The system must control the timeout time of each link when providing HTTP services to the outside world, otherwise it is vulnerable to DDos attacks. The business framework used by our department is based on the Go language net/http standard library secondary development. When I was developing the framework, I did not have a deep understanding of the timeout control of the Go HTTP server. TimeoutHandler in the outermost layer was enough. TimeoutHandler in the outermost layer was enough. After the system went online, there had been no problems in this area, and I felt good about myself. In fact, it was because we set the timeout control in the outermost nginx and did not expose the system to the problem. When we ran another business system on AWS, because the AWS ALB configuration was different from the original nginx, we found that using only http. I was killed on the spot, so I rushed to find out why. I looked at the source code of the Go language HTTP service and found the cause of the deadlock. Today, I’ll share my experience with you. While looking at the code, I found that the Go HTTP server starts another goroutine after reading the complete HTTP request, and the goroutine tries to read another byte of content. It was very strange 🤔 I also looked into it, and eventually found the issue and commit logs, and discovered a flaw in the Go language, which I’ll share with you today.
The corresponding structure of the Go HTTP server is net/http.Server, and there are four timeout-related configurations.
ReadTimeoutReadHeaderTimeoutWriteTimeoutIdleTimeout
In addition to these four configurations, TimeoutHandler can be used, but this needs to be generated by calling net/http.TimeoutHandler() with the following function signature.
The above configuration and TimeHandler corresponding to the role of the process as follows (from Cloudflare).
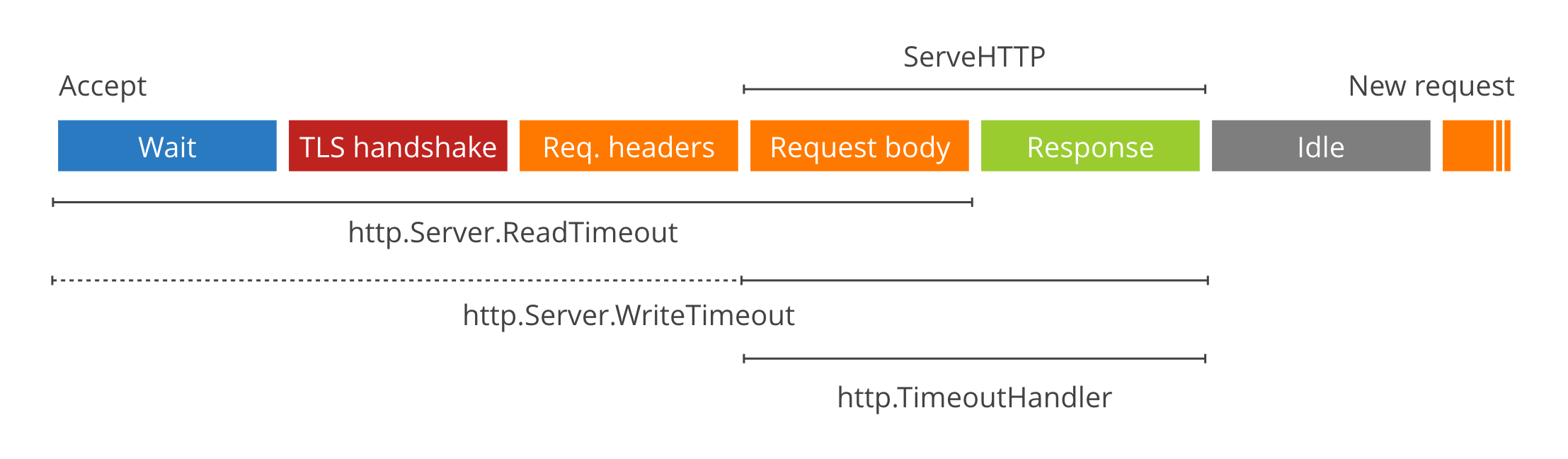
This is a very important diagram because it shows the different stages of HTTP request processing by http.Server. http.Server starts and calls the Accept method and waits for the client to initiate an HTTP request. Once the client establishes a TCP connection, the server starts waiting for the client to send an HTTP request. This corresponds to the Wait phase on the far left. In general, Go HTTP services are rarely directly external, so TLS sessions are handled by edge gateways (like Nginx), so we skip the TLS handshake phase. Server starts reading the header part of the HTTP request, which leads to the Req. After processing the header information of the request, http.Server knows which Handler’s ServeHTTP method to call, and thus enters the ServeHTTP phase. The server does not read the body content of the request in the Req.headers phase, but prepares a body object for the Req object. So the ServeHTTP phase is divided into Request body and Response phases. After the server sends the Response, it enters the Idle phase and waits for the next HTTP request for the current connection.
The above is the main process of handling HTTP requests by http. Let’s go back to the timeout configuration and TimeoutHandler mentioned earlier.
ReadTimeout controls the timeout from Wait to Reqeust body. If we set ReadTimeout to 50ms, then the client must send both the header and the body of the request to the server within 50 milliseconds, otherwise it will time out and the server will cancel the whole process. On the other hand, the header part of the HTTP request is split by \r\n and the end of the header part (the beginning of the body part) is indicated by a blank line \r\n\r\n. The server cannot determine the length of the header data in advance, but parses it as it receives it. This protocol is very convenient for subsequent upgrades and extensions, but it makes the server very passive. Therefore, it is necessary to set a separate timeout for this process. This timeout is controlled by ReadHeaderTimeout. If we set the ReaderHeaderTimeout to 10ms, then the client must send the entire header within 10ms and cannot dawdle. If ReadTimeout is set and ReadHeaderTimout is not set, http.Server will set ReadHeaderTimeout with the value of ReadTimeout.
The server also needs to control the timeout for sending Response to the client. Why? If the client’s request is processed, but it doesn’t receive the Response or is deliberately slow, it will keep taking up server resources. So it is necessary to “punish” those slow and unsuspecting clients. If WriteTimeout is set to 50ms, then the client must receive all response data within 50ms or the whole process will be cancelled. One thing to note is that the WriteTimeout time includes the time to read the body. This means that the ReadTimeout and WriteTimeout timeouts overlap in the body reading part.
IdleTimeout controls the wait time of the Idle phase. If no new request is received for a long time after a request, the server will actively close the current TCP connection, thus freeing up resources.
Finally, there is the TimeoutHandler, which is also very easy to use.
This turns a normal handler into a handler with timeout control. timeoutHandler controls both the Reqeust body and the Response process, the ServeHTTP process. If the whole process takes longer than the specified time (1 second in the above example), http.
Well, so far on the basics of timeout control is introduced, the following began to analyze the specific problems.
When I wrote the framework when I thought so many Timeout configuration is too complex, and TimeoutHandler seems to be able to play a “one man, no one can open” effect, and decided to use only TimeoutHandler to control the timeout. Server default is not to timeout, that is, wait for you to the end of the world. This sets the stage for problems later.
The service we deployed on AWS was reporting partial Unexpected EOF errors, and after troubleshooting, we found that the client was behaving abnormally. The corresponding client specified the length of the body via the Content-Length header, but never sent the body data. The expected result is that the TimeoutHandler timeout is triggered and a 503 status code is sent to the client. But in reality, our service reports a Unexpected EOF error after the client actively closes the connection.
This is not at all what was expected and must be checked to the end! This scenario is very easy to reproduce, so it is relatively easy to troubleshoot. Just run the following code.
The following HTTP request can be replicated using telnet emulation.
Note that ⚠️ the length of Content-Length in the request is 6, but only he two bytes are actually sent.
At first I suspected that 🤔 TimeoutHandler might have to wait to read all the body data to work, so I looked at its source code.
|
|
That is, the entire ServeHTTP process is controlled. And we are actually reading the req. Theoretically, TimeoutHandler should work. So we turned on the print method and inserted the Print statement directly into the TimeoutHandler source code to see if it was executed or not, and eventually found that it was stuck in the select process afterwards. That is, the <-ctx.Done() case, which corresponds to the source code as follows
In case you can’t believe it, it’s stuck in the Write step, which I really didn’t expect!
Now it’s time to look at why it’s stuck. w’s is a ResponseWriter interface, and we need to find its concrete implementation. Here is the core flow of the serve method of http.
We can see that w is constructed by calling c.readRequest(ctx). Based on the readRequest interface signature, we know that the actual type of w is http.response. Looking further at the Write method of w, we see that it calls the Write method of w.w at the bottom. w.w is a member of http.response, which is of type *bufio.Writer interface, so we had to find out exactly what it implements. Going back to the previous c.readRequest method, at the end of the function there is this line.
|
|
It turns out that this w.w is built out of w.cw. We then look at the type of cw, which is http.chunkWriter, and eventually find the cw.Write function, which is the c.Write function that we got stuck on earlier, with the relevant code as follows.
I got stuck in the cw.writeHeader(p) place. The writeHeader function is very complicated, and after some debugging, I finally found this place.
The root of the problem is bdy.mu.Lock() here! It turns out that http.Server needs to lock the body object of the request when sending a response. What’s the point of this? There is a comment on this conditional branch.
Simply put, you need to read the body content of all responses before sending the response. The whole process is stuck in bdy.mu.Lock() step, there must be a goroutine that has got the lock and is doing something, so the lock is not released. Checking the place where the lock is used, I immediately found here.
Read here is the method we call when the specific handler calls io.ReadAll(req.Body). It first locks b.mu.Lock() and releases it when it has finished reading all the requests. Let’s look at b.readLocked(p) here.
The Read method of b.src is actually called here. b.src is another io.Reader interface, and again we have to find its concrete implementation. This is a bit trickier to find. The final call chain we found was c.ReadRequest -> http.readRequest -> http.readTransfer. This readTransfer is again quite complex, and the relevant flow is as follows.
|
|
The first step is to determine the length of the body via fixLength. In our problem, the body length is obtained by Content-Length and then hitting the realLength > 0 branch. So b.src is actually an io.LimitReader. This Reader blocks until it has read the full length of realLength before returning.
This is where we get to the root of the problem. It turns out that the client sent the Content-Length header, but not the corresponding length of body content, so the business code locks bdy.mu while trying to read all the body content, and waits for the client to send the remaining body content. The TimeoutHandler tries to send a 503 response to the client, but it also needs to lock the body, so it is also stuck. The whole process continues until the client takes the initiative to disconnect, at which point the server triggers a Unexpected EOF error. The effect seems to be a server-side “deadlock”.
This is the end of the whole troubleshooting process. The following is a technical summary.
- http.Server never times out by default, so there is a possibility of DDos attacks
- Setting only TimeoutHandler cannot handle all timeout scenarios
- ReadTimeout and WriteTimeout must be set, and ReadHeaderTimeout can be set when necessary
Server makes extensive use of interfaces, which makes reading the code extremely inconvenient. The best way is to single-step debugging. I have been using vim development, not very friendly to single-step debugging, and rarely used. I tried dlv later, and it really saved a lot of time.
Now, let’s make up the extras!
In the http.server method there is this paragraph.
The literal meaning is to execute w.conn.r.startBackgroundRead when the body is finished reading. The corresponding execution code looks like this.
Take a closer look at the startBackgroundRead function.
A new goroutine is started. That means that for every http request, at least two goroutine are started. And this backgroundRead function is also strange in that it tries to read one byte from the underlying TCP connection and will keep blocking without being controlled by all the previous timeouts. The more I look at this logic, the stranger it gets 🤔 I have to figure it out.
I looked at the code over and over again and couldn’t get the hang of it, so I did the git blame thing. I also downloaded the go source code for this, and finally found this CL.
|
|
The intent is to cancel the current handler process when the underlying TCP connection is closed (i.e., when the client actively closes the connection). It is generally easiest to use event callbacks to handle this. However, Go is a concurrent blocking programming paradigm, and does not expose the ability of event callbacks to the application layer. So you can only start a goroutine to try to read a little bit of content (not zero, then read a byte). Theoretically it will keep blocking until the current request is processed or the client actively disconnects. But for this feature, you have to start a goroutine, which is a flaw of the Go language.
In addition, the HTTP protocol provides the pipeline feature. The client can send multiple http requests to the server at once without waiting for the server to respond. Then the server sends the corresponding responses in order. Server to detect the client’s active disconnection and start a new concatenation, if it encounters a client that supports pipeline, it will really receive a byte of content, so it also needs to save this one byte for subsequent processing. In short, this approach is not very elegant. But it’s the only viable solution in the Go language. What does everyone think? 😄