It’s been a long time since I’ve shared tips on file IO, and I vaguely remember the last time I did so.
Kirito is also working on the topic “RocketMQ Storage System Design for Hot and Cold Read/Write Scenarios”, but we are participating in the internal track, so we can’t rank with our external partners.
As we all know, storage design is inseparable from file IO, and storing data in files for persistence is a regular operation in most message queues and database systems. In competitions, in order to be closer to real production scenarios, a correctness testing phase is often introduced as well, to avoid having players design code logic that only supports in-memory behavior. Imagine how terrible it would be if RocketMQ or Mysql could not query data after a downtime due to index loss!
Correctness testing requires that the data we write can be queried without loss, and in my personal experience with the competition, there are usually three levels
- Process exits normally or process is interrupted by kill -15
- Process interrupted by kill -9
- System power down
The first level, the process exits normally or the process is interrupted by kill -15, there is nothing to say about this scenario, generally the evaluation program will leave destroy, close and other callback interfaces for explicit closure, or use the ShutdownHook provided by the JVM in Java to listen to the -15 signal, this is the simplest kind of scenario, generally there is no need to consider data consistency issues. In real production, it corresponds to our graceful exit, manual shutdown process.
At the second level, the process is interrupted by kill -9. This means that we may be limited in using memory to aggregate some data, but we can still take advantage of some OS features, such as PageCache, to do caching. After all, the process hangs, but the machine doesn’t. In actual production, this corresponds to scenarios where we encounter some memory overflows, FullGC restarts the process, and other violent exits from the program.
The third level, the system power down. This is also the main character of my article, and is also the level with the highest data consistency requirements. System power down means that we can’t even utilize PageCache directly and must strictly ensure that the data falls to disk. In actual production, this corresponds to scenarios such as host downtime and power failure in the server room.
It can be found that any level, there are scenarios of their practical application, the more the level of consistency required, usually the worse the performance, the less means can be utilized, and the more difficult the system is to design.
And the correctness of this competition is described
Translated with www.DeepL.com/Translator (free version)
- Write several pieces of data.
- restart the machine
- Read it out again, it must be strictly equal to the data written before
One of the reboot machine sessions happens to be a simulated power drop.
How to understand no data loss
Before introducing the means to ensure that power loss is not lost in Java file IO, I also need to make a conceptual introduction, so that we can better understand the subsequent points of the article.
Many students may have doubts, if a data is written halfway and a power loss occurs, how does the evaluation program know if this data has fallen on the disk or not? Will the evaluation program read this data? In fact, no one can guarantee the logic of “halfway through the execution”, just as the system really loses power, he will not discuss with you. Therefore, in the general evaluation, to verify the consistency of the player’s data, usually take the approach that when a method returns synchronously, it should be considered that this data has fallen on the disk, even if the power is lost immediately after the return, it should be possible to query this data after restart.
This is in line with our perception in real development/production scenarios that.
- For synchronous methods, the contract of ack is actually implied, i.e., the moment we get the return value, we think the other side is finished processing.
- For asynchronous methods, we only need to add the mechanism of callback or polling ack.
Java File IO guarantees power down without data loss
There is only one FileChannel in Java that is the most commonly used file manipulation class. The write method of FileChannel looks like a synchronous method that writes in-memory data to disk, but there is actually a PageCache between it and the disk.
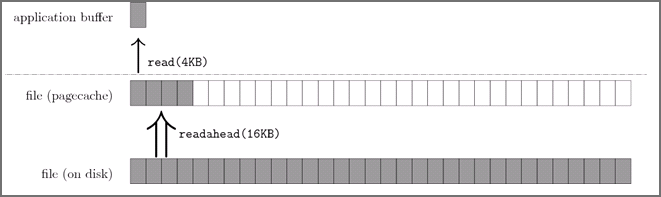
While the OS may be quick to swipe the PageCache to disk, the process is still an asynchronous one. In the case of this contest, if you just write data to the PageCache and leave it alone, it will definitely not pass the correctness test.
The solution is also simple, just call the FileChannel#force(boolean meta) method, which forces the OS to flush the PageCache to disk.
The entry for force is a boolean value that represents whether the metadata will also be flushed. According to my personal understanding, metadata contains size and timestamp information, which may affect the actual length of the file, so force(true) may be more secure.
Combined with what was introduced in Section 2, we just need to make sure that we call force before each write operation returns to achieve the effect of no data loss on power down.
So, what is the cost? It means that we completely lose a cache set by the OS for file IO. With no cache and no 4kb alignment, the write amplification problem will be very obvious.
Here’s the data: according to the official data, the SSD used in this review can reach 320MiB/s, while I tested the force in an unoptimized scenario and it only reached 50 Mib/s, which directly caused the review to time out.
force is the savior of power loss, and possibly the destroyer of performance.
Possible optimization solutions under force
In the actual scenario, the producer of the message may send multiple messages in succession synchronously, and there may be multiple producers sending messages together. Although the delivery of messages is synchronous, we can still do something between the messages of multiple different producers to reduce the problem of write amplification while ensuring force.
Given that the game is still in progress, I won’t talk too much about the detailed design. Those who know should see the above paragraph to understand that it is still a relatively basic optimization. After the optimization, I can guarantee that the throughput can be increased from 50 Mib/s to 275 Mib/s under the premise of force, although there is still a gap from the theoretical value, but it is enough to get out a baseline.
Practical Applications in RocketMQ
RocketMQ has two main mechanisms to protect against data loss on the Broker side: 1.
- RocketMQ supports configuring synchronous double writes to ensure that messages are backed up in a slave node in addition to the master node
- RocketMQ supports a synchronous flush-to-disk policy, i.e., the
FileChannel#force(boolean meta)scheme introduced in this paper