Database management systems are an important part of software today. Open source databases such as MySQL, PostgreSQL, and commercial Oracle are everywhere, and almost all services rely on database management systems to store data.

It sounds like a matter of course that a database will not lose data, and persistence capability should be the most basic guarantee of a database, but in this complex world it is very difficult to guarantee that data will not be lost. In today’s world, we can find many examples of databases with problems that lead to data loss.
- MongoDB has not been able to guarantee persistence for a long time in the past, and data can be lost very easily.
- Data loss problems caused by RocksDB DeleteRange function.
- Tencent Cloud hard disk failure, resulting in complete loss of online production data for startups.
Data loss can occur in both open source databases and services provided by cloud providers. In this paper, we attribute the causes of database data loss to the following aspects, which we will expand on in detail.
- Human-caused operational and configuration errors are the primary cause of database data loss.
- Data loss due to corruption of the disks used to store data in the database.
- the complexity of the functions and implementation of the database, the risk of data loss if the data is not flushed to disk in a timely manner.
Human error
Human error is the primary cause of data loss. In the Tencent Cloud data loss accident, we will find that although the cause of the accident is hardware failure, it is the improper operation of operation and maintenance personnel that ultimately leads to the damage of data integrity: > The first is that the normal data relocation process opens data verification by default.
The first is that the normal data relocation process opens data verification by default, which can effectively detect and avoid data abnormalities at the source end and guarantee the correctness of relocation data after opening, but the operation and maintenance personnel violated the data verification in order to speed up the completion of the relocation task.
The second is that after the normal data relocation is completed, the source warehouse data should be retained for 24 hours for data recovery in the case of relocation anomalies, but the operations and maintenance staff violated the data recovery of the source warehouse in order to reduce the warehouse utilization rate as soon as possible.
The best way to reduce human error is to standardize operations such as data backup and operation and maintenance, and use automated processes to handle operations involving data security, so as to reduce the risks associated with human intervention.
For software engineers, we should be in awe of the production environment and be careful to perform all operations in the production environment, recognizing that all operations may have an impact on the services that are running online, so that the probability of similar problems can be reduced.
Hardware Errors
It is extremely fortuitous for any online service to function properly, and there is no way we can guarantee 100% availability of a service if it is stretched out over a long enough period of time. Hardware such as disks are likely to become corrupted if they are used for a long enough period of time, and according to data from a Google paper, the annualized failure rates (AFR) of hard disks over a 5-year period is 8.6%.
In 2018, the cause of the Tencent Cloud data corruption incident was a single copy data error caused by a disk silent error (Silent data corruption). Silent disk errors are errors that are not detected by disk firmware or the host operating system and include the following: loose cables, unreliable power supply, external vibration, network-induced data loss, and other issues.
It is because data corruption on disks is so common that we need data redundancy to ensure that disks can recover disk data in the event of an Unrecoverable Read Error (URE). Redundant Array of Independent Disks (RAID) is a data storage virtualization technology that can combine multiple physical disks into a single logical disk to increase data redundancy and improve performance.
RAID uses three main policies: Striping, Mirroring and Parity to manage the data on the disk, and here are a few simple examples.
- RAID 0 uses data striping, but no mirroring or parity. It provides little to no protection for the data on the disk, and a corruption of any disk disk means that the data on it cannot be recovered, but it also provides better performance because there is no redundancy.
- RAID 1 uses data mirroring, but there is no parity or data splitting. All data is written to two identical disks, and both disks are externally available for data reading. This approach reduces disk utilization, but improves read performance and provides backups.
- …
RAID uses a partitioning and mirroring strategy that is more similar to partitioning and replication in distributed databases. Partitioning and partitioning slice and distribute data to different disks or machines, while mirroring and replication both serve to replicate data.
Many modern operating systems provide software-based RAID implementations, and some cloud service vendors use self-developed file systems or redundant backup mechanisms.
- Google uses Google File System to manage files, which stores files in blocks and manages all file blocks through a master service.
- Microsoft uses erasure coding in Azure to calculate redundant data.
Hardware errors are common in production environments and the only way we can reduce the possibility of data loss is through data redundancy and checksumming, but adding redundancy can only continuously reduce the probability of data loss and cannot be avoided 100% of the time.
Implementation Complexity
Database management systems eventually store data on disk, and for many databases, data falling to disk means that persistence is complete. Disk as the lower layer of the database system, disk can be stable storage data is the basis of the database can persist data.

Many people mistakenly believe that using write will write data to disk, but this is wrong. Not only does the write function not guarantee that data will be written to disk, some implementations do not even guarantee that the target space is reserved for the written data[. In general, write to a file only updates the page cache in memory, which is not immediately flushed to disk, and the operating system’s flusher kernel thread will drop the data to disk when the following conditions are met.
- free memory drops to a specific threshold and the memory space occupied by dirty pages needs to be released.
- dirty data lasts for a certain amount of time and the oldest data is written to disk.
- the user process executes the
syncorfsyncsystem call.
If we want to flush data to disk immediately, we need to call functions such as fsync immediately after executing write, and only when functions such as fsync return will the database notify the caller that the data has been written successfully.
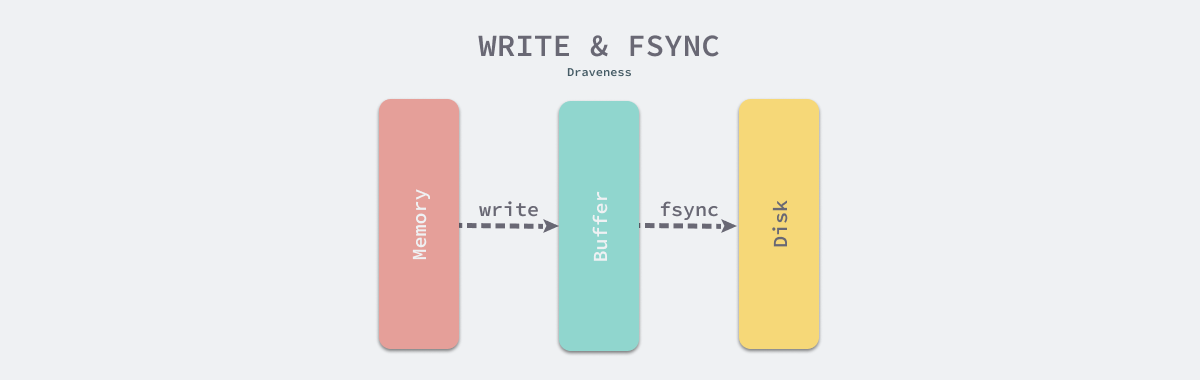
write and fsync are very important in a database management system as they are the core methods for providing persistence guarantees, and some developers write the wrong code with a wrong understanding of write which can lead to data loss.
In addition to persistence features, databases may also need to provide ACID (Atomicity, Consistency, Isolation, Durability) or BASE (Basically Available, Soft state, Eventual consistency) guarantees. Some databases also provide complex features such as sharding, replicas, and distributed transactions. The introduction of these features also increases the complexity of the database system, and as the complexity of the program increases, so does the likelihood of problems.
Summary
Database management systems are among the most complex and important systems in software engineering, and the proper operation of almost all services is based on the assumption that the database will not lose data. However, databases cannot fully guarantee data security because of the following reasons shown below.
- There is a high risk of data loss due to operational errors by operations staff during configuration and operation.
- Hardware errors in the underlying disks on which the database depends, resulting in unrecoverable data.
- The database system supports very many and complex functions, and data loss may be caused by data not falling on disk in a timely manner.
Once the accident of data loss, the impact caused will be very large, we can not completely trust the stability of the database when using the database to store core business data, you can consider using hot standby and snapshots and other ways of disaster recovery. At the end, we still look at some more open related issues, interested readers can think carefully about the following issues.
- Besides the data loss incidents listed in the article, what other databases or cloud providers have lost data?
- When does Redis’ RDB and AOF mechanisms drop data to disk?
- How exactly should a successful data write to the database be defined?