GraphQLis both a query language for the API and a runtime for your data queries.GraphQLprovides a complete set of easy-to-understand descriptions of the data in your API, allowing the client to get exactly the data it needs without any redundancy, and making it easier for the API to evolve over time, as well as for building powerful developer tools.
Over the last decade, REST has become the design standard for Web APIs, providing some great ideas such as stateless servers and structured access to resources. However, the REST API has shown to be too inflexible to meet the rapidly changing needs of accessing clients.
GraphQL was developed to meet the need for greater flexibility and efficiency! It solves many of the shortcomings and inefficiencies that developers encounter when interacting with the REST API.
The REST and GraphQL difference
To illustrate the main difference between REST and GraphQL when getting data from the API, let’s consider a simple example scenario: In a blog application, the application needs to display the post title of a specific user. It also displays the names of the last 3 followers of that user.
How can this situation be solved with REST and GraphQL?
Using REST and GraphQL for data fetching
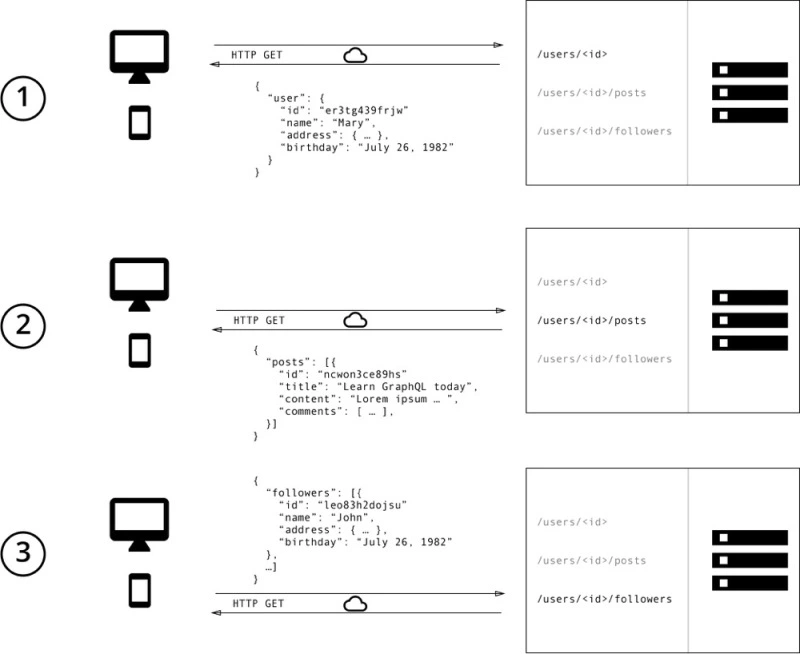
Using the REST API, three interfaces need to be designed to fetch data.
/users/<id>: Get the initial user data/users/<id>/posts: return all posts of the user/users/<id>/followers: return the list of followers for each user.
In GraphQL simply send a query to the GraphQL server with a specific data request. The server then responds using JSON objects to satisfy the request.
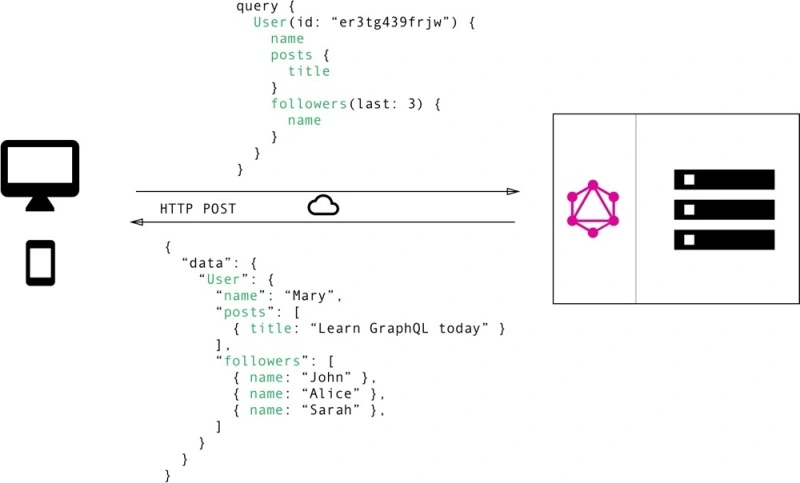
Using GraphQL, the client can specify exactly the data attributes needed in the query.
REST
REST is the most general and commonly used interface design scheme. It is stateless and resource-centric, defining a set of URL conventions for how to manipulate resources, and the operation types are represented by HTTP Methods such as GET POST PUT DELETE.
- Downloading excess data The client downloads more information than is actually needed in the application. For example a page that only needs to display a list of usernames. In the
RESTAPI, this application would typically hit/usersto receive a JSON array with user data, and for generality, the interface may return more user information, such as birthday or address. - Missing information and N+1 issues Missing information usually means that the particular interface does not provide enough of the required information. The client needs to ask for additional interfaces to get the required information.
GraphQL
GraphQL is not an alternative to REST, but another form of interaction: the front-end decides what to return to the back-end.
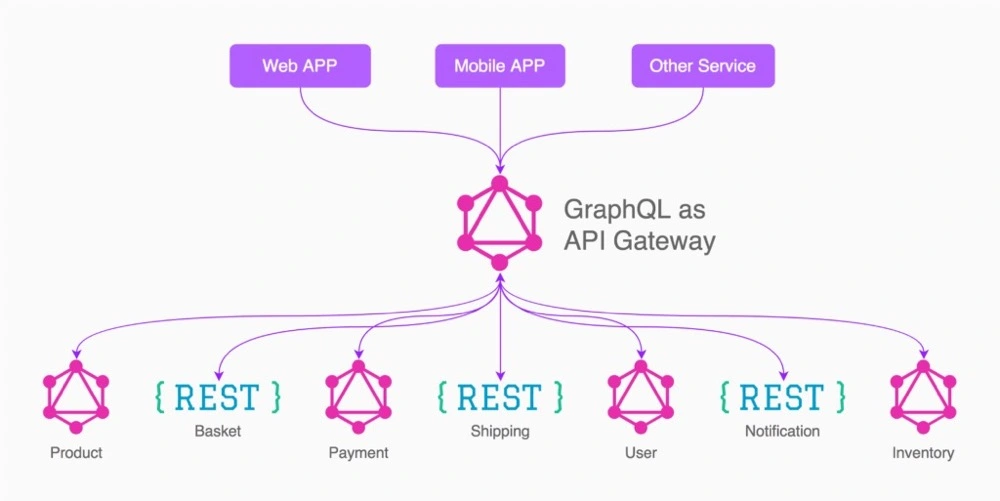
The main application scenario for the GraphQL API is the API gateway, which provides an abstraction layer between the client and the service.
The biggest benefit of GraphQL is that the request response is streamlined, there are no redundant fields, and the front-end can decide what data is returned by the back-end. But note that the front-end decision depends on what data the back-end supports, so GraphQL is more like REST with streamlined return values, and the back-end interface can define all the functionality at once without the need for case-by-case development. Now for the benefits of GraphQL.
- Improved development speed First,
GraphQLhelps reduce the number of requests. It is much easier to get the data you need with a single call than with multiple requests. From a development perspective, this speeds up development. Back-end and client-side teams need to work closely together to define the API, test it, and make changes. Front-end, mobile, IoT, and other client teams are constantly iterating on features and experimenting with new UX and designs. Data requirements change frequently, and back-end teams must keep pace. If the same team is responsible for client-side and back-end code, the problem is less severe. WithGraphQL, client-side engineers have complete control over the front-end and don’t need to rely on anyone becauseGraphQLqueries can be used to tell the back-end what they need and what the response structure should look like. Instead of spending time having the back-end API team add or modify something. The self-documenting nature ofGraphQLsaves some of the time spent looking up documentation to understand how to use the API. Once you have a large number ofGraphQLAPIs, and then someone comes up with a new product idea, using the existingGraphQLAPIs can be prototyped quickly, much faster than calling various REST APIs or building new REST APIs for new applications. - Performance engineers aren’t the only ones who benefit from
GraphQL. Users also benefit from the (perceived) performance gains of the application: reduced payload (the client only needs what is necessary) multiple requests combined into one request reduces network overhead; faster UI updates - improved security, strong typing and validation of
GraphQLschema independent of the language. Extending the previous example, we can define the Address type in the schema:type Address { city: String! country: String! zip: Int }String and Int are scalar types, and ! schema validation is part of the GraphQL specification, so a query like this will return an error because name and phone are not fields of the Address object:{ user (id: 123) { address { name phone } } }
GraphQL Implementation
When choosing a platform to implement the GraphQL API, Node is a candidate because initially GraphQL was used for web applications and front-ends, and Node is the preferred choice for developing web applications because it is based on JavaScript. GraphQL can be implemented very easily with Node (assuming a schema is provided). In fact, the implementation using Express or Koa requires only a few lines of code.
|
|
The schema is defined using the types in npm’s graphql. query and Mutation are special schema types.
Most of the implementation of the GraphQL API lies in the schema and the parser. Parsers can contain arbitrary code, but the most common are the following five main categories.
- calls to Thrift, gRPC, or other RPC services.
- calls to HTTP REST APIs (when the priority is not rewriting existing REST APIs).
- direct calls to data stores.
- calling other GraphQL schema queries or services.
- calling external APIs.
GraphQL does not necessarily require a client. A simple GraphQL request is a regular POST HTTP request with the query content. We can use any HTTP proxy library (e.g. CURL, axios, fetch, superagent, etc.) to generate the request. For example, to send a request using curl in the terminal.
The following code can be run in any modern browser (to avoid CORS, please visit launchpad.graphql.com).
While building GraphQL requests is easy, there are many other things that need to be implemented, such as caching, as caching can greatly improve the user experience. Building client-side caches is not so easy, but fortunately, Apollo and Relay Modern, among others, provide client-side caching out of the box.
When shouldn’t I use GraphQL?
Of course, there is no perfect solution (although GraphQL is close to perfect), and there are some issues to keep in mind, such as
- does it have a single point of failure?
- is it scalable?
- who uses GraphQL?
Finally, here is a list of the main reasons why GraphQL may not be a good choice.
- When the client’s needs are simple: if your API is simple, e.g. /users/resumes/123, then GraphQL is a bit heavy.
- the use of asynchronous resource loading for faster loading.
- using new APIs when developing new products, rather than building on existing ones.
- not intending to make the API available to the public.
- not requiring changes to the UI and other clients.
- Inactive product development.
- Uses some other JSON schema or serialization format.