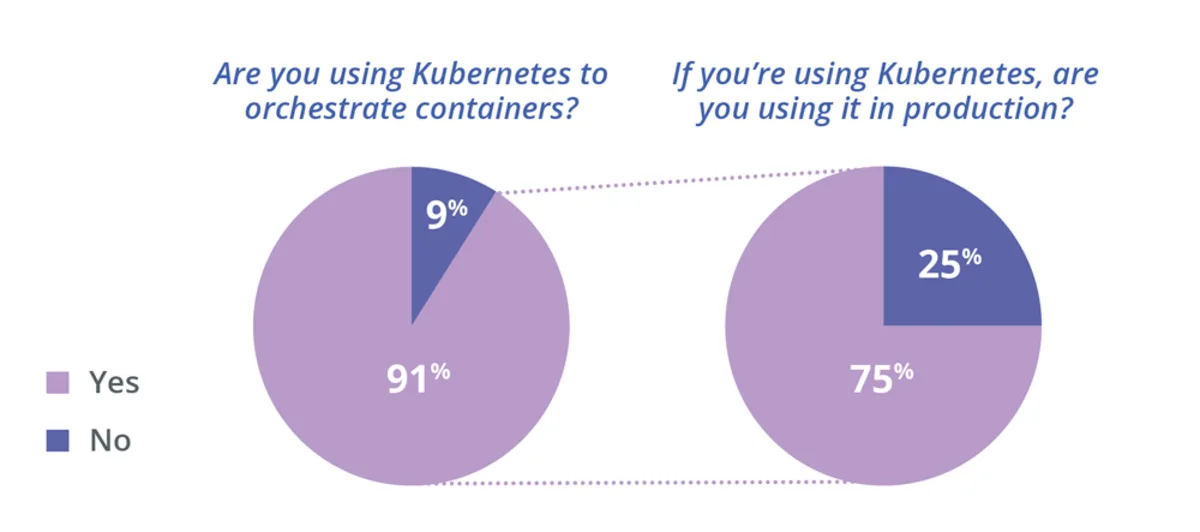
Kubernetes, released in 2014, has become the de facto standard in container orchestration today, and I’m sure developers who talk about Kubernetes will repeat the above phenomenon over and over again. As the chart below shows, most individuals or teams today choose Kubernetes to manage containers, and 75% of people use Kubernetes in production environments.
In this context of universal learning and use of Kubernetes, it is also important to be very clear about what the limitations of Kubernetes are. While Kubernetes can solve most of the problems in the container orchestration space, there are still some scenarios that are difficult, if not impossible, for it to handle.
Only with a clear understanding of these potential risks can we better navigate this technology, and this article will talk about the current development and some limitations of the Kubernetes community, both in terms of cluster management and application scenarios.
Cluster Management
A cluster is a group of computers that can work together. We can see all the computers in the cluster as a whole, and all the resource scheduling systems are managed in the cluster dimension. All the machines in the cluster form a resource pool, and this huge resource pool will provide resources for the containers to be run to perform computational tasks, and here we briefly talk about several complex issues faced by Kubernetes cluster management.
Horizontal Scalability
Cluster size is one of the key metrics we need to look at when evaluating resource management systems, yet Kubernetes can manage far smaller clusters than other resource management systems in the industry. Why is cluster size important? Let’s first look at another equally important metric - resource utilization. Many engineers may not have requested resources on public cloud platforms, which are quite expensive, and a virtual machine instance on AWS with a similar configuration to the host (8 CPUs, 16 GB) costs about 150 USD per month, which is about 1000 CNY
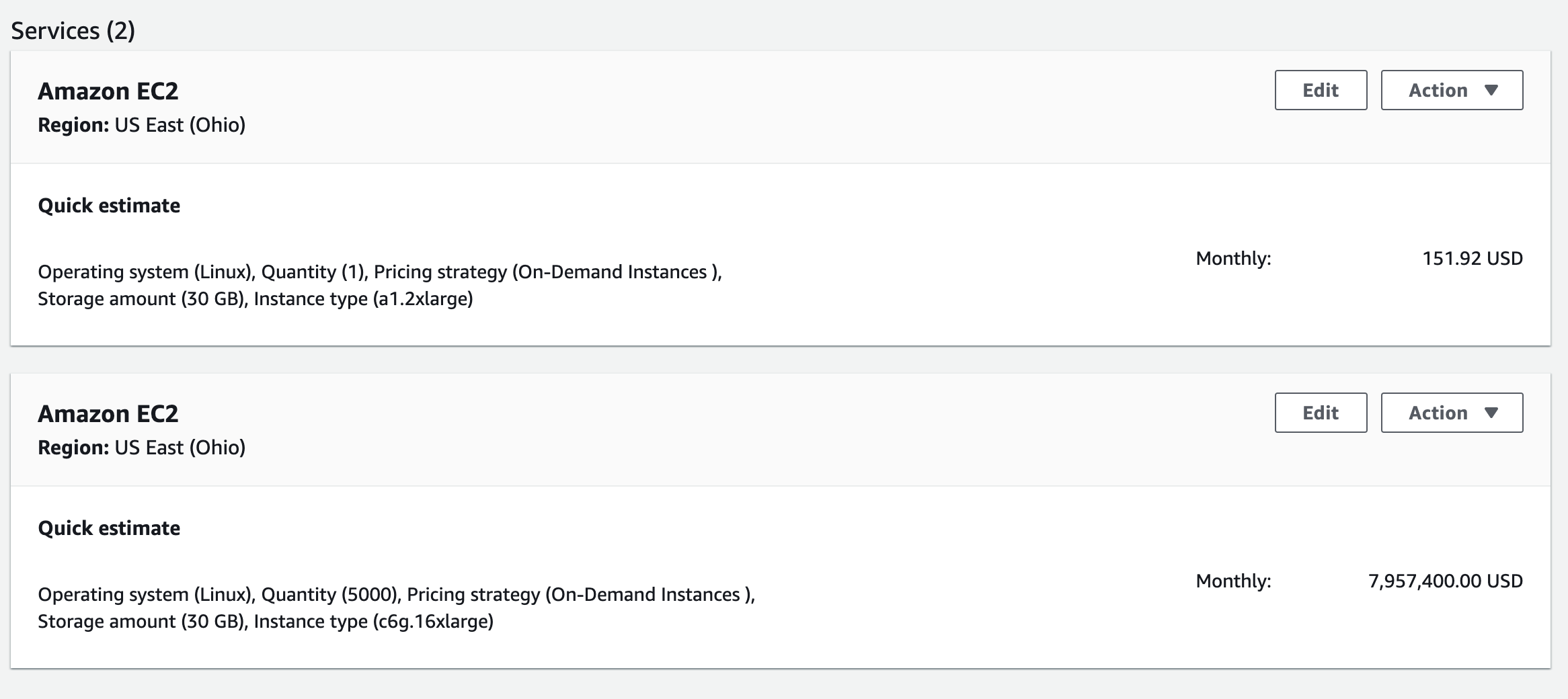
Most clusters use 48 CPU or 64 CPU physical or virtual machines as nodes in the cluster. If we need to include 5,000 nodes in our cluster, then these nodes cost about $8,000,000 per month, which is about 50,000,000 RMB, and in such a cluster a 1% increase in resource utilization is equivalent to a cost savings of 500,000 per month.
Most online tasks have low resource utilization, and a larger cluster means that more workloads can be run, and multiple peak and trough loads can be deployed together to achieve overselling, which can significantly improve the cluster’s resource utilization, and if there are enough nodes in a single cluster, we can deploy a more reasonable mix of different types of tasks to perfectly stagger the peaks of different services.
The Kubernetes community advertises that a single cluster can support up to 5,000 nodes, no more than 150,000 total Pods, no more than 300,000 total containers, and no more than 100 single-node Pods , compared to the Apache Mesos cluster with tens of thousands of nodes and the Microsoft YARN cluster with 50,000 nodes , the cluster size of Kubernetes is a full order of magnitude worse. Although Aliyun’s engineers have also achieved 5-digit cluster sizes by optimizing various components of Kubernetes, there is a relatively large gap compared to other resource management approaches.

It is important to note that while the Kubernetes community claims to support 5,000 nodes in a single cluster and has a variety of integration tests to ensure that every change does not affect its scalability, the Kubernetes is really complex, and there is no way to guarantee that every feature you use will not have problems during the scaling process. And in a production environment, we may even run into bottlenecks when the cluster scales to 1000 ~ 1500 nodes.
Every large company of any size wants to implement a larger Kubernetes cluster, but this is not a simple problem that can be solved by changing a few lines of code, it may require us to limit the use of some features in Kubernetes, and problems may occur with etcd, API servers, schedulers, and controllers during the scaling process. Some of these issues have been noted by some developers in the community, such as adding caches on nodes to reduce the load on the API servers, but it is still difficult to push for similar changes, and interested parties can try to push for similar projects.
Multi-Cluster Management
Even if a Kubernetes cluster could one day reach 50,000 nodes, we would still need to manage multiple clusters, and multi-cluster management is something the Kubernetes community is currently exploring. The SIG Multi-Cluster interest group is currently working on this. In the author’s opinion, multi-clustering in Kubernetes poses three major problems: resource imbalance, difficulty in accessing across clusters, and increased operational and management costs.
kubefed
The first project to be introduced is kubefed, a solution from the Kubernetes community that provides both resource and network management capabilities across clusters. Cluster) is responsible for the development of this project.
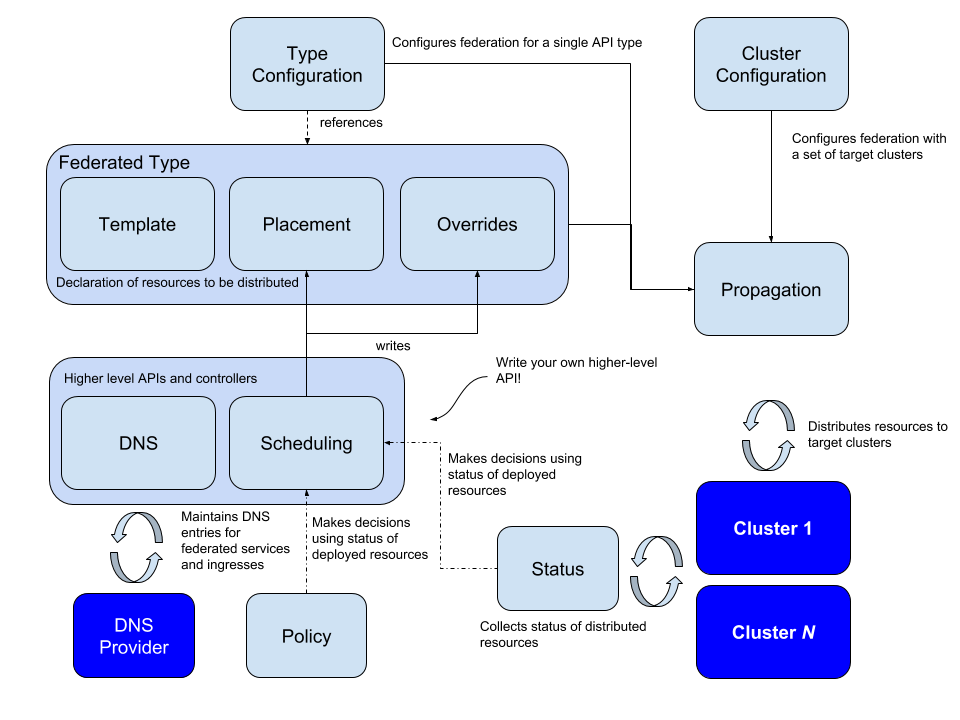
kubefed manages metadata in multiple clusters through a centralized federation console that creates corresponding federation objects for the resources in the manager cluster, e.g., FederatedDeployment.
|
|
The upper-level control panel generates the corresponding Deployment based on the FederatedDeployment specification file and pushes it to the lower-level cluster, which can normally create a specific number of copies based on the definition in the Deployment.
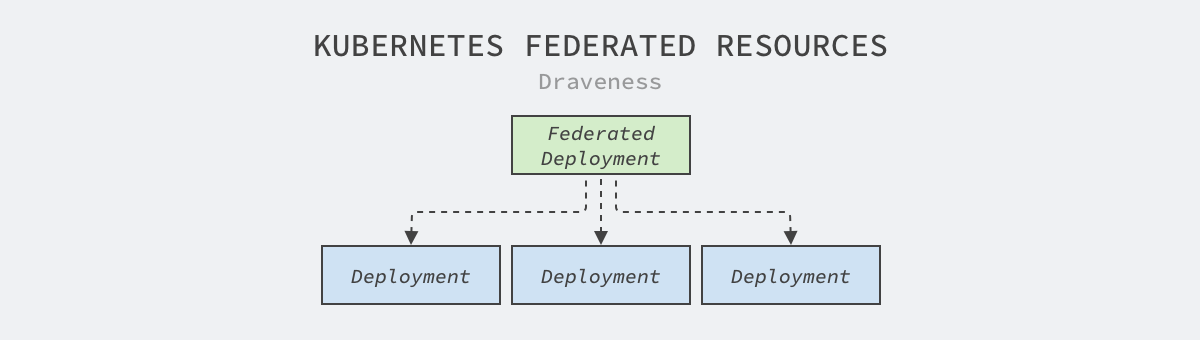
FederatedDeployment is only the simplest distribution strategy, in production environments we want to achieve complex functions such as disaster recovery through federated clusters, when you can use ReplicaSchedulingPreference to achieve a more intelligent distribution strategy in different clusters.
|
|
The above scheduling strategy enables workloads to be weighted across clusters and instances to be migrated to other clusters when cluster resources are insufficient or even problematic, so that both flexibility and availability of service deployment can be improved and infrastructure engineers can better balance the load across multiple clusters.
We can consider the main role of kubefed is to form multiple loosely coupled federated clusters and provide more advanced networking and deployment capabilities so that we can more easily solve some of the problems of resource imbalance and connectivity between clusters, however, the focus of the project does not include cluster lifecycle management.
Cluster Interface
The Cluster API is also a project related to multi-cluster management in the Kubernetes community, developed by the Cluster Lifecycle Group (SIG Cluster-Lifecycle). Its main goal is to simplify the preparation, update, and maintenance of multiple clusters through a declarative API, and you can find its terms of reference in the project’s design proposal.
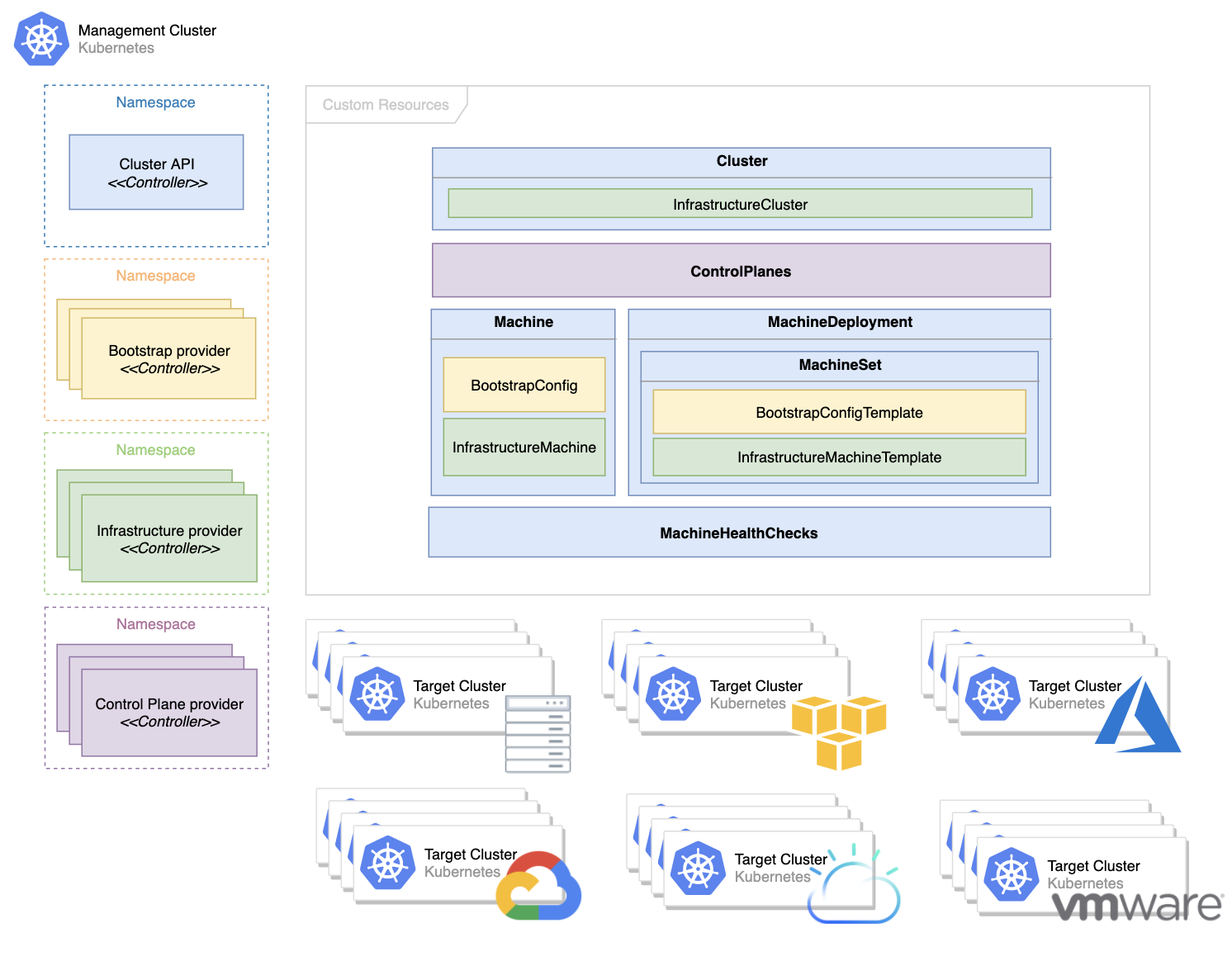
The most important resource in the project is the Machine, which represents a node in a Kubernetes cluster. When that resource is created, the provider-specific controller initializes and registers the new node into the cluster based on the machine’s definition, and also performs operations to reach the user’s state when that resource is updated or deleted.
This strategy has some similarities to Ali’s approach to multi-cluster management in that they both use declarative APIs to define the state of machines and clusters, and then use Kubernetes’ native Operator model to manage lower-level clusters at a higher level, which can significantly reduce cluster operations and improve cluster operational efficiency, although similar projects do not consider cross-cluster resource management and network management.
Application Scenarios
We talk about some interesting application scenarios in Kubernetes in this section, including the current state of application distribution methods, batch scheduling tasks, and hard multi-tenancy support in clusters, which are of interest in the community and a current blind spot for Kubernetes.
Application Distribution
The Kubernetes master project provides several minimal ways to deploy applications, namely Deployment, StatefulSet, and DaemonSet, resources for stateless services, stateful services, and daemons on nodes, respectively. These resources provide the most basic policies, but they can’t handle more complex applications.

With the introduction of CRD, the current community’s application management group (SIG Apps) basically does not introduce big changes to the Kubernetes main repository, and most of the changes are patches on existing resources. Many common scenarios, such as DaemonSet that runs only once and features like Canary and Bluegreen deployment, have many problems with the current resources, such as StatefulSet getting stuck in the initialization container and not being able to roll back and update.
We can understand that the community does not want to maintain more basic resources in Kubernetes. 90% of the scenarios can be covered by a few basic resources, and the rest of the various complex scenarios can be implemented by other communities by way of CRD. However, the authors believe that if the community can implement more high quality components upstream, this is a valuable and important work for the whole ecosystem, and it should be noted that if you want to be a contributor in the Kubernetes project, SIG Apps may not be a good choice.
Batch Scheduling
Running workloads such as machine learning, batch tasks, and streaming tasks has not been Kubernetes’ strong suit since day one. Most companies use Kubernetes to run online services to handle user requests, and Yarn-managed clusters to run batch loads.
Most online tasks are stateless services that can be migrated across different machines and hardly have strong dependencies on each other; however, many offline tasks have complex topologies, with some tasks requiring multiple jobs to be executed together and some tasks needing to be executed sequentially according to dependencies, a complex scheduling scenario that is difficult to handle in Kubernetes.
Before the introduction of the scheduling framework in the Kubernetes scheduler, all Pods were unrelated in the view of the scheduler, but with the scheduling framework, we can implement more complex scheduling policies in the scheduling system, such as a PodGroup that guarantees simultaneous scheduling of a group of Pods, which is very useful for Spark and TensorFlow tasks.
|
|
Volcano is also a batch task management system built on Kubernetes14 that can handle machine learning, deep learning, and other big data applications and can support multiple frameworks including TensorFlow, Spark, PyTorch, and MPI.

While Kubernetes is capable of running some batch tasks, it is still very far from replacing older resource management systems like Yarn in this space, and it is believed that most companies will be maintaining both Kubernetes and Yarn technology stacks to manage and run different types of workloads for a longer period of time.
Hard Multi-Tenancy
Multi-tenancy means that the same software instance can serve different groups of users. Multi-tenancy in Kubernetes means that multiple users or groups of users use the same Kubernetes cluster. Today, Kubernetes is still hard to do with hard multi-tenancy support, which means that multiple tenants in the same cluster do not affect each other and do not perceive each other’s presence.
Hard multi-tenancy is an important and difficult topic in Kubernetes. A typical multi-tenancy scenario is a shared apartment, where multiple tenants share the infrastructure in the house, and hard multi-tenancy requires that multiple visitors do not interact with each other. ](https://draveness.me/kuberentes-limitations/#fn:15), yet while there are many interested engineers, the results are very limited.
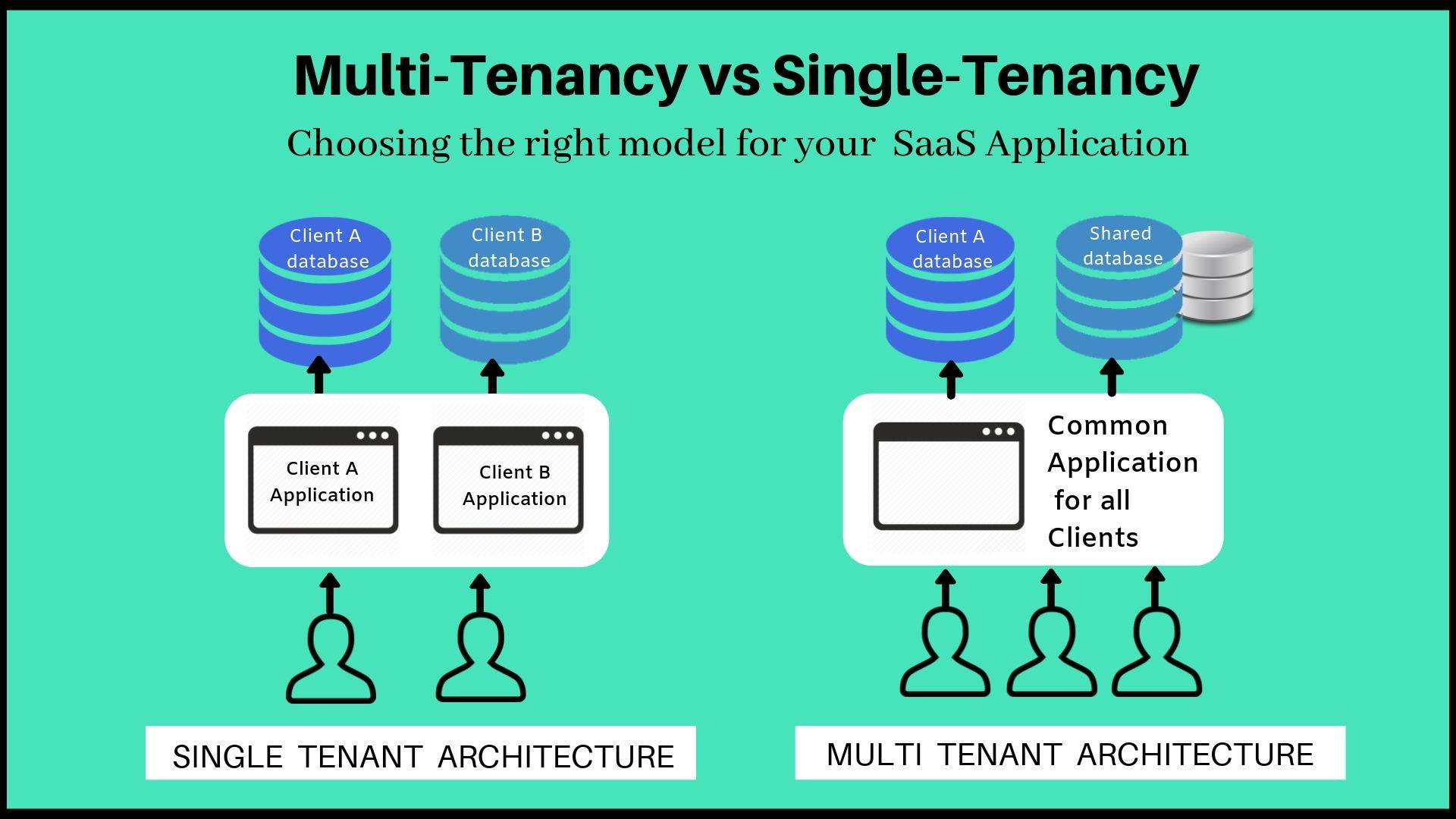
Although Kubernetes uses namespaces to divide groups of VMs, this also makes it difficult to achieve true multi-tenancy. What exactly does multi-tenancy support do? Here is a brief list of the benefits that multi-tenancy brings.
- The additional deployment costs associated with Kubernetes are prohibitive for small clusters. Stable Kubernetes clusters typically require at least three master nodes running etcd, and if most clusters are small, these additional machines can introduce a high level of additional overhead.
- Containers running in Kubernetes may need to share physical and virtual machines, and some developers may have experienced their services being impacted by other businesses within their companies because the containers on the host may isolate CPU and memory resources, but not resources such as I/O, network and CPU cache, which are relatively difficult to isolate.
If Kubernetes can implement hard multi-tenancy, it will not only be a boon for cloud providers and users of small clusters, it will also be able to isolate the impact between different containers and prevent potential security issues, though this is still difficult to achieve at this stage.
Summary
Every technology has its own lifecycle, the lower the technology lifecycle will be longer, and the higher the technology lifecycle will be shorter, although Kubernetes is the leader of the container world today, but no one can say what the future will be. We should always be aware of the strengths and weaknesses of the tools at hand and spend some time learning the essence of the design in Kubernetes, but if at some point in the future Kubernetes becomes a thing of the past, we should be happy that there will be better tools to replace it.