Since golang does not have a uniform coding pattern like java, we, like the rest of the team, used some of the theory presented in the article Go Package Oriented Design and Architecture Layering and then combined it with our previous project experience to define the packge.
|
|
In fact, this division above is only a simple division of functions into packages, there are still many problems in the process of project practice. For example.
For the function implementation do I pass it through the parameters of a function or through the variables of a structure?
Is it safe to use a reference to a database global variable? Is there excessive coupling?
Almost all of the code implementation is implementation dependent rather than interface dependent, so does switching from MySQL to MongDB require all the implementation changes?
So now as we work with more and more code, the code feels more and more chaotic with all the init, function, struct and global variables.
Each module is not independent, it seems to be divided into modules according to logic, but there is no clear relationship between the upper and lower levels, each module may have configuration reading, external service calls, protocol conversion, etc..
Over time, the calls between the different package functions of the service slowly evolve into a mesh structure, and the flow of data and logic becomes more and more complex to sort out, making it difficult to figure out the flow of data without looking at the code calls.
But as it says in Refactoring: first make the code work - if it doesn’t work, it can’t produce value; then try to make it better - by refactoring the code so that we ourselves and others understand it better and can keep modifying it as needed.
So I think it’s time for some self-change.
The Clean Architecture
The Clean Architecture sets out a number of requirements for our projects.
- Independence from the framework. The architecture is not dependent on the existence of certain feature-rich software libraries. This allows you to use these frameworks as tools, rather than cramming your system into their limited constraints.
- Testable. Business rules can be tested without a UI, database, web server or any other external elements.
- Independent of the user interface. the UI can be easily changed without having to alter the rest of the system. For example, a Web UI can be replaced with a console UI without changing the business rules.
- Database independent. You can swap out Oracle or SQL Server for Mongo, BigTable, CouchDB or something else. Your business rules are not bound by the database.
- Independence from any external bodies. In fact, your business rules don’t know anything about the outside world at all.
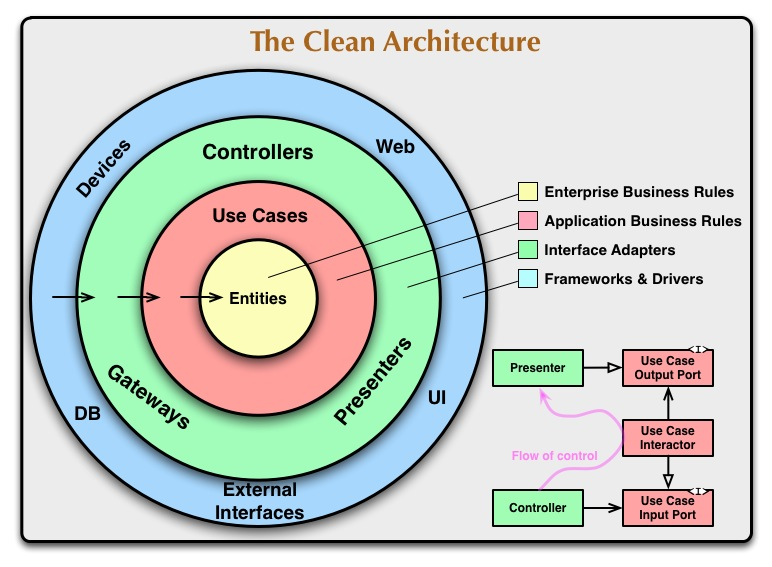
The concentric circles in the diagram above represent a variety of different areas of software. Generally speaking, the deeper you go the higher the level of software you have. The outer circles are the tactical implementation mechanisms and the inner circles are the strategic core strategy.
For our projects, code dependencies should be outward to inward, one-way single-level dependencies that contain code names, or functions of classes, variables or any other named software entities.
For a clean architecture there are four layers.
- Entities: Entities
- Usecase: expresses the application business rules, corresponding to the application layer, which encapsulates and implements all the use cases of the system.
- Interface Adapters: the software in this layer is basically adapters that are used to convert the data in use cases and entities into data for use in external systems such as databases or the Web.
- Framework & Driver: the outermost circle is usually made up of frameworks and tools such as Database, Web Framework, etc.
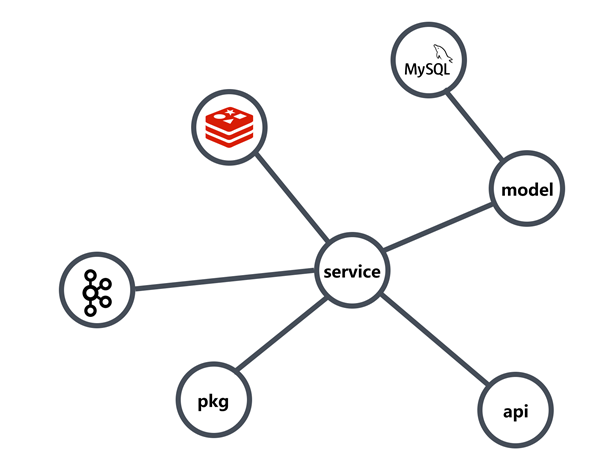
For my project, then, it is also divided into four layers.
- models
- repo
- service
- api
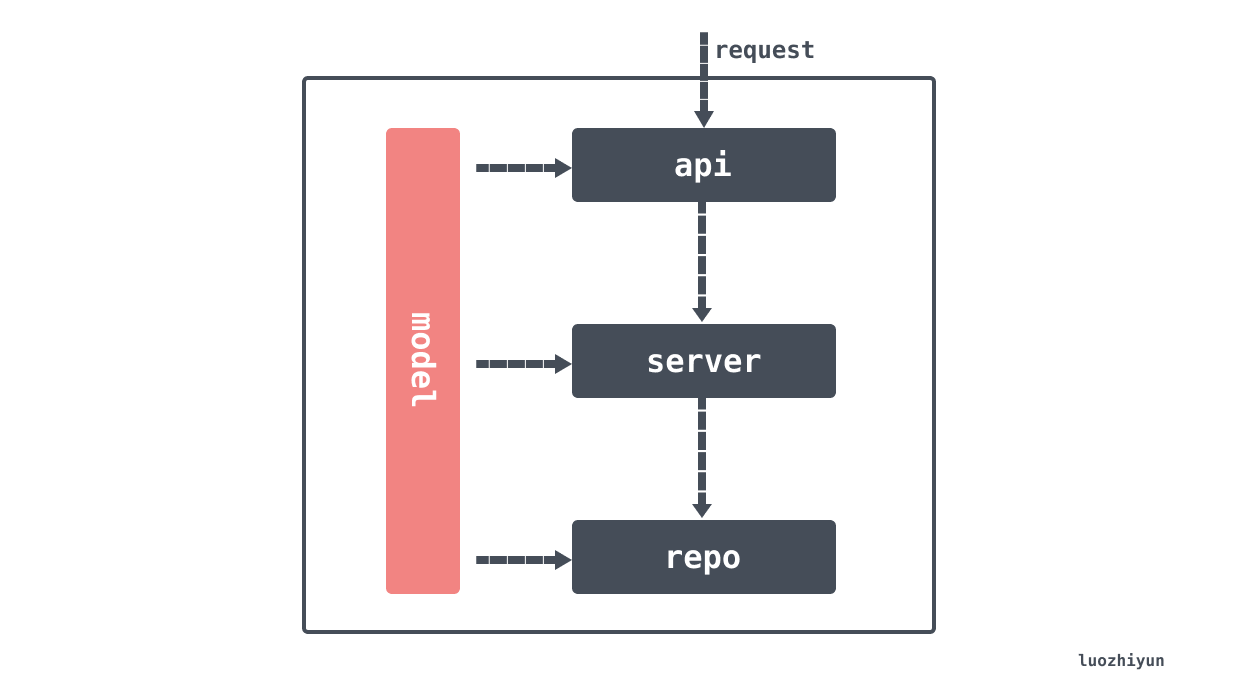
models
Encapsulates various entity class objects, those that interact with the database, those that interact with the UI, etc. Any entity class should be placed here. For example.
repo
This is where the database operation classes are stored, the database CRUD is all here. It is important to note that this does not contain any business logic code, as many people like to put business logic here as well.
If you are using ORM, then this is where you would put the code for ORM operations; if you are using microservices, then this is where you would put the code for other service requests.
service
This is the business logic layer, where all the business process code should be placed. This layer will determine what code is requested from the repo layer, whether to manipulate the database or to call other services; all business data calculations should also be placed here; the input accepted here should be that passed in by the controller.
api
This is the code that receives external requests, e.g. gin’s corresponding handler, gRPC, other REST API framework access layers, etc.
Interface-oriented programming
Except for the models layer, layers should interact with each other via interfaces, not implementations. If you want to call the repo layer with a service, then you should call the repo’s interface. Then when modifying the underlying implementation our base class in the upper layer does not need to be changed, we just need to replace the underlying implementation.
For example, if we want to look up all the articles, we can provide this interface in the repo.
The implementation class of this interface can be changed according to the requirements, for example when we want mysql to be used as a stored query, then we just need to provide a base class like this.
|
|
If we want to switch to MongoDB to implement our storage, we can simply define a structure to implement the IArticleRepo interface.
Then we can inject the corresponding repo implementation into the service level implementation as we need it, without changing the service level implementation.
|
|
Dependency Injection DI
Dependency injection, or DI for short, used to be common in java projects, but many people in go say it’s not needed, but I think it’s still necessary in large software development, otherwise it can only be passed through global variables or method parameters.
As for what DI is, it is simply a dependent module that is injected into (i.e. passed as an argument to) a module when it is created. For a more in-depth understanding of what DI is, here are some more recommendations Dependency injection and Inversion of Control Containers and the Dependency Injection pattern.
There are two main inconveniences if you don’t use DI. One is that modifications to the underlying classes require modifications to the upper classes, and in large software development processes there are many base classes, so a single link can easily require dozens of files to be modified.
Because of the use of dependency injection, it is inevitable that a large number of new will be written during the initialisation process, for example, in our project we need this.
|
|
So for such a piece of code, is there any way we don’t have to write it ourselves? Here we can use the power of frameworks to generate our injection code.
In go DI tools are not as convenient as in java, and the main technical frameworks are: wire, dig, fx, etc. Since wire uses code generation for injection, the performance is higher and it is a DI framework introduced by google, so we use wire for injection here.
The requirements for wire are simple, create a new wire.go file (the name of the file is optional) and create our initialisation functions. For example, if we want to create and initialise a server object, we can do so.
|
|
Note that the annotation in the first line: +build wireinject, indicates that this is an injector.
In the function, we call wire.Build() to pass in the constructor for the type on which the Server is created. Executing the wire command after writing the wire.go file will automatically generate a wire_gen.go file.
|
|
You can see that wire automatically generates the InitServer method for us, which initialises all the base classes in turn. After that, we can just call this InitServer in our main function.
Testing
Having defined what each layer should do above, we should be able to test each layer individually, even if another layer does not exist.
- models layer: for this layer it’s very simple, as it doesn’t depend on any other code, so it can be tested directly with go’s single test framework.
- repo layer: for this layer, since we use a mysql database, we need to mock mysql so that we can test it even without connecting to mysql.
- service layer: since the service layer depends on the repo layer, and since they are related through an interface, I use github.com/golang/mock/gomock to mock the repo layer.
- The api layer: this layer depends on the service layer and is related through an interface, so you can also use gomock to mock the service layer. However, this is a little trickier because we are using gin for the access layer, so we need to simulate sending requests in a single test.
As we are mocking through github.com/golang/mock/gomock, we need to perform a bit of code generation and put the generated mock code into the mock package as follows
These two commands will automatically generate the mock function for me through the interface.
repo layer testing
In the project, since we are using gorm as our orm library, we need to use github.com/DATA-DOG/go-sqlmock in conjunction with gorm to do the mock.
|
|
service layer testing
The main thing here is to use our gomock-generated code to mock the repo layer.
|
|
api layer testing
For this layer, we not only mock the service layer, but also send httptest to simulate the request being sent.
|
|
Summary
The above is a little summary of the problems I found in the golang project, and I don’t care if it’s right, it’s a solution to some of our current problems. However, the project will always need to be refactored, so if there are problems next time, we can change them next time.