Background
A friend asked me a while ago what the difference between deleting a file and formatting it, and recently I happened to be reading the book “Unix Linux Programming Practice Tutorial”, chapter 4 of which is about the file system.
The internal structure of the Unix file system
From the user’s point of view, the files on a Unix system form a directory tree, each directory can contain files or other directories. The contents of the files are placed in the corresponding directories, and the contents of the corresponding directories are placed in the higher-level directories.
The file system is a multi-level abstraction of the hard disk device and contains the following three main layers.
Layer 1: From hard drive to partition
A hard disk is capable of storing a large amount of data. A hard disk can be divided into multiple areas, or hard disk partitions, each of which can be seen as a separate hard disk in the system.
Layer 2: From disks to block sequences
A hard disk consists of a number of magnetic platters, each surface of which is divided into a number of concentric circles, these concentric circles are called tracks, each track is further divided into sectors, each sector can store a certain number of bytes of data, for example 512 bytes of space per sector. Sectors are the basic unit of storage on a disk, and disks contain a large number of sectors.

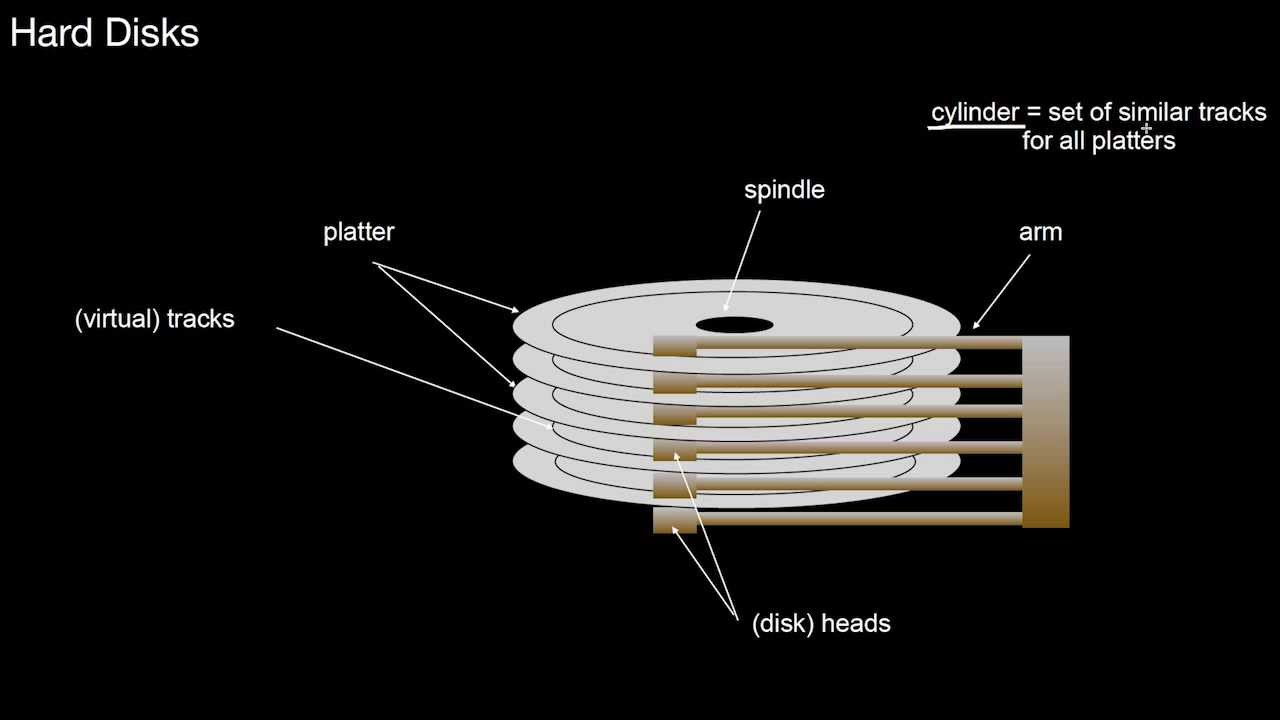
Assigning consecutive numbers to each disk block allows the operating system to count each block on the disk, either by numbering all the blocks from top to bottom, disk by disk, or by numbering all the blocks from the outside in, track by track. A system of numbering disk sectors allows us to think of the disk as a series of blocks.
Layer 3: from block sequences to the three zone divisions
The file system can be used to store file contents, file attributes (file owner, date, etc.) and directories. How are these different types of data stored on numbered disk blocks?
File system zoning

One part becomes the data area, which is used to store the real contents of the file. Another part becomes the i-node table, which holds the file attributes. The third part is the superblock, which holds information about the file system itself. The file system is a combination of these 3 parts, any one of which is made up of a number of ordered disk blocks.
Superblock
The first block of the file system is called a superblock. This block holds information about the structure of the file system itself, such as the size of each area. The superblock also holds information about unused disk blocks. The superblock information varies from file system to file system and can be viewed with similar commands such as debugfs.
i-node table
The next part of the file system is called the i-node table. Each file has a number of attributes such as size, file owner and last modified time etc. These attributes are recorded in a structure called an i-node, all i-nodes have the same size and the i-node table is a list of these i-node structures. There is one i-node for each file in the file system.
Data area
The 3rd part of the file system is the data area. The real contents of the file are stored in this area. All blocks on the disk are the same size. If the file contains the contents of more than one block, the file contents are stored in multiple disk blocks. A larger file can easily be spread over thousands of separate disk blocks.
Explanation of common operation procedures
Creating a file
When we create a file, there are 4 main operations.
- Storing attributes
- Storage of file attributes: the kernel first finds an empty i-node and records the file’s information into the i-node.
- Storing data
- Storage of file contents: the kernel finds enough data blocks from the list of unused data blocks and then copies the data from the buffer to the corresponding data block.
- Recording allocation
- The file contents are stored in the data blocks in order. The kernel records the above sequence of blocks in the disk distribution of the i-node. The disk distribution area is a list of disk block serial numbers.
- Adding a file name to a directory
- The kernel adds the file i-node number and corresponding file name to the directory file. The correspondence between the file name and the i-node number correlates the file name with the file contents and file attributes.
What do I do if I create a large file? A large file requires multiple disk blocks and stores a list of disk block allocations in the i-node, but the length is fixed, i.e. there is an upper limit to the file size, how do you support as large a file as possible?
If a file needs 14 blocks to store its contents, but the i-node only contains an allocation list with 13 entries, this is done by putting the first 10 numbers from the allocation list into the i-node, putting the last 4 numbers into a data block, and then using the 11th entry in the i-node as a point to the data block holding the 4 block numbers. In the end the file uses a total of 15 blocks, the extra blocks used become indirect blocks.

View files
- Finding a filename in a directory
- The filename is stored in the directory file, the kernel looks for a record containing the filename in the directory file, and then finds the corresponding i-node number
- Locating the i-node number and reading the contents
- The kernel finds the corresponding i-node in the i-node area of the file system. locating the i-node requires a simple calculation, all i-nodes are the same size and each disk block contains the same number of i-nodes. the kernel places the i-node as a buffer and the i-node contains a list of data block numbers.
- Accessing the blocks that store the contents of a file
- With the i-node information, the kernel already knows which data blocks the file’s real contents are stored on, and the order in which they are copied bytes from the disk to the kernel buffer before reaching user space.
Creating directories
A directory is a special kind of file containing a list of file names. The internal structure of Unix directories varies from version to version, but the abstract model is the same - a list containing i-node numbers and file names.
When a file is to be shared in multiple ways and to ensure that they are one file with multiple valid pathnames, the system introduces linking mechanisms: hard and soft links. Where hard links are consistent with the i-node of the file. The number of hard links in a file’s content itself is 1 when it is first created, and increases when it is created by other means.
“File in directory” means from a system point of view that there is an entry in the directory containing the file name and the corresponding i-node number, “File x in directory a” means that there is a link to the corresponding i-node in directory a. This link The name of the file attached to this link is x. In simple terms, a directory contains references to files, each reference is a link, the contents of the file are stored in a data block, the attributes of the file are recorded in the i-node, and the i-node number and file name are stored in the directory.
Deleting a file
Deleting a file removes a reference record of the corresponding file from a directory and reduces the number of links of the corresponding i-node. However, the real content of the file still exists in the block and has not been deleted. If you stop all operations immediately after discovering the deletion, it is possible to recover the data in some way.