Intro
Opening a Kotlin Coroutine requires calling the launch or async methods on the CoroutineScope. These extension methods defined on the CoroutineScope are called coroutine builder.
In addition to the suspend block, additional parameters can be passed to the coroutine builder. For example, the above Dispatchers.IO specifies that the Coroutine block of launch is dispatched to the IO thread pool for execution. Signature of launch.
You can see that opening a Kotlin Coroutine involves at least three concepts: CoroutineScope, CoroutineContext and Job. Scope and Context seem to have very similar meanings when taken literally. In addition, Coroutine’s Scope contains only one property, CoroutineContext.
Why does Kotlin’s Coroutine need a concept of Scope? Can we reduce the complexity of the API by eliminating the Scope and leaving only the Context? It seems that everyone has been confused about this (e.g. discussion here). Elizarov also has a dedicated article about it. This paper will document the author’s understanding.
Context is used to configure the properties of the Coroutine
Context is a specially customized data structure
Context is like a collection (Set) : This collection consists of Element of different types. Elements can be added via the operator overloaded add, or overwritten if an element of an already existing type is added.
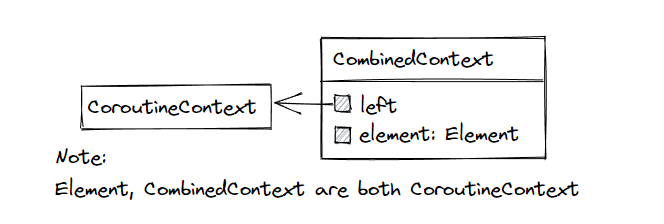
The type returned when the two Contexts are “+” together is CombinedContext. Since the collection itself and the elements inside CoroutineContext.Element are both CoroutineContext, we can pass either a single element or a combined Context when calling a function like launch that receives a Context, without the need to add an extra listOf, or use vararg, which is very simple and elegant.
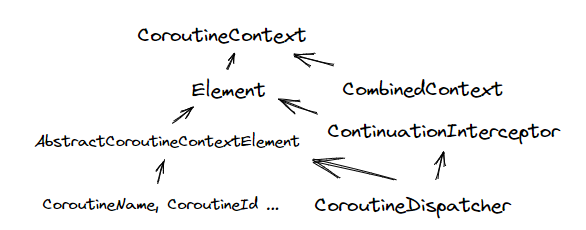
Context is immutable . Adding or removing elements to or from a Context returns a new Context object. This property is needed for Coroutine concurrency scenarios.
Context is also like a Map: each type of Element has a corresponding CoroutineContext.Key, which can be used to safely access the corresponding type of Element.
The CoroutineName used to get the element in the sample code is actually a companion object of the class CoroutineName. It is also more concise and elegant than using CoroutineName::class as the Key of the dictionary.
The nature of Context collections and dictionaries ensures the uniqueness of each type of Element in the collection CombinedContext.
Although Context is used like a dictionary and a collection, its implementation is a LikedList.
Since each type of Element in Context is unique and the number of Element types is defined inside the Kotlin Coroutine library (kotlinx.coroutines) is fixed, there is an upper bound on the time complexity of chaining table operations. Implementing Context using a custom linked table avoids some additional overhead compared to using an off-the-shelf data structure and makes sense for a framework implementation.
Get Context anywhere in the Coroutine call chain
Context is generally used to store certain state that is global in nature. For example, React.js describes the shape of a component tree through a declarative API. Sometimes it can be tricky to pass some data across component layers. If this data is global in nature (e.g., the theme of a page), React’s Context API allows us to pass values deep into the component tree without explicitly passing through each component.
|
|
A block of code that can be executed as a whole can be called a “subroutine routine”, such as a function, method, lambda, conditional block, loop block, etc. A Kotlin Coroutine is a block of code that can be suspended. For the purpose of abstraction and reuse, we extracted a part of the code containing asynchrony and wrapped it into a suspend function.
Function calls are also similar to UI components and can be seen as a tree structure. In Kotlin’s suspend function, we can get the Context (Context propagation) at any level of the call chain.
|
|
This coroutineContext is added by Kotlin at compile time and can be seen as the compiler passing the caller’s Context implicitly to the calling suspend function. In the article “Understanding Kotlin’s suspend function”], we described that the essence of suspend is Continuation. In addition to the resumeWith method that corresponds to the callback, the other property of Continuation is the CoroutineContext.
The coroutineContext in the suspend function is the same as the caller’s Context without updating the Context via withContext. It is useful to understand that it is conceivable to inline the calling suspend function into this suspend block and the behavior of the program does not change. The following example checks that the Context of the caller, the suspend function’s internals, and the Continuation are all the same.
|
|
So is the Context mechanism provided by Kotlin just to facilitate passing some global state?
A core element: the ContinuationInterceptor
We know that Context is for Coroutine. A Coroutine is when a programming language “collaboratively” dispatches subroutines to threads for execution at runtime.
The ContinuationInterceptor element provides the infrastructure for Coroutine scheduling. The familiar CoroutineDispatcher, such as Dispatchers.IO, which specifies the threads to execute Coroutines, is the ContinuationInterceptor.
|
|
CoroutineScope and ‘structured concurrency’
A major milestone was reached on September 12, 2018 with the release of version 0.26.0 of the Coroutine library kotlinx.coroutines. Prior to this coroutine builders were global top-level functions that did not require a CoroutineScope to enable Coroutine, such as async in the example below.
Trouble with global top-level coroutine builder
What are the problems with such a design? Let’s look at a few simple examples.
Example: Passing a file stream to a process function for processing
As a result, the exception java.io.IOException : Stream closed is thrown when it runs, and we open the function process to see.
It turns out that use in the Kotlin standard library closes the file stream (encapsulating finally) after the accepted lambda has finished executing. Since the asynchronous task opened by the process function is still executing after it returns, but the file is closed, an exception is thrown.
Example: Suppose we call a writeData function to write some data to storage, and this function opens a Coroutine that is scheduled to execute in the IO thread with launch(Dispatchers.IO).
After writeData returns, has the data been written? We can’t be sure. The Coroutine inside writeData that launches can even throw an exception, but as the caller we can’t catch this exception (we can’t catch the exception thrown inside the Coroutine opened by writeData by try catching outside writeData).
Example: Android’s Activity
Suppose someNetworkRequest becomes slow due to network problems, and the user may get impatient and close the page. Since the Coroutine block of launch refers to the properties of the Activity, this Coroutine will leak together with the whole Activity.
Analyzing the above examples, we can see that the problem is that we have opened the Coroutine and then abandoned it, not canceling it in time or not join to wait for the result of the Coroutine. In fact, not only Kotlin’s GlobalScope, but almost all asynchronous APIs (thread, promise, callback, goroutine, etc.) allow us to enable asynchronous tasks without lifecycle qualification. When the function that started the asynchronous task returns, the asynchronous task may not have finished yet and continue to execute in the background. The caller has no way of knowing when the asynchronous task has finished and whether an exception has been thrown.
You may have experienced that when using some APIs, you have to manually delay the execution of the logic for a few seconds, otherwise strange problems will occur. Maybe the API forgot to join a thread.
Structured Concurrency
So it seems like a better choice for asynchronous APIs to make join wait for asynchronous tasks to complete the default behavior - that’s the core idea of Structured Concurrency.
Nathaniel J. Smith, author of Trio, an asynchronous concurrency library for Python, published a blog post in 2018 Notes on structured concurrency, or: Go statement considered harmful, which is a thorough exposition of Structured Concurrency, and is worth a read. Coroutine’s GlobalScope.launch. It is argued that the existing asynchronous API, typified by the go keyword, is akin to the goto statement that Dijkstra argued against half a century ago.
In his famous article Go To Statement Considered Harmful (1968), Dijkstra pointed out that people are better at grasping the static relationships between things static relationships, whereas when a program is running, the flow of state of the process is a very dynamic process. Therefore, it is difficult to draw a complete picture in one’s mind of how the state of a program changes while it is running. Programming languages should be designed to shorten the difference between the code text and the runtime program as much as possible, so that the programmer can look at a line of code and deduce the state of the program.
The goto statement, which was very popular at the time, allowed the process to jump to any position in the corresponding code text. This way we can only simulate the execution of the program in our minds from the beginning, and it is difficult to infer the running state of the program at the local location of the code, which makes it difficult to guarantee the correctness of the program.
Dijkstra believes that high-level languages should abandon goto statements and promote “Structured Programming” - that is, programmers use conditional, loops, function blocks, and other structural blocks to combine program logic.
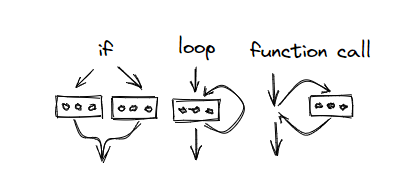
As you can see, the program always goes from top to bottom (sequential) when it passes through these control structures: one entrance, one exit. The middle part of the different control structures is like a “black box”. When we read this piece of code, we can be sure that there is some logic in this block, and when this logic is done, the control flow will eventually come out of one exit and go to the next line of code. And once the programming language supports goto statements, this encapsulation is broken.
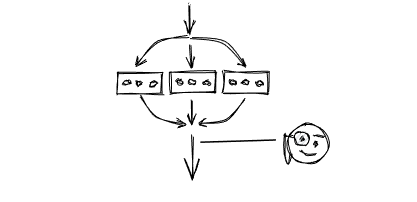
In structured concurrency, all asynchronous tasks are bound inside a scope that is similar to the conditional, loop, and function control bodies in structured programming, and although there may be multiple tasks executing concurrently, they all eventually come out of a single exit, conforming to the nature of a “black box”. Assuming the programmer reads the dotted line shown in the figure, he can be sure that if the code goes here, the three concurrent tasks above must have completed successfully.
More and more languages are absorbing the idea of structured concurrency, such as Java’s Project Loom and [Swift’s Coroutine](https ://forums.swift.org/t/swift-concurrency-roadmap/41611).
Job and cancellation
Before we discuss how Kotlin implements structured concurrency, let’s look at Coroutine’s Cancellation.
First, as you can see from the Android Activity example above, if the user leaves the interface, the Coroutine should support cancellation for the sake of recycling system resources in a timely manner. Also on the server side, if a connection is broken or a key asynchronous task fails, other asynchronous tasks should be stopped in time to avoid unnecessary waste of resources.
The fact that Kotlin’s Coroutine, Java’s threads and Goroutine are all collaborative means that to truly support cancellation, the Coroutine needs to actively check if the current Job is active in between tasks. This is because if a subroutine can be abruptly aborted, there is a high probability that things will go halfway, damaging data structures or file resources, etc.
The Go language implements Coroutine cancellation through channels, and the following example passes a channel named done to all functions in the call chain that contain asynchronous tasks. The caller “notifies” all open Coroutines of the end of the ongoing task by closing the channel. We don’t send data to this channel, we just “broadcast” the side effects of closing it.
|
|
Based on this approach to Coroutine cancellation, the Go standard library provides a Context whose Done method returns such a channel. if you use a Context, all functions in the call chain need to explicitly pass in this Context object and listen to this Done channel inside each function.
If you are used to using ThreadLocal, you may find this explicit passing of values cumbersome (e.g. this introductory Go context Context article under the comments).
In Kotlin Coroutine, we cancel the Coroutine via a Job object passed implicitly in CoroutineContext. The return value of the Coroutine builder launch is a Job object representing the Coroutine, which can be called .cancel to cancel the Coroutine and .join to wait for the Coroutine to finish. Since Job is a CoroutineContext.Element, the Job corresponding to the current Coroutine can be obtained from the coroutineContext property at any point in the suspend function call chain.
|
|
How do we make the Kotlin Coroutine code we write support cancellation? Inside the Coroutine block opened by the coroutine builder, you can use Job.isActive to determine if the current Coroutine is cancelled. If it is cancelled, you can return it directly or throw CancellationException. This exception is different from other exceptions in the Coroutine library and has a special meaning. It is a special flag used to cancel a Coroutine, and after it is thrown, the call stack reverts back to the launch Coroutine and the whole Coroutine ends normally and the exception does not continue to propagate.
|
|
Cancellation is supported inside the wrapped suspend function, return does not work and CancellationException must be thrown. Because after return, the control flow returns to the upper level function normally and may continue to execute the synchronous statements that follow. When the Coroutine is cancelled, the entire call chain should immediately fall back. The Coroutine block of launch, on the other hand, is different from inside the suspend function and is the root node of the Coroutine call tree, so you can just return to end the Coroutine.
If we call a suspend function that supports cancellation, it means that this suspend function will check if the current Coroutine is cancelled and throw a CancellationException. All the suspend functions in kotlinx.coroutines support cancellation. By calling a suspend function that supports cancellation, we automatically support cancellation and need to do very little specialized processing.
Suppose we wrap the code that outputs the fibonacci numbers in the example above into a suspend function, inside which we can use the yield method to ensure that only the Coroutine in the active state will continue to compute.
When wrapping the callback API as a suspend function, you can use suspendCancellableCoroutine to support the cancel operation, as described in Understanding Kotlin’s suspend function for an example.
There are advantages and disadvantages to passing context implicitly like Kotlin and explicitly like Go. Kotlin makes use of the CoroutineContext integrated into the language for cleaner code; at the same time, we can make use of the Coroutine library in the Coroutine call tree At the same time, we can use the yield and suspendCancellableCoroutine functions provided in the Coroutine library to automatically insert a check of the Coroutine state in the gap of the asynchronous task, and back out the whole Coroutine call stack through the exception mechanism to make it more convenient to cancel Coroutine, but there may be some learning cost.
Job and Coroutine parent-child relationship
In the Coroutine call tree, it is possible to open a new Coroutine in addition to calling the suspend function. Coroutine.
Kotlin Coroutine recommended this way of writing before 0.26.0.
The above example will pass the coroutineContext added by the compiler in the suspend function into launch, so that the newly opened Coroutine will run in the external Coroutine Job that executes the suspend function. If the external Job is cancelled, the Coroutine in sayHelloWorldInContext with launch will also be cancelled, which can solve the problem of Coroutine leakage after the Android Activity with lifecycle is finished. But the other problem is not solved, the function to open Coroutine doesn’t wait for the end of asynchronous task, and the asynchronous task may still be executed after returning. So a better way to write it is like this.
In this example, we create a new Job instance inside the suspend function sayHelloWorld, and manually join the Job inside the function, which is a bit cumbersome to write, easy to forget, and not much better than Java’s thread API. The Kotlin veterans may realize that they can encapsulate the internal Job-related logic into a higher-order function that takes a lambda with a Job instance as the receiver, such as
This is very Kotlin, but launch(this) is a bit awkward, and Kotlin veterans might think that if launch is defined on the Receiver of a job block, then we could just launch inside the block, and write it much like the global top-level functions before 0.26.0.
At this point we’ve pretty much reinvented the two pillars of the Kotlin Coroutine library Structured Concurrency - the coroutineScope higher-order function and the CoroutineScope interface. CoroutineScope is similar to the job function we wrote (Kotlin officially considered using this name). And CoroutineScope is the Receiver mentioned earlier.
Structured concurrent design of Kotlin Coroutine
Kotlin 0.26.0 deprecated all global top-level functions coroutine builder in favor of extended methods on CoroutineScope. This makes it mandatory to have a CoroutineScope to open a Coroutine. Dijkstra’s point is not just that control bodies such as conditions, loops, and functions are recommended, but that goto’s should be deprecated in programming languages, because as long as they exist, every function can have a goto inside, breaking the “black box” nature and breaking encapsulation. Similarly, structured concurrency argues for deprecating the “unstructured”, fire-and-forget asynchronous API. The introduction of CoroutineScope has made structured concurrency the default behavior in the Kotlin Coroutine API.
According to current best practices, if you need to open a new Coroutine in the suspend function, you need to first open a new block with the help of coroutineScope, which contains a new Job and limits the lifecycle of all Coroutines opened in it: if the code runs behind the coroutineScope block, it means that all asynchronous jobs inside this block have been successfully terminated; if any of the Coroutines in coroutineScope throws an exception, the call stack is rolled back and the exception is passed to the outer layer of coroutineScope. In the following example, if any of the loadImages fails to throw an exception, the exception is passed to the caller of loadAndCombineImage.
|
|
The top-level Coroutine is the “end of the world” and generally needs to be integrated with a framework component that has a lifecycle, configured with a CoroutineScope. Example.
In this example, the Context, Scope and Job parts of the Kotlin Coroutine are elegantly stitched together: we have the system component with the lifecycle implement CoroutineScope, which requires override coroutineContext, where we configure all the default properties of the Coroutine opened in this We need to override CoroutineContext, where we configure the default properties of all the Coroutines opened in this scope. Since MyActivity “is” a CoroutineScope, you can omit this when opening the Coroutine, and the API calls look like global top-level functions, but with lifecycle constraints.
However, the familiar androidx provides Scope through the LifecycleOwner.lifecycleScope extension property. Android community. Using the above manual integration approach requires a base class like BaseActivity in the project, and requires the developer to understand the concepts of Context, Scope, and Job, which is a bit more expensive to learn.
For unstructured, traditional fire-and-forget concurrency, Kotlin provides the GlobalScope that was used as an example earlier. Reading this, I believe you can imagine the implementation of GlobalScope as follows.
The use of GlobalScope in applications is generally not recommended. Based on the idea of structured concurrency, GlobalScope may eventually be deprecated in the long run. Some “backend” asynchronous tasks may consider defining CoroutineScope on components with a longer lifecycle, such as Android’s Application and Spring’s singleton scope components. A more convenient approach could be.
|
|
Reference your own defined appScope in your business logic code to facilitate configuration of the Coroutine in a single location.
Two conventions of ## Kotlin Coroutine
How Kotlin structured concurrency solves “the trouble caused by the global top-level coroutine builder function” under this heading? As an example of a problem dealing with file streams.
To turn on Coroutine you must have CoroutineScope. We can pass this CoroutineScope explicitly into the wrapped function, or we can define it as an extension method of CoroutineScope like the coroutine builder. The difference is only formal, but the substance is the same, but the latter seems to be more in line with the Kotlin style.
Using structured concurrency, wrapping a coroutineScope block around process allows the caller to control the lifecycle of the Coroutine opened within the called function. We can be sure that the end of the coroutineScope block means that all the asynchronous tasks started by process have been successfully completed.
In addition to the extended functions on CoroutineScope, the mechanism for reusing the Kotlin Coroutine abstraction is described in the sister article “Understanding Kotlin’s suspend function”. There are important differences between the two.
- The extension function defined on
CoroutineScopeprovides the convention that this function returns immediately, but the function opens an asynchronous task, which can be interpreted as concurrent execution of the subroutine inside this function and the caller’s code. - The suspend function provides the convention that calling the function will not block the thread, but the function will return when the subroutine inside the function is finished and control flows back to the caller. suspend should not have the side effect of opening an asynchronous task.
Suspend functions are sequential by default. Concurrency is hard, and its launch must be explicit.
Roman Elizarov, Project Lead for Kotlin
As you can see, Kotlin makes a distinction between these two different properties of functions in the type system.
理解和遵循这两个约定是用好 Kotlin Coroutine的关键。