Memory cgroup leaks are a common problem in K8s (Kubernetes) clusters, resulting in nodes being stretched for memory resources, or nodes becoming unresponsive and having to restart the server to recover. Most developers use regular drop cache or disable kernel kmem accounting to circumvent this problem. This paper analyses the root cause of memory cgroup leaks and provides a solution to fix the problem at the kernel level, based on a practical example from the NetEase Digital Sail kernel team.
Background
The O&M monitoring found that some cloud host computing nodes and K8s (Kubernetes) nodes were experiencing abnormally high load, specifically the system was running very stuck, load was constantly at 40+, some of the kworker threads had high cpu usage or were in D status, which had affected the business and needed to be analyzed for specific reasons.

Problem location
Phenomenon analysis
perf is an essential tool for cpu usage anomalies. Looking at hotspot functions via perf top, we find that the kernel function cache_reap has intermittent high usage.
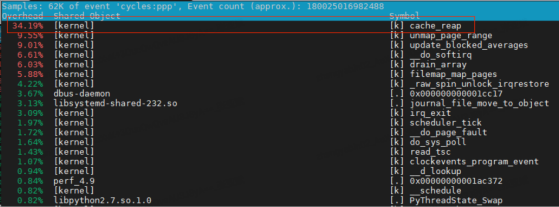
Looking at the corresponding kernel code, the cache_reap function is implemented as follows
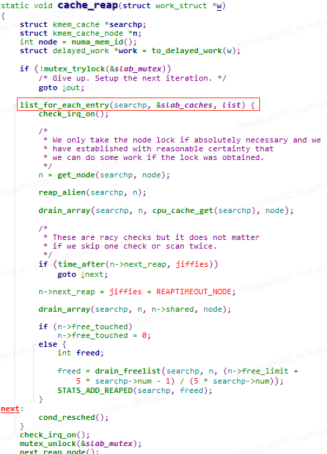
It is easy to see that this function iterates through a global chain of slab_caches, which records information about all slab memory objects on the system.
Analysis of the code flow associated with the slab_caches variable shows that each memory cgroup corresponds to a memory.kmem.slabinfo file.
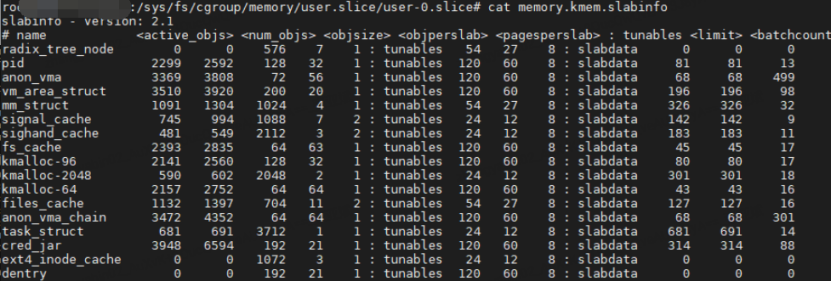
This file records information about the slabs requested by each memory cgroup group, and the slab objects of that memory cgroup are also added to the global slab_caches chain, could it be that there are too many slab_caches chains, which causes a long traversal time, and thus a high CPU charge?
If there are too many slab_caches chains, then the number of memory cgroups must be very large, so naturally we have to count how many memory cgroups exist on the system. Each memory cgroup contains at most a few dozen records in the memory.kmem.slabinfo file, so the number of members of the slab_caches chain does not exceed 10,000 at most, so there is no problem at all.

In the end, we started with the original function, cache_reap, and since this function consumes more CPU, we traced it directly to analyse what was taking longer to execute in the code.
Identifying the root cause
Tracing the cache_reap function through a series of tools shows that the number of slab_caches chain table members is in the millions, a number that differs significantly from the number we actually calculated.
The number of memory cgroups had already accumulated to 20w+ when we checked the current cgroup information by cat /proc/cgroup. This number of cgroups on a cloud host compute node is clearly not normal, and even on a K8s (Kubernetes) node, this number of cgroups is not likely to be generated by the container business.
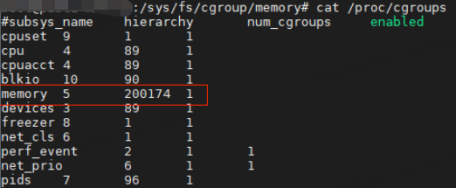
So why is there such a big difference between the number of memory cgroups counted in the /sys/fs/cgroup/memory directory and the number recorded in the /proc/cgroups file? Because of a memory cgroup leak!
For a detailed explanation, see the following.
Many operations on the system (e.g. creating and destroying containers/cloud hosts, logging into hosts, cron timed tasks, etc.) trigger the creation of temporary memory cgroups. When a process in a memory cgroup exits, the cgroup’s directory in the /sys/fs/cgroup/memory directory will be deleted. However, the cache memory generated by the memory cgroup is not actively reclaimed, and the memory cgroup objects in memory are not deleted because there is cache memory still referencing the memory cgroup objects.
In the process of locating the memory cgroup, we found that the cumulative number of memory cgroups per day was still growing slowly, so we tracked the creation and deletion of the node’s memory cgroup directory and found that the following two main triggers could cause memory cgroup leaks.
- the execution of specific cron timed tasks
- frequent user logins and logouts from the node
Both of these triggers are related to the systemd-logind login service, which causes memory cgroup leaks. The systemd-logind service creates a temporary memory cgroup when a cron task is executed or when a user logs out of the host, and deletes the temporary memory cgroup when the cron task is executed or when the user logs out.
This can lead to memory cgroup leaks in the event of file operations.
Reproducing the problem
Once the trigger scenario for a memory cgroup leak has been analyzed, it is much easier to reproduce the problem.

The core recovery logic is to create a temporary memory cgroup, perform file operations to generate cache memory, and then delete the temporary memory cgroup directory. By doing this, the 40w memory cgroup residue was quickly reproduced in the test environment.
Solution
By analyzing the memory cgroup leak, we have basically figured out the root cause of the problem and the trigger scenario, so how do we solve the leak problem?
Option 1: drop cache
Since cgroup leaks are caused by unrecoverable cache memory, the most straightforward solution is to clean up the system cache with “echo 3 > /proc/sys/vm/drop_caches”.
However, this will only alleviate the problem and will still result in cgroup leaks. On the one hand, you need to configure a daily task to drop cache, and on the other hand, the drop cache action itself will consume a lot of cpu, which will affect the business. For nodes that already have a lot of cgroup leaks, the drop cache action may get stuck in the process of cleaning up the cache, causing new problems.
Option 2: nokmem
The kernel provides the cgroup.memory = nokmem parameter to disable the kmem accounting function. After configuring this parameter, the memory cgroup will not have a separate slabinfo file, so that even if there is a memory cgroup leak, it will not cause the kworker thread to have a high CPU.
However, this solution requires a reboot to take effect, which will have some impact on the business. Moreover, this solution cannot completely solve the fundamental problem of memory cgroup leakage, but can only alleviate the problem to a certain extent.
Option 3: Eliminate the trigger source
The 2 triggers found in the above analysis that cause cgroup leaks can both be eliminated.
In the first case, we can confirm that the cron task can be disabled by communicating with the corresponding business module.
In the second case, you can use loginctl enable-linger username to set the corresponding user as a resident user in the background.
Once set as a resident user, the systemd-logind service will create a permanent memory cgroup for the user when he logs in, and the user can reuse this memory cgroup every time he logs in. It will not be deleted when the user logs out, so there will be no leaks.
At this point, it looks like the memory cgroup leak has been solved perfectly, but in fact the above solution only covers the 2 known trigger scenarios, and does not solve the problem of cgroup resources not being completely cleaned up and recycled, and new memory cgroup leak trigger scenarios may occur in the future.
Solutions in the kernel
General solutions
In the process of locating the problem, Google has identified many container scenarios where cgroup leaks have been reported in the centos7 series and 4.x kernels, mainly due to imperfect kernel support for the cgroup kernel memory accounting feature, when K8s( Kubernetes)/RunC has a memory cgroup leak problem when using this feature.
The main solutions to this problem are the following:
- execute drop cache at regular intervals
- configure nokmem in the kernel to disable the kmem accounting feature
- disable KernelMemoryAccounting in K8s (Kubernetes)
- docker/runc to disable KernelMemoryAccounting
We are considering whether there is a better solution to “completely” solve the cgroup leakage problem at the kernel level?
Kernel recycling threads
After a deeper analysis of the memoy cgroup leak, we see that the core problem is that the cgroup directory created temporarily by systemd-logind is automatically destroyed, but the cache memory and associated slab memory generated by the file reads and writes is not immediately reclaimed, and because of the existence of these memory pages, the cgroup management structure’s reference count cannot be cleared due to the existence of these memory pages. So although the cgroup-mounted directories are deleted, the associated kernel data structures remain in the kernel.
Based on our analysis of the community’s solutions to this problem, and the ideas provided by Ali cloud linux, we implement a simple and straightforward solution.
Run a kernel thread in the kernel to do separate memory reclamation for these residual memory cgroups, releasing the memory pages they hold to the system so that these residual memory cgroups can be reclaimed by the system normally.
This kernel thread has the following characteristics.
- only residual memory cgroups are reclaimed
- the priority of the kernel thread is set to the lowest level
- cond_resched() is active every time a memory cgroup is reclaimed to prevent prolonged cpu usage
The core process of a recycle thread is as follows.
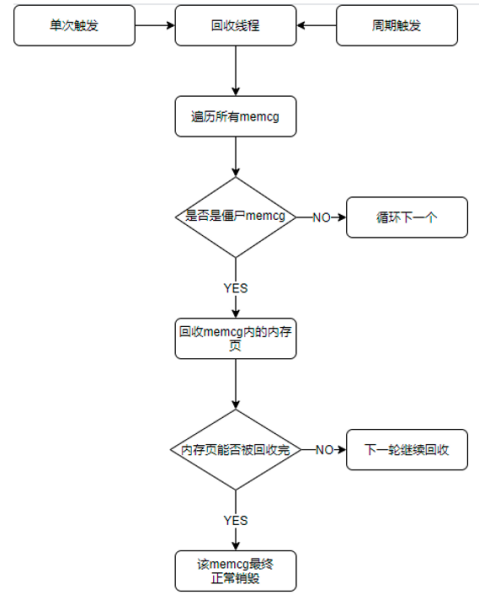
Functional verification
Functional and performance tests were performed on kernels that were merged into the kernel recycling thread, with the following results.
- The system residual memory cgroups can be cleaned up in a timely manner when the recycle thread is opened in the test environment.
- Simulated cleanup of 40w leaked memory cgroups, with the maximum cpu usage of the recovery thread not exceeding 5%, with acceptable resource usage.
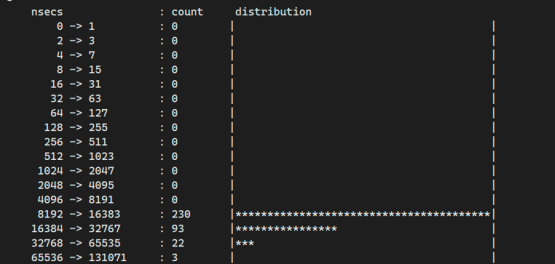
- Tested against a residual memory cgroup of very large size, recovering a memory cgroup holding 20G of memory, the execution time distribution of the core recovery function, basically not exceeding 64us; no impact on other services.
After the kernel recycling thread is enabled, it passes the kernel LTP stability test normally and does not increase the risk of kernel stability.
We can see that by adding a new kernel thread to recycle the residual memory cgroup, we can effectively solve the problem of cgroup leakage with a smaller resource usage. This solution is already in use in NetEase Private Cloud and has effectively improved the stability of NetEase’s container business.
Summary
The above is our analysis of the memory cgroup leak problem, the solution to the problem, and a way of thinking to solve the problem at the kernel level.
In our long-term business practice, we have learned that the use and requirements of the Linux kernel for K8s (Kubernetes)/container scenarios are comprehensive. On the one hand, the whole container technology is mainly built on the capabilities provided by the kernel, so it is essential to improve the stability of the kernel and the ability to locate and fix bugs in the relevant modules; on the other hand, the kernel has a lot of optimisations/new features for the container scenario. We also continue to pay attention to the development of related technologies, such as the use of ebpf to optimize the container network, enhance kernel monitoring capabilities, and the use of cgroup v2/PSI to improve the resource isolation and monitoring capabilities of containers, which are also the main directions to promote the internal implementation of NetEase in the future.