Someone recommended this article before, Complexity has to live somewhere, the general idea is that the complexity of the system can’t just disappear, it can only be transferred from one place to another, because there is so much logic in the real world, there are so many cases around the corner that you have to deal with, which will inevitably introduce complexity into the system.
Although these complexities you can transfer to your colleagues or outsource to third-party systems, the complexity is indefinite.
When designing systems, we need to be aware of this, and at the same time manage the complexity issue.
In the book “a philosophy of software design”, the authors also present a different and more interesting theory of system complexity that
It can be read in conjunction with the article above.
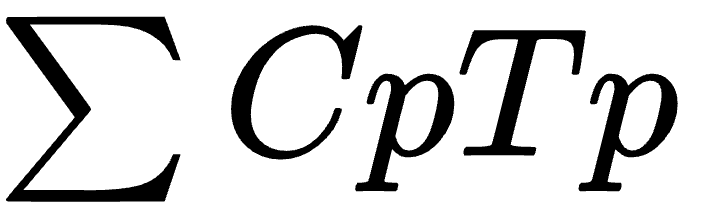
C stands for Complexity, T stands for the time invested in the development of the module Time. the overall complexity of the system = “the complexity of each module Ⅹ the development time invested in the module”, and then sum the results.
If we have actively or passively designed and implemented some logically complex systems in our daily work, this simple formula should be easy to understand at first sight. The C in this formula can also be considered as Cognitive Load, that is, the cognitive burden. The code you write is hard for your colleagues to understand, then also to think that these codes are very complex.
Improving R&D efficiency should essentially reduce the overall complexity of the system defined here.
Combining the formula with our daily development and system design, this article briefly lists some stormy theories that we hope to discuss together.
The system can be designed to be complex, as long as the complex parts are not often modified
For example, our API services are basically deployed on linux, which currently has millions of lines of code, but we don’t need to read the linux source code or focus on the complexity of linux. Only need to focus on the upper layer of business. Even if you do system programming, you only need to familiarize yourself with man7.org, and do not need to understand the underlying implementation mechanism of syscall (many people are now too voluminous for their own good).
If we encounter system-related performance problems, in most cases we do not need to do optimization in the kernel, and adjust a small number of system exposure configuration parameters according to the business situation, such as somaxconn, tcp_tw_reuse, etc..
If you are designing a business system, there is no need to be afraid of the complexity of the infrequently modified parts in order to adapt to as many situations as possible, as long as your abstractions are generic enough and you can provide users with a good extension backdoor when they cannot be adapted.
Similar to the linux kernel scenario, if we are dealing with a complex problem that only needs to be solved once, it makes sense to solve it through a complex system that is not frequently modified.
For this part of the system that is extremely complex, even if it takes a month to modify it once, it is not too costly to modify it once every two years.
Frequently modified parts and infrequently modified parts can be split
Both business systems and infrastructure become more and more complex over time, perhaps in terms of long and complex logic, scenario-based code branches, numerous protocol adaptations, and strange combinations of functionality.
Developing on a “complex-looking” system is not necessarily painful, because what we often modify is not always the process of the system, but maybe just the frequently changing business strategy: the frequency of pushing triggers to pull, the business metrics used by users, the city where the current feature is enabled, the criteria for penalizing users for violations.
These strategies above are also part of the business complexity, though they have little to do with processes. A poorly designed system with a huge code base doesn’t know where to make changes and needs to read the entire process code again and again to confirm where changes are more appropriate. If the work task is seriously pressed and the schedule is shrunk, the engineer also has a magic trick that all the requirements can be processed in the reference, and the results are returned to the previous two positions for infinite accumulation. After years and years of iteration, such a system is basically unmaintainable.

We can split these fallible and often changing elements from the system into configurations, summarized as patterns. The behavior of the system is controlled through configuration.
Even if configuration is not possible, isolating the infrequently modified parts from the frequently modified parts can significantly reduce the mental burden on engineers when maintaining the overall system, and the developers only need to focus on the functionality of their own system. The system is decoupled from the system.
Repetitive work can definitely be configured
If we are repeatedly modifying some judgment conditions, then abstract these conditions as rules and put them in the configuration management system.
If we are repeatedly modifying external data sources, then abstract the data itself and use tools like xpath, jpath, etc. to query it. More complex data fetching can be done directly using open source projects like apijson, GraphQL or falcor, and it is not difficult to design a solution by yourself.
If we are repeatedly modifying the computational logic, then we can support the expression engine in the system.
If we repeatedly modify the business process, then the process itself can be implemented using a bpm-like framework.
If we are iteratively modifying the support for various protocols, then designing a set of tools to generate protocol handling code according to IDL is sufficient.
Configuration is the templating of repetitive work content, which in the above equation reduces the overall complexity of the system by directly reducing T.
Engineers should not resist complexity
Nowadays, CRUD engineers don’t like complicated things, and often refuse to accept new requirements or make major changes to the system on the grounds that “this requirement will make the system complicated”.
But the simple project is just a logical pile, freshmen can do a good job, and many people jumped for a salary increase, for the experience of the company’s business understanding is limited. The business of all companies are summarized as CRUD, is a bit simple and violent.
A few years ago, almost all companies are pushing the CRUD, although I have some criticism of the CRUD, but does not deny the utility of the CRUD to enhance the ability of engineers. As business middle platform projects often have a certain degree of complexity, for the engineers involved is a good opportunity to broaden their horizons and ability to exercise, because it is too complex, no revenue (year-end bonus) reason to give up these opportunities, for individuals is a relatively large loss (of course, the revenue or to consider).
When the initial design of a certain platform in a division, according to the practice within the department, such a platform does not get too much departmental support and revenue, but can eliminate a lot of repetitive and boring development work within the group. We summed up 90% of the requirements and daily work from our past development experience, combined with the company’s own stage considerations and research on advanced systems in the industry before designing this system.
After the implementation, we, the participants, also saw through this process what kind of future this data-related system could develop by extending to a larger scale. For example, it can be a data center that rides on the hot stream of domestic centers and becomes a case of data center practice for first-tier Internet companies; it can also be a super query system like Google F1 that becomes a model for the implementation of advanced engineering concepts; it can also evolve into a feature and model lifecycle management platform that specifically serves machine learning business.
These are the possibilities afterwards, and it is not up to the front-line developers and architects to continue to evolve in which direction. Removing the political factors, the development and iteration of the whole system still provided us with very valuable experience, which is still useful today.
Design system similar to fortune telling
Although we can learn from past developments, it is important to make some predictions about the future when doing system design.
These predictions are not always accurate, and technical judgments and business future development do not always match. For example, e-commerce companies did not expect a new type of e-commerce company like a game maker to emerge and were caught off guard for a long time. The original system and mechanism design will not be able to achieve similar to the rival game-based e-commerce, in the promotional slogan of the gods in the middle of the table is also not possible.
We have a flirtation with the architect, the architect itself is a data-driven fortune teller, to make predictions about the future, predicted right is God, predicted wrong is 🐶.
But it’s just a banter, we are all human, no one can break the human ceiling.
I have time to write a separate book “a philosophy of software design” reading notes.