Disk for persistent storage is not a scarce resource today, but CPU and memory are still relatively expensive resources, and this article will describe how memory, a scarce resource in computers, is managed.
Memory management systems and modules play an important role in operating systems and programming languages. The use of any resource is inseparable from the two actions of requesting and releasing, and two important processes in memory management are memory allocation and garbage collection, and how a memory management system can use limited memory resources to provide services to as many programs or modules as possible is its core goal.

Although most systems split memory management into several complex modules and introduce some intermediate layers to provide caching and conversion functions, memory management systems can actually be reduced to two modules, namely Allocator and Collector. Of course, in addition to these two modules, a third module - the Mutator - is introduced in any study of memory management to help us understand the workflow of the system.
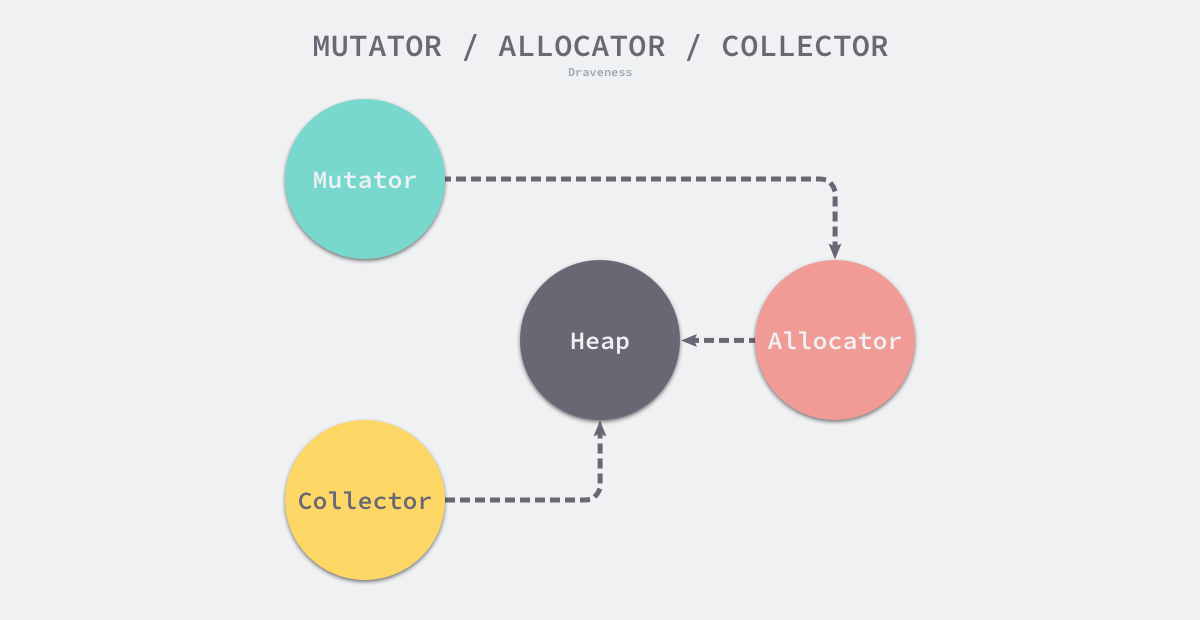
- User programs (Mutator) - can create objects or update the pointers held by objects through the allocator.
- Memory allocator (Allocator) - handles memory allocation requests from user programs.
- Garbage collector - marks objects in memory and reclaims unneeded memory.
The above three modules are the core of the memory management system, they can maintain a relatively balanced state of managed memory during the operation of the application. We will also focus on these three different components when introducing memory management, this section will introduce the theory related to memory management in detail from three aspects: basic concepts, memory allocation and garbage collection.
Basic Concepts
This section will introduce the basic issues in memory management. We will briefly introduce the memory layout of an application, common concepts of design in memory management, and several different approaches to memory management in a broad sense.
Memory Layout
It is important to note that unlike the main memory and physical memory of an operating system, virtual memory is not a concept that actually exists physically, it is a logical concept built by the operating system. The memory of an application is generally divided into several different areas as follows.
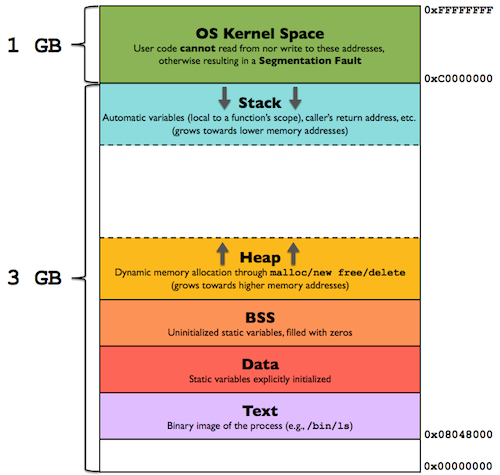
- Stack - an area that stores local variables and parameters of functions during program execution, growing from high to low addresses.
- Heap area (Heap) - dynamically allocated memory area, managed by the
malloc,new,freeanddeletefunctions. - Uninitialized variables section (BSS) - stores uninitialized global and static variables.
- Data area - stores global and static variables that have predefined values in the source code.
- Code area (Text) - stores the read-only program execution code, i.e. machine instructions.
Although the above five different segments store different data, we can divide them into three different types of memory allocations, namely static memory, stack memory and heap memory.
Static Memory
Static memory dates back as far as the ALGOL language in the 1960’s, and static variables can have a lifecycle that spans the entire program. The layout of all static memory is confirmed during compilation and no new static memory is allocated during runtime. Because all static memory is confirmed during compilation, a fixed size of memory space is requested for these variables, and these fixed memory spaces can also result in static memory not supporting recursive calls to functions.
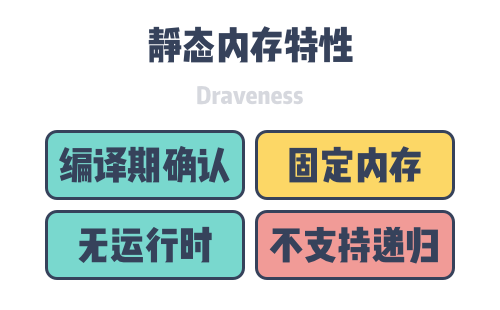
Because the compiler can determine the addresses of static variables, they are the only variables in the program that can be addressed using absolute addresses. When a program is loaded into memory, static variables are stored directly in the BSS area or data area of the program, and these variables are also destroyed when the program exits. It is because of these characteristics of static memory that we do not need to introduce a static memory management mechanism at program runtime.
Stack Memory
The stack is a common memory space in applications that manages stored data following the last-in, first-out rule. When an application calls a function, it adds the arguments of the function to the top of the stack, and when the function returns, it destroys the entire stack used by the current function. The instructions for stack memory management are also all generated by the compiler, and we will use the registers BP and SP to store information about the current stack without any involvement of engineers at all, although we can only allocate large blocks of fixed data structures on the stack.

Because stack memory is released dynamically and linearly, it can support recursive function calls, although the introduction of a dynamic stack allocation strategy at runtime can also lead to program stack memory overflows, which can cause stack overflow errors if the recursive functions we use in our programming language exceed the program’s memory limit.
Heap Memory
Heap memory is also a common memory in applications. It enables the callee of a function to return memory to the caller and provides greater flexibility in memory allocation than stack memory, which is automatically reclaimed when the scope of a function is exceeded, although the flexibility it provides also brings memory safety issues such as memory leaks and hanging pointers.
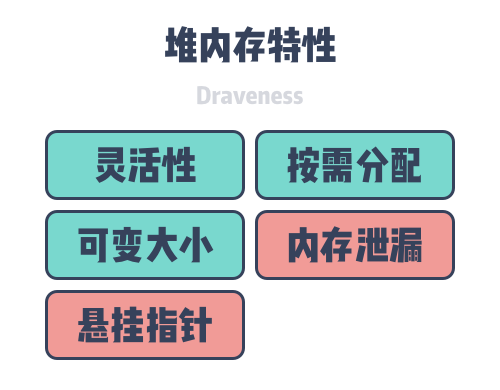
Because memory on the heap is manually requested by the engineer, it needs to be released at the end of use. Once the used memory is not released, it will cause a memory leak and take up more system memory; if it is released before the end of use, it will lead to dangerous hanging pointers, where other objects point to memory that has been reclaimed or reused by the system. Although the process memory can be divided into many areas, when we talk about memory management, we generally refer to the management of heap memory, that is, how to solve the memory leak and hanging pointer problems.
Management style
We can simply divide memory management into two ways: manually managed memory generally means that the engineer manually requests memory through functions such as malloc when needed and calls functions such as free to free memory when not needed; automatically managed memory is automatically managed by the programming language’s memory management system, which in most cases does not require the engineer’s involvement and can automatically free memory that is no longer in use.
Manual management and automatic management are just two different ways of memory management. This section will introduce each of the two ways of memory management and the different choices made by different programming languages.
Manual Management
Manual memory management is a more traditional way of memory management. System-level programming languages like C/C++ do not contain narrowly automatic memory management mechanisms, and engineers need to actively request or release memory. If the ideal engineer exists who can precisely determine the timing of memory allocation and release, a human memory management strategy can improve program performance and not cause memory security problems using manual memory management, as long as it is done with sufficient precision.
But such ideal engineers often do not exist in reality. Human Factor always brings some errors, and memory leaks and hanging pointers are basically the most frequent errors in languages like C/C++. Manual memory management also takes up a lot of the engineer’s energy, and many times it requires thinking about whether objects should be allocated to the stack or the heap and when the memory on the heap should be released, which is still relatively expensive to maintain and is a tradeoff that must be made.
Automatic Management
Automatic memory management is basically standard in modern programming languages. Since the memory management module is very deterministic, we can introduce automatic memory management methods in the compile-time or run-time of programming languages. The most common automatic memory management mechanism is garbage collection, but in addition to garbage collection, some programming languages also use automatic reference counting to assist in memory management.
Automatic memory management can save engineers a lot of time in dealing with memory, allowing them to focus on core business logic and improve development efficiency; in general, such automatic memory management can be a good solution to memory leaks and hanging pointers, but it also brings additional overhead and affects the language’s runtime performance.
Object Headers
The object header is the key meta-information for automatic memory management, and is accessed by memory allocators and garbage collectors to obtain relevant information. When we request memory through functions such as malloc, we often need to align the memory to the size of the pointer (4 bytes on 32-bit architectures, 8 bytes on 64-bit architectures), and in addition to the memory used for alignment, each object on the heap also needs the corresponding object header.
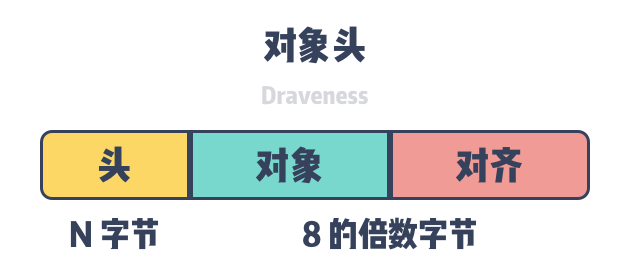
Different automatic memory management mechanisms store different information in the object header. Programming languages that use garbage collection store marker bits MarkBit/MarkWord, e.g., Java and Go, and those that use automatic reference counting store reference count RefCount in the object header, e.g., Objective-C.
Programming languages choose to store the object header with the object, but because the storage of the object header may affect the local nature of data access, some programming languages may create a separate memory space to store the object header and establish an implicit link between the two via memory addresses.
Memory Allocation
A memory allocator is an important component of a memory management system whose main responsibility is to handle memory requests from user programs. Although the duties of memory allocators are very important, the allocation and use of memory its a process that increases entropy in the system , so the design and working principle of memory allocators is relatively simple, we introduce two types of memory allocators here.
All memory allocators in the memory management mechanism are actually variants of the above two different allocators, which are designed with completely different ideas and also have very different application scenarios and characteristics, and we introduce here the principles of these two types of memory allocators in turn.
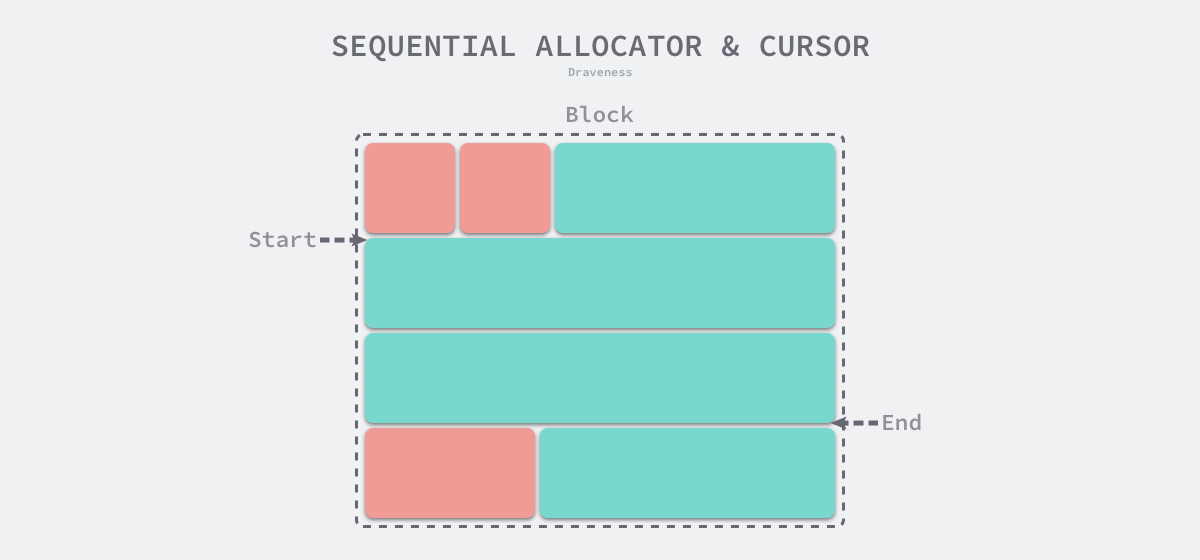
Linear Allocator
Linear allocation (Bump Allocator) is an efficient way to allocate memory, but has major limitations. When we use a linear allocator in a programming language, we only need to maintain a pointer to a specific location in memory. When the user program requests memory, the allocator simply checks the remaining free memory, returns the allocated memory area and modifies the location of the pointer in memory, i.e., moves the pointer in the following figure.
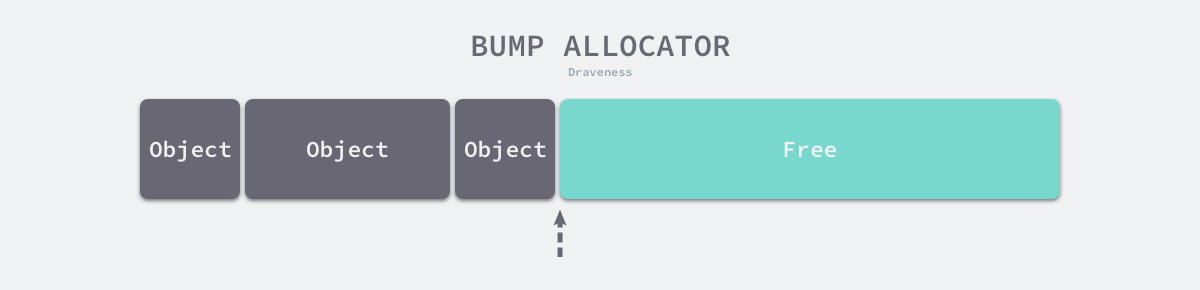
Based on the principle of linear allocator, we can presume that it has a faster execution speed and lower implementation complexity; however, the linear allocator cannot reuse memory when it is freed. As shown in the figure below, the linear allocator is unable to reuse the portion of memory in red if the allocated memory is reclaimed.
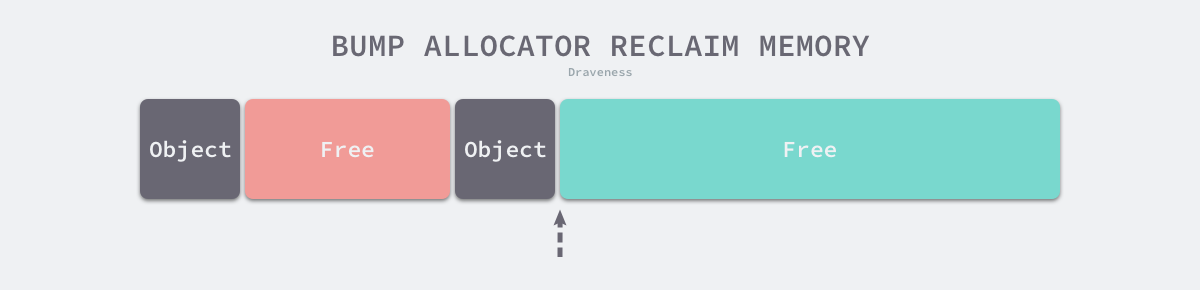
It is because of this characteristic of linear allocators that we need suitable garbage collection algorithms to work with. Algorithms such as Mark-Compact, Copying GC, and Generational GC can improve the performance of a memory allocator by periodically merging free memory with the efficiency of a linear allocator by sorting out the fragmentation of living objects in a copy-based manner.
Because the use of linear allocators requires a copy-based garbage collection algorithm, languages such as C and C++ that need to expose pointers directly to the public cannot use this strategy, and we will detail the design principles of common garbage collection algorithms in the next section.
Free-List Allocator
The Free-List Allocator reuses memory that has already been freed and maintains an internal data structure similar to a chain table. When a user program requests memory, the free-list allocator sequentially traverses the free memory blocks, finds a large enough memory, then requests new resources and modifies the chain table to.
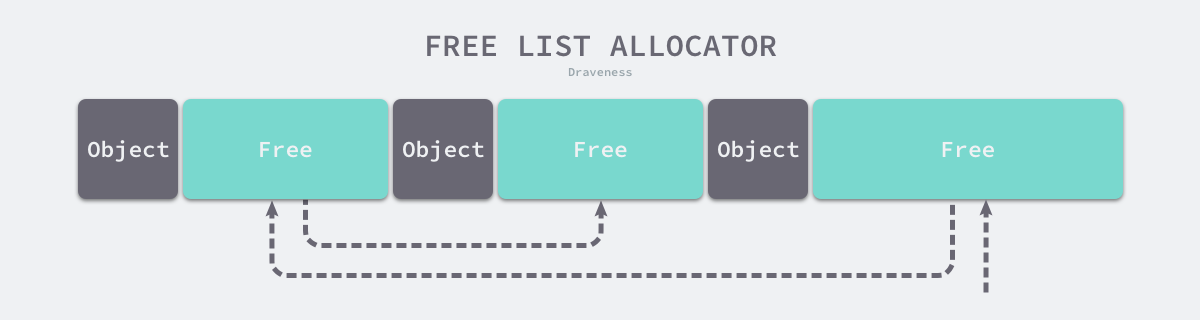
Because different memory blocks are connected in a chained table, an allocator that uses this way of allocating memory can reuse the reclaimed resources, but because allocating memory requires traversing the chain table, its time complexity is O(n) . The free link table allocator can choose different strategies to select among the memory blocks in the link table, the most common ones are the following four ways.
- First-Fit (First-Fit) - traversing from the head of the chain table and selecting the first memory block whose size is larger than the requested memory.
- Cyclic first adaptation (Next-Fit) - traversing from the end of the last traversal and selecting the first memory block whose size is larger than the requested memory.
- Best-Fit - traverses the entire chain from the head of the chain and selects the most suitable block.
- Segregated-Fit - splitting the memory into multiple chained tables, each with memory blocks of the same size, and requesting memory by first finding the chained table that meets the conditions and then selecting the appropriate memory block from the chained table.
Without going into the first three of the four strategies mentioned above, the memory allocation strategy used by the Go language is somewhat similar to the fourth strategy, and we understand the principle of this strategy through the following diagram.
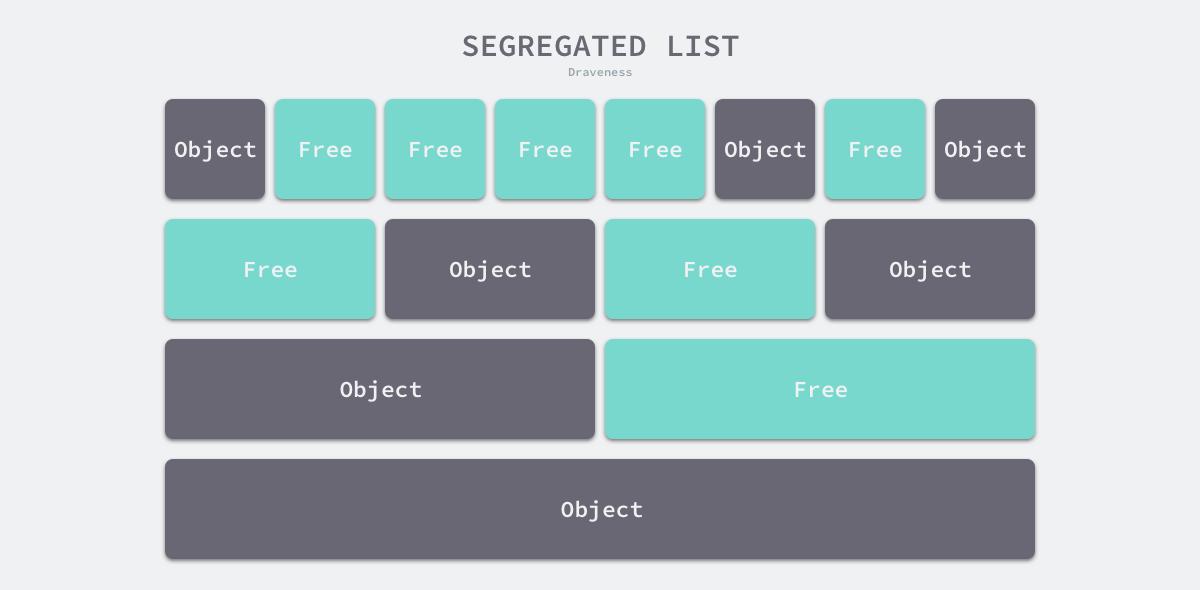
As shown in the figure above, this policy splits the memory into a chain of 4, 8, 16, and 32-byte memory blocks. When we request 8 bytes of memory from the memory allocator, we find the free block in the second chain in the figure above and return it. The isolation-adapted allocation strategy reduces the number of memory blocks to be traversed and improves the efficiency of memory allocation.
Garbage collection
Garbage collection is an automated form of memory management. The garbage collector is an important component of the memory management system. The memory allocator takes care of requesting memory on the heap, and the garbage collector releases objects that are no longer in use by the user program. When it comes to garbage collection, many people’s first reaction may be to pause the program (stop-the-world, STW) and garbage collection pause (GC Pause). Garbage collection does bring STW, but it is not all about garbage collection, this section will introduce garbage collection and garbage collector related concepts and theories in detail.
What is garbage
Before we can analyze garbage collection in depth, we need to clarify the definition of garbage in garbage collection. A clear definition can help us understand more precisely the problem that garbage collection solves and its responsibilities. Garbage in computer science includes objects, data and other memory areas in a computer system that will not be used in future computations because memory resources are limited, so we need to return the memory occupied by this garbage back to the heap and reuse it in the future
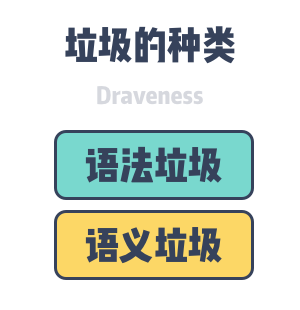
Garbage can be divided into semantic garbage and syntactic garbage. Semantic Garbage is an object or data in a computer program that will never be accessed by the program; Syntactic Garbage is an object or data in the memory space of a computer program that is unreachable from the root object.
Semantic Garbage is objects that will not be used and may include discarded memory, unused variables. The garbage collector cannot solve the problem of semantic garbage in the program and we need to identify part of the semantic garbage by the compiler. Syntactic garbage is the objects in the object graph that cannot be reached from the root node, so syntactic garbage is semantic garbage in general:.
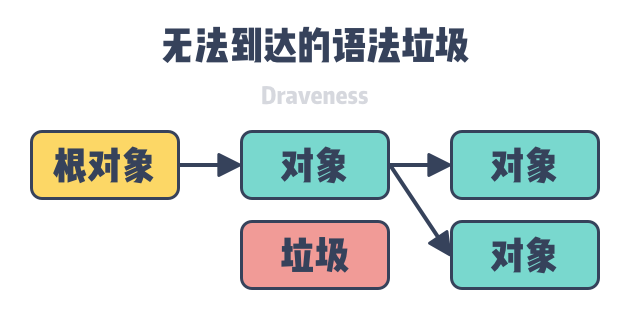
What the garbage collector can find and recycle is the syntactic garbage that is unreachable in the object graph. By analyzing the reference relationships between objects, we can get the objects that are unreachable at the root node in the graph, and these unreachable objects will be recycled in the cleanup phase of the garbage collector.
Collector performance
Throughput and maximum pause time (Pause time) are two main metrics to measure the garbage collector. Besides these two metrics, heap memory usage efficiency and access locality are also common metrics for garbage collection, and we briefly introduce the impact of these metrics on the garbage collector as follows.
Throughput
The throughput of the garbage collector is actually interpreted in two ways. One interpretation is the speed of the garbage collector during the execution phase, that is, the ability to mark and clean up memory per unit of time, which we can calculate by dividing the heap memory by the total time used by the GC.
|
|
Another way to calculate the throughput is to use the total time the program runs divided by the total time all GC loops run. The GC time is extra overhead for the whole application, and this metric shows the percentage of resources taken up by the extra overhead, and from this, we can also see how efficiently the GC is executed.
Maximum Pause Time
Since STW is triggered during some phases of garbage collection, the user program is not able to execute. The maximum STW time can seriously affect the tail delay of the program to process requests or provide services, so this is also a metric we need to consider when measuring the performance of the garbage collector.
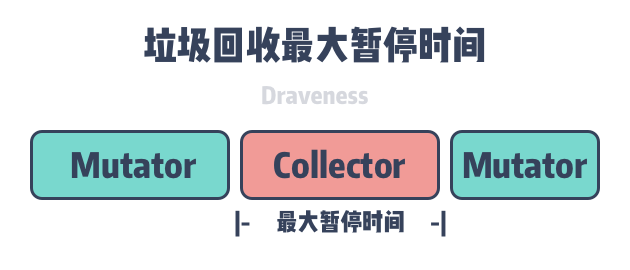
Programming languages that use the STW garbage collector, the user program cannot be executed during all phases of garbage collection. A garbage collector with concurrent tag removal executes all the work that can be executed concurrently with the user program, and is able to reduce the maximum program pause time, the
Heap Usage Efficiency
Heap usage efficiency is also an important measure of a garbage collector. In order to be able to identify garbage, we need to introduce object headers containing specific information in the memory space, these object headers are additional overhead brought by the garbage collector, just as network bandwidth may not be the final download speed, the transmission of protocol headers and checksums will take up network bandwidth, the size of object headers will eventually affect the efficiency of heap memory usage; in addition to object headers, the fragmentation that occurs during heap usage also In addition to object headers, the fragmentation that occurs during heap usage also affects the efficiency of memory usage. In order to ensure memory alignment, we leave many gaps in memory, and these gaps are also the overhead brought by memory management.
Access Locality
Access locality is a topic we have to talk about when discussing memory management. Spatial locality means that the processor will always access the same or adjacent memory area repeatedly in a short period of time, and the operating system will manage the memory space in terms of memory pages. Ideally, a reasonable memory layout will allow both the garbage collector and the application to take full advantage of spatial locality to improve the execution efficiency of the program.
Collector types
The types of garbage collectors in general can be divided into Direct garbage collectors and Tracing garbage collectors. Direct garbage collectors include Refernce-Counting, Tracing garbage collectors include strategies such as tag cleanup, tag compression, copy garbage collection, etc., while Refernce-Counting collectors are not particularly common, and a few programming languages use this approach to memory management.
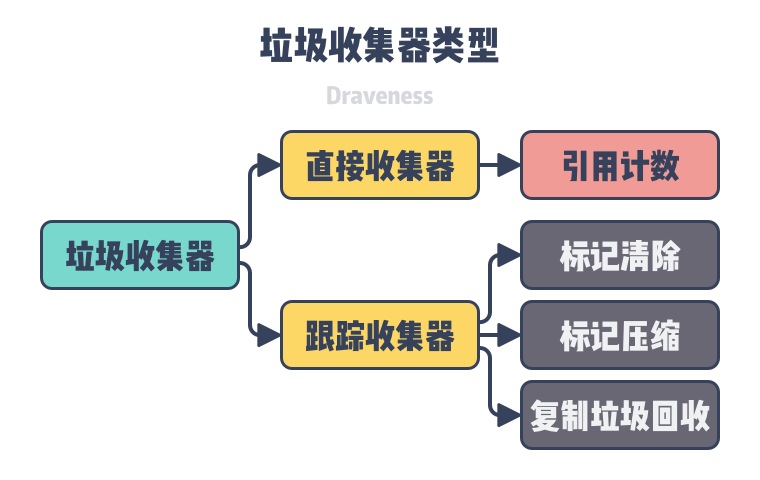
In addition to the relatively common garbage collection methods of direct and trace garbage collectors, there are also ways to manage memory using ownership or manually. We will cover the design principles of the four different types of garbage collectors, reference counting, tag removal, tag compression, and copy garbage collection, as well as their advantages and disadvantages in this section.
Reference Counting
A reference counting-based garbage collector is a direct garbage collector that modifies the reference count between objects when we change the reference relationship between them. In programming languages that use reference counting, garbage collection occurs in real time while the user’s program is running, so in theory there is no STW or apparent garbage collection pause.
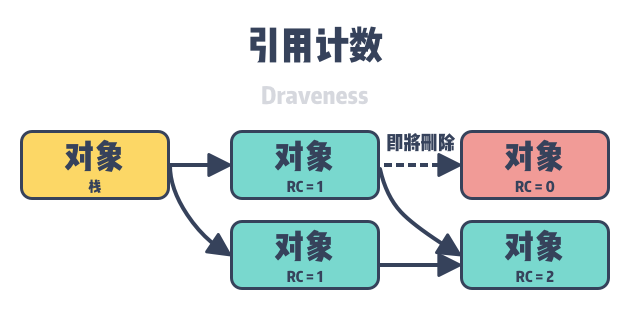
As shown above, reference-counting-based garbage collectors require applications to store reference counts in the object header, and reference counts are the additional overhead introduced in memory by this type of collector. We present here an example of how reference counting works, if the following assignment statement is used in a programming language that uses a reference counting collector.
|
|
- the reference count of the original object referenced by
obj,old_ref, is minus one; 2. the reference count of the new object referenced byobjis plus one; and - the reference count of the new object
new_refreferenced by the objectobjwill be plus one; and - if the reference count of an
old_refobject goes to zero, we free the object to reclaim its memory.
Two of the more common problems associated with this type of garbage collector are recursive object recycling and circular references.
- recursive recycling - whenever the object’s reference relationship changes, we need to calculate the object’s new reference count, and once the object is freed, we need to recursively access all references to that object and subtract one from the referenced object’s counter, which may cause a GC pause once a larger number of objects are involved.
- circular references - mutual references to objects are also very common in object graphs, and if the references between objects are all strong references, circular references can cause the counters of multiple objects to not go to zero, which can eventually cause memory leaks.
Recursive recycling is a problem that has to be faced when using reference counting, and it is difficult for us to solve the problem in engineering; however, programming languages that use reference counting can use weak references to solve the problem of circular references, weak references are also reference relations between objects, the establishment and destruction of weak reference relations do not modify the reference count of both sides , which can avoid weak reference relations between objects, but it also requires engineers to make additional and correct judgments about reference relations.
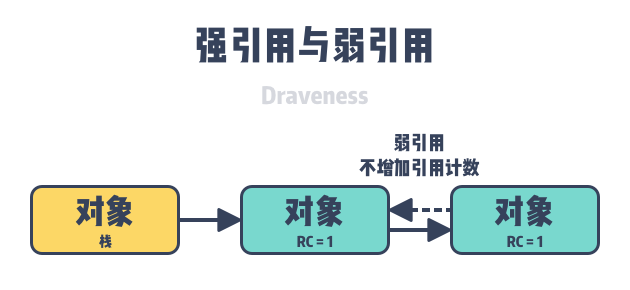
In addition to weak references, some programming languages also add marker clearing techniques to reference counting to solve the problem of circular references by traversing and marking objects in the heap that are no longer in use.
A reference counting garbage collector is a non-moving garbage collection strategy that does not move existing objects during memory collection. Many programming languages expose direct memory pointers to engineers, so C, C++, and Objective-C programming languages can actually use reference counting to solve memory management problems.
Mark-Sweep
Mark-Sweep is the simplest and most common garbage collection strategy. It is performed in two phases, Mark and Clean, where the mark phase scans the heap for surviving objects using depth-first or breadth-first algorithms, and the clean phase recovers the garbage in memory. When we use this strategy to recover garbage, it first traverses all the objects in the heap from the root node along the object’s reference, and the objects that can be accessed are the living objects, and the objects that cannot be accessed are the garbage in memory.
As shown in the figure below, the memory space contains several objects, we start from the root object and iterate through the object’s children and mark the objects accessible from the root node as alive, i.e. A, C and D. The remaining three objects, B, E and F, are not accessible from the root node, so they are treated as garbage.
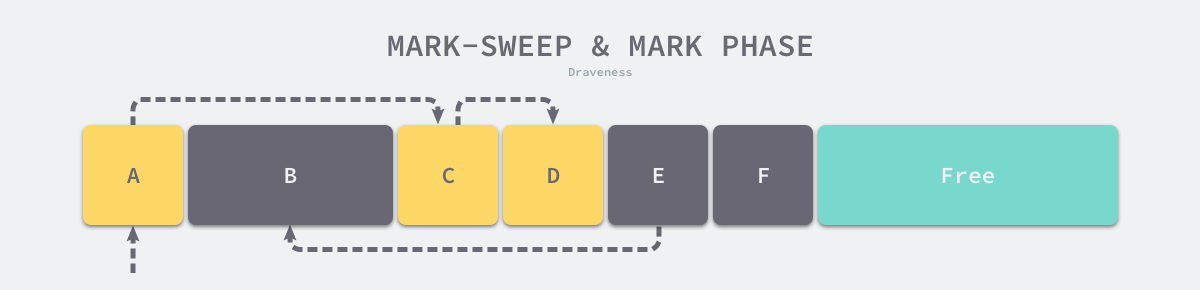
At the end of the marking phase, it enters the clearing phase, where the collector traverses all objects in the heap in turn, releasing the three unmarked objects B, E and F and chaining the new free memory space in a chain structure for the memory allocator.
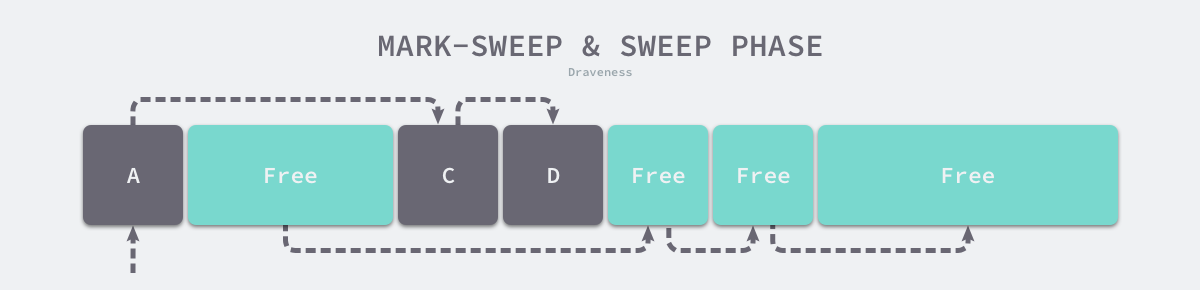
Programming languages that use mark-cleaning algorithms need to include a Mark Bit in the object header to indicate that the object is alive. The Mark Bit is not compatible with the OS write-time replication because even if the object in the memory page is not modified, the garbage collector will modify the Mark Bit adjacent to the object in the memory page resulting in a replication of the memory page. We can avoid this situation by using Bitmap tags, which indicate the existence of an object and store the tags separately from the object, and only need to traverse the bitmap when cleaning up the object, which can reduce the additional overhead of the cleanup process.
As shown above, a garbage collector using the marker clearing algorithm generally uses an allocator based on the idle chain table, because the objects are recycled in place when they are not used, so long running programs will have a lot of memory fragmentation, which reduces the allocation efficiency of the memory allocator.
The mark-and-clear strategy is a simple garbage collection strategy to implement, but it also has a serious memory fragmentation problem. The simple memory recycling strategy also increases the overhead and complexity of memory allocation, and when the user program requests memory, we also need to find a large enough block in memory to allocate memory.
Mark-Compact
Mark-Compact is also a common garbage collection algorithm. Similar to the mark-clean algorithm, the execution of Mark-Compact can be divided into two phases, Mark and Compact. In the mark phase, we also traverse the objects from the root node to find and mark all living objects; in the compact phase, we ‘squeeze out’ the gaps between the living objects by arranging them in a tightly packed manner.
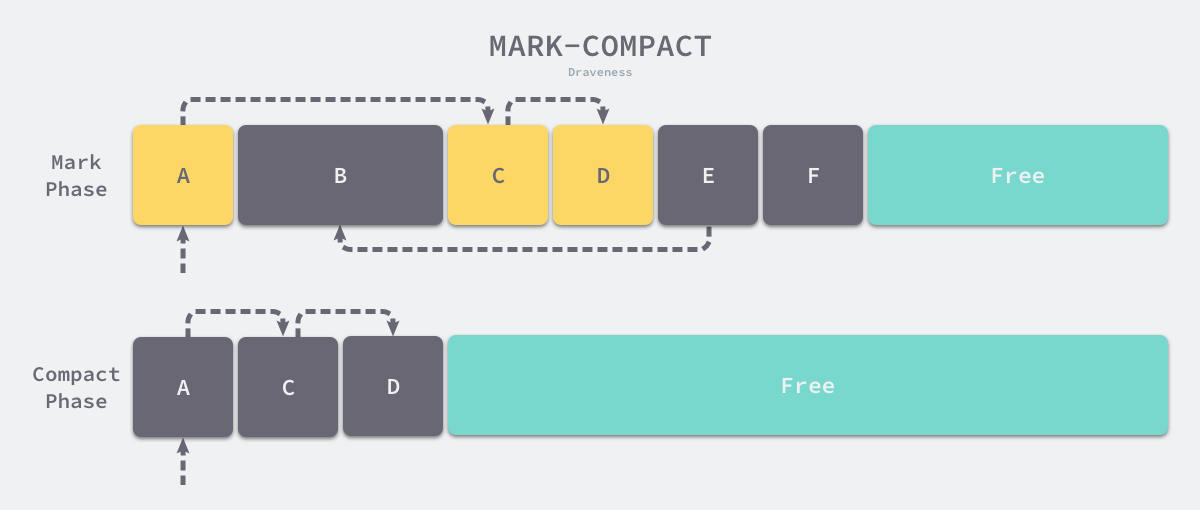
Because we need to move the surviving objects in the compression phase, this kind of moving collector, if the programming language supports accessing objects using pointers, then we cannot use this algorithm. The process of tagging is relatively simple, and we focus here on the compression phase of the Lisp 2 compression algorithm as an example:
- calculating the final location of the current object after migration and storing the location in the Forwarding Address (Forwarding Address).
- pointing references to the new location based on the forwarding address of the current object’s children.
- move all surviving objects to the location of the forwarding address in the object header.
From the above process we can see that the programming language using the marker compression algorithm not only has to store the marker bits in the object header, but also the forwarding address of the current object, which adds additional overhead to the object in memory.
The implementation of the marker compression algorithm is complex and requires three iterations of the objects in the heap during execution. As a moving garbage collector, it is not applicable to programming languages such as C and C++; the introduction of the compression algorithm reduces memory fragmentation in the program and we can directly use the simplest linear allocator to quickly allocate memory for user programs.
Copying Garbage Collection
Copying GC is also a type of tracked garbage collector that divides the application heap into two equal-sized regions, as shown in the figure below, where the left region is responsible for allocating memory space for user programs and the right region is used for garbage collection.
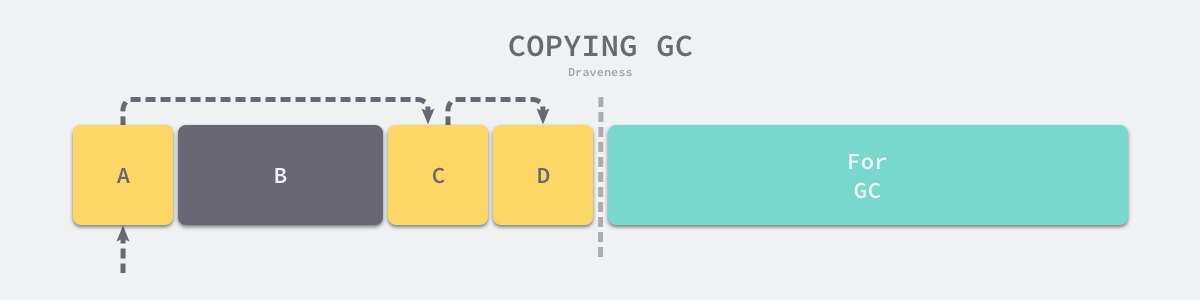
Out-of-memory (OOM) occurs when the user program uses more memory than the left-hand area in the above diagram, at which point the garbage collector opens a new garbage collection loop. The execution process of replication garbage collection can be very four phases as follows.
- replication phase - traversing the objects in memory from the GC root node and migrating the surviving objects found to the right side of the memory.
- forwarding phase - setting the forwarding address (Forwarding Address) of the new object in the object header of the original object or at the original location, from which other objects can be forwarded to the new address if they refer to it.
- repair pointer - traverse the reference held by the current object, if the reference points to an object in the left heap, back to the new object found in the first step of migration.
- swap phase - swapping the left and right memory areas after the object to be migrated does not exist in memory.
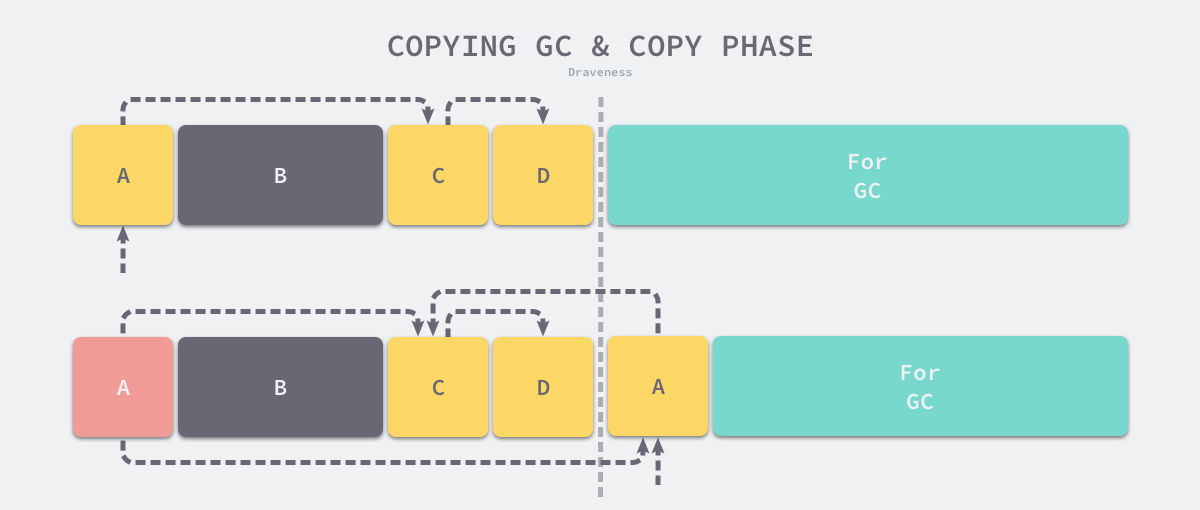
As shown above, when we copy the A object to the right area, it will point the original A object to the new A object so that other objects referencing A can quickly find its new address; because the copy of the A object is a ‘pixel-level copy’, the A object will still point to the C object in the left memory, and then we need to copy the C object to the new memory area and modify the pointer of the A object. At the end, when there is no object to copy, we can just swap the pointers of the two memory regions.
Copy garbage collection copies objects as well as the marker compression algorithm and can reduce memory fragmentation in the program, and we can use a linear allocator to quickly allocate memory for the user program. Since only half of the heap needs to be scanned and the number of heap traversals is reduced, the garbage collection time can be reduced, but this also reduces memory utilization.
Advanced Garbage Collection
Memory management is a relatively large topic. We introduced some basic concepts of garbage collection in the previous subsection, including the common garbage collection algorithms: reference counting, token clearing, token compression, and copy garbage collection, which are all relatively basic garbage collection algorithms.
Generational garbage collector
Generational garbage collection is a relatively common garbage collection algorithm in production environments, and is based on the Weak Generational Hypothesis – most objects The algorithm is based on the Weak Generational Hypothesis – most objects become garbage immediately after they are generated, and only a very small number of objects survive for a long time. According to this experience, generational garbage collection divides the objects in the heap into multiple generations, and the triggering conditions and algorithms for garbage collection in different generations are completely different.
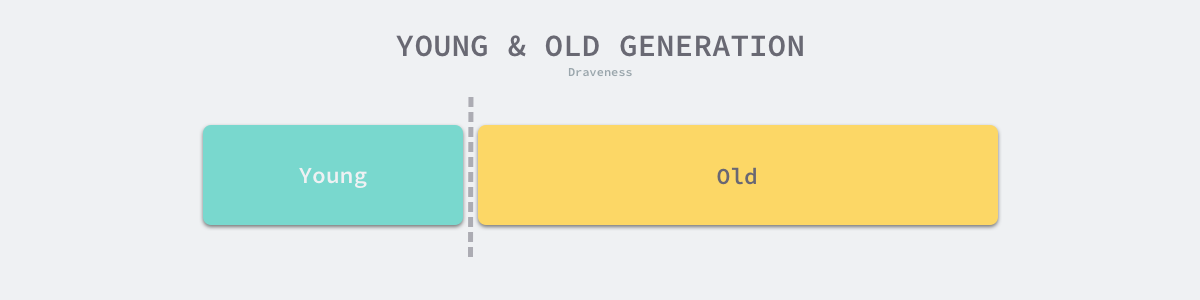
The common generational garbage collection will divide the heap into Young and Old ages. All objects will enter the Young age when they are just initialized, and the frequency of triggering GC is higher in the Young age.
The garbage collection in the young age is called Minor GC cycle, while the garbage collection in the old age is called Major GC cycle, and Full GC cycle generally refers to the garbage collection of the whole heap.
Green-age garbage collection only scans a portion of the entire heap, which reduces the heap size and program pause time required for a garbage collection, and increases the throughput of garbage collection. However, generation separation also introduces complexity to garbage collection, the most common problem is Intergenerational Pointer, i.e. the old generation refers to the objects in the young generation, if there are intergenerational references in the heap, then in the Minor GC loop we should not only traverse the root object of garbage collection, but also start from the object containing the intergenerational references Mark the objects in the Cyan era.
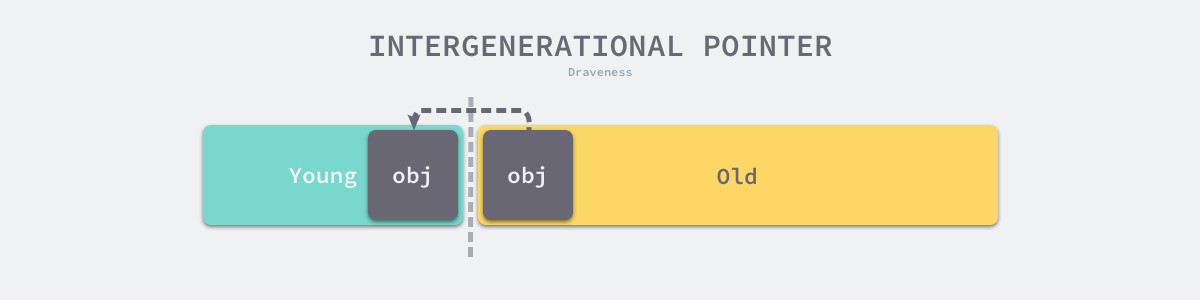
To handle cross-references in generational garbage collection, we need to solve two problems, namely how to identify cross-references in the heap and how to store the identified cross-references, in general we will use the Write Barrier to identify cross-references and use the Card Table to store the related data.
Note: Card Table is only one way to mark or store cross-references. In addition to Card Table, we can also use Record Set to store cross-referenced older objects or use page markers to mark older objects according to the dimension of the OS memory page.
The write barrier is a code fragment that is called when a pointer between objects changes, and this code determines if the pointer is a cross-generational reference from an old-age object to a young-age object. If the pointer is a cross-generational reference, we mark the area where the old-age object is located in the card table as shown below.
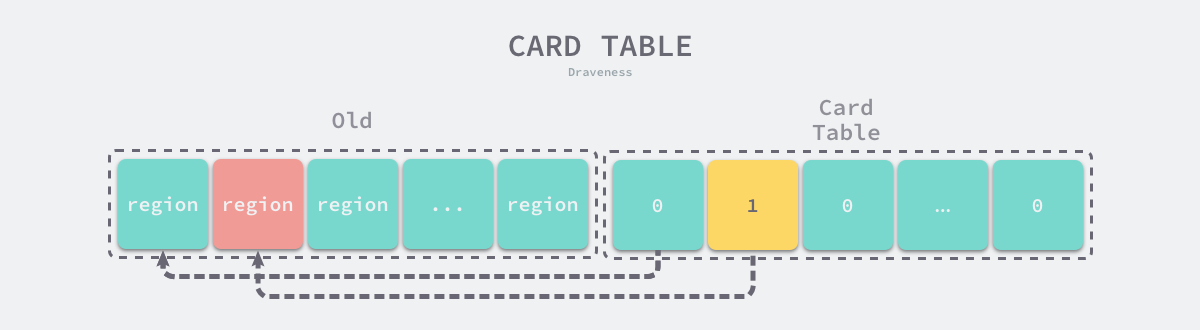
The card table is more similar to the bitmap, it also consists of a series of bits, where each bit corresponds to a piece of memory in the older region. If a pointer to a cyan-age object exists in that memory, then this piece of memory is marked in the card table, and when the Minor GC loop is triggered, in addition to traversing the cyan-age heap from the root object, we also start traversing the cyan-age from all the older-age objects in the card table marked region.
Generational garbage collection is based on the weak generational hypothesis, which combines replica garbage collection, write barrier and card table techniques, dividing the heap area in memory into cyan and old age regions, and using different memory allocation and garbage collection algorithms for different generations, which can effectively reduce the heap size and processing time for GC loop traversal. cannot be used in programming languages such as C, C++, etc. The weak generation hypothesis does not necessarily hold in some scenarios, and using generation garbage collection may be counterproductive if most objects will live long enough.
Mark-Region Collectors
Mark-Region Garbage Collector is a garbage collection algorithm proposed in 2008. This algorithm, also known as Immix GC, combines a mark-cleaning and a replication garbage collection algorithm, where we use the former to keep track of surviving objects in the heap and the latter to reduce the fragmentation present in memory.
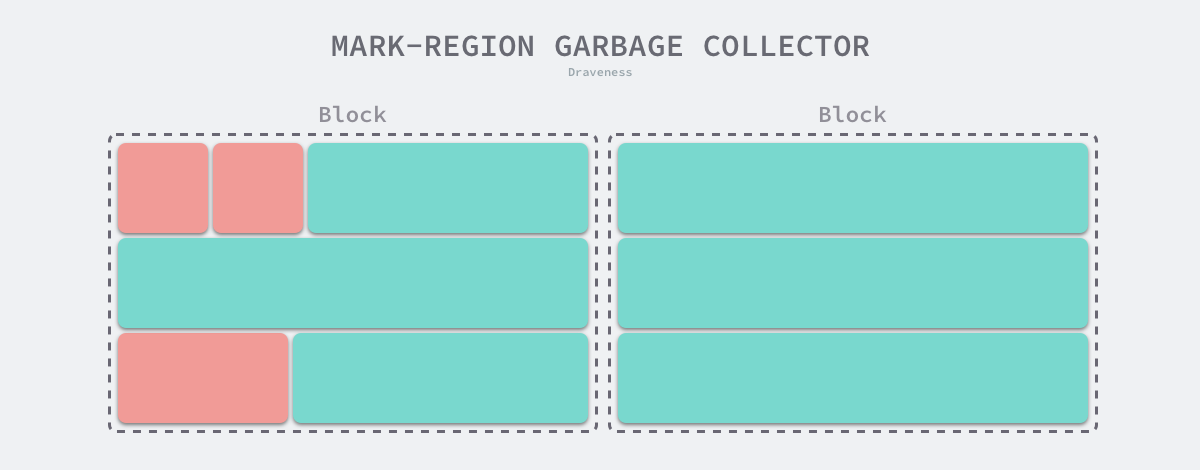
The Immix garbage collection algorithm contains two components, a collector for marking regions and a defragmentation mechanism. The marked area collector is more similar to the marked-clear collector in that it splits the heap memory into memory blocks of a specific size and then splits all the memory blocks into lines of a specific size. When a user program requests memory, it looks for free lines in said memory blocks and allocates memory quickly using a linear allocator; by introducing coarse-grained memory blocks and fine-grained lines, memory allocation and release can be better controlled.
Marked area collectors are more similar to marked clear collectors in that they do not move objects, so they both face memory fragmentation. As shown in the figure below, marker area collectors recycle memory in blocks and lines, so as long as the current memory line contains a live object, the collector will keep that memory area, which brings about the memory fragmentation we mentioned above.
The Opportunistic Evacuation mechanism introduced by Immix is effective in reducing fragmentation in programs. When the collector encounters an object in a memory block that can be evacuated, it uses the replication garbage collection algorithm to move the surviving object in the current block to a new block and release the memory in the original block.
Marked area collector divides heap memory into coarse-grained memory blocks and fine-grained memory lines. Combining the features of several basic garbage collectors, marker clearing algorithm and replicated garbage collection, it is able to improve both the throughput of garbage collectors and the speed of memory allocation using linear allocators, but the implementation of this collector is relatively complex.
Incremental Concurrent Collector
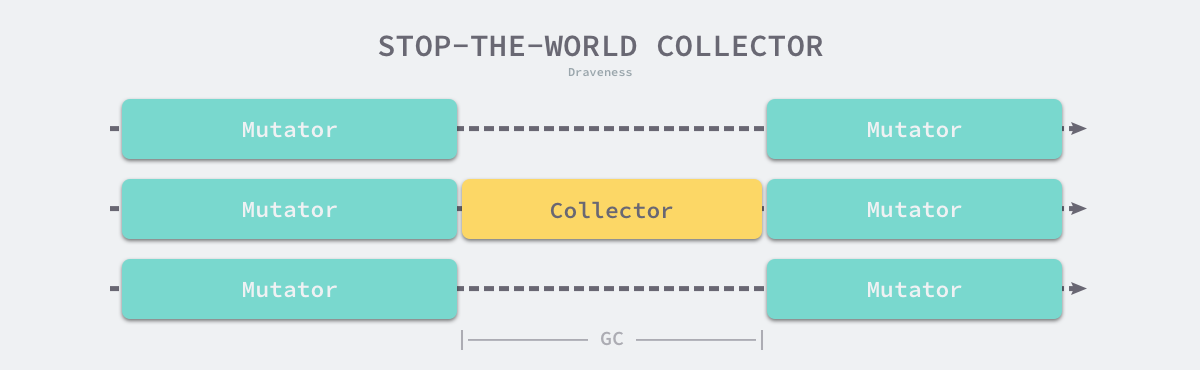
I believe many people’s impression of garbage collector is to suspend the program (Stop the world, STW), as the user program requests more and more memory, the garbage in the system gradually increases; when the program’s memory occupation reaches a certain threshold, the entire application will be suspended, and the garbage collector will scan all the objects already allocated and reclaim the memory space that is no longer used, when the process is finished, the user program can continue execution.
Traditional garbage collection algorithms suspend the application during the execution of garbage collection, and once garbage collection is triggered, the garbage collector will seize CPU usage to occupy a large amount of computational resources to complete the marking and removal work, however, many applications pursuing real-time can not accept a long time STW.
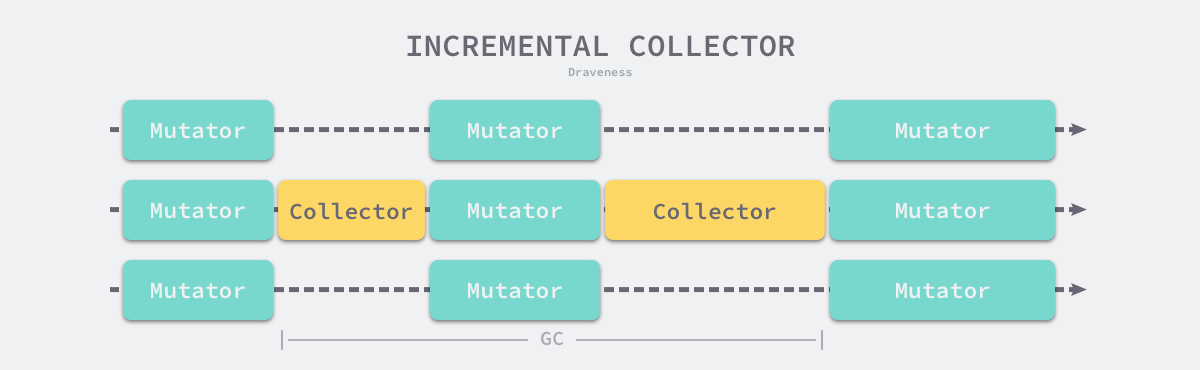
Computational resources were not as abundant in ancient times as they are today, and today’s computers tend to have multi-core processors, and garbage collectors waste a lot of computational resources once they start executing. To reduce the maximum time that an application pauses and the total pause time for garbage collection, we would optimize modern garbage collectors using the following strategies.
- Incremental garbage collection - marking and removing garbage incrementally, reducing the maximum time the application is suspended.
- Concurrent garbage collection - using the computing resources of multiple cores to mark and remove garbage concurrently while the user program executes.
Since both incremental and concurrent can run alternately with the user program, we need to use barrier techniques to ensure correct garbage collection; at the same time, the application cannot wait until memory overflows to trigger garbage collection, because when memory is running low, the application can no longer allocate memory, which is no different from directly suspending the program. Incremental and concurrent garbage collection needs to be triggered early and complete the whole loop before memory runs low to avoid long program pauses.
Incremental garbage collection is a solution to reduce the maximum pause time of the program by slicing the otherwise long pause time into smaller GC time slices, which reduces the maximum application pause time, although the time from the start to the end of garbage collection is longer.
It should be noted that incremental garbage collection needs to be used together with the tri-color marking method. To ensure correct garbage collection, we need to turn on the write barrier before garbage collection starts, so that any modification to memory by the user program will be processed by the write barrier first, ensuring strong tri-color invariance or weak tri-color invariance of object relationships in heap memory. Although incremental garbage collection can reduce the maximum program pause time, incremental collection also increases the total time of a GC cycle, and the user program has to bear additional computational overhead during garbage collection because of the write barrier, so incremental garbage collection is not the only advantage.
Concurrent garbage collection reduces not only the maximum pause time of the program, but also the entire garbage collection phase. By turning on the read/write barrier and taking advantage of multi-core parallel execution with the user program, concurrent garbage collectors can indeed reduce the impact of garbage collection on the application by.
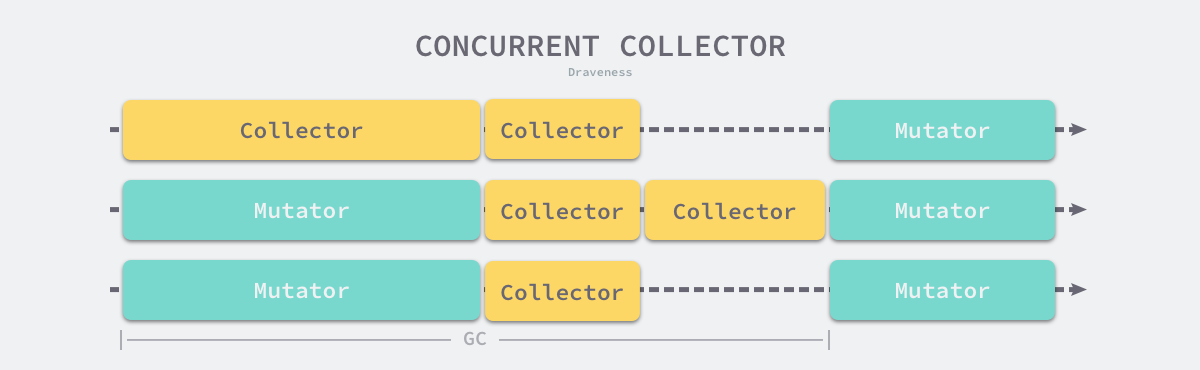
Although the concurrent collector can run with the user program, not all phases can run with the user program, and some phases still need to suspend the user program, but compared with the traditional algorithm, concurrent garbage collection can execute the work that can be executed concurrently as much as possible; of course, because of the introduction of the read-write barrier, concurrent garbage collector must also bring extra overhead, which will not only increase the total time of garbage collection, but also affect the user program, which is something we must pay attention to when designing the garbage collection strategy.
However, because the concurrent marking phase of the incremental concurrent collector will run together or alternately with the user program, it may happen that objects marked as garbage are re-referenced by other objects in the user program , and when the marking phase of garbage collection is over, objects that are incorrectly marked as garbage will be directly recycled, which will cause very serious problems. To solve this problem of the incremental concurrent collector, we need to understand the three-color abstraction and barrier techniques.
Three-color abstraction
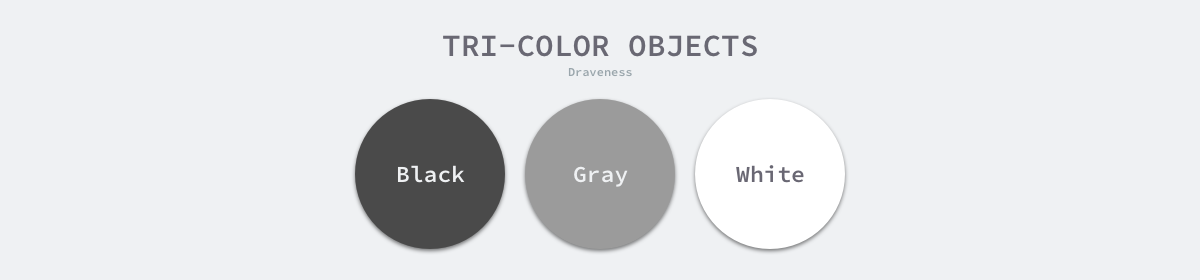
To address the long STW caused by the original marker removal algorithm, most modern trace-based garbage collectors implement a variant of the three-color marker algorithm to reduce the STW time. The three-color tagging algorithm classifies objects in the program into three categories: white, black, and gray.
- White objects - potentially garbage, whose memory may be reclaimed by the garbage collector.
- Black objects - active objects, including objects without any reference to external pointers and objects reachable from the root object.
- Gray objects - active objects, because of the presence of external pointers to white objects, whose children are scanned by the garbage collector.
When the garbage collector starts working, there are no black objects in the program, the root object of garbage collection will be marked as gray, the garbage collector will only take objects from the gray object collection and start scanning, the marking phase will end when there are no objects in the gray collection.

The working principle of the three-colored marker garbage collector is simple, and we can summarize it in the following steps.
- select a gray object from the set of gray objects and mark it as black.
- mark all objects pointed to by the black object as gray, ensuring that neither the object nor the objects referenced by it will be reclaimed.
- repeating the above two steps until no gray objects exist in the object graph.
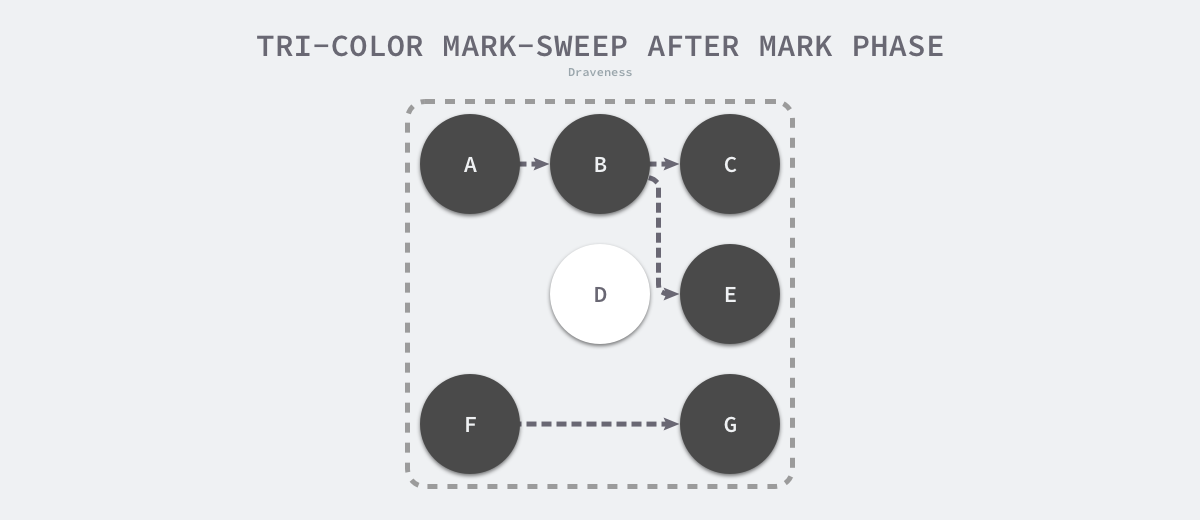
When the marking phase of the three-color marker purge is over, there are no gray objects in the application’s heap, and we can only see black surviving objects as well as white garbage objects, which can be reclaimed by the garbage collector. The following is the heap memory after the marker is executed using the three-color marker garbage collector, with only object D in the heap as the garbage to be reclaimed.
Because the user program may modify the object’s pointer during the marker execution, the three-color marker removal algorithm itself cannot be executed concurrently or incrementally; it still requires STW. In the three-color marker process shown below, the user program creates a reference from object A to object D, but since there is no longer a gray object in the program, object D is incorrectly reclaimed by the garbage collector.
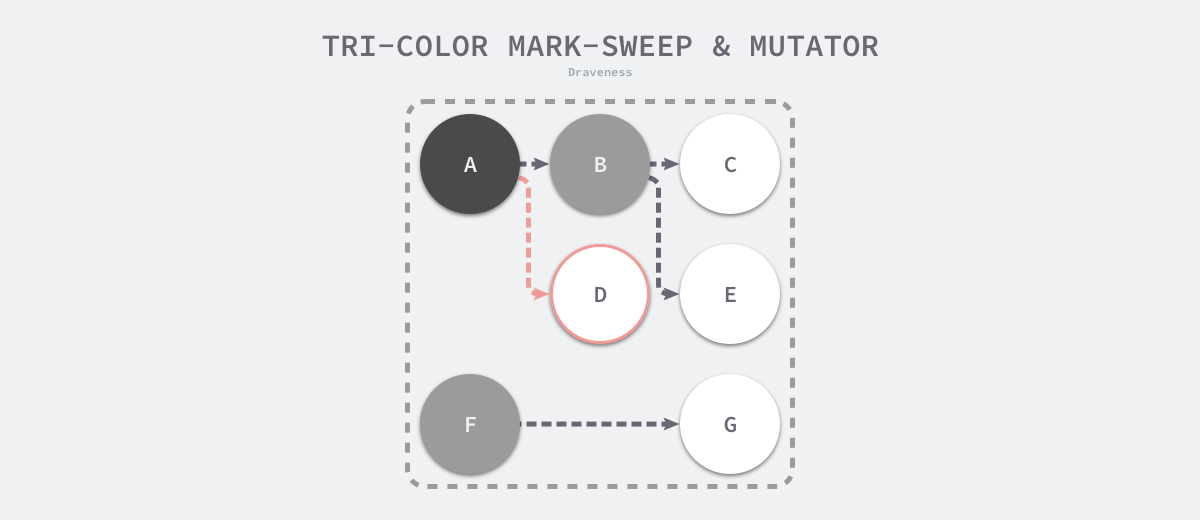
Objects that should not be reclaimed but are reclaimed are very serious errors in memory management. We make such errors as hanging pointers, i.e., pointers that do not point to legal objects of a specific type, affecting memory security, and it is still necessary to use barrier techniques if you want to mark objects concurrently or incrementally.
Garbage Collection Barrier
Most modern processors today execute instructions out of order to maximize performance, but this technique ensures that the code is sequential in its memory operations, and that operations executed before the memory barrier must precede those executed after the memory barrier.
To guarantee correctness in concurrent or incremental tagging algorithms, we need to achieve either of the following two types of Tri-color invariant.
- strong tri-color invariant - black objects do not point to white objects, but only to gray or black objects.
- Weak Tri-color invariant - the white object to which the black object points must contain a reachable path from the gray object through multiple white objects.
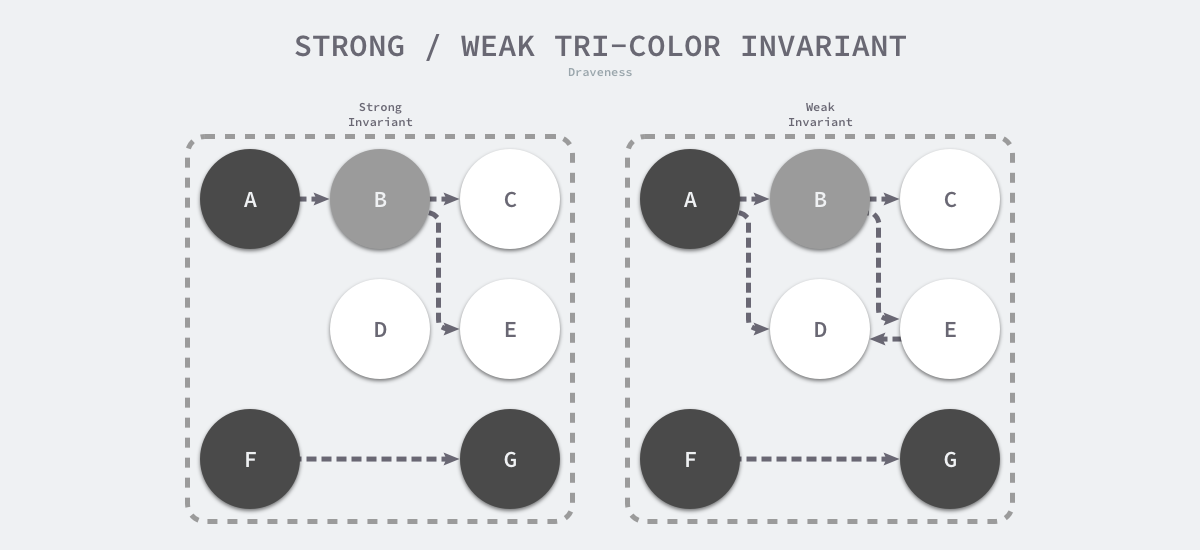
The above diagram shows the heap memory with strong and weak tricolor invariance. By following either of the two invariants, we can guarantee the correctness of the garbage collection algorithm, and the barrier technique is an important technique to guarantee tricolor invariance during concurrent or incremental marking.
The barrier technique in garbage collection is more like a hook method, which is a piece of code that is executed when the user program reads an object, creates a new object, and updates an object pointer.
Here we would like to introduce the following write barrier techniques, namely the insertion write barrier proposed by Dijkstra and the deletion write barrier proposed by Yuasa, and analyze how they guarantee tri-color invariance and correctness of the garbage collector.
Insert Write Barrier
Dijkstra proposed the insertion write barrier in 1978, which allows the user program and the garbage collector to guarantee the correctness of program execution while working alternately by means of a write barrier as follows.
The above pseudo-code for inserting the write barrier is very well understood, whenever we execute an expression like *slot = ptr, we execute the above write barrier to try to change the color of the pointer via the shade function. If the ptr pointer is white, then this function will set the object to gray, otherwise it will stay the same.
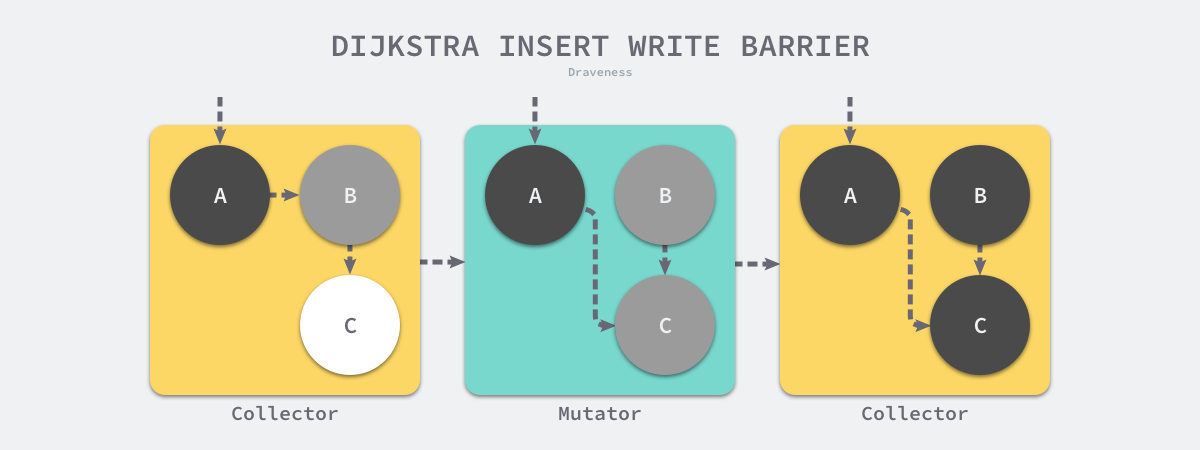
Suppose we use Dijkstra’s proposed insertion-write barrier in our application. In a scenario where the garbage collector and the user program run alternately, the marking process appears as shown in the figure above: 1.
- the garbage collector marks the root object pointing to object A as black and marks object B pointed to by object A as gray.
- the user program modifies the pointer to object A, pointing the pointer to object B to object C, which triggers the write barrier to mark object C as gray.
- the garbage collector iterates through the other gray objects in the program in turn, marking them each as black.
Dijkstra’s insertion of the write barrier is a relatively conservative barrier technique, which marks all potentially viable objects as gray to satisfy strong tricolor invariance. In the garbage collection process shown above, the B objects that are actually no longer alive are not eventually recycled; and if we change the pointer to the C objects back to point to B between the second and third steps, the garbage collector still considers the C objects to be alive, and these incorrectly marked garbage objects will only be recycled in the next loop.
Although the plug-in Dijkstra write barrier is very simple to implement and guarantees strong tricolor invariance, it has obvious drawbacks. Because objects on the stack are also considered root objects in garbage collection, Dijkstra must either add a write barrier to the objects on the stack or rescan the objects on the stack at the end of the marking phase in order to ensure memory safety, each of which has its own disadvantages. The designer of the garbage collection algorithm needs to make a trade-off between these two approaches.
Removing the write barrier
Yuasa’s 1990 paper Real-time garbage collection on general-purpose machines proposed removing the write barrier because once it starts working, it guarantees the reachability of all objects on the heap when the write barrier is turned on, so it is also called Snapshot garbage collection GC.
This guarantees that no objects will become unreachable to the garbage collector traversal all objects which are live at the beginning of garbage collection will be reached even if the pointers to them are overwritten.
The algorithm will guarantee the correctness of the program when garbage collection is performed incrementally or concurrently using a write barrier as follows.
The above code will paint the old object in white gray when the reference to the old object is removed, so that removing the write barrier will ensure weak tricolor invariance and the downstream object referenced by the old object can definitely be referenced by the gray object.
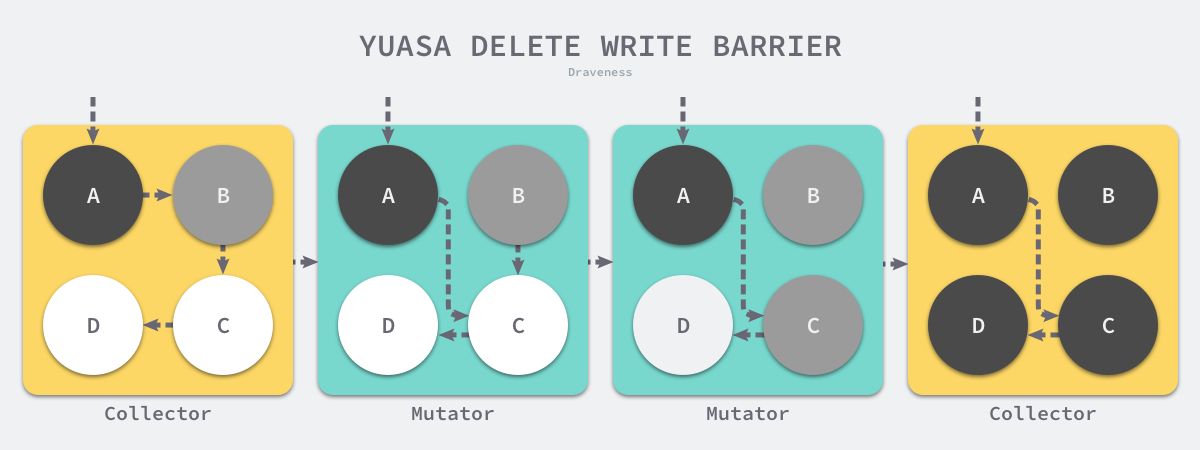
Assuming that we use Yuasa’s proposed remove-write barrier in our application, a scenario in which the garbage collector and the user program run alternately would result in the marking process shown above: 1.
- the garbage collector marks the root object pointing to object A as black and marks object B pointed to by object A as gray.
- the user program points the pointer from object A originally pointing to B to C, triggering the removal of the write barrier, but leaving it unchanged because object B is already grayed out.
- The user program removes the pointer to object B originally pointing to C, triggering the removal of the write barrier, and the white C object is grayed out;
- the garbage collector iterates through the other gray objects in the program in turn, marking them each as black.
The third step in the above process triggers Yuasa to remove the coloring of the write barrier because the user program removes the pointer of B to the C object, so the two objects C and D will violate strong and weak trichromatic invariance, respectively: * Strong trichromatic invariance - black
- Strong tricolor invariance - the black A object points directly to the white C object.
- Weak tricolor invariance - the garbage collector cannot access the white C and D objects from some gray object through several consecutive white objects.
Yuasa removes the write barrier by coloring the C object to ensure that the C object and the downstream D object survive this garbage collection loop, avoiding the occurrence of hanging pointers to ensure correctness of the user program.
Summary
Memory management is still a very important topic today, and when we discuss the performance and convenience of programming languages, memory management mechanisms are inescapable. Most modern programming languages choose to use garbage collection to reduce the burden on engineers, but there are a few languages that use manual management to achieve the ultimate performance.
It is impossible to show all aspects of memory management in one article, and we may need a book or several books to show memory management related technologies in detail, but we focus more on garbage collection here.