kube-scheduler is one of the core components of kubernetes, mainly responsible for the scheduling function of the entire cluster resources, according to specific scheduling algorithms and policies, Pods will be scheduled to the optimal working nodes, so as to make more reasonable and full use of the cluster resources, which is also a very important reason why we choose to use kubernetes This is a very important reason why we chose to use kubernetes. If a new technology doesn’t help companies save money and provide efficiency, I believe it’s hard to move forward.
Scheduling Process
By default, the default scheduler provided by kube-scheduler meets most of our requirements, and the examples we’ve talked to earlier have largely used the default policy to ensure that our Pods can be assigned to nodes with sufficient resources to run. However, in a real online project, we may know our application better than kubernetes, for example, we want a Pod to run on only a few nodes, or these nodes can only be used to run certain types of applications, which requires our scheduler to be controllable.
The main purpose of kube-scheduler is to schedule Pods to the appropriate Node node based on a specific scheduling algorithm and scheduling policy. It is a standalone binary that listens to the API Server all the time after startup, gets Pods with empty PodSpec.NodeName, and creates a binding for each Pod.
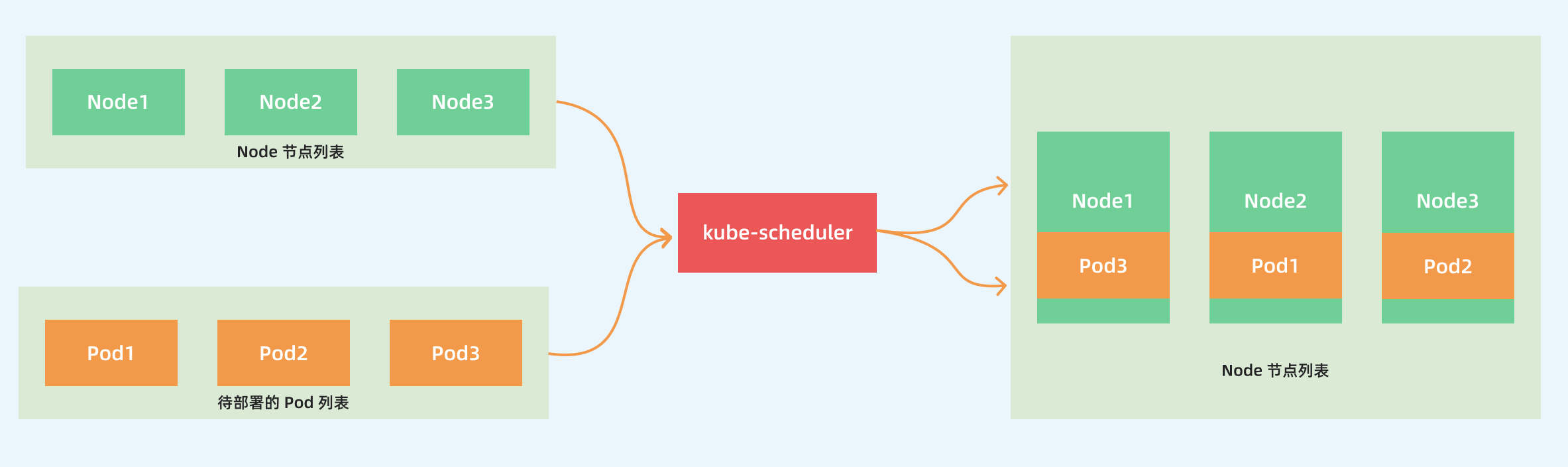
This process may seem relatively simple to us, but in a real production environment, there are many issues to consider.
- How to ensure the fairness of all node scheduling? It is important to know that not all nodes have the same resource allocation.
- How to ensure that each node can be allocated resources?
- How can the cluster resources be used efficiently?
- How can the cluster resources be maximized?
- How to ensure the performance and efficiency of Pod scheduling?
- Can users customize their own scheduling policies according to their actual needs?
Considering the various complexities in real-world environments, the kubernetes scheduler is implemented in a plug-in form, which allows users to customize or develop the scheduler as a plug-in and integrate it with kubernetes.
The source code of the kubernetes scheduler is located in kubernetes/pkg/scheduler, and the general code directory structure is as follows: (the directory structure may not be the same for different versions)
The core program that creates and runs the Scheduler is in pkg/scheduler/scheduler.go and the entry program for kube-scheduler is in cmd/kube-scheduler/scheduler.go.
Customizing the Scheduler
Generally speaking, we have 4 ways to extend the Kubernetes scheduler.
- One way is to directly clone the official kube-scheduler source code, modify the code directly where appropriate, and then recompile and run the modified program. This method is of course the least recommended and impractical, as it requires a lot of extra effort to keep up with the upstream scheduler changes.
- The default scheduler and our custom scheduler can be overridden by the Pod’s
spec.schedulerName. The default default scheduler is used by default, but it is also troublesome when multiple schedulers coexist, for example, when multiple schedulers schedule For example, when multiple schedulers schedule Pods to the same node, you may encounter some problems because it is likely that both schedulers will schedule both Pods to the same node at the same time, but it is likely that one of the Pods will actually run out of resources. It is not easy to maintain a high quality custom scheduler because we need a comprehensive knowledge of the default scheduler, the overall Kubernetes architecture, and the various relationships or limitations of the various Kubernetes API objects. - The third approach is the scheduler extender, which is currently a viable solution that is compatible with the upstream scheduler. The so-called scheduler extension is actually a configurable Webhook that contains
filterandpriorityendpoints corresponding to the two main phases of the scheduling cycle (filtering and scoring). - The fourth approach is through the Scheduling Framework. The pluggable architecture of the Scheduling Framework was introduced in Kubernetes v1.15, making the task of customizing the scheduler much easier. The Scheduling Framework adds a set of plug-in APIs to the existing scheduler, which keeps the “core” of the scheduler simple and easy to maintain while making most of the scheduling functionality available in the form of plug-ins, and the above
scheduler extensionshave been deprecated in our current v1.16 release. So the scheduling framework is the core way to customize the scheduler in the future.
Here we can briefly describe the implementation of the latter two approaches.
Scheduler Extensions
Before we get into the scheduler extensions, let’s take a look at how the Kubernetes scheduler works:
- the default scheduler is started with the specified parameters (we built the cluster with kubeadm and the startup configuration file is located at
/etc/kubernetes/manifests/kube-schdueler.yaml) - watch apiserver and put the Pods with empty
spec.nodeNameinto the scheduler’s internal scheduling queue - Pop out a Pod from the scheduling queue and start a standard scheduling cycle
- Retrieve the “hard requirements” (e.g. CPU/memory request values, nodeSelector/nodeAffinity) from the Pod properties, and then a filtering phase occurs, where a candidate list of nodes satisfying the requirements is calculated
- retrieves the “soft requirements” from the Pod property and applies some default “soft policies” (e.g. Pods tend to be more clustered or spread out on nodes), and finally, it gives a score to each candidate node and selects the final one with the highest score 6.
- communicates with the apiserver (sends a binding call) and then sets the Pod’s
spec.nodeNameproperty to indicate the node to which the Pod will be dispatched.
We can specify which parameters the scheduler will use by looking at the official documentation with the --config parameter, which configuration file should contain a KubeSchedulerConfiguration object in the following format: (/etc/kubernetes/scheduler-extender.yaml)
The key parameter we should enter here is algorithmSource.policy, this policy file can be either a local file or a ConfigMap resource object, depending on how the scheduler is deployed, for example, our default scheduler here is started as a static Pod, so we can configure it as a local file.
The policy file /etc/kubernetes/scheduler-extender-policy.yaml should follow kubernetes/pkg/scheduler/apis/config/legacy_types.go#L28, in our v1.16.2 release here we already support both JSON and YAML format policy files, here is a simple example of our definition, you can see the Extender for a description of the policy file definition specification.
Our Policy policy file here extends the scheduler by defining extenders, sometimes we don’t need to write the code, we can customize it directly in this configuration file by specifying predicates and priorities, if not specified then the default DefaultProvier will be used.
|
|
The policy change file defines an HTTP extender service running under 127.0.0.1:8888 and has registered the policy with the default scheduler so that at the end of the filtering and scoring phases, the results can be passed to the extender’s endpoints <urlPrefix>/<filterVerb> and < urlPrefix>/<prioritizeVerb>, where we can further filter and prioritize in the extender to suit our specific business needs.
Example
Let’s implement a simple scheduler extension directly in golang, but of course you can use any other programming language, as follows.
Then we need to implement the /filter and /prioritize endpoint handlers.
The extension function Filter takes an argument with input type schedulerapi.ExtenderArgs and returns a value of type *schedulerapi.ExtenderFilterResult. In the function, we can further filter the input nodes: the
|
|
In the filter function, we loop through each node and then use our own implemented business logic to determine whether the node should be approved or not, here our implementation is relatively simple, in the podFitsOnNode() function we simply check whether the random number is even to determine, if so we consider it a lucky node, otherwise we refuse to approve the node.
|
|
The same scoring function is implemented in the same way, where we give a random score on each node:
|
|
We can then use the following command to compile and package our application.
|
|
The complete code for this section of the scheduler extension is available at: https://github.com/cnych/sample-scheduler-extender.
Once the build is complete, copy the application app to the node where kube-scheduler is located and run it directly. Now we can configure the above policy file into the kube-scheduler component. Our cluster here is built by kubeadm, so we can directly modify the file /etc/kubernetes/manifests/kube-schduler.yaml with the following content.
|
|
Of course we are configuring this directly on the default
kube-scheduler, but we can also copy a YAML file of the scheduler and change the schedulerName to deploy it without affecting the default scheduler, and then specifyspec. schedulerNameon the Pod that needs to use this test scheduler. For using multiple schedulers, see the official documentation Configuring Multiple Schedulers.
After reconfiguring kube-scheduler, you can check the logs to verify that the reboot was successful, but be sure to add /etc/kubernetes/scheduler-extender.yaml and /etc/kubernetes/scheduler-extender- policy.yaml files into the Pod: /etc/kubernetes/scheduler-extender.yaml.
|
|
Here we have created and configured a very simple scheduler extension, now let’s run a Deployment to see how it works, we prepare a deployment Yaml with 20 copies: (test-scheduler.yaml)
Create the above resource object directly.
At this point we go to the log of the scheduler extension we wrote.
|
|
We can see the process of Pod scheduling, in addition the default scheduler will periodically retry failed Pods, so they will be re-passed again and again to our scheduler extension, our logic is to check if the random number is even, so eventually all Pods will be in running state.
The scheduler extender may be able to meet our needs in some cases, but he still has some limitations and drawbacks.
- Communication cost: data is transferred between the default scheduler and the scheduler extender with
http(s), which has some cost when performing serialization and deserialization - Limited extension points: extensions can only participate at the end of certain phases, such as
"Filter"and"Prioritize", and they cannot be called at the beginning or middle of any phase - Subtraction over addition: compared to the node candidate list passed by the default scheduler, we may have some requirements to add a new candidate node list, but this is a riskier operation because there is no guarantee that the new node will pass other requirements, so it is better for the scheduler extensions to perform
"Subtraction"(further filtering) rather than"Addition"(adding nodes) - Cache sharing: the above is just a simple test example, but in a real project we are required to make scheduling decisions by looking at the state of the whole cluster. The default scheduler can schedule decisions well, but cannot share its cache, which means we have to build and maintain our own cache
Due to these limitations, the Kubernetes scheduling team came up with the fourth method above for better extensions, the Scheduler Framework, which basically solves all the problems we encounter and is now the official recommended extension, so it will be the most mainstream way to extend the scheduler in the future.
Scheduling Framework
The scheduling framework defines a set of extension points. Users can implement the interfaces defined by the extension points to define their own scheduling logic (we call them extensions) and register extensions to the extension points. The scheduling framework will call the extensions registered by the user when it encounters the corresponding extension points when executing the scheduling workflow. Scheduling frameworks have a specific purpose when reserving extensions, some extensions on extension points can change the scheduler’s decision method, some extensions on extension points just send a notification.
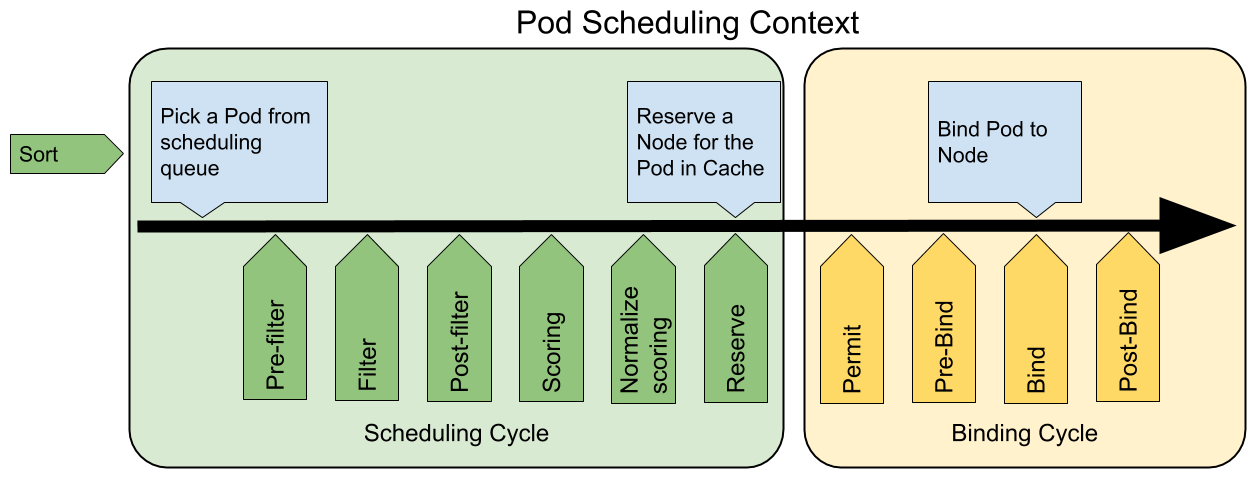
We know that whenever a Pod is scheduled, it is executed according to two processes: the scheduling process and the binding process.
The scheduling process selects a suitable node for the Pod, and the binding process applies the decisions of the scheduling process to the cluster (i.e., runs the Pod on the selected node), combining the scheduling and binding processes in what is called the scheduling context. Note that the scheduling process runs `synchronously’ (scheduling for only one Pod at the same point in time), and the binding process can run asynchronously (binding for multiple Pods at the same point in time).
The scheduling process and the binding process will exit in the middle of the process when they encounter the following conditions.
- The scheduler thinks there is no optional node for the Pod
- Internal error
In this case, the Pod is put back into the pending queue and waits for the next retry.
Extension Points
The following diagram shows the scheduling context in the scheduling framework and the extension points in it. An extension can register multiple extension points so that more complex stateful tasks can be executed.
-
The
QueueSortextension is used to sort the queue of Pods to be dispatched to decide which Pod to be dispatched first. can only have oneQueueSortplugin in effect at the same point in time. -
Pre-filterextension is used to pre-process the Pod information or check some prerequisites that must be met by the cluster or Pod, ifpre-filterreturns an error, the scheduling process is terminated. -
The
Filterextension is used to exclude nodes that cannot run the Pod. For each node, the scheduler will execute thefilterextensions in order; if any of thefilters marks the node as unselectable, the remainingfilterextensions will not be executed. The scheduler can executefilterextensions on multiple nodes at the same time. -
Post-filteris a notification type extension point that is called with the argument of a list of nodes that have been filtered as selectable nodes at the end of thefilterphase, which can be used in the extension to update the internal state, or to generate log or metrics information. -
The
Scoringextension is used to score all the selectable nodes. The scheduler will call theSoringextension for each node, and the scoring result is an integer in a range. During thenormalize scoringphase, the scheduler will combine the scoring results of eachscoringextension for a specific node with the extension’s weight as the final scoring result. -
The
normalize scoringextension modifies the scoring result of each node before the scheduler performs the final sorting of the nodes. scoring` extensions of all plugins once for each scheduling session performed by the scheduling framework. 4. -
Reserveis a notification extension that stateful plugins can use to obtain the resources reserved for Pods on a node. This event occurs before the scheduler binds a Pod to a node, in order to avoid the situation where the actual resources used exceed the resources available when the scheduler schedules a new Pod to the node while waiting for the Pod to be bound to the node. (Because binding a Pod to a node happens asynchronously). This is the last step of the scheduling process, after the Pod enters the reserved state, either the Unreserve extension is triggered when the binding fails or the binding process is ended by the Post-bind extension when the binding succeeds. -
The
Permitextension is used to prevent or delay the binding of a Pod to a node. the Permit extension can do one of the following three things.
- approve: When all permit extensions have approved the binding of the Pod to the node, the scheduler will continue the binding process
- deny: If any of the permit extensions deny the binding of a Pod to a node, the Pod will be put back in the queue to be scheduled and the
Unreserveextension will be triggered. - wait: If a permit extension returns wait, the Pod will remain in the permit phase until it is approved by another extension. If a timeout event occurs and the wait state becomes deny, the Pod will be put back in the queue to be dispatched and the Unreserve extension will be triggered.
-
The
Pre-bindextension is used to perform certain logic before the Pod is bound. For example, the pre-bind extension can mount a network-based data volume to a node so that the Pod can use it. If any of thepre-bindextensions return an error, the Pod will be put back in the queue to be dispatched, at which point the Unreserve extension will be triggered. -
The
Bindextension is used to bind a Pod to a node.
- The bind extension is executed only when all pre-bind extensions have been successfully executed
- The scheduling framework invokes bind extensions one by one in the order in which they are registered
- A specific bind extension can choose to process or not process the Pod
- If a bind extension handles the binding of the Pod to a node, the remaining bind extensions will be ignored
Post-bindis a notification extension.
- Post-bind extension is called passively after a Pod is successfully bound to a node
- The Post-bind extension is the last step of the binding process and can be used to perform resource cleanup actions
Unreserveis a notification extension that is called if a resource is reserved for a Pod and the Pod is denied binding during the binding process. the unreserve extension should release the compute resources on the node that has been reserved for the Pod. The reserve extension and the unreserve extension should appear in pairs in a plugin.
If we want to implement our own plugin, we must register the plugin with the scheduling framework and complete the configuration, in addition to implementing the extension point interface, which corresponds to the extension point interface we can find in the source code pkg/scheduler/framework/v1alpha1/interface.go file, as follows.
|
|
For enabling or disabling the scheduling framework plugin, we can also use the KubeSchedulerConfiguration resource object above. KubeSchedulerConfiguration) resource object to configure it. The configuration in the following example enables a plugin that implements the reserve and preBind extension points, and disables another plugin, and provides some configuration information for the plugin foo.
|
|
The order in which extensions are called is as follows.
- If no corresponding extension is configured for an extension point, the scheduling framework will use the extension from the default plugin
- If an extension is configured and activated for an extension point, the scheduling framework will call the extension from the default plugin first, and then the configured extension
- The extensions of the default plugin are always called first, and then the extensions of the extension points are called one by one in the order of their activation
enabledinKubeSchedulerConfiguration. - You can disable the extensions of the default plugin and then activate the extensions of the default plugin somewhere in the
enabledlist, which changes the order in which the extensions of the default plugin are called
Suppose the default plugin foo implements the reserve extension point, and we want to add a plugin bar, which we want to be called before foo, then we should disable foo first and then activate bar foo in the same order. An example configuration is shown below.
In the source code directory pkg/scheduler/framework/plugins/examples there are several demonstration plugins that we can refer to for their implementation.
example
In fact, it is not difficult to implement a scheduler framework plugin, we just need to implement the corresponding extension points and then register the plugin to the scheduler, the following is the plugin registered by the default scheduler at initialization time: pkg/scheduler/framework/plugins/examples.
But as you can see there are no plugins registered by default, so to make the scheduler recognize our plugin code, we need to implement a scheduler ourselves, but of course we don’t need to implement this scheduler at all. In the kube-scheduler source file kubernetes/cmd/kube-scheduler/app/server.go there is a NewSchedulerCommand entry function with a list of arguments of type Option, and this Option happens to be the definition of a plugin configuration:
So we can call this function directly as our function entry and pass in our own plug-in as an argument, and there is a function named WithPlugin under the file to create an Option instance.
So we end up with the following entry function.
|
|
WithPlugin(sample.Name, sample.New) is the next plug-in we want to implement, from the WithPlugin function parameters can also see that we here sample.New must be a framework.PluginFactory type value and the definition of PluginFactory is a function.
|
|
So sample.New is actually the above function, in this function we can get some data in the plug-in and then logical processing can be done, plug-in implementation is shown below, we just simply get the data here to print the log, if you have the actual needs of the data can be processed on the basis of the acquisition, we just implement the PreFilter , Filter, PreBind three extension points, the other can be extended in the same way can be.
|
|
The full code can be obtained from the repository https://github.com/cnych/sample-scheduler-framework.
After the implementation is complete, we can compile and package it into an image, and then we can deploy it as a normal application with a Deployment controller. KubeSchedulerConfigurationresource object configuration, you can enable or disable our plugins viaplugins, and you can pass some parameter values to the plugins via pluginConfig`.
|
|
By deploying the above resource object directly, we have deployed a scheduler called sample-scheduler, and we can deploy an application to use this scheduler for scheduling.
|
|
For enabling or disabling the scheduling framework plugin, we can also use the KubeSchedulerConfiguration resource object above.
Let’s create this resource object directly and check the logging information of our custom scheduler after it is created.
|
|
You can see that after we create the Pod, the corresponding logs appear in our custom scheduler and above the extension points we defined, proving the success of our example, which can also be verified by looking at the Pod’s schedulerName.
In the latest version of Kubernetes v1.17, the Scheduler Framework built-in preselection and preference functions have all been plugged in, so to extend the scheduler we should master and understand the scheduling framework in this way.