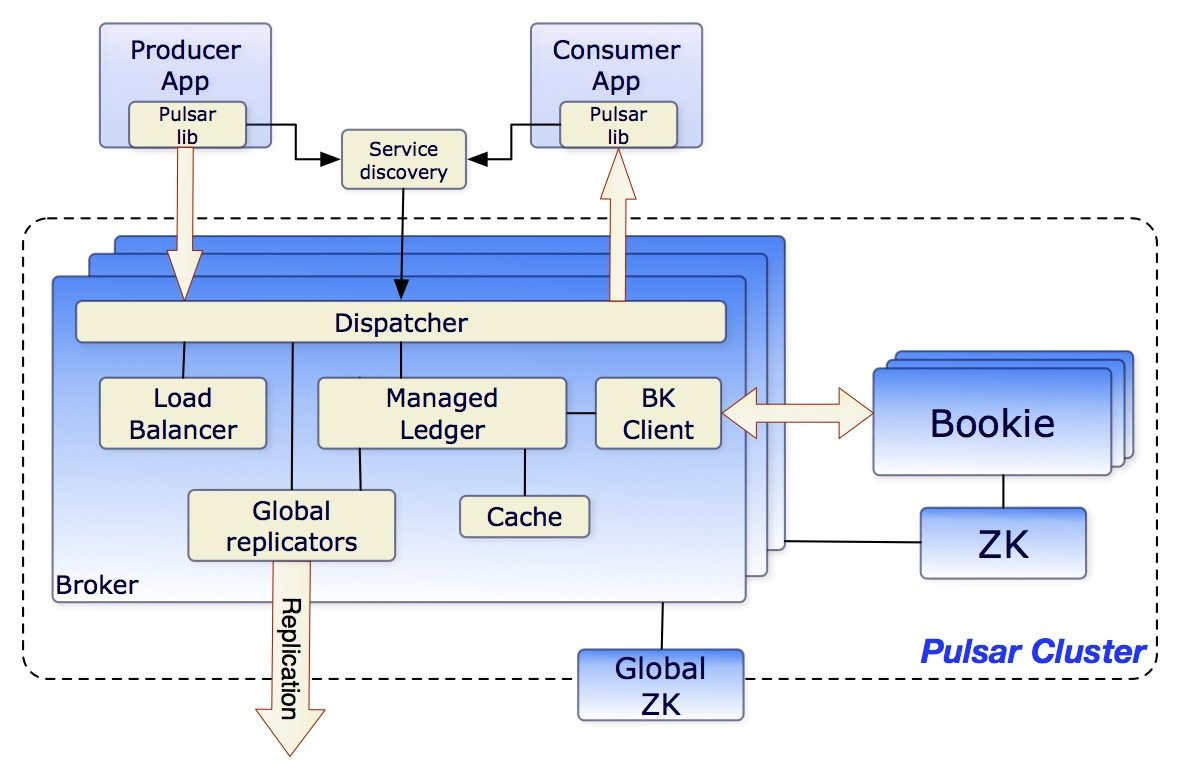
The official architecture diagram shows that Pulsar consists of the following main components.
Brokerstateless component, which can scale horizontally, mainly for producer and consumer connections; similar to Kafka’s broker, but without data storage, so it scales more easily.BookKeepercluster: mainly used for persistent storage of data.Zookeeperis used to store metadata of broker and BookKeeper.
The overall look seems to have more components than Kafka, which does add complexity to the system; but the same benefits are obvious.
Pulsar’s storage is separate from the compute, so when it needs to be scaled up, it’s as simple as adding a new broker without any other mental burden.
When the storage becomes a bottleneck, you only need to expand BookKeeper, no need to do artificial rebalancing, BookKeeper will automatically load.
The same operation is much more complicated with Kafka.
Characteristics
Multi-tenant
Multi-tenancy is also a just-needed feature to isolate the data of different businesses and teams in the same cluster.
|
|
Take the topic name for example, there is a namespace of order under the core tenant, and finally the topic name of create-order.
In practice, tenants are usually divided according to business teams, and namespace is the different businesses under the current team; this makes it clear to manage the topic.
The advantages and disadvantages are known by comparison. How are such problems handled in messaging middleware without multi-tenancy:.
- Simply do not divide so fine, all business lines mixed, when the team is small may not be a big problem; once the business increases, management will be very troublesome.
- You do a layer of abstraction before topic, but you are actually essentially implementing multi-tenancy as well.
- Each business team maintains its own cluster, which can certainly solve the problem, but the complexity of operation and maintenance naturally increases.
The above is a good visualization of the importance of multi-tenancy.
Function Calculation
Pulsar also supports lightweight function calculations, such as the need to clean and transform data for some messages and then publish them to another topic.
Pulsar provides an SDK that makes it easy to process the data and then publish it to a broker using official tools.
Until then, such simple requirements may also need to handle their own stream processing engine.
Use
In addition to the upper layer of applications, such as producers, consumers such concepts and use of everyone is similar.
For example, Pulsar supports four consumption modes.
Exclusive: exclusive mode, only one consumer can start and consume data at the same time; identify the same consumer by SubscriptionName), less applicable.- Failover
Failovermode: on top of exclusive mode, multiple consumers can be started at the same time, once a consumer hangs up, the rest can quickly take over, but only one consumer can consume; some scenarios are available. - Shared mode: N consumers can be running at the same time, and messages are delivered to each consumer according to round-robin polling; when a consumer is down without ack, the message will be delivered to other consumers. This consumption model can improve the consumption capacity, but the messages cannot be ordered.
KeySharedshared mode: Based on the shared mode; it is equivalent to grouping messages in the same topic, and the messages in the same group can only be consumed by the same consumer in an orderly manner.
The third shared consumption pattern should be the most used, and the KeyShared pattern can be used when there is an order requirement for the messages.
SDK

The official SDK support is extensive; I’ve also wrapped an internal SDK on top of the official SDK.
Since we use a lightweight dependency injection library like dig, it looks something like this.
|
|
Two of the container.Provide() functions are used to inject consumer objects.
Invoke(StartConsumer) will take all the consumer objects out of the container and start consuming them at the same time.
At this point, with my limited experience in Go development, I was wondering if dependency injection was needed in Go.
Let’s first look at the benefits of using a library like Dig.
-
The objects are managed by the container, which is convenient to achieve single instance.
-
When the dependencies are complex before each object, you can reduce a lot of code to create and get objects, and the dependencies are clearer. The same disadvantages are.
-
It’s not as intuitive to trace through the code and see at a glance how a dependent object was created.
-
This is not consistent with the simplicity that Go promotes.
For Java developers who have used Spring, it must smell good, after all, it’s still a familiar flavor, but for Gopher, who have not been exposed to similar needs at all, it doesn’t seem to be a necessity.
There are a variety of Go dependency injection libraries on the market today, and many of the big players are producing them, so there’s still a market for them.
I believe there are many Gophers who resent the introduction of some complex concepts from Java into Go, but I think that dependency injection itself is not limited by language, and all languages have their own implementations, except that Spring in Java is not just a dependency injection framework, but also has many complex features that are daunting to many developers.
If it’s just a subdivision of the dependency injection requirement, it’s not complicated to implement and doesn’t bring too much complexity. If you take the time to look at the source code, you can quickly master it based on understanding the concepts.
Back to the SDK itself, the Go SDK is less functional than the Java version at this stage (to be precise, only the Java version is the most feature-rich), but the core is there and it doesn’t affect daily use.
Summary
This article introduces some basic concepts and benefits of Pulsar, and also discusses Go dependency injection in passing; if you are doing technical selection like us, you may want to consider Pulsar.
Reference https://crossoverjie.top/2021/04/18/pulsar/pulsar-start/