In 2009, the University of California, Berkeley published a paper, “The Berkeley View on Cloud Computing,” which correctly predicted the evolution and popularity of cloud computing over the next decade.
In 2019, Berkeley published another paper with the same naming style, “A Berkeley View on Serverless Computing,” which again predicted that “serverless computing will evolve to become the dominant form of cloud computing in the future. Serverless has been met with high hopes, but also with some controversy.
Now, seven years after the first release of Amazon Lambda in 2014, we look back and see if the promises of serverless computing have been fulfilled.
The Promise and Controversy of Serverless
The term “serverless” first appeared in an article around 2012, and was explained by author Ken Fromm as follows
The term “serverless” does not mean that servers are no longer involved, it simply means that developers no longer need to consider as much physical capacity or other infrastructure resource management responsibilities. By eliminating the complexity of back-end infrastructure, serverless allows developers to shift their focus from the server level to the task level.
Although many technology prophets considered serverless architecture to be “a major innovation that will soon catch on,” the concept was not well received at the time of its introduction.
The event that really brought serverless to widespread attention was the launch of Amazon Lambda services by Amazon Cloud Technologies in 2014. After that, “serverless” became an industry buzzword as services from companies like Google and Microsoft entered the market.
The main advantages of serverless computing over “traditional services” are.
- A better way to automatically scale up and down, theoretically able to handle sudden spikes in demand from “zero” to “infinity”. Decisions about scaling are provided on demand by the cloud provider, and developers no longer need to write automatic scaling policies or define rules for the use of machine-level resources (CPU, memory, etc.).
- Traditional cloud computing charges for reserved resources, while serverless charges for function execution time. This also implies a more granular approach to management. The use of resources on a serverless framework is only paid for the actual runtime. This is in contrast to traditional cloud computing charging, where users pay for computers with idle time.
- As the next iteration of cloud computing, serverless computing allows developers to focus more on building the applications in their products without the need to manage and maintain the underlying stack, and is cheaper than traditional cloud computing, making serverless the “fastest way to develop new applications and the lowest total cost of ownership.
“The Berkeley Perspective even argues that serverless computing provides an interface that greatly simplifies cloud programming, a shift similar to “migrating from assembly language to a high-level programming language.
From its inception, serverless computing has had high expectations, but the development process has inevitably been controversial, and some of the issues involved have been
- Limited programming languages. Most serverless platforms only support running applications written in specific languages.
- Vendor lock-in risk. There are few cross-platform standards for how “functions” can be written, deployed, and managed. This means that migrating “functions” from one vendor-specific platform to another can be time-consuming and costly.
- Performance issues such as cold starts. If a “function” has not run on a particular platform before, or has not run for some time, it will take some time to initialize.
2019 is considered to be a year of significant serverless development. At the end of the year, Amazon Cloud Technologies released Amazon Lambda’s “Provisioned Concurrency” feature, which allows Amazon Cloud Technologies serverless computing users to keep their functions “initialized and ready to ready to respond in double-digit milliseconds,” meaning that the “cold start” problem is a thing of the past and the industry has reached a point of maturity.
While this technology still has a long way to go, we are seeing continued growth in serverless adoption as more and more companies, including Amazon Cloud Technologies, Google, and Microsoft, invest in this technology.
According to Datadog’s 2021 State of Serverless report, developers are accelerating their adoption of serverless architectures: Amazon Lambda usage increases significantly after 2019, with the average daily invocation of Amazon Lambda functions at the beginning of 2021 being 3.5 times more frequent than two years ago, and half of new Amazon Web Services users have adopted Amazon Lambda.
While Microsoft and Google have increased their share, Amazon Lambda, a pioneer in serverless technology, has maintained its leadership in adoption, with half of all functions-as-a-service (FaaS) users using Amazon Cloud Technologies’ services. Hundreds of thousands of customers are already building their services with Amazon Lambda, according to data published by Amazon Web Services.
A look at the evolution of serverless technology through Amazon Lambda
Amazon Lambda is an event-driven compute engine, and Amazon Cloud Technologies released a preview version of the feature at the Amazon Cloud Technologies re:Invent conference in November 2014. This immediately prompted competitors to follow suit, and a number of companies began offering similar services on the cloud, with Google releasing Cloud Functions the following February, IBM releasing Bluemix OpenWhisk the same month, and Microsoft releasing a preview version of Azure Functions the following March, among others.
On the Amazon Web Services product page, Amazon Cloud Technologies defines Amazon Lambda as “the ability for users to run code without on-premises or managed infrastructure. Simply write code and upload it as a .zip file or container image.”
In a simple use case, The Seattle Times uses serverless technology to automatically resize images for display on mobile, tablet, and desktop devices whenever an image is uploaded to Amazon Simple Storage Service (S3), triggering an Amazon Lambda function call to perform the resizing function. The Seattle Times pays Amazon Web Services only after the image has been resized.
Key Advances in Amazon Lambda
For teams exploring serverless technologies, it is critical to understand Amazon Lambda. While serverless is not the same as Amazon Lambda, since its release in 2014, Amazon Lambda has become almost synonymous with Amazon Serverless services. In fact, Amazon Lambda needs to be combined with other tools to form a complete serverless architecture, such as sending HTTP requests through Amazon API Gateway or calling resources in Amazon S3 storage buckets, Amazon DynamoDB tables, or Amazon Kinesis streams.
Early in the release, only Amazon S3, Amazon DynamoDB, and Amazon Kinesis were available for Amazon Lambda functions. But since then, Amazon CloudTech has gradually integrated many other services for Amazon Lambda functions, such as Amazon Cognito Authentication, Amazon API Gateway, Amazon SNS, Amazon SQS, Amazon CloudFormation, and Amazon CloudWatch, and more.
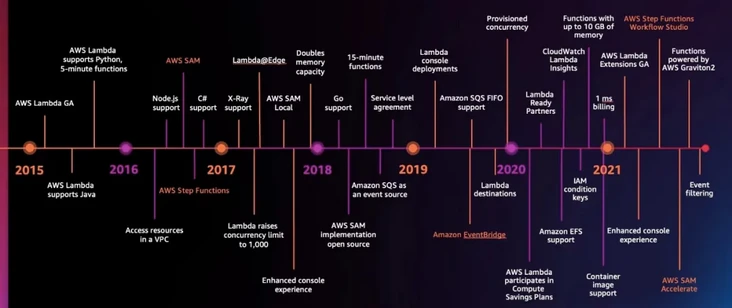
When it launched in 2014, Amazon Lambda only supported Node.js, Java support was added to Amazon Lambda in late 2015, and Python support was added in 2016. By now, Amazon Lambda natively supports Java, Go, PowerShell, Node.js, C#, Python, and Ruby code, and provides a Runtime API that allows users to write functions in any other programming language.
With Amazon Lambda, in addition to uploading code (or building code in the Amazon Lambda console), users need to select memory and timeout to create functions.
Amazon Lambda function timeouts started at 30 seconds and were later extended to 5 minutes, and in October 2018, Amazon Web Services set the timeout to 15 minutes, allowing users to run longer functions and more easily perform tasks such as big data analysis, bulk data transformation, bulk event processing, and statistical calculations.
Amazon Lambda functions linearly allocate CPUs and other resources based on the amount of memory configured, and at the end of 2020, the memory limit for Amazon Lambda functions was adjusted to 10 GB, more than three times the previous limit, which means users can access up to six vCPUs per execution environment, allowing users to run multi-threaded and multi-process programs faster. This allows users to run multi-threaded and multi-process programs faster.
In the seven years since its release, Amazon Serverless services have continued to improve in all areas.
In 2016, Amazon Cloud Technologies released Amazon Step Functions, which can combine calls to multiple Amazon Lambda functions and other Amazon services to visually represent complex business logic as a low-code, event-driven workflow.
In 2017, the default concurrency for Amazon Lambda was increased to 1000 and the distributed tracing tool X-Ray was made available.
In 2018, Amazon Cloud Technologies released Amazon Aurora Serverless v1, formally announcing that more complex relational databases (RDBMS) can also have Serverless features, enabling automatic load-based start-stop and elastic scaling of cloud databases.
With the evolution of cloud services, Amazon Cloud Technologies has released five Serverless database services, including Amazon Aurora Serverless, Amazon DynamoDB, Amazon Timestream (a time series database service), Amazon Keyspaces (a hosted database service compatible with Apache Cassandra-compatible managed database service) and Amazon QLDB, a fully managed ledger database.
Amazon Aurora Serverless has now evolved from v1 to v2. Aurora Serverless v2 can scale database workloads from hundreds to hundreds of thousands of transactions in less than a second, saving up to 90 percent on database costs compared to the cost of provisioning capacity for peak loads.
In 2019, Amazon Cloud Technologies released Amazon EventBridge, a serverless event bus service that serves as a centralized hub to Amazon Web Services services, custom applications, and SaaS applications, providing real-time data flow from event sources to target objects such as Amazon Lambda and other SaaS applications) in real time. Amazon Lambda now integrates with more than 200 Amazon Web Services services and SaaS applications.
In the same year, Amazon Cloud Technologies also introduced the Amazon S3 Glacier Deep Archive, further refining the smart billing tiers for S3 storage services by hot and cold reads and writes.
In 2021 Amazon Lambda billing was adjusted to the 1ms level and also provided container mirroring support, as well as Amazon Graviton2 processor support, which provides up to 34% better price/performance compared to its x86-based counterpart.
Cold start and vendor lock-in
The “cold start” performance improvement is a landmark event, as FaaS platforms take some time to initialize function instances. Even for the same specific function, this startup latency can vary greatly from platform to platform, from milliseconds to seconds, depending on the library used, the arithmetic power of the function configuration, and a host of other factors. In the case of Amazon Lambda, for example, Amazon Lambda functions are either “hot-started” or “cold-started” for initialization. A “hot start” reuses an instance of the Amazon Lambda function and its host container from a previous event, while a “cold start” creates a new container instance and starts the function’s host process. When considering startup latency, “cold starts” are of greater concern.
Amazon Cloudtech is offering an important new feature in 2019 called “Provisioned Concurrency” to more precisely control startup latency by keeping functions in an initialized state. All users need to do is set a value that specifies how many instances the platform needs to configure for a particular function, and the Amazon Lambda service itself will ensure that there are always that number of pre-warmed instances waiting to work. “The emergence of this feature in Amazon Cloud Technologies represents the end of the controversy over “cold starts,” which have undoubtedly been the biggest issue pointed out by critics of serverless technology.
In addition, “vendor lock-in” is also a very controversial area. A few years ago, CoreOS CEO Alex Polvi, an opponent of serverless technology, called the Amazon Lambda serverless product “one of the worst forms of proprietary locking we’ve seen in human history. Matt Asay, who works for MongoDB, countered with an article saying that “the way to avoid lock-in altogether is to write all the underlying software (event model, deployment model, etc.) yourself.
In short, as supporters, many believe that “locking” is not a black-and-white thing, but an architectural choice that needs to be weighed over and over. Other technologists say that migration costs can be minimized by designing the application and platform separately, and by standardizing the technology: if using standardized HTTP, then use Amazon API Gateway to convert HTTP requests to Amazon Lambda event format; if using standardized SQL, then use Amazon Aurora Serverless, which is compatible with MySQL. MySQL-compatible Amazon Aurora Serverless, which naturally simplifies the migration path to the database ……
Best Practice Examples
What are the scenarios in which users are using serverless computing now that it has evolved? In fact, every year at the Amazon CloudTech re:Invent conference, a number of teams share their practical experiences to the audience, and there is no shortage of representative case studies.
At the 2017 Amazon CloudTech re:Invent conference, the Revvel team at Verizon, a US telecom company, presented how they use Amazon Lambda and Amazon S3 to transcode video in different formats. Earlier the team was using an EC2 instance, which became problematic if the video was 2 hours long or hundreds of gigabytes, and HD conversions could take 4-6 hours, and a stop or interruption in the middle of the conversion meant that the work was lost. So the Revvel team’s new approach is to divide the video into 5M chunks and store them in Amazon S3 buckets, then use Amazon Lambda to enable thousands of instances to compute in parallel, finish the transcoding, and then merge them into one complete video, reducing the process to less than 10 minutes and a tenth of the cost.
At Amazon CloudTech re:Invent 2020, Coca-Cola’s Freestyle device innovation team shared their contactless vending solution: using Amazon Lambda and Amazon API Gateway to build a back-end hosted service, and Amazon CloudFront for the front-end. This allowed them to launch a prototype in a week and scale the web application from a prototype to 10,000 machines in three months, allowing them to quickly capture the market during the epidemic.
In this year’s Amazon CloudTech re:Invent conference keynote, Dr. Werner Vogels talked about the serverless solution in the New World Game multiplayer game.
This is a very complex, massively distributed real-time game that can handle 30 times/s of action or state, and requires a lot of CPU resources for redraw and computation. It stores user state in Amazon DynamoDB through 800,000 writes every 30 seconds, so that users can revert to their previous game state in time even if they accidentally interrupt the game. It also records user actions in logs, then uses Amazon Kinesis to transfer log events at a rate of 23 million events per minute, and then pushes the event stream to Amazon S3 for analysis with Amazon Athena. Using this data stream, teams can instantly predict game user behavior and change in-game strategy. Operations in the game environment, such as logins, transactions, notifications, and other operational events, are made possible by Amazon Lambda serverless computing.
Serverless plays a very important role in this multiplayer game, but this large architecture also poses a very big performance challenge for serverless. amazon Lambda reaches a frequency of 150 million calls per minute, which is several times higher than the industry average.

The Future of Serverless
At the end of the year, Amazon Cloud Technologies launched five serverless products in one fell swoop.
Amazon Redshift Serverless, which automatically configures compute resources to analyze structured and unstructured data using SQL across data warehouses, operational databases and data lakes.
Amazon EMR Serverless (preview), a new option in Amazon EMR that enables data engineers and analysts to run petabyte-scale data analytics in the cloud with open source analytics frameworks such as Apache Spark, Hive and Presto.
Amazon MSK Serverless (public preview), a new type of Amazon MSK cluster that is fully compatible with Apache Kafka and eliminates the need to manage Kafka’s capacity as the service automatically pre-populates and scales compute and storage resources.
Amazon Kinesis On-demand, for large-scale real-time streaming data processing, with the service automatically scaling up and down on demand.
Amazon SageMaker Serverless Inference (preview version), which lets developers deploy machine learning models for inference without configuring or managing the underlying infrastructure, paying per execution time and volume of data processed.
As a result, we can see a growing number of Serverless services on the cloud, and the capabilities of serverless computing have expanded from compute, storage, and database services to data analytics, and inference for machine learning. Previously, inference for machine learning required starting a large number of resources to support peak requests. With EC2 inference nodes, idle resources can drive up costs, while with Amazon Lambda services, there is no need to think about cluster node management. The service automatically pre-posts, scales, and shuts down compute capacity based on Workload, paying only for execution time and the amount of data processed, which can save a lot in comparison.
Amazon Serverless services continue to evolve while the computing architecture continues to improve, such as the original Intel x86 processor, the platform provides options to configure the Amazon Graviton2 ARM processor, faster performance and can be 20% cheaper. Some technical experts believe that the platform will also move in the direction of more intelligent, “now need users to change the configuration of the choice of cheaper ARM processor, the future service can do completely automatically select the computing platform.”
As an evolutionary approach to cloud computing, the vision of serverless is bound to change the way we think about writing software. Whereas never before has there been an approach that considers how to design with millions of processor cores and petabytes of memory like cloud computing, serverless has now moved to a stage where it is common and available, and users don’t have to think about how to manage these resources.
As Dr. Werner Vogels said in his keynote, “These large architectures simply wouldn’t be possible without cloud computing. So now, build systems the way you always wanted to, but never could, with an architecture that belongs to the 21st century.”