Windows is the core of processing wireless data streams, it splits the streams into buckets of finite size and performs various calculations on them.
The structure of a windowed Flink program is usually as follows, with both grouped streams (keyed streams) and non-keyed streams (non-keyed streams). The difference between the two is that the grouped streams call the keyBy(...) method in grouped streams and windowAll(...) instead of the window(...) method in grouped streams.

Window lifecycle
A window is created when the first element belonging to it arrives and is completely removed when the time (event or processing time) has elapsed after its end timestamp and the user-specified allowed delay. Also, Flink ensures that only time-based windows are removed, but not for other types (e.g. global windows). For example, if an event time based window policy creates a non-overlapping window every 5 minutes and allows a 1 minute delay, then Flink will create a new window for the first element whose timestamp belongs to the interval 12:00-12:05 when it arrives, until the watermark reaches the timestamp 12:06, when Flink deletes the window.
In Flink, each window has a Trigger and a function (ProcessWindowFunction, ReduceFunction, AggregateFunction or FoldFunction) associated with it. The function contains the computational logic that acts on the elements of the window, and the trigger is used to specify the conditions under which the window’s function is to be executed. The trigger policy is usually similar to “when the number of elements in the window exceeds 4” or “when watermark reaches the window end time stamp”. Triggers can also decide to clear the contents of a window at any time during its lifetime. The clear operation in this case only involves the elements of the window, not the window metadata. That is, new elements can still be added to the window.
In addition, you can specify an Evictor, which can remove elements from the window after the trigger has been triggered and before or after the function has acted.
Grouped and ungrouped windows
Before defining the window, the first thing that needs to be clarified is whether our data streams need to be grouped or not. Using keyBy(...) will separate the wireless stream into logically grouped streams, and vice versa, without grouping the stream data.
In a grouped stream, any property of the incoming event can be used as a key for the grouped stream. Since each grouped stream can be processed independently of the other streams, multiple tasks are allowed in a grouped stream to perform window calculations in parallel. All elements that reference the same key will be sent to the same parallel task.
For ungrouped streams, the data source is not separated into multiple logical streams, and all window computation logic will be executed in one task.
Window Assigner
After determining whether the windows are grouped or not, next we need to define the assigners, which define how the elements are assigned to the windows.
WindowAssigner is responsible for assigning incoming elements to one or more windows. flink provides us with several predefined WindowAssigners based on some common application scenarios, namely tumbling windows, sliding windows, session windows, and global windows. session windows, and global windows. We can also customize the window assigner logic by inheriting from WindowAssigner class.Among the built-in WindowAssigners in Flink, except for global windows, the rest of them assign elements to windows based on processing time or event time.
Time-based windows contain a start timestamp (greater than or equal to) and an end timestamp (less than), and the time difference between the two is used to represent the window size. Also, we can query the start and end timestamps through the TimeWindow provided by Flink, and we can get the maximum timestamp allowed for a given window through the maxTimestamp() method.
Tumbling Windows
The scrolling window allocator will assign each element to a window of the specified window size. Scrolling windows have a fixed window size and the windows do not overlap with each other. For example, the image below shows a scrolling window set to a 5-minute window size, and a new window is created every five minutes.
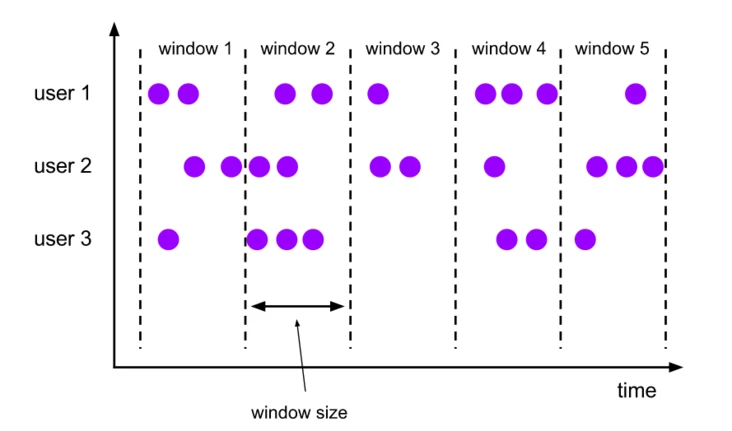
|
|
As the last example in the above code shows, tumbling window assigners contain an optional offset parameter that we can use to change the alignment of the window. For example, an hourly scrolling window with no offset creates a time window that is typically 1:00:00.000 - 1:59:59.999 , 2:00:00.000 - 2:59:59.999 , and when we are given a 15 minute offset, the time window will become 1:15:00.000 - 2:14: 59.999 , 2:15:00.000 - 3:14:59.999 . In practice, a more common usage scenario is to adjust the window to a time zone other than UTC-0 by offset, for example, by Time.hours(-8) to adjust the time zone to East 8.
Sliding Windows
The sliding window allocator also assigns elements to fixed-size time windows. The window size is configured in the same way as the scrolling window, except that the sliding window has an additional slide parameter to control how often the window slides. When slide is smaller than window size, the sliding windows will overlap. In this case the same element will be assigned to multiple windows.
For example, in the figure below, a sliding window of 10 minutes in size is set with a sliding parameter (slide) of 5 minutes. In this case, a new window will be created every 5 minutes, and this window will contain some elements from the previous window.

|
|
Similarly, we can set the offset for the window with the offset parameter.
Session Windows
Session windows group elements by active sessions. Unlike scrolling and sliding windows, session windows do not overlap and do not have fixed start and end times. When a session window does not receive new data within the specified time interval, this window will be closed. The session window allocator can be configured directly with a static constant session interval, or dynamically with a function that specifies the session interval time.
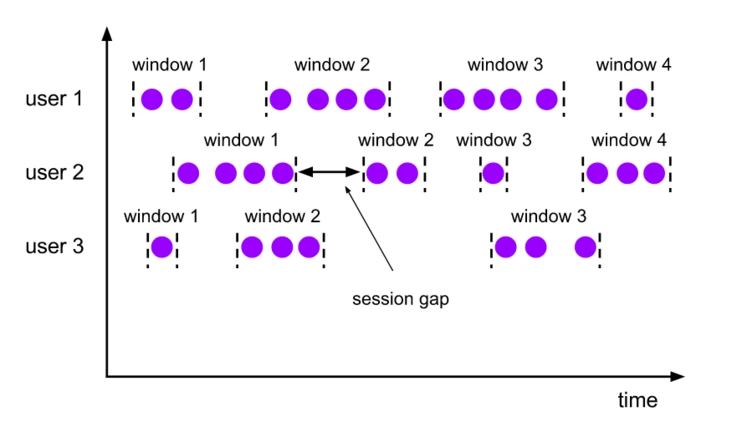
|
|
As above, fixed size session interval can be specified by Time.milliseconds(x) , Time.seconds(x) , Time.minutes(x) , dynamic session interval is specified by implementing SessionWindowTimeGapExtractor interface.
Note: Since a session window does not have a fixed start/end time, it is calculated differently than a scrolling window or a sliding window. Inside a session window operator a new window is created for each received element, and if the time interval between these elements is less than the defined session window interval, the amen is merged into one window. To be able to perform a window merge, we need to define a Tigger function and a Window Function function for the session window (e.g. ReduceFunction, AggregateFunction, or ProcessWindowFunction. FoldFunction cannot be used for FoldFunction cannot be used for merging).
Global Windows
The global window allocator will assign all elements with the same key value to the same window. This window mode requires us to set a custom Trigger, otherwise no computation will be performed, this is because the global window does not have a natural end that can handle aggregated elements.

Window Function
After defining the window allocator, we need to specify the computation that acts on each window. This can be done by specifying a Window Function, which will process each element of the window once the system has determined that a window is ready to be processed.
Window Functions are typically available as ReduceFunction, AggregateFunction, FoldFunction, and ProcessWindowFunction, of which the first two can be executed efficiently because Flink can aggregate each element incrementally as it arrives at the window. ProcessWindowFunction holds Iterable objects for all elements contained in a window, as well as additional meta information for the window to which the element belongs.
ProcessWindowFunction cannot be executed efficiently because Flink must internally cache all the elements in the window before calling the function. We can mitigate this problem by combining ProcessWindowFunction with ReduceFunction , AggregateFunction , or FoldFunction functions to get aggregated data about the window elements and the The window meta data received by the ProcessWindowFunction.
ReduceFunction
ReduceFunction is used to indicate how to combine two elements in the input stream to produce an output element of the same type. flink uses ReduceFunction to incrementally aggregate the elements in the window.
|
|
AggregateFunction
AggregateFunction can be called a generalized ReduceFunction, and it contains three element types: input type (IN), accumulator type (ACC), and output type (OUT).
The AggregateFunction interface has a method for creating an initial accumulator, combining the values of two accumulators into one accumulator, and extracting the output from the accumulator.
|
|
FoldFunction
FoldFunction is used to specify how the input elements in the window are combined with the output elements of the given type. For each element entered into the window, the FoldFunction is called incrementally to combine it with the current output value.
Note: fold() cannot be used for session windows or other mergeable windows
ProcessWindowFunction
From ProcessWindowFunction you can get an iterative object containing all the elements in the window and a Context object to access time and state information, which makes it more flexible than other window functions. Of course, this also comes with a greater performance overhead and resource consumption.
|
|
where the key parameter is the key value obtained by the KeySelector specified in keyBy(). For keys indexed by tuples or referenced by string fields, the KEY parameter type here is a tuple type, which we need to manually convert to a tuple of the correct size in order to extract the key value from it.
|
|
ProcessWindowFunction with Incremental Aggregation
As mentioned earlier, we can use ReduceFunction, AggregateFunction, or FoldFunction in conjunction with ProcessWindowFunction to not only perform window calculations incrementally, but also to obtain some additional window meta information that ProcessWindowFunction provides us.
Incremental Window Aggregation with ReduceFunction
The following example shows how to combine the two to return the minimum event in the window and the start time of the window
|
|
Incremental Window Aggregation with AggregateFunction
Example: Calculate the average value of the elements, and output the key value and the average value at the same time.
|
|
Incremental Window Aggregation with FoldFunction
Example: Return the number of events in the window, along with the key value and the window end time.
|
|
Triggers
Triggers are used to determine when a window is processed by the window function. each WindowAssigner in Flink has a default Trigger. we can also customize the trigger rules with the trigger(...) function to customize the trigger rules.
The Trigger interface contains the following 5 methods.
- The
onElement()method is called for each element that is added to a window. - The
onEventTime()method is called when a registered event-time timer fires. - The
onProcessingTime()method is called when a registered processing-time timer fires. - The
onMerge()method is relevant for stateful triggers and merges the states of two triggers when their corresponding windows merge,_e.g._when using session windows. - Finally the
clear()method performs any action needed upon removal of the corresponding window.
Evictors
Flink window mode allows us to specify an optional Evictor in addition to WindowAssigner and Trigger. evictor can remove elements from the window after the trigger is started and before or after the window function acts.
|
|
Flink provides us with three predefined evictors.
CountEvictor: Keeps the user-specified number of elements in the window and removes the other elements from the beginning part of the window buffer.DeltaEvictor: Gets a DeltaFunction function and a threshold value, calculates the Delta value of the remaining elements in the window buffer with respect to the last element, and then removes the elements with a Delta value greater than or equal to the threshold value.TimeEvictor: Holds a millisecondintervalparameter that, for a given window, finds the maximum timestamp max_ts in the element, and then removes those elements with timestamps less than max_ts - interval value.
All predefined Evictors are executed before the window function acts.
Allowed Lateness
When using event time windows, there may be cases where elements arrive late. For example, the watermark used by Flink to track a single event time process has crossed the end time of the window to which the element belongs.
By default, when the watermark crosses the end time of the window, the delayed arrival of the element will be discarded. However, Flink allows us to specify a maximum delay time for a window that allows how long an element can be delayed before it is deleted (when the watermark reaches the end time), and its default value is 0. Depending on the trigger used, elements that arrive late but are not discarded may cause the window to be triggered again. This will be the case with EventTimeTrigger.
Side Output
Flink’s side output allows us to get a stream of data from a deprecated element. As follows, you can get the side output stream by setting the sideOutputLateData(OutputTag) of the window.
|
|