The TCP protocol is arguably the cornerstone of today’s Internet, and as a reliable transport protocol, almost all data is transmitted over TCP today. However, TCP was not designed with today’s complex network environment in mind, and when you are tormented by intermittent networks on the subway or train, you may not even know that it may all be caused by the TCP protocol. This article will analyze why the TCP protocol has serious performance problems in weak network environments
The analysis in this paper is based on the TCP protocol as defined in RFC 793. Almost 40 years have passed since the publication of RFC 793, and several non-mandatory RFCs with the status Proposed Standard have revised the TCP protocol in an attempt to optimize TCP protocol performance, such as Selective ACK (SACK), False Timeout Profile (Forward RTO, F-RTO), and TCP Fast Open (TFO), have been revised in several non-mandatory RFCs with Proposed Standard status to try to optimize the performance of the TCP protocol, and implementations of these RFCs have been included in the latest versions of Linux.
The underlying data transfer protocol has to be designed with trade-offs and trade-offs between bandwidth utilization and communication latency, so trying to solve all the problems in real production is impossible. TCP chooses to make full use of bandwidth and design for traffic, expecting to transfer as much data as possible in as short a time as possible.
In network communication, the time from the time the sender sends data until it receives an acknowledgement from the receiver is called Round-Trip Time (RTT).
The weak network environment is a special scenario with high packet loss rate, and TCP performs poorly in a similar scenario. When the RTT is 30ms, once the packet loss rate reaches 2%, the TCP throughput drops by 89.9%.
| RTT | TCP Throughput | TCP Throughput (2% Packet Loss Ratio) |
|---|---|---|
| 0 ms | 93.5 Mbps | 3.72 Mbps |
| 30 ms | 16.2 Mbps | 1.63 Mbps |
| 60 ms | 8.7 Mbps | 1.33 Mbps |
| 90 ms | 5.32 Mbps | 0.85 Mbps |
This paper will analyze three reasons why TCP performance is affected in weak network environments (high packet loss).
- TCP’s congestion control algorithm actively reduces throughput in case of packet loss.
- TCP’s three handshakes increase the latency and additional overhead of data transmission.
- TCP’s cumulative answer mechanism that results in the transmission of data segments.
Of the above three reasons, the congestion control algorithm is the primary cause of TCP’s poor performance in weak networks, with triple handshake and cumulative answer having a decreasing impact, but also exacerbating TCP’s performance problems.
Congestion Control
The TCP congestion control algorithm, the primary congestion control measure on the Internet, uses a set of network congestion control methods based on Additive increase/multiplicative decrease (AIMD) to control congestion, and is the primary cause of TCP performance problems.
The first identified Internet congestion collapse was in 1986, when the processing capacity of the NSFnet Phase I backbone was reduced from 32,000 bits/s to 40 bits/s. The processing capacity of this backbone was not resolved until 1987 and 1988, when congestion control was implemented in the TCP protocol. It was because of the crashes caused by network blocking that TCP’s congestion control algorithm assumed that whenever packet loss occurred the current network was congested, and from this assumption the original TCP implementations, Tahoe and Reno, used both slow-start and congestion avoidance mechanisms to implement congestion control, and the analysis of congestion control in this section is based on this version of the implementation.

Each TCP connection maintains a Congestion Window, which determines how much data the sender can send to the receiver at the same time and serves two main purposes.
- to prevent the sender from sending too much data to the receiver that the receiver cannot process.
- to prevent either side of a TCP connection from sending a large amount of data into the network, causing the network to collapse with congestion.
In addition to the congestion window size (cwnd), both sides of a TCP connection have a receive window size (rwnd). At the beginning of a TCP connection, both the sender and the receiver do not know each other’s receive window size, so both sides need a dynamic estimation mechanism to change the speed of data transmission. The receive window size is generally determined by the bandwidth-delay product (BDP), but we won’t go into that here.
The maximum number of data segments that a client can transmit simultaneously is the minimum of the receive window size and the congestion window size, min(rwnd, cwnd) The initial congestion window size for a TCP connection is a relatively small value, defined in Linux by TCP_INIT_CWND as follows.
The size of the initial congestion control window has been modified several times since its inception, and several RFC documents called Increasing TCP’s Initial Window: RFC2414, RFC3390, and RFC6928 have increased the value of initcwnd to accommodate increasing network transmission speeds and bandwidth, respectively.
The TCP protocol uses the slow start threshold (ssthresh) to determine whether to use the slow start or congestion avoidance algorithm.
- Use slow start when the congestion window size is less than the slow start threshold.
- using the congestion avoidance algorithm when the congestion window size is greater than the slow start threshold.
- using the slow start or congestion avoidance algorithm when the congestion window size is equal to the slow start threshold.
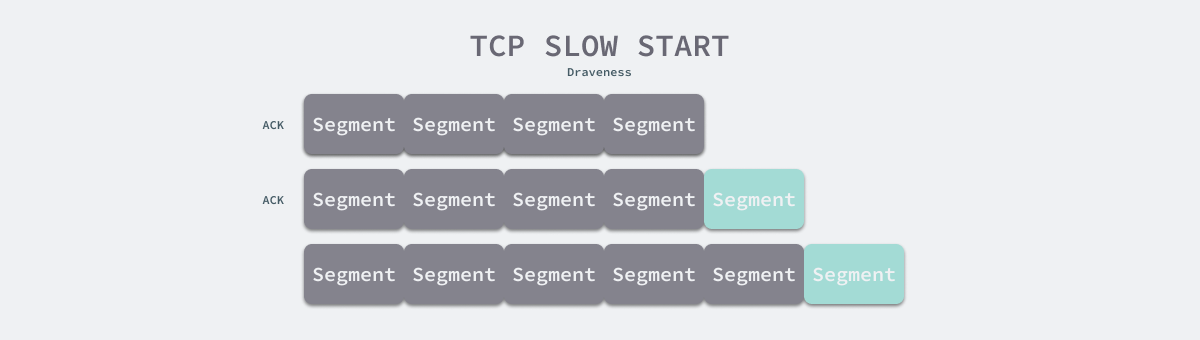
As shown above, when using TCP slow start, the congestion window size is increased by one for each ACK message received by the sender from the responder. When the congestion window size is larger than the slow-start threshold, the congestion avoidance algorithm is used.
- Linear growth: the congestion window size is added by one for each ACK received.
- progressive decrease : the slow-start threshold is set to half the congestion window size when the sender sends a packet that drops packets.
Early implementations of TCP, Tahoe and Reno, reset the congestion control size to its initial value when they encounter packet loss and re-enter the slow-start phase because the congestion window size is less than the slow-start threshold.
If a TCP connection has just been established and the client is able to send 10 data segments at the same time due to the default settings of the Linux system, assuming that the bandwidth of our network is 10M, the RTT is 40ms, and the size of each data segment is 1460 bytes, then the upper limit of the window size for both sides of the communication calculated using BDP should be 35 in order to fully utilize the bandwidth of the network.
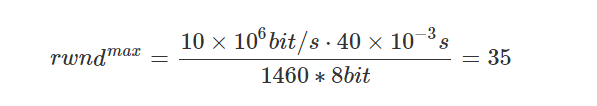
However, the congestion control window size rises from 10 to 35 in 2RTT time, as follows.
- the sender sends
initcwnd = 10data segments to the receiver (consuming 0.5RTT). - the receiver receives 10 data segments and sends an ACK to the sender (consuming 0.5RTT).
- the sender receives the ACK from the sender and the current congestion control window size reaches 20 due to the successful transmission of 10 data segments +10.
- the sender sends 20 data segments to the receiver (consuming 0.5RTT).
- the receiver receives 20 data segments and sends an ACK to the sender (consuming 0.5RTT).
- the sender receives the ACK from the sender and the current congestion control window size reaches 40 due to the successful transmission of 20 data segments +20.
It takes 3.5RTT, or 140ms, from the time the TCP triple handshake establishes the connection to the time the congestion control window size reaches its maximum value of 35 for the assumed network condition, which is a relatively long time.
In the early days, most computing devices on the Internet were connected through wired networks, and the possibility of network instability was relatively low, so the designers of the TCP protocol thought that packet loss meant network congestion, and once packet loss occurred, frantic retries by the client could lead to a congested collapse of the Internet, so the congestion control algorithm was invented to solve the problem.
However, today’s network environment is more complex, and the introduction of wireless networks has led to network instability becoming the norm in some scenarios, so packet loss does not necessarily mean network congestion, and better results will be obtained in some scenarios if more aggressive strategies are used to transmit data.
Triple Handshake
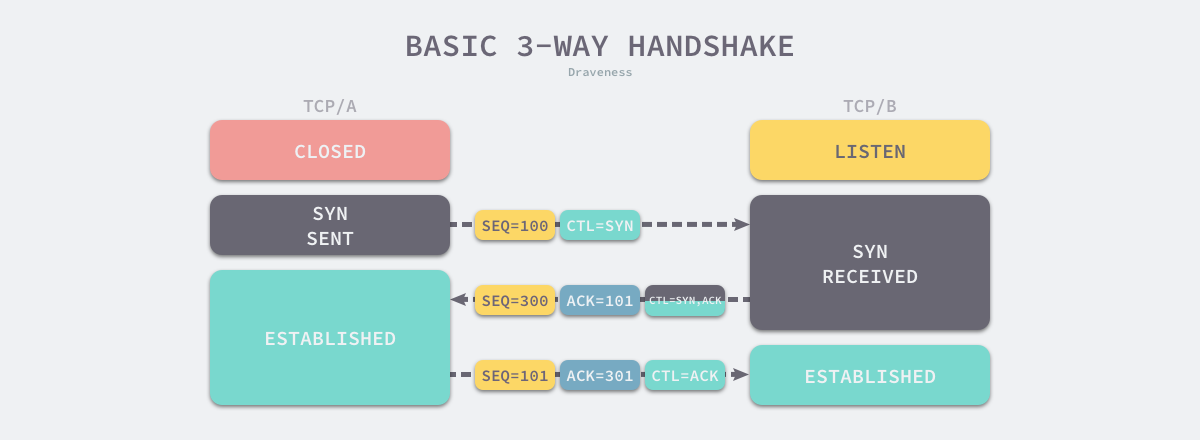
TCP uses three handshakes to establish a connection which should be well understood by all engineers around the world. The main purpose of three handshakes is to avoid the establishment of historically incorrect connections and to allow the two communicating parties to determine the initial sequence number, however three handshakes are quite costly and it requires three communications between the two parties establishing a TCP connection without packet loss.
If we want to access the server in Shanghai from Beijing, the RTT must be greater than 6.7ms since the straight line distance from Beijing to Shanghai is about 1000+ km and the speed of light is the limit of current communication speed.
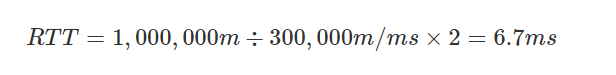
However, because light does not travel in a straight line in optical fiber, the real transmission speed is ~31% slower than the speed of light, and the data needs to bounce back and forth between various network devices, so it is difficult to reach the theoretical limit. In a production environment, the RTT from Beijing to Shanghai is about 40ms, so the shortest time required for TCP to establish a connection is 60ms (1.5RTT).
In scenarios such as subways and stations where the network environment is poor, it is difficult for the client to quickly complete three communications with the server and establish a TCP connection because of the high packet loss rate. When the client does not receive a response from the server for a long time, it can only keep initiating retries, and the access latency will become higher and higher as the number of requests gradually increases.
Since most HTTP requests do not carry a lot of data, the uncompressed request and response headers are around ~200B to 2KB in size, and the additional overhead from the three TCP handshakes is 222 bytes, with Ethernet data frames accounting for 3 * 14 = 42 bytes, IP data frames accounting for 3 * 20 = 60 bytes, and TCP data frames accounting for about 120 bytes (the overhead of the three handshakes is request and environment dependent, and the exact value is variable).
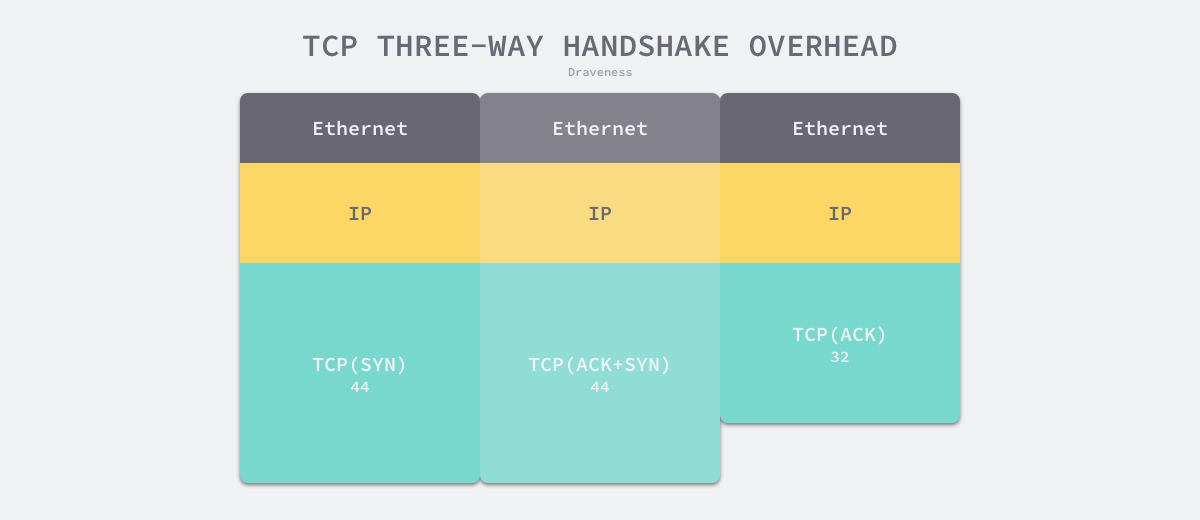
Although TCP does not establish a connection for each outgoing data segment, the cost of establishing a connection with three handshakes is quite high, requiring not only an additional 1.5 RTT of network latency but also an additional 222 bytes of overhead, so establishing a connection with three handshakes can exacerbate TCP performance problems in a weak network environment.
Retransmission mechanism
The reliability of TCP transfers is guaranteed by the sequence number and the receiver’s ACK. When TCP transfers a data segment, it puts a copy of that data segment on the retransmission queue and turns on the timer: ## When TCP transfers a data segment, it puts a copy of that data segment on the retransmission queue and turns on the timer.
- If the sender receives an ACK response corresponding to that data segment, the current data segment is removed from the retransmission queue.
- If the sender does not receive an ACK corresponding to that data segment between timer expirations, the current data segment is retransmitted.
TCP’s ACK mechanism may cause the sender to retransmit a data segment already received by the receiver. an ACK message in TCP indicates that all messages prior to that message have been successfully received and processed, such as.
- the sender sends a message to the receiver with serial numbers 1-10.
- the receiver sends an ACK 8 response to the sender.
- the sender assumes that the messages with serial numbers 1-8 have been successfully received.
This ACK approach is simpler to implement and easier to ensure the sequential nature of the messages, but it may cause the sender to retransmit data already received in the following cases.
As shown above, the receiver has received data with serial numbers 2-5, but since the semantics of TCP ACK is that all data segments before the current segment have been received and processed, the receiver cannot send an ACK message, and since the sender has not received the ACK, the timer corresponding to all data segments will time out and retransmit the data. With more severe packet loss networks, this retransmission mechanism can result in significant bandwidth waste.
The fast retransmission proposed in RFC2581 alleviates this problem by sending three consecutive ACKs to trigger a retransmission from the sender as soon as the receiver receives the out-of-order data segment.
Summary
Some designs of the TCP protocol, while still of great value today, are not applicable to all scenarios. To solve the performance problems of TCP, there are two solutions in the industry today.
- use UDP to build a better performing and more flexible transport protocol, e.g., QUIC, etc.
- optimizing the performance of TCP protocol by different means, such as Selective ACK (SACK), TCP Fast Open (TFO).
Since the TCP protocol is in the operating system kernel, which is not conducive to protocol updates, the first option is currently better developed, and HTTP/3 uses QUIC as the transport protocol. We revisit here three important causes of TCP performance problems.
- TCP’s congestion control backs off in the event of packet loss, reducing the number of data segments that can be sent, but packet loss does not necessarily mean network congestion, but more likely poor network conditions.
- TCP’s three handshakes introduce additional overhead that includes not only the need to transmit more data, but also increases the network latency for the first transmission of data.
- TCP’s retransmission mechanism may retransmit segments of data that have been successfully received when packets are lost, resulting in wasted bandwidth.
The TCP protocol is well deserved as the cornerstone of Internet data transmission, and although it does have some problems in dealing with special scenarios, its design ideas have a lot to learn and are worth studying.
In the end, let’s look at some of the more open questions, and interested readers can think carefully about the following issues.
- Can the QUIC protocol guarantee transmission performance when packet loss is high?
- What are the other means to optimize TCP performance besides SACK and TFO?