Python handles control characters in text
Previously, when using Python for crawling, I encountered an error reading the data. After analysis, I found that the returned HTML contains control characters (it turns out that anti-crawler can also do this, control characters in the crawler easily cause errors, but when presented to the user in the browser does not affect anything).
What is a control character?
Control characters (Control Character), or non-printing characters, appear in the text of a specific message, indicating a control function characters, such as control characters: LF (line feed), CR (carriage return), FF (page break), DEL (delete), BS (backspace), BEL (ringing), etc.; communication-specific characters: SOH (text header), EOT (end of text), ACK (confirmation), etc.
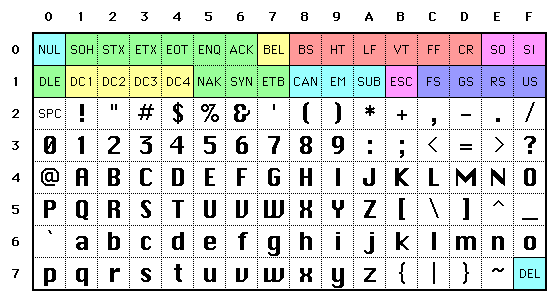
There are two sets of specific control characters as follows.
- Seven-bit ASCII defines 33 codes as control characters, which are 0 to 31, and 127, (located at 0x00-0x1F and 0x7F)
- Compatible eight-bit ISO/IEC 8859-1 plus 32 codes from ISO/IEC 6429 defined from 128 to 159, located at 0x80-0x9F
Control character list: http://ascii-table.com/control-chars.php
Python solution for control characters
Option 1.
|
|
Option 2.
|
|
Option 3.
|
|
Reference links.