Prerequisites
Stream was first introduced in JDK1.8, nearly 8 years ago (JDK1.8 was released at the end of 2013), and the introduction of Stream greatly simplified some development scenarios, but on the other hand, it may have reduced the readability of the code (it is true that many people say that Stream will reduce the readability of the code, but in my opinion, the readability of the code is improved after proficient use). (I think the readability of the code has been improved after using it skillfully). This article will spend a huge amount of space to analyze in detail the underlying implementation principle of Stream, the reference source code is the source code of JDK11, other versions of the JDK may not apply to this article in the source code display and related examples.
This article has taken a lot of time and effort to sort out and write, and I hope it will help the readers of this article
How Stream is forward compatible
Stream is introduced in JDK1.8, such as the need for JDK1.7 or previous code can also run in JDK1.8 or above, then the introduction of Stream must not have been released in the original interface methods to modify, otherwise it will certainly be due to compatibility issues that lead to the old version of the interface implementation can not run in the new version (method signature exceptions), guess is based on this The problem is based on the introduction of the interface default method, that is, the default keyword. A look at the source code shows that ArrayList’s superclasses Collection and Iterable have added several default methods.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
// java.util.Collection部分源码
public interface Collection<E> extends Iterable<E> {
// 省略其他代码
@Override
default Spliterator<E> spliterator() {
return Spliterators.spliterator(this, 0);
}
default Stream<E> stream() {
return StreamSupport.stream(spliterator(), false);
}
default Stream<E> parallelStream() {
return StreamSupport.stream(spliterator(), true);
}
}
// java.lang.Iterable部分源码
public interface Iterable<T> {
// 省略其他代码
default void forEach(Consumer<? super T> action) {
Objects.requireNonNull(action);
for (T t : this) {
action.accept(t);
}
}
default Spliterator<T> spliterator() {
return Spliterators.spliteratorUnknownSize(iterator(), 0);
}
}
|
From intuition, these new methods should be the key methods implemented in Stream (later will confirm that this is not intuition, but the result of viewing the source code). Interface default methods are consistent in use with the instance methods, in the implementation can be written directly in the interface methods method body, a bit of static methods, but subclasses can override its implementation (that is, the interface default methods in this interface implementation is a bit like static methods, can be overridden by subclasses, consistent in use with the instance methods). This implementation could be a breakthrough or a compromise, but both the compromise and the breakthrough achieve forward compatibility.
1
2
3
4
5
6
7
8
9
10
11
12
13
|
// JDK1.7中的java.lang.Iterable
public interface Iterable<T> {
Iterator<T> iterator();
}
// JDK1.7中的Iterable实现
public MyIterable<Long> implements Iterable<Long>{
public Iterator<Long> iterator(){
....
}
}
|
As above, MyIterable is defined in JDK1.7, if the class runs in JDK1.8, then calling its forEach() and spliterator() methods in its example is equivalent to directly calling the default methods forEach() and spliterator() of the interface in Iterable in JDK1.8. Of course, limited by the JDK version, here can only ensure that the compilation passed, the old function is used normally, and can not use the JDK1.7 in the Stream-related functions or use the default method keyword. To sum up so much, is to explain why the code developed and compiled using JDK7 can run in the JDK8 environment.
Splittable Iterator Spliterator
The cornerstone of Stream implementation is Spliterator, which stands for “splitable iterator” and is used to iterate over elements in a specified data source (e.g., array, collection, or IO Channel). It is designed with serial and parallel scenarios in mind. As mentioned in the previous section, Collection has a default interface method spliterator(), which generates a Spliterator instance, meaning that all collection subclasses have the ability to create Spliterator instances. The Stream implementation is very similar in design to the ChannelHandlerContext in Netty, which is essentially a chain table, and the Spliterator is the Head node of this chain (the Spliterator instance is the head node of a stream instance, which will be expanded later when the specific source code is analyzed).
Spliterator interface methods
Moving on to the methods defined by the Spliterator interface.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
public interface Spliterator<T> {
// 暂时省略其他代码
boolean tryAdvance(Consumer<? super T> action);
default void forEachRemaining(Consumer<? super T> action) {
do { } while (tryAdvance(action));
}
Spliterator<T> trySplit();
long estimateSize();
default long getExactSizeIfKnown() {
return (characteristics() & SIZED) == 0 ? -1L : estimateSize();
}
int characteristics();
default boolean hasCharacteristics(int characteristics) {
return (characteristics() & characteristics) == characteristics;
}
default Comparator<? super T> getComparator() {
throw new IllegalStateException();
}
// 暂时省略其他代码
}
|
tryAdvance
- Method signature:
boolean tryAdvance(Consumer<? super T> action)
- Function: If the Spliterator has the ORDERED feature enabled, the action callback passed in is executed for one of the elements and returns true, otherwise it returns false. if the Spliterator has the ORDERED feature enabled, it will process the next element in order (where the order value can be analogous to the subscript of the container array elements in an ArrayList. Adding new elements to an ArrayList is naturally ordered, with subscripts incrementing from zero) to the next element
- Example.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
public static void main(String[] args) throws Exception {
List<Integer> list = new ArrayList<>();
list.add(2);
list.add(1);
list.add(3);
Spliterator<Integer> spliterator = list.stream().spliterator();
final AtomicInteger round = new AtomicInteger(1);
final AtomicInteger loop = new AtomicInteger(1);
while (spliterator.tryAdvance(num -> System.out.printf("第%d轮回调Action,值:%d\n", round.getAndIncrement(), num))) {
System.out.printf("第%d轮循环\n", loop.getAndIncrement());
}
}
// 控制台输出
第1轮回调Action,值:2
第1轮循环
第2轮回调Action,值:1
第2轮循环
第3轮回调Action,值:3
第3轮循环
|
forEachRemaining
- Method Signature:
default void forEachRemaining(Consumer<? super T> action)
- Function: If there are remaining elements in the Spliterator, the incoming action callback is executed in the current thread for all remaining elements in it. If the Spliterator has the ORDERED feature enabled, all remaining elements are processed in order. This is the default method of the interface, and the method body is rather brutal, directly a dead loop wrapped around the tryAdvance() method until false exits the loop
- Example.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
public static void main(String[] args) {
List<Integer> list = new ArrayList<>();
list.add(2);
list.add(1);
list.add(3);
Spliterator<Integer> spliterator = list.stream().spliterator();
final AtomicInteger round = new AtomicInteger(1);
spliterator.forEachRemaining(num -> System.out.printf("第%d轮回调Action,值:%d\n", round.getAndIncrement(), num));
}
// 控制台输出
第1轮回调Action,值:2
第2轮回调Action,值:1
第3轮回调Action,值:3
|
trySplit
- Method Signature:
Spliterator<T> trySplit()
- Function: If the current Spliterator is partitionable, then this method will return a new Spliterator instance, and the elements inside this new Spliterator instance will not be overwritten by the elements in the current Spliterator instance (this is a direct translation of the API comment, what it actually means is: the current Spliterator instance X is splittable, trySplit() method will split X to generate a new Spliterator instance Y, and the elements (range) contained in the original X will be shrunk, similar to X = [a,b,c,d] => X = [a,b], Y = [c,d]; if the current Spliterator instance X is (if the current Spliterator instance X is indivisible, this method will return NULL), the specific splitting algorithm is determined by the implementation class
- Example.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
public static void main(String[] args) throws Exception {
List<Integer> list = new ArrayList<>();
list.add(2);
list.add(3);
list.add(4);
list.add(1);
Spliterator<Integer> first = list.stream().spliterator();
Spliterator<Integer> second = first.trySplit();
first.forEachRemaining(num -> {
System.out.printf("first spliterator item: %d\n", num);
});
second.forEachRemaining(num -> {
System.out.printf("second spliterator item: %d\n", num);
});
}
// 控制台输出
first spliterator item: 4
first spliterator item: 1
second spliterator item: 2
second spliterator item: 3
|
estimateSize
- Method Signature:
long estimateSize()
- Function: Returns an estimate of the total number of elements to be traversed by the forEachRemaining() method, or Long.MAX_VALUE if the number of samples is infinite, too expensive to compute, or unknown.
- Example.
1
2
3
4
5
6
7
8
9
10
11
12
|
public static void main(String[] args) throws Exception {
List<Integer> list = new ArrayList<>();
list.add(2);
list.add(3);
list.add(4);
list.add(1);
Spliterator<Integer> spliterator = list.stream().spliterator();
System.out.println(spliterator.estimateSize());
}
// 控制台输出
4
|
getExactSizeIfKnown
- Method Signature:
default long getExactSizeIfKnown()
- Function: If the current Spliterator has the SIZED feature (more on the feature below), then call the optimizeSize() method directly, otherwise it returns -1.
- Example.
1
2
3
4
5
6
7
8
9
10
11
12
|
public static void main(String[] args) throws Exception {
List<Integer> list = new ArrayList<>();
list.add(2);
list.add(3);
list.add(4);
list.add(1);
Spliterator<Integer> spliterator = list.stream().spliterator();
System.out.println(spliterator.getExactSizeIfKnown());
}
// 控制台输出
4
|
int characteristics()
- Method Signature:
long estimateSize()
- Function: The current Spliterator has features (collections) that use bitwise operations and are stored in 32-bit integers (more on features below)
hasCharacteristics
- Method Signature:
default boolean hasCharacteristics(int characteristics)
- Function: Determine if the current Spliterator has the incoming features
getComparator
- Method Signature:
default Comparator<? super T> getComparator()
- Function: If the current Spliterator has the SORTED feature, a Comparator instance is returned; if the elements in the Spliterator are naturally ordered (e.g. the elements implement the Comparable interface), NULL is returned; otherwise, an IllegalStateException is thrown directly.
Spliterator Self-Splitting
Spliterator#trySplit() can split an existing Spliterator instance into two Spliterator instances, which I refer to here as Spliterator self splitting, schematically as follows.
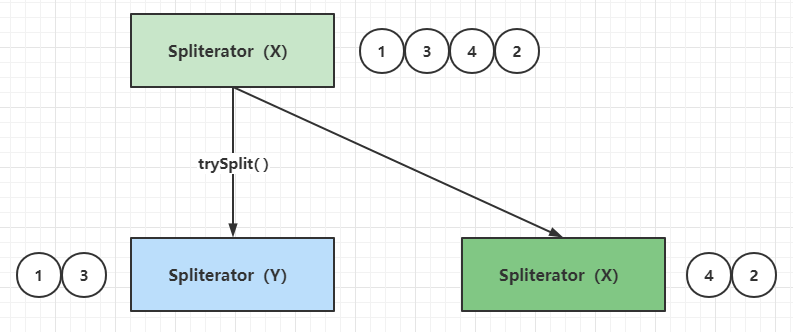
The split here can be implemented in two ways.
- Physical Partitioning: For ArrayList, copying the underlying array and partitioning it is equivalent to X = [1,3,4,2] => X = [4,2], Y = [1,3] using the above example, which is obviously not very reasonable when combined with the array of elements in the ArrayList itself, which is equivalent to storing an extra copy of the data.
- Logical partitioning: For ArrayList, since the array of element containers is naturally ordered, you can use the index (subscript) of the array for partitioning, using the above example is equivalent to X = index table [0,1,2,3] => X = index table [2,3], Y = index table [0,1], this way is to share the underlying array of containers, only the index of the elements for partitioning, the implementation is relatively simple and relatively reasonable
See the source code of ArrayListSpliterator to analyze the implementation of its segmentation algorithm.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
|
// ArrayList#spliterator()
public Spliterator<E> spliterator() {
return new ArrayListSpliterator(0, -1, 0);
}
// ArrayList中内部类ArrayListSpliterator
final class ArrayListSpliterator implements Spliterator<E> {
// 当前的处理的元素索引值,其实是剩余元素的下边界值(包含),在tryAdvance()或者trySplit()方法中被修改,一般初始值为0
private int index;
// 栅栏,其实是元素索引值的上边界值(不包含),一般初始化的时候为-1,使用时具体值为元素索引值上边界加1
private int fence;
// 预期的修改次数,一般初始化值等于modCount
private int expectedModCount;
ArrayListSpliterator(int origin, int fence, int expectedModCount) {
this.index = origin;
this.fence = fence;
this.expectedModCount = expectedModCount;
}
// 获取元素索引值的上边界值,如果小于0,则把hi和fence都赋值为(ArrayList中的)size,expectedModCount赋值为(ArrayList中的)modCount,返回上边界值
// 这里注意if条件中有赋值语句hi = fence,也就是此方法调用过程中临时变量hi总是重新赋值为fence,fence是ArrayListSpliterator实例中的成员属性
private int getFence() {
int hi;
if ((hi = fence) < 0) {
expectedModCount = modCount;
hi = fence = size;
}
return hi;
}
// Spliterator自分割,这里采用了二分法
public ArrayListSpliterator trySplit() {
// hi等于当前ArrayListSpliterator实例中的fence变量,相当于获取剩余元素的上边界值
// lo等于当前ArrayListSpliterator实例中的index变量,相当于获取剩余元素的下边界值
// mid = (lo + hi) >>> 1,这里的无符号右移动1位运算相当于(lo + hi)/2
int hi = getFence(), lo = index, mid = (lo + hi) >>> 1;
// 当lo >= mid的时候为不可分割,返回NULL,否则,以index = lo,fence = mid和expectedModCount = expectedModCount创建一个新的ArrayListSpliterator
// 这里有个细节之处,在新的ArrayListSpliterator构造参数中,当前的index被重新赋值为index = mid,这一点容易看漏,老程序员都喜欢做这样的赋值简化
// lo >= mid返回NULL的时候,不会创建新的ArrayListSpliterator,也不会修改当前ArrayListSpliterator中的参数
return (lo >= mid) ? null : new ArrayListSpliterator(lo, index = mid, expectedModCount);
}
// tryAdvance实现
public boolean tryAdvance(Consumer<? super E> action) {
if (action == null)
throw new NullPointerException();
// 获取迭代的上下边界
int hi = getFence(), i = index;
// 由于前面分析下边界是包含关系,上边界是非包含关系,所以这里要i < hi而不是i <= hi
if (i < hi) {
index = i + 1;
// 这里的elementData来自ArrayList中,也就是前文经常提到的元素数组容器,这里是直接通过元素索引访问容器中的数据
@SuppressWarnings("unchecked") E e = (E)elementData[i];
// 对传入的Action进行回调
action.accept(e);
// 并发修改异常判断
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
return true;
}
return false;
}
// forEachRemaining实现,这里没有采用默认实现,而是完全覆盖实现一个新方法
public void forEachRemaining(Consumer<? super E> action) {
// 这里会新建所需的中间变量,i为index的中间变量,hi为fence的中间变量,mc为expectedModCount的中间变量
int i, hi, mc;
Object[] a;
if (action == null)
throw new NullPointerException();
// 判断容器数组存在性
if ((a = elementData) != null) {
// hi、fence和mc初始化
if ((hi = fence) < 0) {
mc = modCount;
hi = size;
}
else
mc = expectedModCount;
// 这里就是先做参数合法性校验,再遍历临时数组容器a中中[i,hi)的剩余元素对传入的Action进行回调
// 这里注意有一处隐蔽的赋值(index = hi),下界被赋值为上界,意味着每个ArrayListSpliterator实例只能调用一次forEachRemaining()方法
if ((i = index) >= 0 && (index = hi) <= a.length) {
for (; i < hi; ++i) {
@SuppressWarnings("unchecked") E e = (E) a[i];
action.accept(e);
}
// 这里校验ArrayList的modCount和mc是否一致,理论上在forEachRemaining()遍历期间,不能对数组容器进行元素的新增或者移除,一旦发生modCount更变会抛出异常
if (modCount == mc)
return;
}
}
throw new ConcurrentModificationException();
}
// 获取剩余元素估计值,就是用剩余元素索引上边界直接减去下边界
public long estimateSize() {
return getFence() - index;
}
// 具备ORDERED、SIZED和SUBSIZED特性
public int characteristics() {
return Spliterator.ORDERED | Spliterator.SIZED | Spliterator.SUBSIZED;
}
}
|
When reading the source code be sure to pay attention to the older generation of programmers sometimes use a more covert assignment, the author believes that it needs to be expanded.
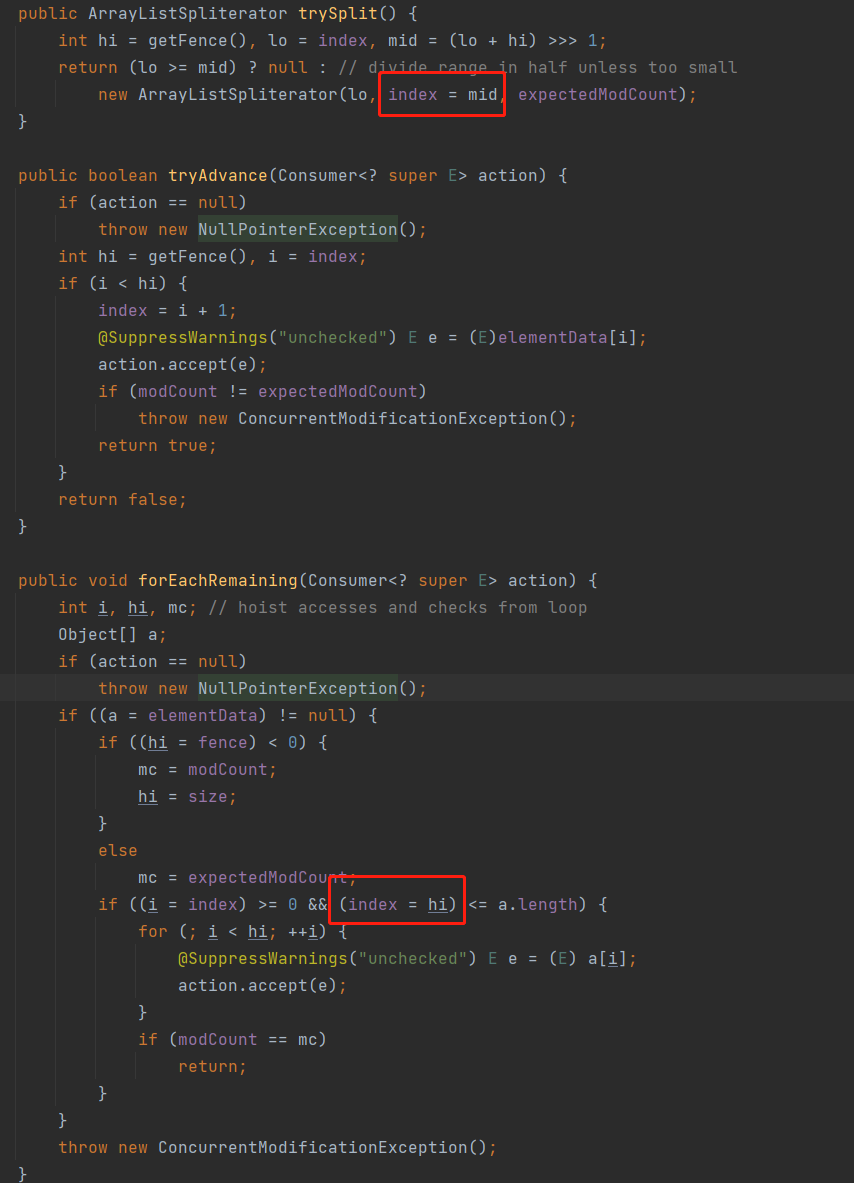
The first red circle position in the construction of the new ArrayListSpliterator, the index property of the current ArrayListSpliterator is also modified, the process is as follows.
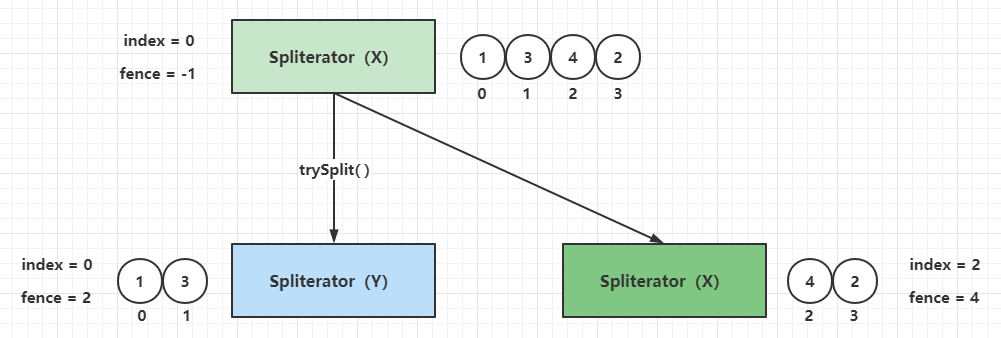
In the second red circle, if the forEachRemaining() method is called with parameter checking and the index (lower bound value) is assigned to hi (upper bound value) in the if branch, then the forEachRemaining() method of an ArrayListSpliterator instance must perform the traversal operation only once. once. This can be verified as follows.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
public static void main(String[] args) {
List<Integer> list = new ArrayList<>();
list.add(2);
list.add(1);
list.add(3);
Spliterator<Integer> spliterator = list.stream().spliterator();
final AtomicInteger round = new AtomicInteger(1);
spliterator.forEachRemaining(num -> System.out.printf("[第一次遍历forEachRemaining]第%d轮回调Action,值:%d\n", round.getAndIncrement(), num));
round.set(1);
spliterator.forEachRemaining(num -> System.out.printf("[第二次遍历forEachRemaining]第%d轮回调Action,值:%d\n", round.getAndIncrement(), num));
}
// 控制台输出
[第一次遍历forEachRemaining]第1轮回调Action,值:2
[第一次遍历forEachRemaining]第2轮回调Action,值:1
[第一次遍历forEachRemaining]第3轮回调Action,值:3
|
The following points can be confirmed for the implementation of ArrayListSpliterator.
- The forEachRemaining() method in a new instance of ArrayListSpliterator can only be called once
- The bound of the forEachRemaining() method in the ArrayListSpliterator instance to traverse the elements is [index, fence)
- When ArrayListSpliterator splits itself, the new ArrayListSpliterator is responsible for handling the segments with small subscripts (analogous to fork’s left branch), while the original ArrayListSpliterator is responsible for handling the segments with large subscripts (analogous to fork’s right branch).
- The number of remaining elements in the segment is an exact value, as provided by the estimSize() method of the ArrayListSpliterator.
If the above example is further divided, the following process can be obtained.
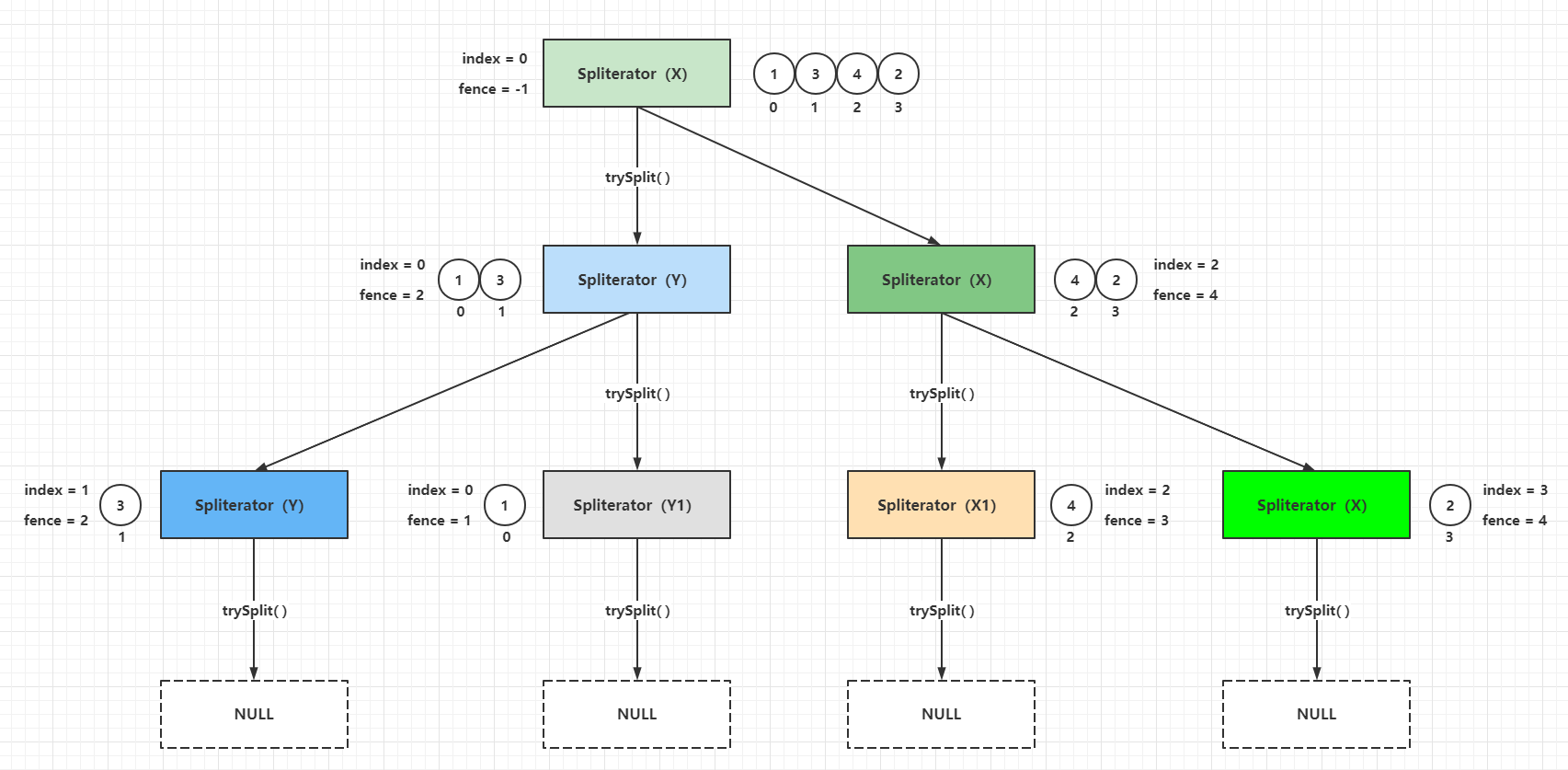
Spliterator self splitting is the basis of parallel stream implementation, the parallel stream computation process is actually fork-join processing, the implementation of trySplit() method determines the granularity of fork tasks, each fork task is concurrently safe when computing, this is guaranteed by thread closure (thread stack closure), each fork task computation The final result is then joined by a single thread to get the correct result. The following example is to find the sum of integers 1 to 100.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
|
public class ConcurrentSplitCalculateSum {
private static class ForkTask extends Thread {
private int result = 0;
private final Spliterator<Integer> spliterator;
private final CountDownLatch latch;
public ForkTask(Spliterator<Integer> spliterator,
CountDownLatch latch) {
this.spliterator = spliterator;
this.latch = latch;
}
@Override
public void run() {
long start = System.currentTimeMillis();
spliterator.forEachRemaining(num -> result = result + num);
long end = System.currentTimeMillis();
System.out.printf("线程[%s]完成计算任务,当前段计算结果:%d,耗时:%d ms\n",
Thread.currentThread().getName(), result, end - start);
latch.countDown();
}
public int result() {
return result;
}
}
private static int join(List<ForkTask> tasks) {
int result = 0;
for (ForkTask task : tasks) {
result = result + task.result();
}
return result;
}
private static final int THREAD_NUM = 4;
public static void main(String[] args) throws Exception {
List<Integer> source = new ArrayList<>();
for (int i = 1; i < 101; i++) {
source.add(i);
}
Spliterator<Integer> root = source.stream().spliterator();
List<Spliterator<Integer>> spliteratorList = new ArrayList<>();
Spliterator<Integer> x = root.trySplit();
Spliterator<Integer> y = x.trySplit();
Spliterator<Integer> z = root.trySplit();
spliteratorList.add(root);
spliteratorList.add(x);
spliteratorList.add(y);
spliteratorList.add(z);
List<ForkTask> tasks = new ArrayList<>();
CountDownLatch latch = new CountDownLatch(THREAD_NUM);
for (int i = 0; i < THREAD_NUM; i++) {
ForkTask task = new ForkTask(spliteratorList.get(i), latch);
task.setName("fork-task-" + (i + 1));
tasks.add(task);
}
tasks.forEach(Thread::start);
latch.await();
int result = join(tasks);
System.out.println("最终计算结果为:" + result);
}
}
// 控制台输出结果
线程[fork-task-4]完成计算任务,当前段计算结果:1575,耗时:0 ms
线程[fork-task-2]完成计算任务,当前段计算结果:950,耗时:1 ms
线程[fork-task-3]完成计算任务,当前段计算结果:325,耗时:1 ms
线程[fork-task-1]完成计算任务,当前段计算结果:2200,耗时:1 ms
最终计算结果为:5050
|
Of course, the computation of the final parallel stream uses ForkJoinPool and is not executed asynchronously as brute-force as in this example. The implementation of parallel streams will be analyzed in detail below.
Features supported by Spliterator
The characteristics supported by a particular Spliterator instance are determined by the method characteristics(), which returns a 32-bit value that in practice is expanded into a bit array with all characteristics assigned to different bits, and hasCharacteristics(int characteristics) is By inputting the specific characteristics value through the bit operation to determine whether the characteristics exist in characteristics(). The following is an analysis of this technique by simplifying characteristics to byte.
1
2
3
4
5
6
7
|
假设:byte characteristics() => 也就是最多8个位用于表示特性集合,如果每个位只表示一种特性,那么可以总共表示8种特性
特性X:0000 0001
特性Y:0000 0010
以此类推
假设:characteristics = X | Y = 0000 0001 | 0000 0010 = 0000 0011
那么:characteristics & X = 0000 0011 & 0000 0001 = 0000 0001
判断characteristics是否包含X:(characteristics & X) == X
|
The process inferred above is the processing logic of the feature determination method in Spliterator.
1
2
3
4
5
6
7
|
// 返回特性集合
int characteristics();
// 基于位运算判断特性集合中是否存在输入的特性
default boolean hasCharacteristics(int characteristics) {
return (characteristics() & characteristics) == characteristics;
}
|
Here it can be verified.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
public class CharacteristicsCheck {
public static void main(String[] args) {
System.out.printf("是否存在ORDERED特性:%s\n", hasCharacteristics(Spliterator.ORDERED));
System.out.printf("是否存在SIZED特性:%s\n", hasCharacteristics(Spliterator.SIZED));
System.out.printf("是否存在DISTINCT特性:%s\n", hasCharacteristics(Spliterator.DISTINCT));
}
private static int characteristics() {
return Spliterator.ORDERED | Spliterator.SIZED | Spliterator.SORTED;
}
private static boolean hasCharacteristics(int characteristics) {
return (characteristics() & characteristics) == characteristics;
}
}
// 控制台输出
是否存在ORDERED特性:true
是否存在SIZED特性:true
是否存在DISTINCT特性:false
|
There are currently eight features supported by Spliterator, as follows.
| Features |
Hex value |
Binary value |
Function |
| DISTINCT |
0x00000001 |
0000 0000 0000 0001 |
De-weighting, e.g. for each pair of elements (x,y) to be processed, use !x.equals(y) to compare, de-weighting in Spliterator is actually based on Set processing |
| ORDERED |
0x00000010 |
0000 0000 0001 0000 |
The (element) order processing can be understood as trySplit(), tryAdvance() and forEachRemaining() methods guarantee a strict prefix order for all element processing |
| SORTED |
0x00000004 |
0000 0000 0000 0100 |
Sorting, elements are sorted using the Comparator provided by the getComparator() method, and if the SORTED feature is defined, the ORDERED feature must be defined |
| SIZED |
0x00000040 |
0000 0000 0100 0000 |
If this feature is enabled, the exact number of elements will be returned by estimateSize() before Spliterator is split or iterated. |
| NONNULL |
0x00000040 |
0000 0001 0000 0000 |
(element) is not NULL, the data source ensures that the elements Spliterator needs to process cannot be NULL, most commonly used in concurrent containers in collections, queues and Map |
| IMMUTABLE |
0x00000400 |
0000 0100 0000 0000 |
(elements) are immutable, the data source cannot be modified, i.e. elements cannot be added, replaced and removed during processing (updating attributes is allowed) |
| CONCURRENT |
0x00001000 |
0001 0000 0000 0000 |
Modifications (to the element source) are concurrently safe, meaning that multiple threads adding, replacing, or removing elements from the data source are concurrently safe without additional synchronization conditions |
| SUBSIZED |
0x00004000 |
0100 0000 0000 0000 |
The estimated number of Spliterator elements (sub-Spliterator elements), enabling this feature means that all sub-Spliterators split by trySplit() method (the current Spliterator is also a sub-Spliterator after splitting) are enabled with SIZED feature |
A closer look reveals that all features are stored in 32-bit integers, using a 1-bit interval storage strategy, and the mapping of bit subscripts to features is: (0 => DISTINCT), (3 => SORTED), (5 => ORDERED), (7 => SIZED), (9 => NONNULL), (11 => IMMUTABLE), (13 => CONCURRENT), (15 => SUBSIZED)
All the features of the function here only outlines the core definition, there are some small words or special case description limited to space did not add completely, which can refer to the specific source code in the API comments. These features will eventually be converted into StreamOpFlag and then provided to the operation judgment in Stream, as StreamOpFlag will be more complex, the following detailed analysis.
The principle of stream implementation and source code analysis
Since the stream implementation is highly abstract engineering code, it can be a bit difficult to read in source code. The whole system involves a large number of interfaces, classes and enumerations, as follows.

The top-level class structure diagram describes the pipeline-related class inheritance relationship of the stream, in which IntStream, LongStream and DoubleStream are special types, respectively, for Integer, Long and Double types, other reference types to build the Pipeline are ReferencePipeline instances, so I believe that the ReferencePipeline (reference type pipeline) is the core data structure of the stream, the following will be based on the implementation of the ReferencePipeline to do in-depth analysis.
StreamOpFlag source code analysis
Note that this subsection is very brain-burning, it is also possible that the author’s bit operation is not very skilled, most of the time consumed in this article in this subsection
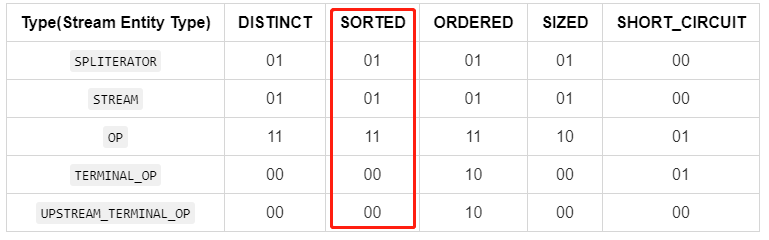
StreamOpFlag is an enumeration that functions to store Flags corresponding to characteristics of streams and operations (hereafter referred to as Stream Flags) that are provided to the Stream framework for control, customization and Stream flags can be used to characterize a number of different entities associated with a stream, including the source of the stream, the intermediate operation (Op) of the stream, and the terminal operation (Op) of the stream. However, not all Stream flags have meaning for all Stream entities, which are currently mapped to flags as follows.
| Type(Stream Entity Type) |
DISTINCT |
SORTED |
ORDERED |
SIZED |
SHORT_CIRCUIT |
| SPLITERATOR |
01 |
01 |
01 |
01 |
00 |
| STREAM |
01 |
01 |
01 |
01 |
00 |
| OP |
11 |
11 |
11 |
10 |
01 |
| TERMINAL_OP |
00 |
00 |
10 |
00 |
01 |
| UPSTREAM_TERMINAL_OP |
00 |
00 |
10 |
00 |
00 |
Among them.
- 01: indicates set/inject
- 10: indicates clear
- 11: indicates reserved
- 00: indicates the initialization value (default fill value), which is a key point, the 0 value indicates that it will never be a certain type of flag
The top comment of StreamOpFlag also contains a table as follows.
| - |
DISTINCT |
SORTED |
ORDERED |
SIZED |
SHORT_CIRCUIT |
| Stream source |
Y |
Y |
Y |
Y |
N |
| Intermediate operation |
PCI |
PCI |
PCI |
PC |
PI |
| Terminal operation |
N |
N |
PC |
N |
PI |
Tag -> Meaning.
- Y: Allowed
- N: illegal
- P: Reserved
- C: Clear
- I: Inject
- Combination PCI: can be retained, cleared or injected
- Combination PC: can be retained or cleared
- Combination PI: can be retained or injected
The two tables actually describe the same conclusion and can be compared and understood, but the final implementation refers to the definition of the first table. Note one thing: preserved(P) here means preserved. If a flag of a Stream entity is assigned to preserved, it means that the entity can use the characteristics represented by this flag. For example, the DISTINCT, SORTED and ORDERED of the OP in the first table of this subsection are all assigned the value 11 (reserved), which means that entities of type OP are allowed to use the de-duplication, natural ordering and sequential processing features. Returning to the source code section, first look at the core properties and constructors of StreamOpFlag.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
|
enum StreamOpFlag {
// 暂时忽略其他代码
// 类型枚举,Stream相关实体类型
enum Type {
// SPLITERATOR类型,关联所有和Spliterator相关的特性
SPLITERATOR,
// STREAM类型,关联所有和Stream相关的标志
STREAM,
// STREAM类型,关联所有和Stream中间操作相关的标志
OP,
// TERMINAL_OP类型,关联所有和Stream终结操作相关的标志
TERMINAL_OP,
// UPSTREAM_TERMINAL_OP类型,关联所有在最后一个有状态操作边界上游传播的终止操作标志
// 这个类型的意义直译有点拗口,不过实际上在JDK11源码中,这个类型没有被流相关功能引用,暂时可以忽略
UPSTREAM_TERMINAL_OP
}
// 设置/注入标志的bit模式,二进制数0001,十进制数1
private static final int SET_BITS = 0b01;
// 清除标志的bit模式,二进制数0010,十进制数2
private static final int CLEAR_BITS = 0b10;
// 保留标志的bit模式,二进制数0011,十进制数3
private static final int PRESERVE_BITS = 0b11;
// 掩码建造器工厂方法,注意这个方法用于实例化MaskBuilder
private static MaskBuilder set(Type t) {
return new MaskBuilder(new EnumMap<>(Type.class)).set(t);
}
// 私有静态内部类,掩码建造器,里面的map由上面的set(Type t)方法得知是EnumMap实例
private static class MaskBuilder {
// Type -> SET_BITS|CLEAR_BITS|PRESERVE_BITS|0
final Map<Type, Integer> map;
MaskBuilder(Map<Type, Integer> map) {
this.map = map;
}
// 设置类型和对应的掩码
MaskBuilder mask(Type t, Integer i) {
map.put(t, i);
return this;
}
// 对类型添加/inject
MaskBuilder set(Type t) {
return mask(t, SET_BITS);
}
MaskBuilder clear(Type t) {
return mask(t, CLEAR_BITS);
}
MaskBuilder setAndClear(Type t) {
return mask(t, PRESERVE_BITS);
}
// 这里的build方法对于类型中的NULL掩码填充为0,然后把map返回
Map<Type, Integer> build() {
for (Type t : Type.values()) {
map.putIfAbsent(t, 0b00);
}
return map;
}
}
// 类型->掩码映射
private final Map<Type, Integer> maskTable;
// bit的起始偏移量,控制下面set、clear和preserve的起始偏移量
private final int bitPosition;
// set/inject的bit set(map),其实准确来说应该是一个表示set/inject的bit map
private final int set;
// clear的bit set(map),其实准确来说应该是一个表示clear的bit map
private final int clear;
// preserve的bit set(map),其实准确来说应该是一个表示preserve的bit map
private final int preserve;
private StreamOpFlag(int position, MaskBuilder maskBuilder) {
// 这里会基于MaskBuilder初始化内部的EnumMap
this.maskTable = maskBuilder.build();
// Two bits per flag <= 这里会把入参position放大一倍
position *= 2;
this.bitPosition = position;
this.set = SET_BITS << position; // 设置/注入标志的bit模式左移2倍position
this.clear = CLEAR_BITS << position; // 清除标志的bit模式左移2倍position
this.preserve = PRESERVE_BITS << position; // 保留标志的bit模式左移2倍position
}
// 省略中间一些方法
// 下面这些静态变量就是直接返回标志对应的set/injec、清除和保留的bit map
/**
* The bit value to set or inject {@link #DISTINCT}.
*/
static final int IS_DISTINCT = DISTINCT.set;
/**
* The bit value to clear {@link #DISTINCT}.
*/
static final int NOT_DISTINCT = DISTINCT.clear;
/**
* The bit value to set or inject {@link #SORTED}.
*/
static final int IS_SORTED = SORTED.set;
/**
* The bit value to clear {@link #SORTED}.
*/
static final int NOT_SORTED = SORTED.clear;
/**
* The bit value to set or inject {@link #ORDERED}.
*/
static final int IS_ORDERED = ORDERED.set;
/**
* The bit value to clear {@link #ORDERED}.
*/
static final int NOT_ORDERED = ORDERED.clear;
/**
* The bit value to set {@link #SIZED}.
*/
static final int IS_SIZED = SIZED.set;
/**
* The bit value to clear {@link #SIZED}.
*/
static final int NOT_SIZED = SIZED.clear;
/**
* The bit value to inject {@link #SHORT_CIRCUIT}.
*/
static final int IS_SHORT_CIRCUIT = SHORT_CIRCUIT.set;
}
|
And because StreamOpFlag is an enumeration, an enumeration member is a separate flag, and a flag will act on multiple Stream entity types, so one of its members describes a column of the above entity-flag mapping relationship (viewed vertically):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
|
// 纵向看
DISTINCT Flag:
maskTable: {
SPLITERATOR: 0000 0001,
STREAM: 0000 0001,
OP: 0000 0011,
TERMINAL_OP: 0000 0000,
UPSTREAM_TERMINAL_OP: 0000 0000
}
position(input): 0
bitPosition: 0
set: 1 => 0000 0000 0000 0000 0000 0000 0000 0001
clear: 2 => 0000 0000 0000 0000 0000 0000 0000 0010
preserve: 3 => 0000 0000 0000 0000 0000 0000 0000 0011
SORTED Flag:
maskTable: {
SPLITERATOR: 0000 0001,
STREAM: 0000 0001,
OP: 0000 0011,
TERMINAL_OP: 0000 0000,
UPSTREAM_TERMINAL_OP: 0000 0000
}
position(input): 1
bitPosition: 2
set: 4 => 0000 0000 0000 0000 0000 0000 0000 0100
clear: 8 => 0000 0000 0000 0000 0000 0000 0000 1000
preserve: 12 => 0000 0000 0000 0000 0000 0000 0000 1100
ORDERED Flag:
maskTable: {
SPLITERATOR: 0000 0001,
STREAM: 0000 0001,
OP: 0000 0011,
TERMINAL_OP: 0000 0010,
UPSTREAM_TERMINAL_OP: 0000 0010
}
position(input): 2
bitPosition: 4
set: 16 => 0000 0000 0000 0000 0000 0000 0001 0000
clear: 32 => 0000 0000 0000 0000 0000 0000 0010 0000
preserve: 48 => 0000 0000 0000 0000 0000 0000 0011 0000
SIZED Flag:
maskTable: {
SPLITERATOR: 0000 0001,
STREAM: 0000 0001,
OP: 0000 0010,
TERMINAL_OP: 0000 0000,
UPSTREAM_TERMINAL_OP: 0000 0000
}
position(input): 3
bitPosition: 6
set: 64 => 0000 0000 0000 0000 0000 0000 0100 0000
clear: 128 => 0000 0000 0000 0000 0000 0000 1000 0000
preserve: 192 => 0000 0000 0000 0000 0000 0000 1100 0000
SHORT_CIRCUIT Flag:
maskTable: {
SPLITERATOR: 0000 0000,
STREAM: 0000 0000,
OP: 0000 0001,
TERMINAL_OP: 0000 0001,
UPSTREAM_TERMINAL_OP: 0000 0000
}
position(input): 12
bitPosition: 24
set: 16777216 => 0000 0001 0000 0000 0000 0000 0000 0000
clear: 33554432 => 0000 0010 0000 0000 0000 0000 0000 0000
preserve: 50331648 => 0000 0011 0000 0000 0000 0000 0000 0000
|
Then the by-and (&) and by-or (|) operations are used. Suppose A = 0001, B = 0010, C = 1000, then.
- A|B = A | B = 0001 | 0010 = 0011 (by bit or, 1|0=1, 0|1=1,0|0 =0,1|1=1)
- A&B = A & B = 0001 | 0010 = 0000 (by bit with, 1|0=0, 0|1=0,0|0 =0,1|1=1)
- MASK = A | B | C = 0001 | 0010 | 1000 = 1011
- Then the condition to determine whether A|B contains A is: A == (A|B & A)
- Then the condition to determine whether MASK contains A is: A == MASK & A
The enumeration in StreamOpFlag is applied here for analysis.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
static int DISTINCT_SET = 0b0001;
static int SORTED_CLEAR = 0b1000;
public static void main(String[] args) throws Exception {
// 支持DISTINCT标志和不支持SORTED标志
int flags = DISTINCT_SET | SORTED_CLEAR;
System.out.println(Integer.toBinaryString(flags));
System.out.printf("支持DISTINCT标志:%s\n", DISTINCT_SET == (DISTINCT_SET & flags));
System.out.printf("不支持SORTED标志:%s\n", SORTED_CLEAR == (SORTED_CLEAR & flags));
}
// 控制台输出
1001
支持DISTINCT标志:true
不支持SORTED标志:true
|
Since StreamOpFlag’s modifier is the default, it cannot be used directly, and its code can be copied out to modify the package name to verify the functionality inside:
1
2
3
4
5
6
7
8
9
10
|
public static void main(String[] args) {
int flags = StreamOpFlag.DISTINCT.set | StreamOpFlag.SORTED.clear;
System.out.println(StreamOpFlag.DISTINCT.set == (StreamOpFlag.DISTINCT.set & flags));
System.out.println(StreamOpFlag.SORTED.clear == (StreamOpFlag.SORTED.clear & flags));
}
// 输出
true
true
|
The following methods are defined based on these arithmetic properties.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
enum StreamOpFlag {
// 暂时忽略其他代码
// 返回当前StreamOpFlag的set/inject的bit map
int set() {
return set;
}
// 返回当前StreamOpFlag的清除的bit map
int clear() {
return clear;
}
// 这里判断当前StreamOpFlag类型->标记映射中Stream类型的标记,如果大于0说明不是初始化状态,那么当前StreamOpFlag就是Stream相关的标志
boolean isStreamFlag() {
return maskTable.get(Type.STREAM) > 0;
}
// 这里就用到按位与判断输入的flags中是否设置当前StreamOpFlag(StreamOpFlag.set)
boolean isKnown(int flags) {
return (flags & preserve) == set;
}
// 这里就用到按位与判断输入的flags中是否清除当前StreamOpFlag(StreamOpFlag.clear)
boolean isCleared(int flags) {
return (flags & preserve) == clear;
}
// 这里就用到按位与判断输入的flags中是否保留当前StreamOpFlag(StreamOpFlag.clear)
boolean isPreserved(int flags) {
return (flags & preserve) == preserve;
}
// 判断当前的Stream实体类型是否可以设置本标志,要求Stream实体类型的标志位为set或者preserve,按位与要大于0
boolean canSet(Type t) {
return (maskTable.get(t) & SET_BITS) > 0;
}
// 暂时忽略其他代码
}
|
Here is a special operation, the bit operation is used (flags & preserve), the reason is: the same Stream entity type in the same flag can only exist one of set/inject, clear and preserve, that is, the same flags can not exist both StreamOpFlag. SORTED.set and StreamOpFlag.SORTED.clear, which are semantically contradictory, while the size (2 bits) and position of set/inject, clear and preserve in the bit map are already fixed, and preserve is designed to be 0b11 exactly 2 bits inverse, so it can be specialised to (This specialization also makes the judgment more rigorous).
1
2
3
|
(flags & set) == set => (flags & preserve) == set
(flags & clear) == clear => (flags & preserve) == clear
(flags & preserve) == preserve => (flags & preserve) == preserve
|
Analyze so much, in general, is to want to pass a 32-bit integer, every 2 bits indicate 3 kinds of state, then a complete Flags (Flags collection) can represent a total of 16 kinds of flags (position = [0,15], you can check the API notes, [4,11] and [13,15] position is not required to achieve or reserved, belong to the gap). Then we analyze the example of MaskMask calculation process
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
|
// 横向看(位移动运算符优先级高于与或,例如<<的优先级比|高)
SPLITERATOR_CHARACTERISTICS_MASK:
mask(init) = 0
mask(DISTINCT,SPLITERATOR[DISTINCT]=01,bitPosition=0) = 0000 0000 | 0000 0001 << 0 = 0000 0000 | 0000 0001 = 0000 0001
mask(SORTED,SPLITERATOR[SORTED]=01,bitPosition=2) = 0000 0001 | 0000 0001 << 2 = 0000 0001 | 0000 0100 = 0000 0101
mask(ORDERED,SPLITERATOR[ORDERED]=01,bitPosition=4) = 0000 0101 | 0000 0001 << 4 = 0000 0101 | 0001 0000 = 0001 0101
mask(SIZED,SPLITERATOR[SIZED]=01,bitPosition=6) = 0001 0101 | 0000 0001 << 6 = 0001 0101 | 0100 0000 = 0101 0101
mask(SHORT_CIRCUIT,SPLITERATOR[SHORT_CIRCUIT]=00,bitPosition=24) = 0101 0101 | 0000 0000 << 24 = 0101 0101 | 0000 0000 = 0101 0101
mask(final) = 0000 0000 0000 0000 0000 0000 0101 0101(二进制)、85(十进制)
STREAM_MASK:
mask(init) = 0
mask(DISTINCT,SPLITERATOR[DISTINCT]=01,bitPosition=0) = 0000 0000 | 0000 0001 << 0 = 0000 0000 | 0000 0001 = 0000 0001
mask(SORTED,SPLITERATOR[SORTED]=01,bitPosition=2) = 0000 0001 | 0000 0001 << 2 = 0000 0001 | 0000 0100 = 0000 0101
mask(ORDERED,SPLITERATOR[ORDERED]=01,bitPosition=4) = 0000 0101 | 0000 0001 << 4 = 0000 0101 | 0001 0000 = 0001 0101
mask(SIZED,SPLITERATOR[SIZED]=01,bitPosition=6) = 0001 0101 | 0000 0001 << 6 = 0001 0101 | 0100 0000 = 0101 0101
mask(SHORT_CIRCUIT,SPLITERATOR[SHORT_CIRCUIT]=00,bitPosition=24) = 0101 0101 | 0000 0000 << 24 = 0101 0101 | 0000 0000 = 0101 0101
mask(final) = 0000 0000 0000 0000 0000 0000 0101 0101(二进制)、85(十进制)
OP_MASK:
mask(init) = 0
mask(DISTINCT,SPLITERATOR[DISTINCT]=11,bitPosition=0) = 0000 0000 | 0000 0011 << 0 = 0000 0000 | 0000 0011 = 0000 0011
mask(SORTED,SPLITERATOR[SORTED]=11,bitPosition=2) = 0000 0011 | 0000 0011 << 2 = 0000 0011 | 0000 1100 = 0000 1111
mask(ORDERED,SPLITERATOR[ORDERED]=11,bitPosition=4) = 0000 1111 | 0000 0011 << 4 = 0000 1111 | 0011 0000 = 0011 1111
mask(SIZED,SPLITERATOR[SIZED]=10,bitPosition=6) = 0011 1111 | 0000 0010 << 6 = 0011 1111 | 1000 0000 = 1011 1111
mask(SHORT_CIRCUIT,SPLITERATOR[SHORT_CIRCUIT]=01,bitPosition=24) = 1011 1111 | 0000 0001 << 24 = 1011 1111 | 0100 0000 0000 0000 0000 0000 0000 = 0100 0000 0000 0000 0000 1011 1111
mask(final) = 0000 0000 1000 0000 0000 0000 1011 1111(二进制)、16777407(十进制)
TERMINAL_OP_MASK:
mask(init) = 0
mask(DISTINCT,SPLITERATOR[DISTINCT]=00,bitPosition=0) = 0000 0000 | 0000 0000 << 0 = 0000 0000 | 0000 0000 = 0000 0000
mask(SORTED,SPLITERATOR[SORTED]=00,bitPosition=2) = 0000 0000 | 0000 0000 << 2 = 0000 0000 | 0000 0000 = 0000 0000
mask(ORDERED,SPLITERATOR[ORDERED]=10,bitPosition=4) = 0000 0000 | 0000 0010 << 4 = 0000 0000 | 0010 0000 = 0010 0000
mask(SIZED,SPLITERATOR[SIZED]=00,bitPosition=6) = 0010 0000 | 0000 0000 << 6 = 0010 0000 | 0000 0000 = 0010 0000
mask(SHORT_CIRCUIT,SPLITERATOR[SHORT_CIRCUIT]=01,bitPosition=24) = 0010 0000 | 0000 0001 << 24 = 0010 0000 | 0001 0000 0000 0000 0000 0000 0000 = 0001 0000 0000 0000 0000 0010 0000
mask(final) = 0000 0001 0000 0000 0000 0000 0010 0000(二进制)、16777248(十进制)
UPSTREAM_TERMINAL_OP_MASK:
mask(init) = 0
mask(DISTINCT,SPLITERATOR[DISTINCT]=00,bitPosition=0) = 0000 0000 | 0000 0000 << 0 = 0000 0000 | 0000 0000 = 0000 0000
mask(SORTED,SPLITERATOR[SORTED]=00,bitPosition=2) = 0000 0000 | 0000 0000 << 2 = 0000 0000 | 0000 0000 = 0000 0000
mask(ORDERED,SPLITERATOR[ORDERED]=10,bitPosition=4) = 0000 0000 | 0000 0010 << 4 = 0000 0000 | 0010 0000 = 0010 0000
mask(SIZED,SPLITERATOR[SIZED]=00,bitPosition=6) = 0010 0000 | 0000 0000 << 6 = 0010 0000 | 0000 0000 = 0010 0000
mask(SHORT_CIRCUIT,SPLITERATOR[SHORT_CIRCUIT]=00,bitPosition=24) = 0010 0000 | 0000 0000 << 24 = 0010 0000 | 0000 0000 = 0010 0000
mask(final) = 0000 0000 0000 0000 0000 0000 0010 0000(二进制)、32(十进制)
|
The related methods and properties are as follows.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
|
enum StreamOpFlag {
// SPLITERATOR类型的标志bit map
static final int SPLITERATOR_CHARACTERISTICS_MASK = createMask(Type.SPLITERATOR);
// STREAM类型的标志bit map
static final int STREAM_MASK = createMask(Type.STREAM);
// OP类型的标志bit map
static final int OP_MASK = createMask(Type.OP);
// TERMINAL_OP类型的标志bit map
static final int TERMINAL_OP_MASK = createMask(Type.TERMINAL_OP);
// UPSTREAM_TERMINAL_OP类型的标志bit map
static final int UPSTREAM_TERMINAL_OP_MASK = createMask(Type.UPSTREAM_TERMINAL_OP);
// 基于Stream类型,创建对应类型填充所有标志的bit map
private static int createMask(Type t) {
int mask = 0;
for (StreamOpFlag flag : StreamOpFlag.values()) {
mask |= flag.maskTable.get(t) << flag.bitPosition;
}
return mask;
}
// 构造一个标志本身的掩码,就是所有标志都采用保留位表示,目前作为flags == 0时候的初始值
private static final int FLAG_MASK = createFlagMask();
// 构造一个包含全部标志中的preserve位的bit map,按照目前来看是暂时是一个固定值,二进制表示为0011 0000 0000 0000 0000 1111 1111
private static int createFlagMask() {
int mask = 0;
for (StreamOpFlag flag : StreamOpFlag.values()) {
mask |= flag.preserve;
}
return mask;
}
// 构造一个Stream类型包含全部标志中的set位的bit map,这里直接使用了STREAM_MASK,按照目前来看是暂时是一个固定值,二进制表示为0000 0000 0000 0000 0000 0000 0101 0101
private static final int FLAG_MASK_IS = STREAM_MASK;
// 构造一个Stream类型包含全部标志中的clear位的bit map,按照目前来看是暂时是一个固定值,二进制表示为0000 0000 0000 0000 0000 0000 1010 1010
private static final int FLAG_MASK_NOT = STREAM_MASK << 1;
// 初始化操作的标志bit map,目前来看就是Stream的头节点初始化时候需要合并在flags里面的初始化值,照目前来看是暂时是一个固定值,二进制表示为0000 0000 0000 0000 0000 0000 1111 1111
static final int INITIAL_OPS_VALUE = FLAG_MASK_IS | FLAG_MASK_NOT;
}
|
The 5 members of SPLITERATOR_CHARACTERISTICS_MASK (see the Mask calculation example above) are actually the bit map of all StreamOpFlag flags of the corresponding Stream entity type, which is the “horizontal” display of the mapping of the Stream’s type and flags.

The previous analysis has been relatively detailed and the process is very complex, but the more complex application of Mask is still in the later methods. the initialization of Mask is provided for the operation of merging (combine) and transforming (transforming from characteristics in Spliterator to flags) of flags, see the following methods.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
|
enum StreamOpFlag {
// 这个方法完全没有注释,只使用在下面的combineOpFlags()方法中
// 从源码来看
// 入参flags == 0的时候,那么直接返回0011 0000 0000 0000 0000 1111 1111
// 入参flags != 0的时候,那么会把当前flags的所有set/inject、clear和preserve所在位在bit map中全部置为0,然后其他位全部置为1
private static int getMask(int flags) {
return (flags == 0)
? FLAG_MASK
: ~(flags | ((FLAG_MASK_IS & flags) << 1) | ((FLAG_MASK_NOT & flags) >> 1));
}
// 合并新的flags和前一个flags,这里还是用到老套路先和Mask按位与,再进行一次按位或
// 作为Stream的头节点的时候,prevCombOpFlags必须为INITIAL_OPS_VALUE
static int combineOpFlags(int newStreamOrOpFlags, int prevCombOpFlags) {
// 0x01 or 0x10 nibbles are transformed to 0x11
// 0x00 nibbles remain unchanged
// Then all the bits are flipped
// Then the result is logically or'ed with the operation flags.
return (prevCombOpFlags & StreamOpFlag.getMask(newStreamOrOpFlags)) | newStreamOrOpFlags;
}
// 通过合并后的flags,转换出Stream类型的flags
static int toStreamFlags(int combOpFlags) {
// By flipping the nibbles 0x11 become 0x00 and 0x01 become 0x10
// Shift left 1 to restore set flags and mask off anything other than the set flags
return ((~combOpFlags) >> 1) & FLAG_MASK_IS & combOpFlags;
}
// Stream的标志转换为Spliterator的characteristics
static int toCharacteristics(int streamFlags) {
return streamFlags & SPLITERATOR_CHARACTERISTICS_MASK;
}
// Spliterator的characteristics转换为Stream的标志,入参是Spliterator实例
static int fromCharacteristics(Spliterator<?> spliterator) {
int characteristics = spliterator.characteristics();
if ((characteristics & Spliterator.SORTED) != 0 && spliterator.getComparator() != null) {
// Do not propagate the SORTED characteristic if it does not correspond
// to a natural sort order
return characteristics & SPLITERATOR_CHARACTERISTICS_MASK & ~Spliterator.SORTED;
}
else {
return characteristics & SPLITERATOR_CHARACTERISTICS_MASK;
}
}
// Spliterator的characteristics转换为Stream的标志,入参是Spliterator的characteristics
static int fromCharacteristics(int characteristics) {
return characteristics & SPLITERATOR_CHARACTERISTICS_MASK;
}
}
|
The bitwise operations here are complex, and only simple calculations and related functions are shown.
- combineOpFlags(): used to merge the new flags and the previous flags, because the data structure of Stream is a Pipeline, the successor node needs to merge the flags of the predecessor node, for example, the predecessor node flags is ORDERED.set, the current new node (successor node) that joins the Pipeline has new flags is SIZED.set, then the flags of the predecessor node should be merged in the successor node, simply imagine SIZED.set | ORDERED.set, if it is the head node, then the flags when initializing the head node should be merged INITIAL_OPS_VALUE, here is an example.
1
2
3
4
5
6
7
8
9
10
11
12
|
int left = ORDERED.set | DISTINCT.set;
int right = SIZED.clear | SORTED.clear;
System.out.println("left:" + Integer.toBinaryString(left));
System.out.println("right:" + Integer.toBinaryString(right));
System.out.println("right mask:" + Integer.toBinaryString(getMask(right)));
System.out.println("combine:" + Integer.toBinaryString(combineOpFlags(right, left)));
// 输出结果
left:1010001
right:10001000
right mask:11111111111111111111111100110011
combine:10011001
|
- The reason why the characteristics in Spliterator can be converted to flags by a simple bitwise conversion is that the characteristics in Spliterator are designed to match the StreamOpFlag, or to be precise, the bit map’s bit distribution is matched, so it can be done directly with SPLITERATOR_CHARACTERISTICS_MASK by bitwise conversion, see the following example.
1
2
3
4
|
// 这里简单点只展示8 bit
SPLITERATOR_CHARACTERISTICS_MASK: 0101 0101
Spliterator.ORDERED: 0001 0000
StreamOpFlag.ORDERED.set: 0001 0000
|
At this point, the complete implementation of StreamOpFlag has been analyzed, Mask-related methods are not intended to be expanded in detail, the following will begin to analyze the implementation of the “pipeline” structure in Stream, because of habit, the following two terms “flag” and “characteristics” will be mixed.
ReferencePipeline source code analysis
Since Stream has the characteristics of stream, it needs a chain data structure, so that the elements can “flow” from the Source all the way down and pass to each chain node, the common data structure to achieve this scenario is a two-way chain table (considering the need for backtracking, a one-way chain table is not suitable), the more famous implementations are AQS and Netty’s ChannelHandlerContext. For example, the pipeline ChannelPipeline in Netty is designed as follows.
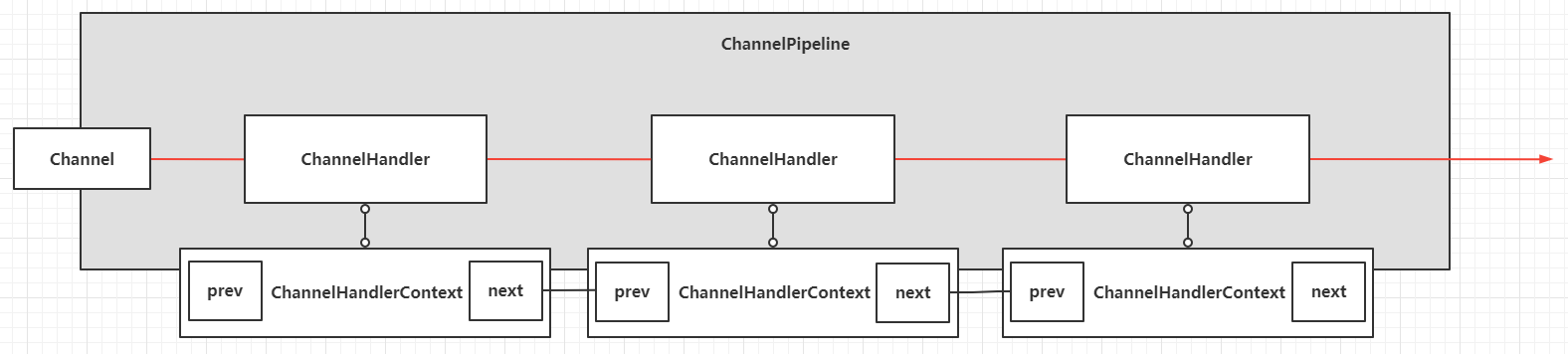
For this bi-directional linked table data structure, the corresponding class in Stream is AbstractPipeline, and the core implementation classes are in ReferencePipeline and ReferencePipeline’s internal classes.
Main interfaces
First, a brief demonstration of AbstractPipeline’s core parent class method definitions, the main parent classes are Stream, BaseStream and PipelineHelper.
- Stream represents a sequence of elements supporting serial and parallel aggregation operations. This top-level interface provides definitions for stream intermediate operations, termination operations and some static factory methods (too many to list here), which are essentially a builder-type interface (for picking up intermediate operations) and can form a chain of multiple intermediate operations and single termination operations, e.g.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
public interface Stream<T> extends BaseStream<T, Stream<T>> {
// 忽略其他代码
// 过滤Op
Stream<T> filter(Predicate<? super T> predicate);
// 映射Op
<R> Stream<R> map(Function<? super T, ? extends R> mapper);
// 终结操作 - 遍历
void forEach(Consumer<? super T> action);
// 忽略其他代码
}
// init
Stream x = buildStream();
// chain: head -> filter(Op) -> map(Op) -> forEach(Terminal Op)
x.filter().map().forEach()
|
- BaseStream: The basic interface of Stream, defining the iterator of streams, equivalent variants of streams (concurrent processing variants, synchronous processing variants and variants that do not support sequential processing of elements), concurrent and synchronous judgments and closing related methods
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
// T是元素类型,S是BaseStream<T, S>类型
// 流的基础接口,这里的流指定的支持同步执行和异步执行的聚合操作的元素序列
public interface BaseStream<T, S extends BaseStream<T, S>> extends AutoCloseable {
// 返回一个当前Stream实例中所有元素的迭代器
// 这是一个终结操作
Iterator<T> iterator();
// 返回一个当前Stream实例中所有元素的可拆分迭代器
Spliterator<T> spliterator();
// 当前的Stream实例是否支持并发
boolean isParallel();
// 返回一个等效的同步处理的Stream实例
S sequential();
// 返回一个等效的并发处理的Stream实例
S parallel();
// 返回一个等效的不支持StreamOpFlag.ORDERED特性的Stream实例
// 或者说支持StreamOpFlag.NOT_ORDERED的特性,也就返回的变体Stream在处理元素的时候不需要顺序处理
S unordered();
// 返回一个添加了close处理器的Stream实例,close处理器会在下面的close方法中回调
S onClose(Runnable closeHandler);
// 关闭当前Stream实例,回调关联本Stream的所有close处理器
@Override
void close();
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
abstract class PipelineHelper<P_OUT> {
// 获取流的流水线的数据源的"形状",其实就是数据源元素的类型
// 主要有四种类型:REFERENCE(除了int、long和double之外的引用类型)、INT_VALUE、LONG_VALUE和DOUBLE_VALUE
abstract StreamShape getSourceShape();
// 获取合并流和流操作的标志,合并的标志包括流的数据源标志、中间操作标志和终结操作标志
// 从实现上看是当前流管道节点合并前面所有节点和自身节点标志的所有标志
abstract int getStreamAndOpFlags();
// 如果当前的流管道节点的合并标志集合支持SIZED,则调用Spliterator.getExactSizeIfKnown()返回数据源中的准确元素数量,否则返回-1
abstract<P_IN> long exactOutputSizeIfKnown(Spliterator<P_IN> spliterator);
// 相当于调用下面的方法组合:copyInto(wrapSink(sink), spliterator)
abstract<P_IN, S extends Sink<P_OUT>> S wrapAndCopyInto(S sink, Spliterator<P_IN> spliterator);
// 发送所有来自Spliterator中的元素到Sink中,如果支持SHORT_CIRCUIT标志,则会调用copyIntoWithCancel
abstract<P_IN> void copyInto(Sink<P_IN> wrappedSink, Spliterator<P_IN> spliterator);
// 发送所有来自Spliterator中的元素到Sink中,Sink处理完每个元素后会检查Sink#cancellationRequested()方法的状态去判断是否中断推送元素的操作
abstract <P_IN> boolean copyIntoWithCancel(Sink<P_IN> wrappedSink, Spliterator<P_IN> spliterator);
// 创建接收元素类型为P_IN的Sink实例,实现PipelineHelper中描述的所有中间操作,用这个Sink去包装传入的Sink实例(传入的Sink实例的元素类型为PipelineHelper的输出类型P_OUT)
abstract<P_IN> Sink<P_IN> wrapSink(Sink<P_OUT> sink);
// 包装传入的spliterator,从源码来看,在Stream链的头节点调用会直接返回传入的实例,如果在非头节点调用会委托到StreamSpliterators.WrappingSpliterator()方法进行包装
// 这个方法在源码中没有API注释
abstract<P_IN> Spliterator<P_OUT> wrapSpliterator(Spliterator<P_IN> spliterator);
// 构造一个兼容当前Stream元素"形状"的Node.Builder实例
// 从源码来看直接委托到Nodes.builder()方法
abstract Node.Builder<P_OUT> makeNodeBuilder(long exactSizeIfKnown,
IntFunction<P_OUT[]> generator);
// Stream流水线所有阶段(节点)应用于数据源Spliterator,输出的元素作为结果收集起来转化为Node实例
// 此方法应用于toArray()方法的计算,本质上是一个终结操作
abstract<P_IN> Node<P_OUT> evaluate(Spliterator<P_IN> spliterator,
boolean flatten,
IntFunction<P_OUT[]> generator);
}
|
Note one thing (repeat 3 times).
- The synchronous stream is referred to here as a stream of synchronous processing|execution, and the “parallel stream” is referred to as a stream of concurrent processing|execution, because the parallel stream is ambiguous and is actually only concurrent execution, not parallel execution
- The synchronous stream is referred to here as a stream of synchronous processing|execution, and the “parallel stream” is referred to as a stream of concurrent processing|execution, because the parallel stream is ambiguous and is actually only concurrent execution, not parallel execution
- The synchronous stream is referred to here as a stream of synchronous processing|execution, and the “parallel stream” is referred to as a stream of concurrent processing|execution, because the parallel stream is ambiguous and is actually only concurrent execution, not parallel execution
Sink and reference type chains
The interface Sink exists in several methods of PipelineHelper, which was not analyzed in the previous section and will be expanded in this subsection. This is similar to a multi-layer wrapper programming model, simplified as follows.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
public class WrapperApp {
interface Wrapper {
void doAction();
}
public static void main(String[] args) {
AtomicInteger counter = new AtomicInteger(0);
Wrapper first = () -> System.out.printf("wrapper [depth => %d] invoke\n", counter.incrementAndGet());
Wrapper second = () -> {
first.doAction();
System.out.printf("wrapper [depth => %d] invoke\n", counter.incrementAndGet());
};
second.doAction();
}
}
// 控制台输出
wrapper [depth => 1] invoke
wrapper [depth => 2] invoke
|
The above example is a bit abrupt, and two different Sink implementations can be achieved without sensory integration, citing another example as follows.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
|
public interface Sink<T> extends Consumer<T> {
default void begin(long size) {
}
default void end() {
}
abstract class ChainedReference<T, OUT> implements Sink<T> {
protected final Sink<OUT> downstream;
public ChainedReference(Sink<OUT> downstream) {
this.downstream = downstream;
}
}
}
@SuppressWarnings({"unchecked", "rawtypes"})
public class ReferenceChain<OUT, R> {
/**
* sink chain
*/
private final List<Supplier<Sink<?>>> sinkBuilders = new ArrayList<>();
/**
* current sink
*/
private final AtomicReference<Sink> sinkReference = new AtomicReference<>();
public ReferenceChain<OUT, R> filter(Predicate<OUT> predicate) {
//filter
sinkBuilders.add(() -> {
Sink<OUT> prevSink = (Sink<OUT>) sinkReference.get();
Sink.ChainedReference<OUT, OUT> currentSink = new Sink.ChainedReference<>(prevSink) {
@Override
public void accept(OUT out) {
if (predicate.test(out)) {
downstream.accept(out);
}
}
};
sinkReference.set(currentSink);
return currentSink;
});
return this;
}
public ReferenceChain<OUT, R> map(Function<OUT, R> function) {
// map
sinkBuilders.add(() -> {
Sink<R> prevSink = (Sink<R>) sinkReference.get();
Sink.ChainedReference<OUT, R> currentSink = new Sink.ChainedReference<>(prevSink) {
@Override
public void accept(OUT in) {
downstream.accept(function.apply(in));
}
};
sinkReference.set(currentSink);
return currentSink;
});
return this;
}
public void forEachPrint(Collection<OUT> collection) {
forEachPrint(collection, false);
}
public void forEachPrint(Collection<OUT> collection, boolean reverse) {
Spliterator<OUT> spliterator = collection.spliterator();
// 这个是类似于terminal op
Sink<OUT> sink = System.out::println;
sinkReference.set(sink);
Sink<OUT> stage = sink;
// 反向包装 -> 正向遍历
if (reverse) {
for (int i = 0; i <= sinkBuilders.size() - 1; i++) {
Supplier<Sink<?>> supplier = sinkBuilders.get(i);
stage = (Sink<OUT>) supplier.get();
}
} else {
// 正向包装 -> 反向遍历
for (int i = sinkBuilders.size() - 1; i >= 0; i--) {
Supplier<Sink<?>> supplier = sinkBuilders.get(i);
stage = (Sink<OUT>) supplier.get();
}
}
Sink<OUT> finalStage = stage;
spliterator.forEachRemaining(finalStage);
}
public static void main(String[] args) {
List<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
list.add(12);
ReferenceChain<Integer, Integer> chain = new ReferenceChain<>();
// filter -> map -> for each
chain.filter(item -> item > 10)
.map(item -> item * 2)
.forEachPrint(list);
}
}
// 输出结果
24
|
The process of execution is as follows.
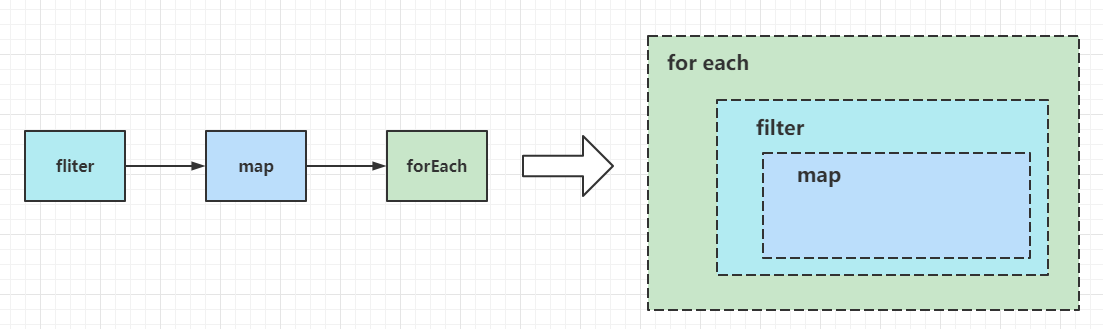
The central tenet of the multi-layer wrapper programming model is that
- the vast majority of operations can be converted to the implementation of java.util.function.Consumer, that is, the implementation of accept(T t) method to complete the processing of incoming elements
- The Sink processed first is always the Sink processed later as an input, in its own processing methods to determine and call back the incoming Sink processing method callback, that is, when building a reference chain, you need to build from back to front, the logic of this way of implementation can refer to AbstractPipeline#wrapSink(), for example.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
// 目标顺序:filter -> map
Sink mapSink = new Sink(inputSink){
private Function mapper;
public void accept(E ele) {
inputSink.accept(mapper.apply(ele))
}
}
Sink filterSink = new Sink(mapSink){
private Predicate predicate;
public void accept(E ele) {
if(predicate.test(ele)){
mapSink.accept(ele);
}
}
}
|
- From the above point, we know that, in general, the final termination operation is applied to the first Sink of the reference chain
The above code is not made up by the author and can be found in the source code of java.util.stream.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
|
// 继承自Consumer,主要是继承函数式接口方法void accept(T t)
interface Sink<T> extends Consumer<T> {
// 重置当前Sink的状态(为了接收一个新的数据集),传入的size是推送到downstream的准确数据量,无法评估数据量则传入-1
default void begin(long size) {}
//
default void end() {}
// 返回true的时候表示当前的Sink不会接收数据
default boolean cancellationRequested() {
return false;
}
// 特化方法,接受一个int类型的值
default void accept(int value) {
throw new IllegalStateException("called wrong accept method");
}
// 特化方法,接受一个long类型的值
default void accept(long value) {
throw new IllegalStateException("called wrong accept method");
}
// 特化方法,接受一个double类型的值
default void accept(double value) {
throw new IllegalStateException("called wrong accept method");
}
// 引用类型链,准确来说是Sink链
abstract static class ChainedReference<T, E_OUT> implements Sink<T> {
// 下一个Sink
protected final Sink<? super E_OUT> downstream;
public ChainedReference(Sink<? super E_OUT> downstream) {
this.downstream = Objects.requireNonNull(downstream);
}
@Override
public void begin(long size) {
downstream.begin(size);
}
@Override
public void end() {
downstream.end();
}
@Override
public boolean cancellationRequested() {
return downstream.cancellationRequested();
}
}
// 暂时忽略Int、Long、Double的特化类型场景
}
|
If you have used RxJava or Project-Reactor, Sink is more like Subscriber, multiple Subscribers form a ChainedReference (Sink Chain, which can be understood as a composite Subscriber), while Terminal Op is similar to Publisher, only when the Subscriber subscribes to the Publisher, the data will be processed, here is the application of Reactive programming model.
Implementation of AbstractPipeline and ReferencePipeline
AbstractPipeline and ReferencePipeline are both abstract classes. AbstractPipeline is used to build the data structure of Pipeline and provide some Shape-related abstract methods for ReferencePipeline to implement, while ReferencePipeline is the base type of Pipeline in Stream. From the source code, the head node and operation node of Stream chain (pipeline) structure are subclasses of ReferencePipeline. First look at the member variables and constructors of AbstractPipeline.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
|
abstract class AbstractPipeline<E_IN, E_OUT, S extends BaseStream<E_OUT, S>>
extends PipelineHelper<E_OUT> implements BaseStream<E_OUT, S> {
// 流管道链式结构的头节点(只有当前的AbstractPipeline引用是头节点,此变量才会被赋值,非头节点为NULL)
@SuppressWarnings("rawtypes")
private final AbstractPipeline sourceStage;
// 流管道链式结构的upstream,也就是上一个节点,如果是头节点此引用为NULL
@SuppressWarnings("rawtypes")
private final AbstractPipeline previousStage;
// 合并数据源的标志和操作标志的掩码
protected final int sourceOrOpFlags;
// 流管道链式结构的下一个节点,如果是头节点此引用为NULL
@SuppressWarnings("rawtypes")
private AbstractPipeline nextStage;
// 流的深度
// 串行执行的流中,表示当前流管道实例中中间操作节点的个数(除去头节点和终结操作)
// 并发执行的流中,表示当前流管道实例中中间操作节点和前一个有状态操作节点之间的节点个数
private int depth;
// 合并了所有数据源的标志、操作标志和当前的节点(AbstractPipeline)实例的标志,也就是当前的节点可以基于此属性得知所有支持的标志
private int combinedFlags;
// 数据源的Spliterator实例
private Spliterator<?> sourceSpliterator;
// 数据源的Spliterator实例封装的Supplier实例
private Supplier<? extends Spliterator<?>> sourceSupplier;
// 标记当前的流节点是否被连接或者消费掉,不能重复连接或者重复消费
private boolean linkedOrConsumed;
// 标记当前的流管道链式结构中是否存在有状态的操作节点,这个属性只会在头节点中有效
private boolean sourceAnyStateful;
// 数据源关闭动作,这个属性只会在头节点中有效,由sourceStage持有
private Runnable sourceCloseAction;
// 标记当前流是否并发执行
private boolean parallel;
// 流管道结构头节点的父构造方法,使用数据源的Spliterator实例封装的Supplier实例
AbstractPipeline(Supplier<? extends Spliterator<?>> source,
int sourceFlags, boolean parallel) {
// 头节点的前驱节点置为NULL
this.previousStage = null;
this.sourceSupplier = source;
this.sourceStage = this;
// 合并传入的源标志和流标志的掩码
this.sourceOrOpFlags = sourceFlags & StreamOpFlag.STREAM_MASK;
// The following is an optimization of:
// StreamOpFlag.combineOpFlags(sourceOrOpFlags, StreamOpFlag.INITIAL_OPS_VALUE);
// 初始化合并标志集合为sourceOrOpFlags和所有流操作标志的初始化值
this.combinedFlags = (~(sourceOrOpFlags << 1)) & StreamOpFlag.INITIAL_OPS_VALUE;
// 深度设置为0
this.depth = 0;
this.parallel = parallel;
}
// 流管道结构头节点的父构造方法,使用数据源的Spliterator实例
AbstractPipeline(Spliterator<?> source,
int sourceFlags, boolean parallel) {
// 头节点的前驱节点置为NULL
this.previousStage = null;
this.sourceSpliterator = source;
this.sourceStage = this;
// 合并传入的源标志和流标志的掩码
this.sourceOrOpFlags = sourceFlags & StreamOpFlag.STREAM_MASK;
// The following is an optimization of:
// StreamOpFlag.combineOpFlags(sourceOrOpFlags, StreamOpFlag.INITIAL_OPS_VALUE);
// 初始化合并标志集合为sourceOrOpFlags和所有流操作标志的初始化值
this.combinedFlags = (~(sourceOrOpFlags << 1)) & StreamOpFlag.INITIAL_OPS_VALUE;
this.depth = 0;
this.parallel = parallel;
}
// 流管道结构中间操作节点的父构造方法
AbstractPipeline(AbstractPipeline<?, E_IN, ?> previousStage, int opFlags) {
if (previousStage.linkedOrConsumed)
throw new IllegalStateException(MSG_STREAM_LINKED);
previousStage.linkedOrConsumed = true;
// 设置前驱节点的后继节点引用为当前的AbstractPipeline实例
previousStage.nextStage = this;
// 设置前驱节点引用为传入的前驱节点实例
this.previousStage = previousStage;
// 合并传入的中间操作标志和流操作标志的掩码
this.sourceOrOpFlags = opFlags & StreamOpFlag.OP_MASK;
// 合并标志集合为传入的标志和前驱节点的标志集合
this.combinedFlags = StreamOpFlag.combineOpFlags(opFlags, previousStage.combinedFlags);
// 赋值sourceStage为前驱节点的sourceStage
this.sourceStage = previousStage.sourceStage;
if (opIsStateful())
// 标记当前的流存在有状态操作
sourceStage.sourceAnyStateful = true;
// 深度设置为前驱节点深度加1
this.depth = previousStage.depth + 1;
}
// 省略其他方法
}
|
At this point, the data structure of the flow pipeline can be seen.
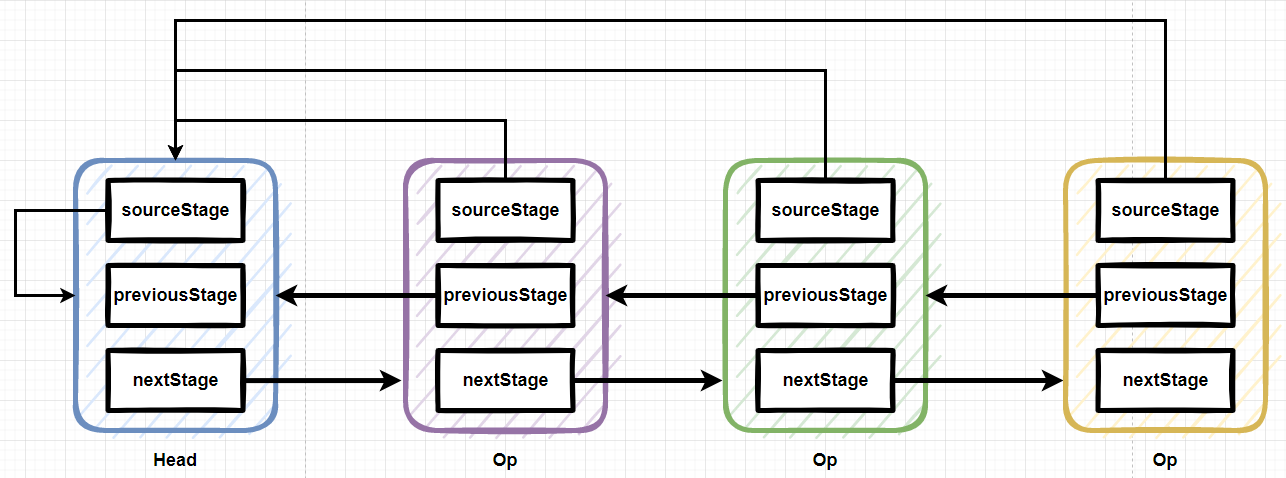
Terminal Op is not involved in the construction of the pipeline chain structure. Moving on to the Terminal evaluation methods in AbstractPipeline.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
|
abstract class AbstractPipeline<E_IN, E_OUT, S extends BaseStream<E_OUT, S>>
extends PipelineHelper<E_OUT> implements BaseStream<E_OUT, S> {
// 省略其他方法
// 基于终结操作进行求值,这个是Stream执行的常用核心方法,常用于collect()这类终结操作
final <R> R evaluate(TerminalOp<E_OUT, R> terminalOp) {
assert getOutputShape() == terminalOp.inputShape();
// 判断linkedOrConsumed,以防多次终结求值,也就是每个终结操作只能执行一次
if (linkedOrConsumed)
throw new IllegalStateException(MSG_STREAM_LINKED);
linkedOrConsumed = true;
// 如果当前流支持并发执行,则委托到TerminalOp.evaluateParallel(),如果当前流只支持同步执行,则委托到TerminalOp.evaluateSequential()
// 这里注意传入到TerminalOp中的方法参数分别是this(PipelineHelper类型)和数据源Spliterator
return isParallel()
? terminalOp.evaluateParallel(this, sourceSpliterator(terminalOp.getOpFlags()))
: terminalOp.evaluateSequential(this, sourceSpliterator(terminalOp.getOpFlags()));
}
// 基于当前的流实例转换为最终的Node实例,传入的IntFunction用于创建数组实例
// 此终结方法一般用于toArray()这类终结操作
@SuppressWarnings("unchecked")
final Node<E_OUT> evaluateToArrayNode(IntFunction<E_OUT[]> generator) {
if (linkedOrConsumed)
throw new IllegalStateException(MSG_STREAM_LINKED);
linkedOrConsumed = true;
// If the last intermediate operation is stateful then
// evaluate directly to avoid an extra collection step
// 当前流支持并发执行,并且最后一个中间操作是有状态,则委托到opEvaluateParallel(),否则委托到evaluate(),这两个都是AbstractPipeline中的方法
if (isParallel() && previousStage != null && opIsStateful()) {
// Set the depth of this, last, pipeline stage to zero to slice the
// pipeline such that this operation will not be included in the
// upstream slice and upstream operations will not be included
// in this slice
depth = 0;
return opEvaluateParallel(previousStage, previousStage.sourceSpliterator(0), generator);
}
else {
return evaluate(sourceSpliterator(0), true, generator);
}
}
// 这个方法比较简单,就是获取当前流的数据源所在的Spliterator,并且确保流已经消费,一般用于forEach()这类终结操作
final Spliterator<E_OUT> sourceStageSpliterator() {
if (this != sourceStage)
throw new IllegalStateException();
if (linkedOrConsumed)
throw new IllegalStateException(MSG_STREAM_LINKED);
linkedOrConsumed = true;
if (sourceStage.sourceSpliterator != null) {
@SuppressWarnings("unchecked")
Spliterator<E_OUT> s = sourceStage.sourceSpliterator;
sourceStage.sourceSpliterator = null;
return s;
}
else if (sourceStage.sourceSupplier != null) {
@SuppressWarnings("unchecked")
Spliterator<E_OUT> s = (Spliterator<E_OUT>) sourceStage.sourceSupplier.get();
sourceStage.sourceSupplier = null;
return s;
}
else {
throw new IllegalStateException(MSG_CONSUMED);
}
}
// 省略其他方法
}
|
The methods of BaseStream are implemented in AbstractPipeline.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
|
abstract class AbstractPipeline<E_IN, E_OUT, S extends BaseStream<E_OUT, S>>
extends PipelineHelper<E_OUT> implements BaseStream<E_OUT, S> {
// 省略其他方法
// 设置头节点的parallel属性为false,返回自身实例,表示当前的流是同步执行的
@Override
@SuppressWarnings("unchecked")
public final S sequential() {
sourceStage.parallel = false;
return (S) this;
}
// 设置头节点的parallel属性为true,返回自身实例,表示当前的流是并发执行的
@Override
@SuppressWarnings("unchecked")
public final S parallel() {
sourceStage.parallel = true;
return (S) this;
}
// 流关闭操作,设置linkedOrConsumed为true,数据源的Spliterator相关引用置为NULL,置空并且回调sourceCloseAction钩子实例
@Override
public void close() {
linkedOrConsumed = true;
sourceSupplier = null;
sourceSpliterator = null;
if (sourceStage.sourceCloseAction != null) {
Runnable closeAction = sourceStage.sourceCloseAction;
sourceStage.sourceCloseAction = null;
closeAction.run();
}
}
// 返回一个添加了close处理器的Stream实例,close处理器会在下面的close方法中回调
// 如果本来持有的引用sourceStage.sourceCloseAction非空,会使用传入的closeHandler与sourceStage.sourceCloseAction进行合并
@Override
@SuppressWarnings("unchecked")
public S onClose(Runnable closeHandler) {
if (linkedOrConsumed)
throw new IllegalStateException(MSG_STREAM_LINKED);
Objects.requireNonNull(closeHandler);
Runnable existingHandler = sourceStage.sourceCloseAction;
sourceStage.sourceCloseAction =
(existingHandler == null)
? closeHandler
: Streams.composeWithExceptions(existingHandler, closeHandler);
return (S) this;
}
// Primitive specialization use co-variant overrides, hence is not final
// 返回当前流实例中所有元素的Spliterator实例
@Override
@SuppressWarnings("unchecked")
public Spliterator<E_OUT> spliterator() {
if (linkedOrConsumed)
throw new IllegalStateException(MSG_STREAM_LINKED);
// 标记当前节点被链接或者消费
linkedOrConsumed = true;
// 如果当前节点为头节点,那么返回sourceStage.sourceSpliterator或者延时加载的sourceStage.sourceSupplier(延时加载封装由lazySpliterator实现)
if (this == sourceStage) {
if (sourceStage.sourceSpliterator != null) {
@SuppressWarnings("unchecked")
Spliterator<E_OUT> s = (Spliterator<E_OUT>) sourceStage.sourceSpliterator;
sourceStage.sourceSpliterator = null;
return s;
}
else if (sourceStage.sourceSupplier != null) {
@SuppressWarnings("unchecked")
Supplier<Spliterator<E_OUT>> s = (Supplier<Spliterator<E_OUT>>) sourceStage.sourceSupplier;
sourceStage.sourceSupplier = null;
return lazySpliterator(s);
}
else {
throw new IllegalStateException(MSG_CONSUMED);
}
}
else {
// 如果当前节点不是头节点,重新对sourceSpliterator进行包装,包装后的实例为WrappingSpliterator
return wrap(this, () -> sourceSpliterator(0), isParallel());
}
}
// 当前流实例是否并发执行,从头节点的parallel属性进行判断
@Override
public final boolean isParallel() {
return sourceStage.parallel;
}
// 从当前combinedFlags中获取数据源标志和所有流中间操作标志的集合
final int getStreamFlags() {
return StreamOpFlag.toStreamFlags(combinedFlags);
}
/**
* Get the source spliterator for this pipeline stage. For a sequential or
* stateless parallel pipeline, this is the source spliterator. For a
* stateful parallel pipeline, this is a spliterator describing the results
* of all computations up to and including the most recent stateful
* operation.
*/
@SuppressWarnings("unchecked")
private Spliterator<?> sourceSpliterator(int terminalFlags) {
// 从sourceStage.sourceSpliterator或者sourceStage.sourceSupplier中获取当前流实例中的Spliterator实例,确保必定存在,否则抛出IllegalStateException
Spliterator<?> spliterator = null;
if (sourceStage.sourceSpliterator != null) {
spliterator = sourceStage.sourceSpliterator;
sourceStage.sourceSpliterator = null;
}
else if (sourceStage.sourceSupplier != null) {
spliterator = (Spliterator<?>) sourceStage.sourceSupplier.get();
sourceStage.sourceSupplier = null;
}
else {
throw new IllegalStateException(MSG_CONSUMED);
}
// 下面这段逻辑是对于并发执行并且存在有状态操作的节点,那么需要重新计算节点的深度和节点的合并标志集合
// 这里只提一下计算过程,从头节点的后继节点开始遍历到当前节点,如果被遍历的节点时有状态的,那么对depth、combinedFlags和spliterator会进行重新计算
// depth一旦出现有状态节点就会重置为0,然后从1重新开始增加
// combinedFlags会重新合并sourceOrOpFlags、SHORT_CIRCUIT(如果sourceOrOpFlags支持)和Spliterator.SIZED
// spliterator简单来看就是从并发执行的toArray()=>Array数组=>Spliterator实例
if (isParallel() && sourceStage.sourceAnyStateful) {
// Adapt the source spliterator, evaluating each stateful op
// in the pipeline up to and including this pipeline stage.
// The depth and flags of each pipeline stage are adjusted accordingly.
int depth = 1;
for (@SuppressWarnings("rawtypes") AbstractPipeline u = sourceStage, p = sourceStage.nextStage, e = this;
u != e;
u = p, p = p.nextStage) {
int thisOpFlags = p.sourceOrOpFlags;
if (p.opIsStateful()) {
depth = 0;
if (StreamOpFlag.SHORT_CIRCUIT.isKnown(thisOpFlags)) {
// Clear the short circuit flag for next pipeline stage
// This stage encapsulates short-circuiting, the next
// stage may not have any short-circuit operations, and
// if so spliterator.forEachRemaining should be used
// for traversal
thisOpFlags = thisOpFlags & ~StreamOpFlag.IS_SHORT_CIRCUIT;
}
spliterator = p.opEvaluateParallelLazy(u, spliterator);
// Inject or clear SIZED on the source pipeline stage
// based on the stage's spliterator
thisOpFlags = spliterator.hasCharacteristics(Spliterator.SIZED)
? (thisOpFlags & ~StreamOpFlag.NOT_SIZED) | StreamOpFlag.IS_SIZED
: (thisOpFlags & ~StreamOpFlag.IS_SIZED) | StreamOpFlag.NOT_SIZED;
}
p.depth = depth++;
p.combinedFlags = StreamOpFlag.combineOpFlags(thisOpFlags, u.combinedFlags);
}
}
// 如果传入的terminalFlags标志不为0,则当前节点的combinedFlags会合并terminalFlags
if (terminalFlags != 0) {
// Apply flags from the terminal operation to last pipeline stage
combinedFlags = StreamOpFlag.combineOpFlags(terminalFlags, combinedFlags);
}
return spliterator;
}
// 省略其他方法
}
|
The methods of PipelineHelper are implemented in AbstractPipeline.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
|
abstract class AbstractPipeline<E_IN, E_OUT, S extends BaseStream<E_OUT, S>>
extends PipelineHelper<E_OUT> implements BaseStream<E_OUT, S> {
// 省略其他方法
// 获取数据源元素的类型,这里的类型包括引用、int、double和float
// 其实实现上就是获取depth<=0的第一个节点的输出类型
@Override
final StreamShape getSourceShape() {
@SuppressWarnings("rawtypes")
AbstractPipeline p = AbstractPipeline.this;
while (p.depth > 0) {
p = p.previousStage;
}
return p.getOutputShape();
}
// 基于当前节点的标志集合判断和返回流中待处理的元素数量,无法获取则返回-1
@Override
final <P_IN> long exactOutputSizeIfKnown(Spliterator<P_IN> spliterator) {
return StreamOpFlag.SIZED.isKnown(getStreamAndOpFlags()) ? spliterator.getExactSizeIfKnown() : -1;
}
// 通过流管道链式结构构建元素引用链,再遍历元素引用链
@Override
final <P_IN, S extends Sink<E_OUT>> S wrapAndCopyInto(S sink, Spliterator<P_IN> spliterator) {
copyInto(wrapSink(Objects.requireNonNull(sink)), spliterator);
return sink;
}
// 遍历元素引用链
@Override
final <P_IN> void copyInto(Sink<P_IN> wrappedSink, Spliterator<P_IN> spliterator) {
Objects.requireNonNull(wrappedSink);
// 当前节点不支持SHORT_CIRCUIT(短路)特性,则直接遍历元素引用链,不支持短路跳出
if (!StreamOpFlag.SHORT_CIRCUIT.isKnown(getStreamAndOpFlags())) {
wrappedSink.begin(spliterator.getExactSizeIfKnown());
spliterator.forEachRemaining(wrappedSink);
wrappedSink.end();
}
else {
// 支持短路(中途取消)遍历元素引用链
copyIntoWithCancel(wrappedSink, spliterator);
}
}
// 支持短路(中途取消)遍历元素引用链
@Override
@SuppressWarnings("unchecked")
final <P_IN> boolean copyIntoWithCancel(Sink<P_IN> wrappedSink, Spliterator<P_IN> spliterator) {
@SuppressWarnings({"rawtypes","unchecked"})
AbstractPipeline p = AbstractPipeline.this;
// 基于当前节点,获取流管道链式结构中第最后一个depth=0的前驱节点
while (p.depth > 0) {
p = p.previousStage;
}
wrappedSink.begin(spliterator.getExactSizeIfKnown());
// 委托到forEachWithCancel()进行遍历
boolean cancelled = p.forEachWithCancel(spliterator, wrappedSink);
wrappedSink.end();
return cancelled;
}
// 返回当前节点的标志集合
@Override
final int getStreamAndOpFlags() {
return combinedFlags;
}
// 当前节点标志集合中是否支持ORDERED
final boolean isOrdered() {
return StreamOpFlag.ORDERED.isKnown(combinedFlags);
}
// 构建元素引用链,生成一个多重包装的Sink(WrapSink),这里的逻辑可以看前面的分析章节
@Override
@SuppressWarnings("unchecked")
final <P_IN> Sink<P_IN> wrapSink(Sink<E_OUT> sink) {
Objects.requireNonNull(sink);
// 这里遍历的时候,总是从当前节点向前驱节点遍历,也就是传入的sink实例总是包裹在最里面一层执行
for ( @SuppressWarnings("rawtypes") AbstractPipeline p=AbstractPipeline.this; p.depth > 0; p=p.previousStage) {
sink = p.opWrapSink(p.previousStage.combinedFlags, sink);
}
return (Sink<P_IN>) sink;
}
// 包装数据源的Spliterator,如果depth=0,则直接返回sourceSpliterator,否则返回的是延迟加载的WrappingSpliterator
@Override
@SuppressWarnings("unchecked")
final <P_IN> Spliterator<E_OUT> wrapSpliterator(Spliterator<P_IN> sourceSpliterator) {
if (depth == 0) {
return (Spliterator<E_OUT>) sourceSpliterator;
}
else {
return wrap(this, () -> sourceSpliterator, isParallel());
}
}
// 计算Node实例,这个方法用于toArray()方法系列,是一个终结操作,下面会另开章节详细分析
@Override
@SuppressWarnings("unchecked")
final <P_IN> Node<E_OUT> evaluate(Spliterator<P_IN> spliterator,
boolean flatten,
IntFunction<E_OUT[]> generator) {
if (isParallel()) {
// @@@ Optimize if op of this pipeline stage is a stateful op
return evaluateToNode(this, spliterator, flatten, generator);
}
else {
Node.Builder<E_OUT> nb = makeNodeBuilder(
exactOutputSizeIfKnown(spliterator), generator);
return wrapAndCopyInto(nb, spliterator).build();
}
}
// 省略其他方法
}
|
The remaining abstract methods in AbstractPipeline to be implemented by subclasses such as XXYYZZPipeline.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
|
abstract class AbstractPipeline<E_IN, E_OUT, S extends BaseStream<E_OUT, S>>
extends PipelineHelper<E_OUT> implements BaseStream<E_OUT, S> {
// 省略其他方法
// 获取当前流的输出"形状",REFERENCE、INT_VALUE、LONG_VALUE或者DOUBLE_VALUE
abstract StreamShape getOutputShape();
// 收集当前流的所有输出元素,转化为一个适配当前流输出"形状"的Node实例
abstract <P_IN> Node<E_OUT> evaluateToNode(PipelineHelper<E_OUT> helper,
Spliterator<P_IN> spliterator,
boolean flattenTree,
IntFunction<E_OUT[]> generator);
// 包装Spliterator为WrappingSpliterator实例
abstract <P_IN> Spliterator<E_OUT> wrap(PipelineHelper<E_OUT> ph,
Supplier<Spliterator<P_IN>> supplier,
boolean isParallel);
// 包装Spliterator为DelegatingSpliterator实例
abstract <P_IN> Spliterator<E_OUT> wrap(PipelineHelper<E_OUT> ph,
Supplier<Spliterator<P_IN>> supplier,
boolean isParallel);
// 基于Sink遍历Spliterator中的元素,支持取消操作,简单理解就是支持cancel的tryAdvance方法
abstract boolean forEachWithCancel(Spliterator<E_OUT> spliterator, Sink<E_OUT> sink);
// 返回Node的建造器实例,用于toArray方法系列
abstract Node.Builder<E_OUT> makeNodeBuilder(long exactSizeIfKnown,
IntFunction<E_OUT[]> generator);
// 判断当前的操作(节点)是否有状态,如果是有状态的操作,必须覆盖opEvaluateParallel方法
abstract boolean opIsStateful();
// 当前操作生成的结果会作为传入的Sink实例的入参,这是一个包装Sink的过程,通俗理解就是之前提到的元素引用链添加一个新的链节点,这个方法算是流执行的一个核心方法
abstract Sink<E_IN> opWrapSink(int flags, Sink<E_OUT> sink);
// 并发执行的操作节点求值
<P_IN> Node<E_OUT> opEvaluateParallel(PipelineHelper<E_OUT> helper,
Spliterator<P_IN> spliterator,
IntFunction<E_OUT[]> generator) {
throw new UnsupportedOperationException("Parallel evaluation is not supported");
}
// 并发执行的操作节点惰性求值
@SuppressWarnings("unchecked")
<P_IN> Spliterator<E_OUT> opEvaluateParallelLazy(PipelineHelper<E_OUT> helper,
Spliterator<P_IN> spliterator) {
return opEvaluateParallel(helper, spliterator, i -> (E_OUT[]) new Object[i]).spliterator();
}
// 省略其他方法
}
|
The abstract method opWrapSink() mentioned here is actually the method of adding a chain node to the element reference chain, and its implementation logic is shown in the subclasses, and only part of the source code of the non-specialized subclass ReferencePipeline is considered here.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
|
abstract class ReferencePipeline<P_IN, P_OUT>
extends AbstractPipeline<P_IN, P_OUT, Stream<P_OUT>>
implements Stream<P_OUT> {
// 构造函数,用于头节点,传入基于Supplier封装的Spliterator实例作为数据源,数据源的标志集合和是否支持并发执行的判断标记
ReferencePipeline(Supplier<? extends Spliterator<?>> source,
int sourceFlags, boolean parallel) {
super(source, sourceFlags, parallel);
}
// 构造函数,用于头节点,传入Spliterator实例作为数据源,数据源的标志集合和是否支持并发执行的判断标记
ReferencePipeline(Spliterator<?> source,
int sourceFlags, boolean parallel) {
super(source, sourceFlags, parallel);
}
// 构造函数,用于中间节点,传入上一个流管道节点的实例(前驱节点)和当前操作节点支持的标志集合
ReferencePipeline(AbstractPipeline<?, P_IN, ?> upstream, int opFlags) {
super(upstream, opFlags);
}
// 这里流的输出"形状"固定为REFERENCE
@Override
final StreamShape getOutputShape() {
return StreamShape.REFERENCE;
}
// 转换当前流实例为Node实例,应用于toArray方法,后面详细分析终结操作的时候再展开
@Override
final <P_IN> Node<P_OUT> evaluateToNode(PipelineHelper<P_OUT> helper,
Spliterator<P_IN> spliterator,
boolean flattenTree,
IntFunction<P_OUT[]> generator) {
return Nodes.collect(helper, spliterator, flattenTree, generator);
}
// 包装Spliterator=>WrappingSpliterator
@Override
final <P_IN> Spliterator<P_OUT> wrap(PipelineHelper<P_OUT> ph,
Supplier<Spliterator<P_IN>> supplier,
boolean isParallel) {
return new StreamSpliterators.WrappingSpliterator<>(ph, supplier, isParallel);
}
// 包装Spliterator=>DelegatingSpliterator,实现惰性加载
@Override
final Spliterator<P_OUT> lazySpliterator(Supplier<? extends Spliterator<P_OUT>> supplier) {
return new StreamSpliterators.DelegatingSpliterator<>(supplier);
}
// 遍历Spliterator中的元素,基于传入的Sink实例进行处理,支持Cancel操作
@Override
final boolean forEachWithCancel(Spliterator<P_OUT> spliterator, Sink<P_OUT> sink) {
boolean cancelled;
do { } while (!(cancelled = sink.cancellationRequested()) && spliterator.tryAdvance(sink));
return cancelled;
}
// 构造Node建造器实例
@Override
final Node.Builder<P_OUT> makeNodeBuilder(long exactSizeIfKnown, IntFunction<P_OUT[]> generator) {
return Nodes.builder(exactSizeIfKnown, generator);
}
// 基于当前流的Spliterator生成迭代器实例
@Override
public final Iterator<P_OUT> iterator() {
return Spliterators.iterator(spliterator());
}
// 省略其他OP的代码
// 流管道结构的头节点
static class Head<E_IN, E_OUT> extends ReferencePipeline<E_IN, E_OUT> {
// 构造函数,用于头节点,传入基于Supplier封装的Spliterator实例作为数据源,数据源的标志集合和是否支持并发执行的判断标记
Head(Supplier<? extends Spliterator<?>> source,
int sourceFlags, boolean parallel) {
super(source, sourceFlags, parallel);
}
// 构造函数,用于头节点,传入Spliterator实例作为数据源,数据源的标志集合和是否支持并发执行的判断标记
Head(Spliterator<?> source,
int sourceFlags, boolean parallel) {
super(source, sourceFlags, parallel);
}
// 不支持判断是否状态操作
@Override
final boolean opIsStateful() {
throw new UnsupportedOperationException();
}
// 不支持包装Sink实例
@Override
final Sink<E_IN> opWrapSink(int flags, Sink<E_OUT> sink) {
throw new UnsupportedOperationException();
}
// 区分同步异步执行forEach,同步则简单理解为调用Spliterator.forEachRemaining,异步则调用终结操作forEach
@Override
public void forEach(Consumer<? super E_OUT> action) {
if (!isParallel()) {
sourceStageSpliterator().forEachRemaining(action);
}
else {
super.forEach(action);
}
}
// 区分同步异步执行forEachOrdered,同步则简单理解为调用Spliterator.forEachRemaining,异步则调用终结操作forEachOrdered
@Override
public void forEachOrdered(Consumer<? super E_OUT> action) {
if (!isParallel()) {
sourceStageSpliterator().forEachRemaining(action);
}
else {
super.forEachOrdered(action);
}
}
}
// 无状态操作节点的父类
abstract static class StatelessOp<E_IN, E_OUT>
extends ReferencePipeline<E_IN, E_OUT> {
// 基于上一个节点引用、输入元素"形状"和当前节点支持的标志集合创建StatelessOp实例
StatelessOp(AbstractPipeline<?, E_IN, ?> upstream,
StreamShape inputShape,
int opFlags) {
super(upstream, opFlags);
assert upstream.getOutputShape() == inputShape;
}
// 操作状态标记设置为无状态
@Override
final boolean opIsStateful() {
return false;
}
}
// 有状态操作节点的父类
abstract static class StatefulOp<E_IN, E_OUT>
extends ReferencePipeline<E_IN, E_OUT> {
// 基于上一个节点引用、输入元素"形状"和当前节点支持的标志集合创建StatefulOp实例
StatefulOp(AbstractPipeline<?, E_IN, ?> upstream,
StreamShape inputShape,
int opFlags) {
super(upstream, opFlags);
assert upstream.getOutputShape() == inputShape;
}
// 操作状态标记设置为有状态
@Override
final boolean opIsStateful() {
return true;
}
// 前面也提到,节点操作异步求值的方法在无状态节点下必须覆盖,这里重新把这个方法抽象,子类必须实现
@Override
abstract <P_IN> Node<E_OUT> opEvaluateParallel(PipelineHelper<E_OUT> helper,
Spliterator<P_IN> spliterator,
IntFunction<E_OUT[]> generator);
}
}
|
Here is a heavy focus on the implementation of the wrapSink method in the ReferencePipeline.
1
2
3
4
5
6
7
8
|
final <P_IN> Sink<P_IN> wrapSink(Sink<E_OUT> sink) {
Objects.requireNonNull(sink);
for ( @SuppressWarnings("rawtypes") AbstractPipeline p=AbstractPipeline.this; p.depth > 0; p=p.previousStage) {
sink = p.opWrapSink(p.previousStage.combinedFlags, sink);
}
return (Sink<P_IN>) sink;
}
|
The input is a Sink instance, and the return value is also a Sink instance. The for loop inside is based on the current AbstractPipeline node traversing forward until the node with depth 0 jumps out of the loop, and depth 0 means that the node must be the head node, that is, the loop is traversing the current node to the successor node of the head node, and Sink is Sink is “forward wrapped”, that is, the node Sink at the back of the chain will always be used as an input to the opWrapSink() method of its predecessor node. When the stream value calculation is executed synchronously, the Sink of the predecessor node will call its accept through the downstream reference after processing the elements (actually, the Sink of the predecessor node ) will call its accept() to pass in the element or the result of the processed element to activate the next Sink, and so on. In addition, the three internal classes of ReferencePipeline, Head, StatelessOp and StatefulOp, are the node classes of the stream, where only Head is a non-abstract class representing the head node of the stream pipeline structure (or bidirectional chain table structure). StatelessOp (stateless operations) and StatefulOp (stateful operations) subclasses constitute the operation nodes or end operations of the stream pipeline structure. In ignoring the premise of whether there is a state operation to see ReferencePipeline, it is only the carrier of the stream data structure, the apparent bi-directional chain table structure seen in the stream value calculation process does not directly traverse each node for value, but first transformed into a multi-layer packaging Sink, which is the latter element reference chain mentioned by the author in the previous sentence of the analysis Sink element processing and delivery, correctly speaking, should be a Sink stack or Sink wrapper, its implementation can be analogous to the real-life onion, or the programming model of the AOP programming model. A more graphic description is as follows.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
Head(Spliterator) -> Op(filter) -> Op(map) -> Op(sorted) -> Terminal Op(forEach)
↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓
forEach ele in Spliterator:
Sink[filter](ele){
if filter process == true:
Sink[map](ele){
ele = mapper(ele)
Sink[sorted](ele){
var array
begin:
accept(ele):
add ele to array
end:
sort ele in array
}
}
}
|
The termination operation forEach is by far the simplest implementation in the analyzed source code, and the implementation details of each termination operation will be analyzed in detail below.
Due to the limitation of space, only a part of the intermediate Op can be analyzed here. The intermediate operations of streams are basically defined by the BaseStream interface and implemented in the ReferencePipeline, here we select the more commonly used filter, map and sorted for analysis. Let’s look at filter first.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
abstract class ReferencePipeline<P_IN, P_OUT>
extends AbstractPipeline<P_IN, P_OUT, Stream<P_OUT>>
implements Stream<P_OUT> {
// 暂时省略其他代码
// filter操作,泛型参数Predicate类型接受一个任意类型(这里考虑到泛型擦除)的元素,输出布尔值,它是一个无状态操作
@Override
public final Stream<P_OUT> filter(Predicate<? super P_OUT> predicate) {
Objects.requireNonNull(predicate);
// 这里注意到,StatelessOp的第一个参数是指upstream,也就是理解为上一个节点,这里使用了this,意味着upstream为当前的ReferencePipeline实例,元素"形状"为引用类型,操作标志位不支持SIZED
// 在AbstractPipeline,previousStage指向了this,当前的节点就是StatelessOp[filter]实例,那么前驱节点this的后继节点引用nextStage就指向了StatelessOp[filter]实例
// 也就是StatelessOp[filter].previousStage = this; this.nextStage = StatelessOp[filter]; ===> 也就是这个看起来简单的new StatelessOp()其实已经把自身加入到管道中
return new StatelessOp<P_OUT, P_OUT>(this, StreamShape.REFERENCE,
StreamOpFlag.NOT_SIZED) {
@Override
Sink<P_OUT> opWrapSink(int flags, Sink<P_OUT> sink) {
return new Sink.ChainedReference<P_OUT, P_OUT>(sink) {
@Override
public void begin(long size) {
// 这里通知下一个节点的Sink.begin(),由于filter方法不感知元素数量,所以传值-1
downstream.begin(-1);
}
@Override
public void accept(P_OUT u) {
// 基于输入的Predicate实例判断当前处理元素是否符合判断,只有判断结果为true才会把元素原封不动直接传递到下一个Sink
if (predicate.test(u))
downstream.accept(u);
}
};
}
};
}
// 暂时省略其他代码
}
|
Next is Map.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
abstract class ReferencePipeline<P_IN, P_OUT>
extends AbstractPipeline<P_IN, P_OUT, Stream<P_OUT>>
implements Stream<P_OUT> {
// 暂时省略其他代码
// map操作,基于传入的Function实例做映射转换(P_OUT->R),它是一个无状态操作
@Override
@SuppressWarnings("unchecked")
public final <R> Stream<R> map(Function<? super P_OUT, ? extends R> mapper) {
Objects.requireNonNull(mapper);
// upstream为当前的ReferencePipeline实例,元素"形状"为引用类型,操作标志位不支持SORTED和DISTINCT
return new StatelessOp<P_OUT, R>(this, StreamShape.REFERENCE,
StreamOpFlag.NOT_SORTED | StreamOpFlag.NOT_DISTINCT) {
@Override
Sink<P_OUT> opWrapSink(int flags, Sink<R> sink) {
return new Sink.ChainedReference<P_OUT, R>(sink) {
@Override
public void accept(P_OUT u) {
// 基于传入的Function实例转换元素后把转换结果传递到下一个Sink
downstream.accept(mapper.apply(u));
}
};
}
};
}
// 暂时省略其他代码
}
|
Then comes sorted, which is a relatively complex operation.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
|
abstract class ReferencePipeline<P_IN, P_OUT>
extends AbstractPipeline<P_IN, P_OUT, Stream<P_OUT>>
implements Stream<P_OUT> {
// 暂时省略其他代码
// sorted操作,基于传入的Comparator实例对处理的元素进行排序,从源码中看,它是一个有状态操作
@Override
public final Stream<P_OUT> sorted(Comparator<? super P_OUT> comparator) {
return SortedOps.makeRef(this, comparator);
}
// 暂时省略其他代码
}
// SortedOps工具类
final class SortedOps {
// 暂时省略其他代码
// 构建排序操作的链节点
static <T> Stream<T> makeRef(AbstractPipeline<?, T, ?> upstream,
Comparator<? super T> comparator) {
return new OfRef<>(upstream, comparator);
}
// 有状态的排序操作节点
private static final class OfRef<T> extends ReferencePipeline.StatefulOp<T, T> {
// 是否自然排序,不定义Comparator实例的时候为true,否则为false
private final boolean isNaturalSort;
// 用于排序的Comparator实例
private final Comparator<? super T> comparator;
// 自然排序情况下的构造方法,元素"形状"为引用类型,操作标志位不支持ORDERED和SORTED
OfRef(AbstractPipeline<?, T, ?> upstream) {
super(upstream, StreamShape.REFERENCE,
StreamOpFlag.IS_ORDERED | StreamOpFlag.IS_SORTED);
this.isNaturalSort = true;
// Comparator实例赋值为Comparator.naturalOrder(),本质是基于Object中的equals或者子类覆盖Object中的equals方法进行元素排序
@SuppressWarnings("unchecked")
Comparator<? super T> comp = (Comparator<? super T>) Comparator.naturalOrder();
this.comparator = comp;
}
// 非自然排序情况下的构造方法,需要传入Comparator实例,元素"形状"为引用类型,操作标志位不支持ORDERED和SORTED
OfRef(AbstractPipeline<?, T, ?> upstream, Comparator<? super T> comparator) {
super(upstream, StreamShape.REFERENCE,
StreamOpFlag.IS_ORDERED | StreamOpFlag.NOT_SORTED);
this.isNaturalSort = false;
this.comparator = Objects.requireNonNull(comparator);
}
@Override
public Sink<T> opWrapSink(int flags, Sink<T> sink) {
Objects.requireNonNull(sink);
// If the input is already naturally sorted and this operation
// also naturally sorted then this is a no-op
// 流中的所有元素本身已经按照自然顺序排序,并且没有定义Comparator实例,则不需要进行排序,所以no op就行
if (StreamOpFlag.SORTED.isKnown(flags) && isNaturalSort)
return sink;
else if (StreamOpFlag.SIZED.isKnown(flags))
// 知道要处理的元素的确切数量,使用数组进行排序
return new SizedRefSortingSink<>(sink, comparator);
else
// 不知道要处理的元素的确切数量,使用ArrayList进行排序
return new RefSortingSink<>(sink, comparator);
}
// 这里是并行执行流中toArray方法的实现,暂不分析
@Override
public <P_IN> Node<T> opEvaluateParallel(PipelineHelper<T> helper,
Spliterator<P_IN> spliterator,
IntFunction<T[]> generator) {
// If the input is already naturally sorted and this operation
// naturally sorts then collect the output
if (StreamOpFlag.SORTED.isKnown(helper.getStreamAndOpFlags()) && isNaturalSort) {
return helper.evaluate(spliterator, false, generator);
}
else {
// @@@ Weak two-pass parallel implementation; parallel collect, parallel sort
T[] flattenedData = helper.evaluate(spliterator, true, generator).asArray(generator);
Arrays.parallelSort(flattenedData, comparator);
return Nodes.node(flattenedData);
}
}
}
// 这里考虑到篇幅太长,SizedRefSortingSink和RefSortingSink的源码不复杂,只展开RefSortingSink进行分析
// 无法确认待处理元素确切数量时候用于元素排序的Sink实现
private static final class RefSortingSink<T> extends AbstractRefSortingSink<T> {
// 临时ArrayList实例
private ArrayList<T> list;
// 构造函数,需要的参数为下一个Sink引用和Comparator实例
RefSortingSink(Sink<? super T> sink, Comparator<? super T> comparator) {
super(sink, comparator);
}
@Override
public void begin(long size) {
if (size >= Nodes.MAX_ARRAY_SIZE)
throw new IllegalArgumentException(Nodes.BAD_SIZE);
// 基于传入的size是否大于0,大于等于0用于作为initialCapacity构建ArrayList,小于0则构建默认initialCapacity的ArrayList,赋值到临时变量list
list = (size >= 0) ? new ArrayList<>((int) size) : new ArrayList<>();
}
@Override
public void end() {
// 临时的ArrayList实例基于Comparator实例进行潘旭
list.sort(comparator);
// 下一个Sink节点的激活,区分是否支持取消操作
downstream.begin(list.size());
if (!cancellationRequestedCalled) {
list.forEach(downstream::accept);
}
else {
for (T t : list) {
if (downstream.cancellationRequested()) break;
downstream.accept(t);
}
}
downstream.end();
// 激活下一个Sink完成后,临时的ArrayList实例置为NULL,便于GC回收
list = null;
}
@Override
public void accept(T t) {
// 当前Sink处理元素直接添加到临时的ArrayList实例
list.add(t);
}
}
// 暂时省略其他代码
}
|
The sorted operation has a distinctive feature: a normal Sink will activate the next Sink reference in the accept() method after processing its own logic, but it only does the accumulation of elements (element enrichment) in the accept() method, the final sorting operation in the end() method and the two element traversal methods that mimic Spliterator to downstream to push the elements to be processed. The schematic diagram is as follows.
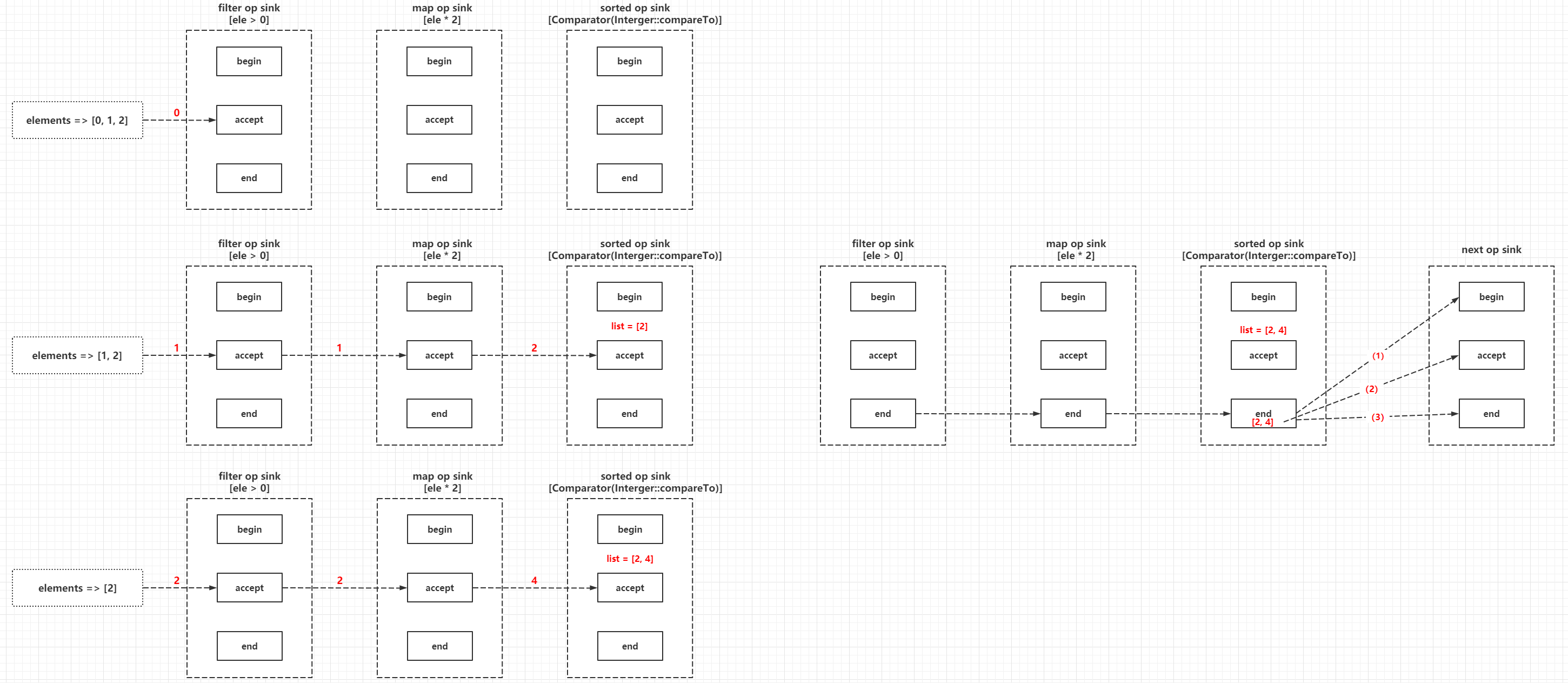
The implementation logic for the other intermediate operations is roughly the same.
Source code implementation of synchronous execution of stream termination operations
Due to the limitation of space, only a part of the Terminal Op can be selected here for analysis, and for simplicity, only the scenario of synchronous execution is analyzed, and the most typical and complex froEach() and collect() are selected here, as well as the more unique toArray() method. First look at the implementation of the froEach() method.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
|
abstract class ReferencePipeline<P_IN, P_OUT>
extends AbstractPipeline<P_IN, P_OUT, Stream<P_OUT>>
implements Stream<P_OUT> {
// 暂时省略其他代码
// 遍历元素
@Override
public void forEach(Consumer<? super P_OUT> action) {
evaluate(ForEachOps.makeRef(action, false));
}
// 暂时省略其他代码
// 基于终结操作的求值方法
final <R> R evaluate(TerminalOp<E_OUT, R> terminalOp) {
assert getOutputShape() == terminalOp.inputShape();
// 确保只会执行一次,linkedOrConsumed是流管道结构最后一个节点的属性
if (linkedOrConsumed)
throw new IllegalStateException(MSG_STREAM_LINKED);
linkedOrConsumed = true;
// 这里暂且只分析同步执行的流的终结操作,终结操作节点的标志会合并到流最后一个节点的combinedFlags中,执行的关键就是evaluateSequential方法
return isParallel()
? terminalOp.evaluateParallel(this, sourceSpliterator(terminalOp.getOpFlags()))
: terminalOp.evaluateSequential(this, sourceSpliterator(terminalOp.getOpFlags()));
}
// 暂时省略其他代码
}
// ForEachOps类,TerminalOp接口的定义比较简单,这里不展开
final class ForEachOps {
// 暂时省略其他代码
// 构造变量元素的终结操作实例,传入的元素是T类型,结果是Void类型(返回NULL,或者说是没有返回值,毕竟是一个元素遍历过程)
// 参数为一个Consumer接口实例和一个标记是否顺序处理元素的布尔值
public static <T> TerminalOp<T, Void> makeRef(Consumer<? super T> action,
boolean ordered) {
Objects.requireNonNull(action);
return new ForEachOp.OfRef<>(action, ordered);
}
// 遍历元素操作的终结操作实现,同时它是一个适配器,适配TerminalSink(Sink)接口
abstract static class ForEachOp<T>
implements TerminalOp<T, Void>, TerminalSink<T, Void> {
// 标记是否顺序处理元素
private final boolean ordered;
protected ForEachOp(boolean ordered) {
this.ordered = ordered;
}
// TerminalOp
// 终结操作节点的标志集合,如果ordered为true则返回0,否则返回StreamOpFlag.NOT_ORDERED,表示不支持顺序处理元素
@Override
public int getOpFlags() {
return ordered ? 0 : StreamOpFlag.NOT_ORDERED;
}
// 同步遍历和处理元素
@Override
public <S> Void evaluateSequential(PipelineHelper<T> helper,
Spliterator<S> spliterator) {
// 以当前的ForEachOp实例作为最后一个Sink添加到Sink链(也就是前面经常说的元素引用链),然后对Sink链进行遍历
return helper.wrapAndCopyInto(this, spliterator).get();
}
// 并发遍历和处理元素,这里暂不分析
@Override
public <S> Void evaluateParallel(PipelineHelper<T> helper,
Spliterator<S> spliterator) {
if (ordered)
new ForEachOrderedTask<>(helper, spliterator, this).invoke();
else
new ForEachTask<>(helper, spliterator, helper.wrapSink(this)).invoke();
return null;
}
// TerminalSink
// 实现TerminalSink的方法,实际上TerminalSink继承接口Supplier,这里是实现了Supplier接口的get()方法,由于PipelineHelper.wrapAndCopyInto()方法会返回最后一个Sink的引用,这里其实就是evaluateSequential()中的返回值
@Override
public Void get() {
return null;
}
// ForEachOp的静态内部类,引用类型的ForEachOp的最终实现,依赖入参遍历元素处理的最后一步回调Consumer实例
static final class OfRef<T> extends ForEachOp<T> {
// 最后的遍历回调的Consumer句柄
final Consumer<? super T> consumer;
OfRef(Consumer<? super T> consumer, boolean ordered) {
super(ordered);
this.consumer = consumer;
}
@Override
public void accept(T t) {
// 遍历元素回调操作
consumer.accept(t);
}
}
}
}
|
forEach terminal operation implementation, itself this operation will not form part of the chain structure of the stream, that is, it is not a subclass instance of AbstractPipeline, but to build a callback Consumer instance operation of a Sink instance (TerminalSink to be exact) instance, here for the time being called forEach terminal sink, add the forEach terminal sink to the end of the Sink chain through the wrapSink() method of the last operation node of the stream, traverse the elements through the copyInto() method of the last operation node of the stream, and follow the set of copyInto() methods, as long as the multi-layer wrapped Sink method always activates the downstream premise when calling back its implementation method, the order of execution is the order of operation nodes defined by the stream chain structure, and the Consumer instance added at the end of the forEach must be the last one called back.
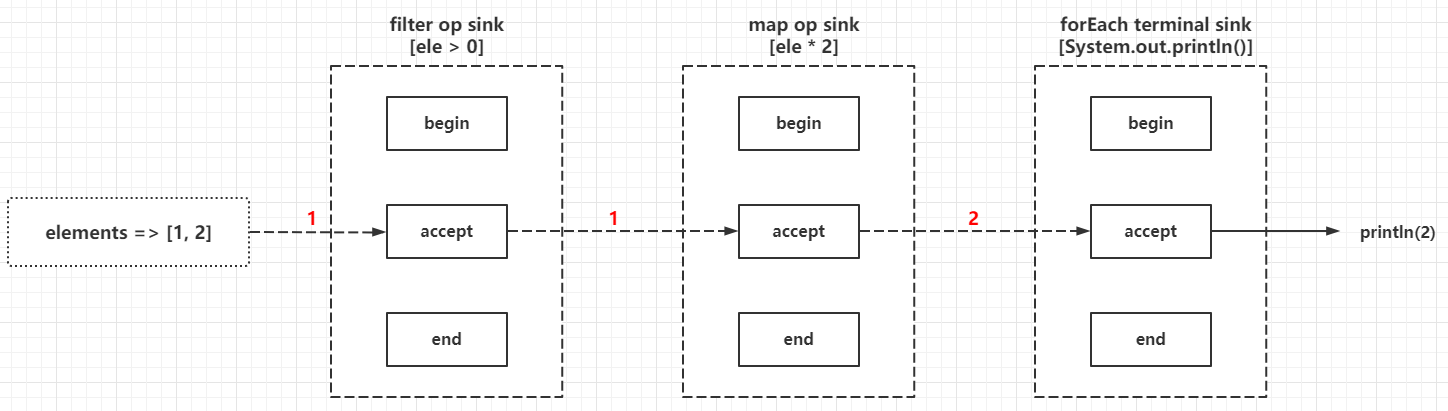
Moving on to the analysis of the implementation of the collect() method, let’s first look at the definition of the Collector interface.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
|
// T:需要进行reduce操作的输入元素类型
// A:reduce操作中可变累加对象的类型,可以简单理解为累加操作中,累加到Container<A>中的可变对象类型
// R:reduce操作结果类型
public interface Collector<T, A, R> {
// 注释中称为Container,用于承载最终结果的可变容器,而此方法的Supplier实例持有的是创建Container实例的get()方法实现,后面称为Supplier
// 也就是一般使用如:Supplier<Container> supplier = () -> new Container();
Supplier<A> supplier();
// Accumulator,翻译为累加器,用于处理值并且把处理结果传递(累加)到Container中,后面称为Accumulator
BiConsumer<A, T> accumulator();
// Combiner,翻译为合并器,真实泛型类型为BinaryOperator<A,A,A>,BiFunction的子类,接收两个部分的结果并且合并为一个结果,后面称为Combiner
// 这个方法可以把一个参数的状态转移到另一个参数,然后返回更新状态后的参数,例如:(arg1, arg2) -> {arg2.state = arg1.state; return arg2;}
// 可以把一个参数的状态转移到另一个参数,然后返回一个新的容器,例如:(arg1, arg2) -> {arg2.state = arg1.state; return new Container(arg2);}
BinaryOperator<A> combiner();
// Finisher,直接翻译感觉意义不合理,实际上就是做最后一步转换工作的处理器,后面称为Finisher
Function<A, R> finisher();
// Collector支持的特性集合,见枚举Characteristics
Set<Characteristics> characteristics();
// 这里忽略两个Collector的静态工厂方法,因为并不常用
enum Characteristics {
// 标记Collector支持并发执行,一般和并发容器相关
CONCURRENT,
// 标记Collector处理元素时候无序
UNORDERED,
// 标记Collector的输入和输出元素是同类型,也就是Finisher在实现上R -> A可以等效于A -> R,unchecked cast会成功(也就是类型强转可以成功)
// 在这种场景下,对于Container来说其实类型强制转换也是等效的,也就是Supplier<A>和Supplier<R>得出的Container是同一种类型的Container
IDENTITY_FINISH
}
}
// Collector的实现Collectors.CollectorImpl
public final class Collectors {
// 这一大堆常量就是预设的多种特性组合,CH_NOID比较特殊,是空集合,也就是Collector三种特性都不支持
static final Set<Collector.Characteristics> CH_CONCURRENT_ID
= Collections.unmodifiableSet(EnumSet.of(Collector.Characteristics.CONCURRENT,
Collector.Characteristics.UNORDERED,
Collector.Characteristics.IDENTITY_FINISH));
static final Set<Collector.Characteristics> CH_CONCURRENT_NOID
= Collections.unmodifiableSet(EnumSet.of(Collector.Characteristics.CONCURRENT,
Collector.Characteristics.UNORDERED));
static final Set<Collector.Characteristics> CH_ID
= Collections.unmodifiableSet(EnumSet.of(Collector.Characteristics.IDENTITY_FINISH));
static final Set<Collector.Characteristics> CH_UNORDERED_ID
= Collections.unmodifiableSet(EnumSet.of(Collector.Characteristics.UNORDERED,
Collector.Characteristics.IDENTITY_FINISH));
static final Set<Collector.Characteristics> CH_NOID = Collections.emptySet();
static final Set<Collector.Characteristics> CH_UNORDERED_NOID
= Collections.unmodifiableSet(EnumSet.of(Collector.Characteristics.UNORDERED));
private Collectors() { }
// 省略大量代码
// 静态类,Collector的实现,实现其实就是Supplier、Accumulator、Combiner、Finisher和Characteristics集合的成员属性承载
static class CollectorImpl<T, A, R> implements Collector<T, A, R> {
private final Supplier<A> supplier;
private final BiConsumer<A, T> accumulator;
private final BinaryOperator<A> combiner;
private final Function<A, R> finisher;
private final Set<Characteristics> characteristics;
CollectorImpl(Supplier<A> supplier,
BiConsumer<A, T> accumulator,
BinaryOperator<A> combiner,
Function<A,R> finisher,
Set<Characteristics> characteristics) {
this.supplier = supplier;
this.accumulator = accumulator;
this.combiner = combiner;
this.finisher = finisher;
this.characteristics = characteristics;
}
CollectorImpl(Supplier<A> supplier,
BiConsumer<A, T> accumulator,
BinaryOperator<A> combiner,
Set<Characteristics> characteristics) {
this(supplier, accumulator, combiner, castingIdentity(), characteristics);
}
@Override
public BiConsumer<A, T> accumulator() {
return accumulator;
}
@Override
public Supplier<A> supplier() {
return supplier;
}
@Override
public BinaryOperator<A> combiner() {
return combiner;
}
@Override
public Function<A, R> finisher() {
return finisher;
}
@Override
public Set<Characteristics> characteristics() {
return characteristics;
}
}
// 省略大量代码
// IDENTITY_FINISH特性下,Finisher的实现,也就是之前提到的A->R和R->A等效,可以强转
private static <I, R> Function<I, R> castingIdentity() {
return i -> (R) i;
}
// 省略大量代码
}
|
The execution portal for the collect() method is in the ReferencePipeline.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
|
// ReferencePipeline
abstract class ReferencePipeline<P_IN, P_OUT>
extends AbstractPipeline<P_IN, P_OUT, Stream<P_OUT>>
implements Stream<P_OUT> {
// 暂时省略其他代码
// 基于Collector实例进行求值
public final <R, A> R collect(Collector<? super P_OUT, A, R> collector) {
A container;
// 并发求值场景暂不考虑
if (isParallel()
&& (collector.characteristics().contains(Collector.Characteristics.CONCURRENT))
&& (!isOrdered() || collector.characteristics().contains(Collector.Characteristics.UNORDERED))) {
container = collector.supplier().get();
BiConsumer<A, ? super P_OUT> accumulator = collector.accumulator();
forEach(u -> accumulator.accept(container, u));
}
else {
// 这里就是同步执行场景下的求值过程,这里可以看出其实所有Collector的求值都是Reduce操作
container = evaluate(ReduceOps.makeRef(collector));
}
// 如果Collector的Finisher输入类型和输出类型相同,所以Supplier<A>和Supplier<R>得出的Container是同一种类型的Container,可以直接类型转换,否则就要调用Collector中的Finisher进行最后一步处理
return collector.characteristics().contains(Collector.Characteristics.IDENTITY_FINISH)
? (R) container
: collector.finisher().apply(container);
}
// 暂时省略其他代码
}
// ReduceOps
final class ReduceOps {
private ReduceOps() { }
// 暂时省略其他代码
// 引用类型Reduce操作创建TerminalOp实例
public static <T, I> TerminalOp<T, I>
makeRef(Collector<? super T, I, ?> collector) {
// Supplier
Supplier<I> supplier = Objects.requireNonNull(collector).supplier();
// Accumulator
BiConsumer<I, ? super T> accumulator = collector.accumulator();
// Combiner
BinaryOperator<I> combiner = collector.combiner();
// 这里注意一点,ReducingSink是方法makeRef中的内部类,作用域只在方法内,它是封装为TerminalOp最终转化为Sink链中最后一个Sink实例的类型
class ReducingSink extends Box<I>
implements AccumulatingSink<T, I, ReducingSink> {
@Override
public void begin(long size) {
// 这里把从Supplier创建的新Container实例存放在父类Box的状态属性中
state = supplier.get();
}
@Override
public void accept(T t) {
// 处理元素,Accumulator处理状态(容器实例)和元素,这里可以想象,如果state为一个ArrayList实例,这里的accept()实现可能为add(ele)操作
accumulator.accept(state, t);
}
@Override
public void combine(ReducingSink other) {
// Combiner合并两个状态(容器实例)
state = combiner.apply(state, other.state);
}
}
return new ReduceOp<T, I, ReducingSink>(StreamShape.REFERENCE) {
@Override
public ReducingSink makeSink() {
return new ReducingSink();
}
@Override
public int getOpFlags() {
return collector.characteristics().contains(Collector.Characteristics.UNORDERED)
? StreamOpFlag.NOT_ORDERED
: 0;
}
};
}
// 暂时省略其他代码
// 继承自接口TerminalSink,主要添加了combine()抽象方法,用于合并元素
private interface AccumulatingSink<T, R, K extends AccumulatingSink<T, R, K>>
extends TerminalSink<T, R> {
void combine(K other);
}
// 状态盒,用于持有和获取状态,状态属性的修饰符为default,包内的类实例都能修改
private abstract static class Box<U> {
U state;
Box() {} // Avoid creation of special accessor
public U get() {
return state;
}
}
// ReduceOp的最终实现,这个就是Reduce操作终结操作的实现
private abstract static class ReduceOp<T, R, S extends AccumulatingSink<T, R, S>>
implements TerminalOp<T, R> {
// 流输入元素"形状"
private final StreamShape inputShape;
ReduceOp(StreamShape shape) {
inputShape = shape;
}
// 抽象方法,让子类生成终结操作的Sink
public abstract S makeSink();
// 获取流输入元素"形状"
@Override
public StreamShape inputShape() {
return inputShape;
}
// 同步执行求值,还是相似的思路,使用wrapAndCopyInto()进行Sink链构建和元素遍历
@Override
public <P_IN> R evaluateSequential(PipelineHelper<T> helper,
Spliterator<P_IN> spliterator) {
// 以当前的ReduceOp实例的makeSink()返回的Sink实例作为最后一个Sink添加到Sink链(也就是前面经常说的元素引用链),然后对Sink链进行遍历
// 这里向上一步一步推演思考,最终get()方法执行完毕拿到的结果就是ReducingSink父类Box中的state变量,也就是容器实例
return helper.wrapAndCopyInto(makeSink(), spliterator).get();
}
// 异步执行求值,暂时忽略
@Override
public <P_IN> R evaluateParallel(PipelineHelper<T> helper,
Spliterator<P_IN> spliterator) {
return new ReduceTask<>(this, helper, spliterator).invoke().get();
}
}
// 暂时省略其他代码
}
|
Then look at the static factory method of Collector to see how some common Collector instances are built, for example, look at Collectors.toList().
1
2
3
4
5
6
7
8
9
10
|
// Supplier => () -> new ArrayList<T>(); // 初始化ArrayList
// Accumulator => (list,number) -> list.add(number); // 往ArrayList中添加元素
// Combiner => (left, right) -> { left.addAll(right); return left;} // 合并ArrayList
// Finisher => X -> X; // 输入什么就返回什么,这里实际返回的是ArrayList
public static <T>
Collector<T, ?, List<T>> toList() {
return new CollectorImpl<>((Supplier<List<T>>) ArrayList::new, List::add,
(left, right) -> { left.addAll(right); return left; },
CH_ID);
}
|
Draw the process as a flow chart as follows.
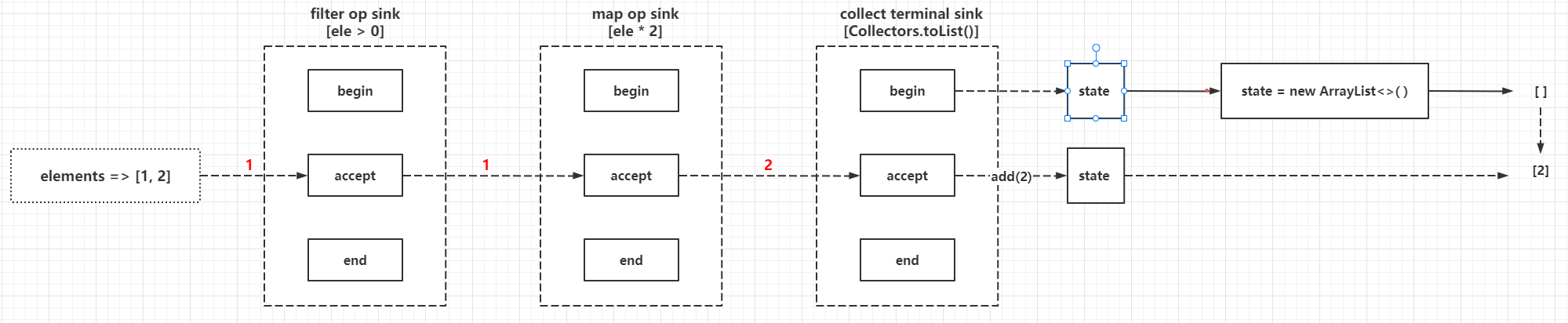
Even more colloquially, the execution of a Terminal Op like Collector can be represented in pseudo-code (still using Collectors.toList() as an example).
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
[begin]
Supplier supplier = () -> new ArrayList<T>();
Container container = supplier.get();
Box.state = container;
[accept]
Box.state.add(element);
[end]
return supplier.get(); (=> return Box.state);
↓↓↓↓↓↓↓↓↓甚至更加通俗的过程如下↓↓↓↓↓↓↓↓↓↓↓↓↓↓
ArrayList<T> container = new ArrayList<T>();
loop:
container.add(element)
return container;
|
That is, although the engineered code looks complex, the final implementation is simple: initialize the ArrayList instance held by the state property, traversing the processing of elements when the elements are added to the state, and finally return to the state. finally look at the method implementation of toArray () (the following method code is not posted in accordance with the actual location, the author put the fragmented code blocks together to facilitate analysis).
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
|
abstract class ReferencePipeline<P_IN, P_OUT>
extends AbstractPipeline<P_IN, P_OUT, Stream<P_OUT>>
implements Stream<P_OUT> {
// 暂时省略其他代码
// 流的所有元素转换为数组,这里的IntFunction有一种比较特殊的用法,就是用于创建数组实例
// 例如IntFunction<String[]> f = String::new; String[] arry = f.apply(2); 相当于String[] arry = new String[2];
@Override
@SuppressWarnings("unchecked")
public final <A> A[] toArray(IntFunction<A[]> generator) {
// 这里主动擦除了IntFunction的类型,只要保证求值的过程是正确,最终可以做类型强转
@SuppressWarnings("rawtypes")
IntFunction rawGenerator = (IntFunction) generator;
// 委托到evaluateToArrayNode()方法进行计算
return (A[]) Nodes.flatten(evaluateToArrayNode(rawGenerator), rawGenerator)
.asArray(rawGenerator);
}
// 流的所有元素转换为Object数组
@Override
public final Object[] toArray() {
return toArray(Object[]::new);
}
// 流元素求值转换为ArrayNode
final Node<E_OUT> evaluateToArrayNode(IntFunction<E_OUT[]> generator) {
// 确保不会处理多次
if (linkedOrConsumed)
throw new IllegalStateException(MSG_STREAM_LINKED);
linkedOrConsumed = true;
// 并发执行暂时跳过
if (isParallel() && previousStage != null && opIsStateful()) {
depth = 0;
return opEvaluateParallel(previousStage, previousStage.sourceSpliterator(0), generator);
}
else {
return evaluate(sourceSpliterator(0), true, generator);
}
}
// 最终的转换Node的方法
final <P_IN> Node<E_OUT> evaluate(Spliterator<P_IN> spliterator,
boolean flatten,
IntFunction<E_OUT[]> generator) {
// 并发执行暂时跳过
if (isParallel()) {
// @@@ Optimize if op of this pipeline stage is a stateful op
return evaluateToNode(this, spliterator, flatten, generator);
}
else {
// 兜兜转换还是回到了wrapAndCopyInto()方法,遍历Sink链,所以基本可以得知Node.Builder是Sink的一个实现
Node.Builder<E_OUT> nb = makeNodeBuilder(
exactOutputSizeIfKnown(spliterator), generator);
return wrapAndCopyInto(nb, spliterator).build();
}
}
// 获取Node的建造器实例
final Node.Builder<P_OUT> makeNodeBuilder(long exactSizeIfKnown, IntFunction<P_OUT[]> generator) {
return Nodes.builder(exactSizeIfKnown, generator);
}
// 暂时省略其他代码
}
// Node接口定义
interface Node<T> {
// 获取待处理的元素封装成的Spliterator实例
Spliterator<T> spliterator();
// 遍历当前Node实例中所有待处理的元素,回调到Consumer实例中
void forEach(Consumer<? super T> consumer);
// 获取当前Node实例的所有子Node的个数
default int getChildCount() {
return 0;
}
// 获取当前Node实例的子Node实例,入参i是子Node的索引
default Node<T> getChild(int i) {
throw new IndexOutOfBoundsException();
}
// 分割当前Node实例的一个部分,生成一个新的sub Node,类似于ArrayList中的subList方法
default Node<T> truncate(long from, long to, IntFunction<T[]> generator) {
if (from == 0 && to == count())
return this;
Spliterator<T> spliterator = spliterator();
long size = to - from;
Node.Builder<T> nodeBuilder = Nodes.builder(size, generator);
nodeBuilder.begin(size);
for (int i = 0; i < from && spliterator.tryAdvance(e -> { }); i++) { }
if (to == count()) {
spliterator.forEachRemaining(nodeBuilder);
} else {
for (int i = 0; i < size && spliterator.tryAdvance(nodeBuilder); i++) { }
}
nodeBuilder.end();
return nodeBuilder.build();
}
// 创建一个包含当前Node实例所有元素的元素数组视图
T[] asArray(IntFunction<T[]> generator);
//
void copyInto(T[] array, int offset);
// 返回Node实例基于Stream的元素"形状"
default StreamShape getShape() {
return StreamShape.REFERENCE;
}
// 获取当前Node实例包含的元素个数
long count();
// Node建造器,注意这个Node.Builder接口是继承自Sink,那么其子类实现都可以添加到Sink链中作为一个节点(终结节点)
interface Builder<T> extends Sink<T> {
// 创建Node实例
Node<T> build();
// 基于Integer元素类型的特化类型Node.Builder
interface OfInt extends Node.Builder<Integer>, Sink.OfInt {
@Override
Node.OfInt build();
}
// 基于Long元素类型的特化类型Node.Builder
interface OfLong extends Node.Builder<Long>, Sink.OfLong {
@Override
Node.OfLong build();
}
// 基于Double元素类型的特化类型Node.Builder
interface OfDouble extends Node.Builder<Double>, Sink.OfDouble {
@Override
Node.OfDouble build();
}
}
// 暂时省略其他代码
}
// 这里下面的方法来源于Nodes类
final class Nodes {
// 暂时省略其他代码
// Node扁平化处理,如果传入的Node实例存在子Node实例,则使用fork-join对Node进行分割和并发计算,结果添加到IntFunction生成的数组中,如果不存在子Node,直接返回传入的Node实例
// 关于并发计算部分暂时不分析
public static <T> Node<T> flatten(Node<T> node, IntFunction<T[]> generator) {
if (node.getChildCount() > 0) {
long size = node.count();
if (size >= MAX_ARRAY_SIZE)
throw new IllegalArgumentException(BAD_SIZE);
T[] array = generator.apply((int) size);
new ToArrayTask.OfRef<>(node, array, 0).invoke();
return node(array);
} else {
return node;
}
}
// 创建Node的建造器实例
static <T> Node.Builder<T> builder(long exactSizeIfKnown, IntFunction<T[]> generator) {
// 当知道待处理元素的准确数量并且小于允许创建的数组的最大长度MAX_ARRAY_SIZE(Integer.MAX_VALUE - 8),使用FixedNodeBuilder(固定长度数组Node建造器),否则使用SpinedNodeBuilder实例
return (exactSizeIfKnown >= 0 && exactSizeIfKnown < MAX_ARRAY_SIZE)
? new FixedNodeBuilder<>(exactSizeIfKnown, generator)
: builder();
}
// 创建Node的建造器实例,使用SpinedNodeBuilder的实例,此SpinedNode支持元素添加,但是不支持元素移除
static <T> Node.Builder<T> builder() {
return new SpinedNodeBuilder<>();
}
// 固定长度固定长度数组Node实现(也就是最终的Node实现是一个ArrayNode,最终的容器为一个T类型元素的数组T[])
private static final class FixedNodeBuilder<T>
extends ArrayNode<T>
implements Node.Builder<T> {
// 基于size(元素个数,或者说创建数组的长度)和数组创建方法IntFunction构建FixedNodeBuilder实例
FixedNodeBuilder(long size, IntFunction<T[]> generator) {
super(size, generator);
assert size < MAX_ARRAY_SIZE;
}
// 返回当前FixedNodeBuilder实例,判断数组元素计数值curSize必须大于等于实际数组容器中元素的个数
@Override
public Node<T> build() {
if (curSize < array.length)
throw new IllegalStateException(String.format("Current size %d is less than fixed size %d",
curSize, array.length));
return this;
}
// Sink的begin方法回调,传入的size必须和数组长度相等,因为后面的accept()方法会执行size此
@Override
public void begin(long size) {
if (size != array.length)
throw new IllegalStateException(String.format("Begin size %d is not equal to fixed size %d",
size, array.length));
// 重置数组元素计数值为0
curSize = 0;
}
// Sink的accept方法回调,当数组元素计数值小于数组长度,直接向数组下标curSize++添加传入的元素
@Override
public void accept(T t) {
if (curSize < array.length) {
array[curSize++] = t;
} else {
throw new IllegalStateException(String.format("Accept exceeded fixed size of %d",
array.length));
}
}
// Sink的end方法回调,再次判断数组元素计数值curSize必须大于等于实际数组容器中元素的个数
@Override
public void end() {
if (curSize < array.length)
throw new IllegalStateException(String.format("End size %d is less than fixed size %d",
curSize, array.length));
}
// 返回FixedNodeBuilder当前信息,当前处理的下标和当前数组中所有的元素
@Override
public String toString() {
return String.format("FixedNodeBuilder[%d][%s]",
array.length - curSize, Arrays.toString(array));
}
}
// Node实现,容器为一个固定长度的数组
private static class ArrayNode<T> implements Node<T> {
// 数组容器
final T[] array;
// 数组容器中当前元素的个数,这个值是一个固定值,或者在FixedNodeBuilder的accept()方法回调中递增
int curSize;
// 基于size和数组创建的工厂IntFunction构建ArrayNode实例
@SuppressWarnings("unchecked")
ArrayNode(long size, IntFunction<T[]> generator) {
if (size >= MAX_ARRAY_SIZE)
throw new IllegalArgumentException(BAD_SIZE);
// 创建szie长度的数组容器
this.array = generator.apply((int) size);
this.curSize = 0;
}
// 这个方法是基于一个现成的数组创建ArrayNode实例,直接改变数组的引用为array,元素个数curSize置为输入参数长度
ArrayNode(T[] array) {
this.array = array;
this.curSize = array.length;
}
// Node - 接下来是Node接口的实现
// 基于数组实例,起始索引0和结束索引curSize构造一个全新的Spliterator实例
@Override
public Spliterator<T> spliterator() {
return Arrays.spliterator(array, 0, curSize);
}
// 拷贝array中的元素到外部传入的dest数组中
@Override
public void copyInto(T[] dest, int destOffset) {
System.arraycopy(array, 0, dest, destOffset, curSize);
}
// 返回元素数组视图,这里直接返回array引用
@Override
public T[] asArray(IntFunction<T[]> generator) {
if (array.length == curSize) {
return array;
} else {
throw new IllegalStateException();
}
}
// 获取array中的元素个数
@Override
public long count() {
return curSize;
}
// 遍历array,每个元素回调Consumer实例
@Override
public void forEach(Consumer<? super T> consumer) {
for (int i = 0; i < curSize; i++) {
consumer.accept(array[i]);
}
}
// 返回ArrayNode当前信息,当前处理的下标和当前数组中所有的元素
@Override
public String toString() {
return String.format("ArrayNode[%d][%s]",
array.length - curSize, Arrays.toString(array));
}
}
// 暂时省略其他代码
}
|
In fact, the final implementation of Node is in many cases Nodes.SpinedNodeBuilder, because SpinedNodeBuilder is a heavy implementation of the array expansion and Spliterator based on the array partitioning method, the source code is relatively complex (especially the spliterator() method). relatively complex (especially the spliterator () method), here to pick part of the analysis, as SpinedNodeBuilder most of the methods are used in the parent class SpinedBuffer implementation, here you can directly analyze the SpinedBuffer.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
|
// SpinedBuffer的当前数组在超过了元素数量阈值之后,会拆分为多个数组块,存储到spine中,而curChunk引用指向的是当前处理的数组块
class SpinedBuffer<E>
extends AbstractSpinedBuffer
implements Consumer<E>, Iterable<E> {
// 暂时省略其他代码
// 当前的数组块
protected E[] curChunk;
// 所有数组块
protected E[][] spine;
// 构造函数,指定初始化容量
SpinedBuffer(int initialCapacity) {
super(initialCapacity);
curChunk = (E[]) new Object[1 << initialChunkPower];
}
// 构造函数,指定默认初始化容量
@SuppressWarnings("unchecked")
SpinedBuffer() {
super();
curChunk = (E[]) new Object[1 << initialChunkPower];
}
// 拷贝当前SpinedBuffer中的数组元素到传入的数组实例
public void copyInto(E[] array, int offset) {
// 计算最终的offset,区分单个chunk和多个chunk的情况
long finalOffset = offset + count();
if (finalOffset > array.length || finalOffset < offset) {
throw new IndexOutOfBoundsException("does not fit");
}
// 单个chunk的情况,由curChunk最接拷贝
if (spineIndex == 0)
System.arraycopy(curChunk, 0, array, offset, elementIndex);
else {
// 多个chunk的情况,由遍历spine并且对每个chunk进行拷贝
// full chunks
for (int i=0; i < spineIndex; i++) {
System.arraycopy(spine[i], 0, array, offset, spine[i].length);
offset += spine[i].length;
}
if (elementIndex > 0)
System.arraycopy(curChunk, 0, array, offset, elementIndex);
}
}
// 返回数组元素视图,基于IntFunction构建数组实例,使用copyInto()方法进行元素拷贝
public E[] asArray(IntFunction<E[]> arrayFactory) {
long size = count();
if (size >= Nodes.MAX_ARRAY_SIZE)
throw new IllegalArgumentException(Nodes.BAD_SIZE);
E[] result = arrayFactory.apply((int) size);
copyInto(result, 0);
return result;
}
// 清空SpinedBuffer,清空分块元素和所有引用
@Override
public void clear() {
if (spine != null) {
curChunk = spine[0];
for (int i=0; i<curChunk.length; i++)
curChunk[i] = null;
spine = null;
priorElementCount = null;
}
else {
for (int i=0; i<elementIndex; i++)
curChunk[i] = null;
}
elementIndex = 0;
spineIndex = 0;
}
// 遍历元素回调Consumer,分别遍历spine和curChunk
@Override
public void forEach(Consumer<? super E> consumer) {
// completed chunks, if any
for (int j = 0; j < spineIndex; j++)
for (E t : spine[j])
consumer.accept(t);
// current chunk
for (int i=0; i<elementIndex; i++)
consumer.accept(curChunk[i]);
}
// Consumer的accept实现,最终会作为Sink接口的accept方法调用
@Override
public void accept(E e) {
// 如果当前分块(第一个)的元素已经满了,就初始化spine,然后元素添加到spine[0]中
if (elementIndex == curChunk.length) {
inflateSpine();
// 然后元素添加到spine[0]中的元素已经满了,就新增spine[n],把元素放进spine[n]中
if (spineIndex+1 >= spine.length || spine[spineIndex+1] == null)
increaseCapacity();
elementIndex = 0;
++spineIndex;
// 当前的chunk更新为最新的chunk,就是spine中的最新一个chunk
curChunk = spine[spineIndex];
}
// 当前的curChunk添加元素
curChunk[elementIndex++] = e;
}
// 暂时省略其他代码
}
|
The source code has been basically analyzed, and the following is still translated into a flow chart using an example.
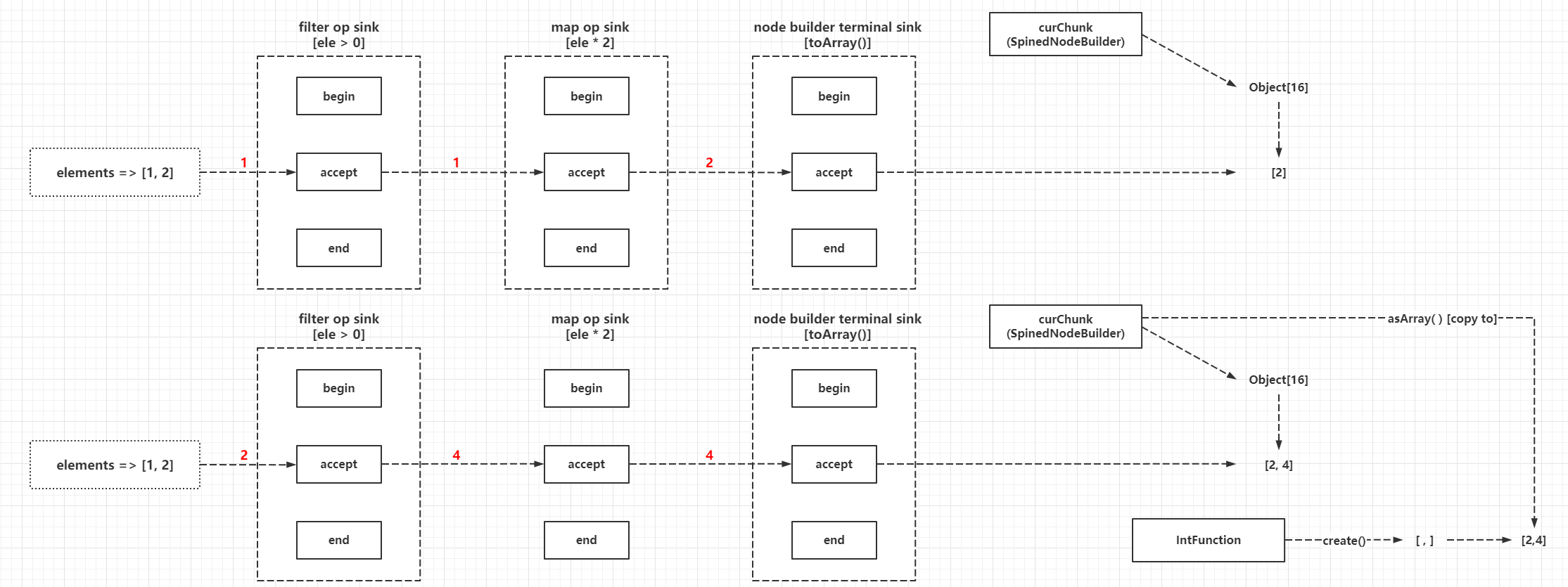
Source code implementation of stream concurrent execution
If the stream instance calls parallel(), the annotation mentions that it will return a variant that performs the stream asynchronously. In fact, no variant is constructed, but only sourceStage.parallel is marked as true, and the basic process of asynchronous solving is that the process of constructing the stream pipeline structure is the same as that of synchronous solving, and after constructing the Sink chain Spliterator will use a specific algorithm based on trySplit() to perform self-partitioning, the self-partitioning algorithm is determined by the specific subclass, for example ArrayList uses the dichotomy method, after the partitioning is completed each Spliterator holds a small portion of all the elements, then each Spliterator as sourceSpliterator in the fork-join thread pool to execute the Sink chain, get the results of multiple parts in the current call thread aggregation, to get the final result. The techniques used here are thread closure and fork-join, and since the concurrency of different Terminal Op’s is similar, we only analyze the implementation of forEach concurrent execution here. First, we show a simple example of using a fork-join thread pool.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
|
public class MapReduceApp {
public static void main(String[] args) {
// 数组中每个元素*2,再求和
Integer result = new MapReducer<>(new Integer[]{1, 2, 3, 4}, x -> x * 2, Integer::sum).invoke();
System.out.println(result);
}
interface Mapper<S, T> {
T apply(S source);
}
interface Reducer<S, T> {
T apply(S first, S second);
}
public static class MapReducer<T> extends CountedCompleter<T> {
final T[] array;
final Mapper<T, T> mapper;
final Reducer<T, T> reducer;
final int lo, hi;
MapReducer<T> sibling;
T result;
public MapReducer(T[] array,
Mapper<T, T> mapper,
Reducer<T, T> reducer) {
this.array = array;
this.mapper = mapper;
this.reducer = reducer;
this.lo = 0;
this.hi = array.length;
}
public MapReducer(CountedCompleter<?> p,
T[] array,
Mapper<T, T> mapper,
Reducer<T, T> reducer,
int lo,
int hi) {
super(p);
this.array = array;
this.mapper = mapper;
this.reducer = reducer;
this.lo = lo;
this.hi = hi;
}
@Override
public void compute() {
if (hi - lo >= 2) {
int mid = (lo + hi) >> 1;
MapReducer<T> left = new MapReducer<>(this, array, mapper, reducer, lo, mid);
MapReducer<T> right = new MapReducer<>(this, array, mapper, reducer, mid, hi);
left.sibling = right;
right.sibling = left;
// 创建子任务父任务的pending计数器加1
setPendingCount(1);
// 提交右子任务
right.fork();
// 在当前线程计算左子任务
left.compute();
} else {
if (hi > lo) {
result = mapper.apply(array[lo]);
}
// 叶子节点完成,尝试合并其他兄弟节点的结果,会调用onCompletion方法
tryComplete();
}
}
@Override
public T getRawResult() {
return result;
}
@SuppressWarnings("unchecked")
@Override
public void onCompletion(CountedCompleter<?> caller) {
if (caller != this) {
MapReducer<T> child = (MapReducer<T>) caller;
MapReducer<T> sib = child.sibling;
// 合并子任务结果,只有两个子任务
if (Objects.isNull(sib) || Objects.isNull(sib.result)) {
result = child.result;
} else {
result = reducer.apply(child.result, sib.result);
}
}
}
}
}
|
Here a simple MapReduce application is written using fork-join. The main method runs the process of mapping all the elements in the array [1,2,3,4] to i -> i * 2 first, and then reducing (summation), the code also simply uses the dichotomy to split the original array. When the final task contains only one element, i.e. lo < hi and hi - lo == 1, Mapper’s method will be called based on a single element to notify tryComplete() of completion, and the task completion will eventually notify the onCompletion() method, in which the Reducer is the aggregation operation of the result. The process is similar for concurrent value seeking in streams, where ForEachOp eventually calls ForEachOrderedTask or ForEachTask, and here ForEachTask is selected for analysis.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
|
abstract static class ForEachOp<T>
implements TerminalOp<T, Void>, TerminalSink<T, Void> {
// 暂时省略其他代码
@Override
public <S> Void evaluateParallel(PipelineHelper<T> helper,
Spliterator<S> spliterator) {
if (ordered)
new ForEachOrderedTask<>(helper, spliterator, this).invoke();
else
// 最终是调用ForEachTask的invoke方法,invoke会阻塞到所有fork任务执行完,获取最终的结果
new ForEachTask<>(helper, spliterator, helper.wrapSink(this)).invoke();
return null;
}
// 暂时省略其他代码
}
// ForEachOps类
final class ForEachOps {
private ForEachOps() { }
// forEach的fork-join任务实现,没有覆盖getRawResult()方法,最终只会返回NULL
static final class ForEachTask<S, T> extends CountedCompleter<Void> {
// Spliterator实例,如果是父任务则代表所有待处理的元素,如果是子任务则是一个分割后的新Spliterator实例
private Spliterator<S> spliterator;
// Sink链实例
private final Sink<S> sink;
// 流管道引用
private final PipelineHelper<T> helper;
// 目标数量,其实是每个任务处理元素数量的建议值
private long targetSize;
// 这个构造器是提供给父(根)任务
ForEachTask(PipelineHelper<T> helper,
Spliterator<S> spliterator,
Sink<S> sink) {
super(null);
this.sink = sink;
this.helper = helper;
this.spliterator = spliterator;
this.targetSize = 0L;
}
// 这个构造器是提供给子任务,所以需要父任务的引用和一个分割后的新Spliterator实例作为参数
ForEachTask(ForEachTask<S, T> parent, Spliterator<S> spliterator) {
super(parent);
this.spliterator = spliterator;
this.sink = parent.sink;
this.targetSize = parent.targetSize;
this.helper = parent.helper;
}
// Similar to AbstractTask but doesn't need to track child tasks
// 实现compute方法,用于分割Spliterator成多个子任务,这里不需要跟踪所有子任务
public void compute() {
// 神奇的赋值,相当于Spliterator<S> rightSplit = spliterator; Spliterator<S> leftSplit;
// rightSplit总是指向当前的spliterator实例
Spliterator<S> rightSplit = spliterator, leftSplit;
// 这里也是神奇的赋值,相当于long sizeEstimate = rightSplit.estimateSize(); long sizeThreshold;
long sizeEstimate = rightSplit.estimateSize(), sizeThreshold;
// sizeThreshold赋值为targetSize
if ((sizeThreshold = targetSize) == 0L)
// 基于Spliterator分割后的右分支实例的元素数量重新赋值sizeThreshold和targetSize
// 计算方式是待处理元素数量/(fork-join线程池并行度<<2)或者1(当前一个计算方式结果为0的时候)
targetSize = sizeThreshold = AbstractTask.suggestTargetSize(sizeEstimate);
// 当前的流是否支持SHORT_CIRCUIT,也就是短路特性
boolean isShortCircuit = StreamOpFlag.SHORT_CIRCUIT.isKnown(helper.getStreamAndOpFlags());
// 当前的任务是否fork右分支
boolean forkRight = false;
// taskSink作为Sink的临时变量
Sink<S> taskSink = sink;
// 当前任务的临时变量
ForEachTask<S, T> task = this;
// Spliterator分割和创建新的fork任务ForEachTask,前提是不支持短路或者Sink不支持取消
while (!isShortCircuit || !taskSink.cancellationRequested()) {
// 当前的任务中的Spliterator(rightSplit)中的待处理元素小于等于每个任务应该处理的元素阈值或者再分割后得到NULL,则不需要再分割,直接基于rightSplit和Sink链执行循环处理元素
if (sizeEstimate <= sizeThreshold || (leftSplit = rightSplit.trySplit()) == null) {
// 这里就是遍历rightSplit元素回调Sink链的操作
task.helper.copyInto(taskSink, rightSplit);
break;
}
// rightSplit还能分割,则基于分割后的leftSplit和以当前任务作为父任务创建一个新的fork任务
ForEachTask<S, T> leftTask = new ForEachTask<>(task, leftSplit);
// 待处理子任务加1
task.addToPendingCount(1);
// 需要fork的任务实例临时变量
ForEachTask<S, T> taskToFork;
// 因为rightSplit总是分割Spliterator后对应原来的Spliterator引用,而leftSplit总是trySplit()后生成的新的Spliterator
// 所以这里leftSplit也需要作为rightSplit进行分割,通俗来说就是周星驰007那把梅花间足发射的枪
if (forkRight) {
// 这里交换leftSplit为rightSplit,所以forkRight设置为false,下一轮循环相当于fork left
forkRight = false;
rightSplit = leftSplit;
taskToFork = task;
// 赋值下一轮的父Task为当前的fork task
task = leftTask;
}
else {
forkRight = true;
taskToFork = leftTask;
}
// 添加fork任务到任务队列中
taskToFork.fork();
// 其实这里是更新剩余待分割的Spliterator中的所有元素数量到sizeEstimate
sizeEstimate = rightSplit.estimateSize();
}
// 置空spliterator实例并且传播任务完成状态,等待所有任务执行完成
task.spliterator = null;
task.propagateCompletion();
}
}
}
|
The source code analysis above may seem difficult to understand, so here is a simple example.
1
2
3
4
5
6
7
8
|
public static void main(String[] args) throws Exception {
List<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
list.add(4);
list.stream().parallel().forEach(System.out::println);
}
|
This code is finally converted into ForEachTask in the evaluation of the targetSize = sizeThreshold == 1, the current calling thread will participate in the calculation, will perform 3 forks, that is, a total of 4 processing process instances (that is, the original Spliterator instance will eventually split out of 3 brand new Spliterator instances, plus itself a 4 Spliterator instances), each processing process instances only deal with 1 element, the corresponding flow chart is as follows.
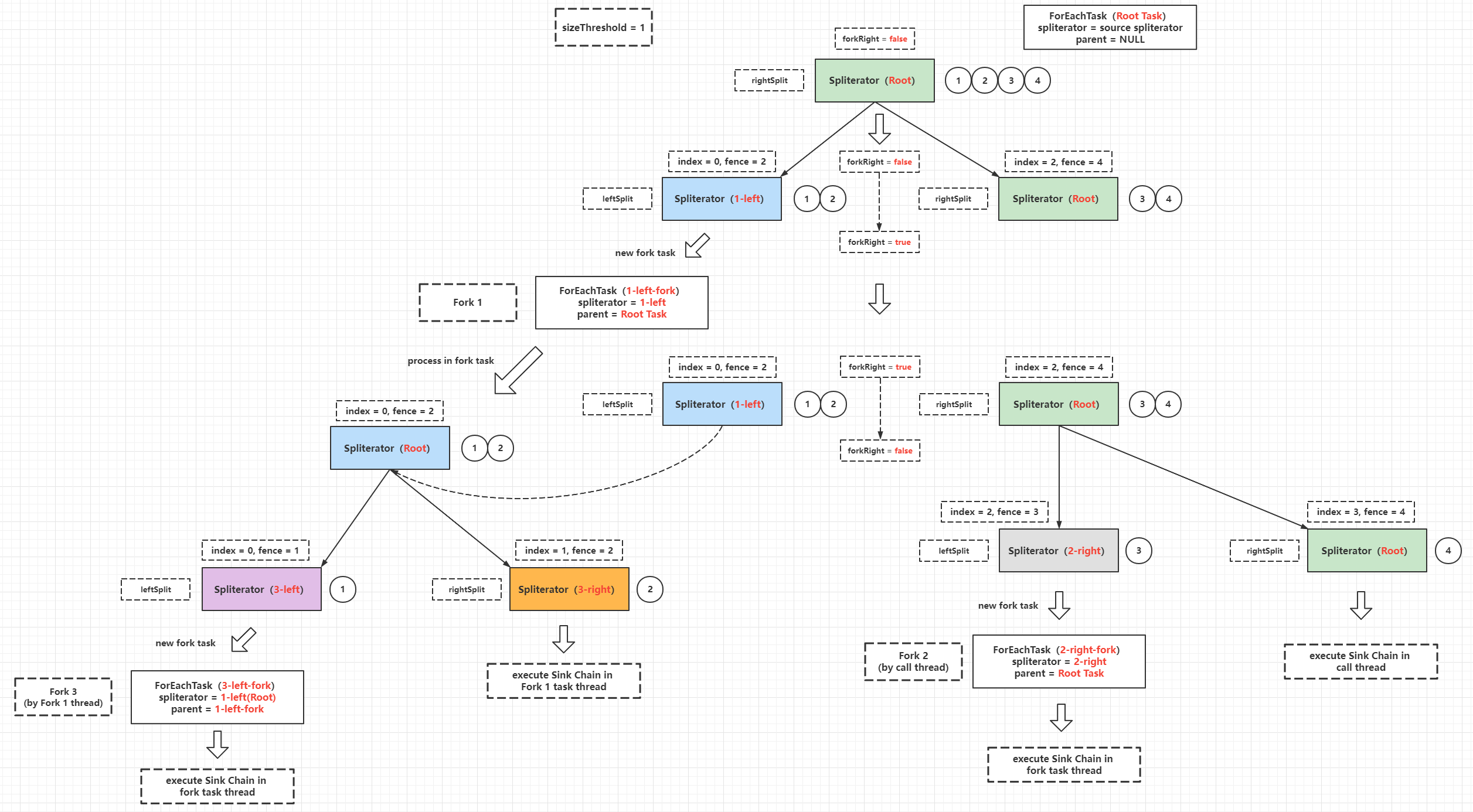
The final result is obtained by calling CountedCompleter.invoke() method, this method will block until all subtasks are processed, of course, forEach end operation does not need to return value, so there is no getRawResult() method, here just to block until all tasks are executed before lifting the calling thread This is just to block until all tasks are executed before releasing the calling thread from the blocking state.
State operation and short-circuit operation
Stream can be divided into stateless operations and stateful operations according to whether the intermediate operations have state or not, and into non-short-circuit operations and short-circuit operations according to whether the end operations support the short-circuit feature. The understanding is as follows.
- Stateless operation: After the current operation node finishes processing the element, the result is passed directly to the next operation node if the preconditions are met, that is, there is no state inside the operation and no need to save state, such as filter, map, etc.
- Stateful operations: when processing elements, depending on the internal state of the node to accumulate elements, when processing a new element, in fact, you can sense the history of all the elements processed, this “state” is actually more like the concept of the buffer, such as sort, limit and other operations, to sort operations, for example, is generally to add all the elements to be processed to a container such as ArrayList, and then sort all the elements, and then re-simulate Spliterator to push the elements to the next node
- Non-short-circuiting (terminating) operations: terminating operations cannot interrupt processing early and return based on short-circuiting conditions when processing elements, i.e., all elements must be processed, such as forEach
- Short-circuit (end) operation: the end operation allows the processing of elements based on the short-circuit condition in advance to interrupt the processing and return, but the final implementation is possible to traverse all the elements, but in the processing method based on the preceding short-circuit condition to skip the actual processing, such as anyMatch (in fact, anyMatch will traverse all the elements, but in the hit the short-circuit condition (actually anyMatch will traverse all the elements, but when the short-circuit condition is hit, the element will call back the Sink.accept() method to skip the actual processing based on the stop short-circuit flag)
Without expanding the source code here for analysis, just show a summary table of frequently seen Stream operations as follows.
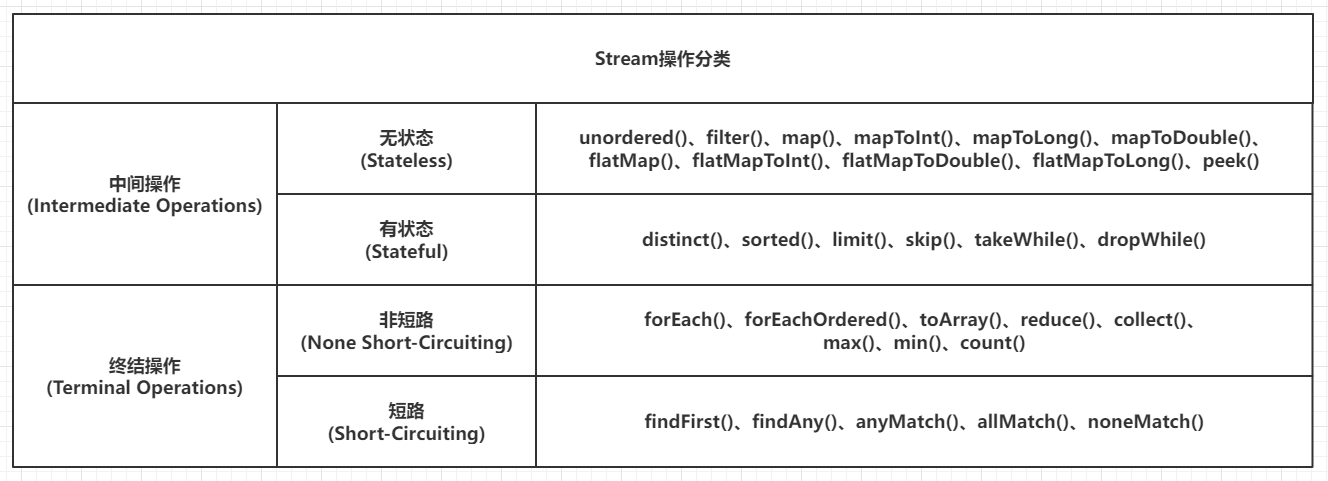
Two other points to note here.
- From the source code, some of the intermediate operations also support short-circuiting, such as slice and while-related operations
- From the source code findFirst and findAny are supported and judged by StreamOpFlag.SHORT_CIRCUIT, while match-related end operations are short-circuited by the internal temporary state stop and value.
Summary
Before and after writing more than 100,000 words, in fact, only a relatively shallow introduction to the basic implementation of Stream, the author believes that many did not analyze the implementation of intermediate and final operations, especially the concurrent implementation of the final operation is very complex, multi-threaded environment requires some imagination and multiple DEBUG positioning execution location and deduce the process of implementation. A brief summary.
- The Stream implementation in the JDK is refined and highly engineered code
- Although the carrier of Stream is AbstractPipeline, the pipeline structure, but only its shape, the actual value of the operation will be transformed into a multi-layer wrapped Sink structure, that is, the previous article has been said Sink chain, from the programming model, the application of the Reactor programming model
- The inherent execution structure supported by Stream must be Head(Source Spliterator) -> Op -> Op … -> Terminal Op form, which is a limitation, there is no way to do as LINQ can be flexible to achieve similar memory view functionality
- Stream currently supports concurrent value solution is for Source Spliterator to split, encapsulate Terminal Op and fixed Sink chain construction of ForkJoinTask for concurrent computation, the calling thread and fork-join thread pool in the work thread can participate in the value process, the author believes that this part is the most complex implementation of Stream in addition to those sign collection bit operation
- Stream implementation is a breakthrough, some people have said that this feature is a “premature child”, here I hope that the JDK can be in the contradiction spiral forward and development