Recently optimized the performance bottleneck of the dynamic form file download interface written by several newcomers, it feels very necessary to summarize an article as a document to throw a brick to promote learning together to write a more professional code.
Simple Download
The simplest case is when a file already exists on the file system on the server, and the client requests a download, the file is read directly in response to.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
import Koa from 'koa';
import Router from 'koa-router';
import * as fs from 'fs/promises';
const app = new Koa();
const router = new Router();
router.get('/download/simple', async (ctx) => {
const file = await fs.readFile(`${__dirname}/1.txt`, 'utf-8');
ctx.set({
'Content-Disposition': `attachment; filename=1.txt`,
});
ctx.body = file;
});
app.use(router.routes());
app.listen(80);
|
Setting the Content-Disposition header to attachment is key and tells the browser that it should download this file.
Streaming Downloads
Simple downloads are not enough when it comes to large files, because Node can’t read large files into the process memory at once. This is solved by using streams.
1
2
3
4
5
6
7
|
router.get('/download/stream', async (ctx) => {
const file = fs.createReadStream(`${__dirname}/1.txt`);
ctx.set({
'Content-Disposition': `attachment; filename=1.txt`,
});
ctx.body = file;
});
|
This example will download without the Content-Disposition header, because the Content-Type is set to application/octet-stream and the browser thinks it is a binary stream file so it is downloaded by default.
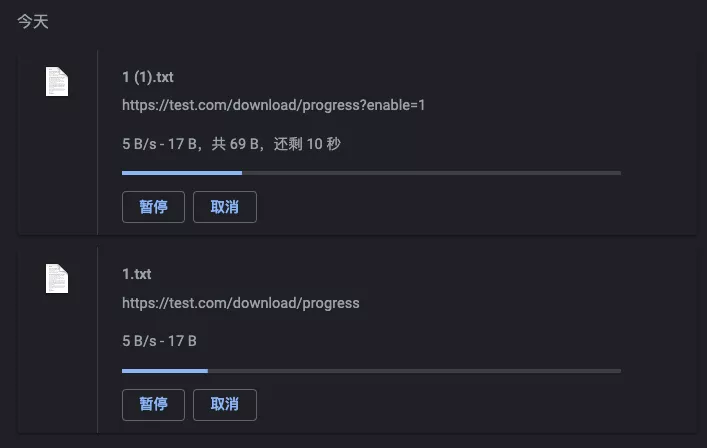
Progress display
When the downloaded file is particularly large, the previous example Content-Length will display the progress properly in the browser download bar when it is set correctly, for convenience we will use the program to simulate this.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
router.get('/download/progress', async (ctx) => {
const { enable } = ctx.query;
const buffer = await fsp.readFile(`${__dirname}/1.txt`);
const stream = new PassThrough();
const l = buffer.length;
const count = 4;
const size = Math.floor(l / count);
const writeQuarter = (i = 0) => {
const start = i * size;
const end = i === count - 1 ? l : (i + 1) * size;
stream.write(buffer.slice(start, end));
if (end === l) {
stream.end();
} else {
setTimeout(() => writeQuarter(i + 1), 3000);
}
};
if (!!enable) {
ctx.set({
'Content-Length': `${l}`,
});
}
ctx.set({
'Content-Type': 'plain/txt',
'Content-Disposition': `attachment; filename=1.txt`,
Connection: 'keep-alive',
});
ctx.body = stream;
writeQuarter();
});
|
Here PassThrough stream is used instead of fs.createReadStream, so Koa no longer knows the file size and type, and divides the file into 4 parts, sending each part 3 seconds apart to simulate a large file download.
When the parameter enable is true, the progress (time remaining) is displayed if Content-Length is set, otherwise it does not display.
Resume from break-point
When downloading a particularly large file, it often fails because the network is unstable and the download is disconnected in the middle, so you can consider supporting intermittent transfer.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
|
function getStartPos(range = '') {
var startPos = 0;
if (typeof range === 'string') {
var matches = /^bytes=([0-9]+)-$/.exec(range);
if (matches) {
startPos = Number(matches[1]);
}
}
return startPos;
}
router.get('/download/partial', async (ctx) => {
const range = ctx.get('range');
const start = getStartPos(range);
const stat = await fsp.stat(`${__dirname}/1.txt`);
const stream = fs.createReadStream(`${__dirname}/1.txt`, {
start,
highWaterMark: Math.ceil((stat.size - start) / 4),
});
stream.on('data', (chunk) => {
console.log(`Readed ${chunk.length} bytes of data.`);
stream.pause();
setTimeout(() => {
stream.resume();
}, 3000);
});
console.log(`Start Pos: ${start}.`);
if (start === 0) {
ctx.status = 200;
ctx.set({
'Accept-Ranges': 'bytes',
'Content-Length': `${stat.size}`,
});
} else {
ctx.status = 206;
ctx.set({
'Content-Range': `bytes ${start}-${stat.size - 1}/${stat.size}`,
});
}
ctx.set({
'Content-Type': 'application/octet-stream',
'Content-Disposition': `attachment; filename=1.txt`,
Connection: 'keep-alive',
});
ctx.body = stream;
});
|
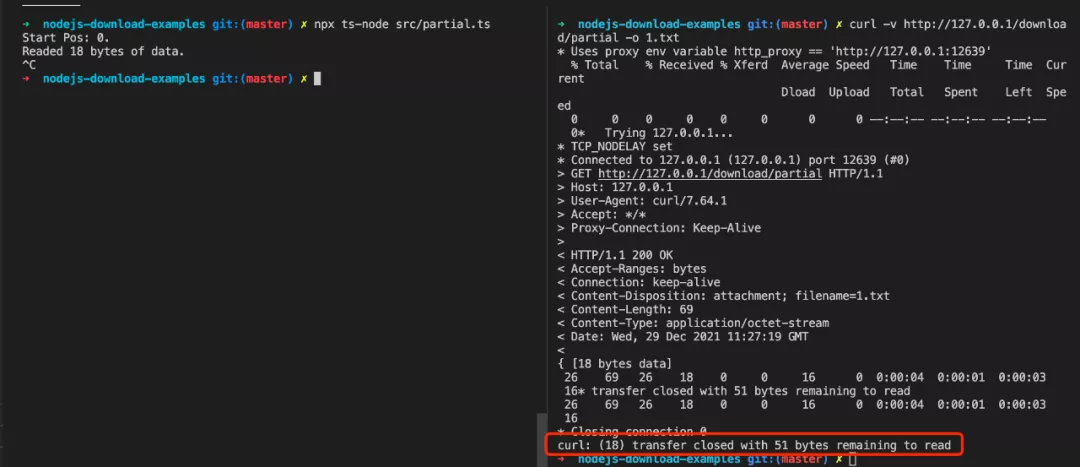
Let’s experiment (Chrome’s default download tool does not support breakpoints).
curl -v http://127.0.0.1/download/partial -o 1.txt
At this point, we take advantage of the transfer gap to stop the service process, and we see that the 1.txt file has only transferred 18 bytes.
We’ll restore the service and resume the download at
curl -v http://127.0.0.1/download/partial -o 1.txt -C -
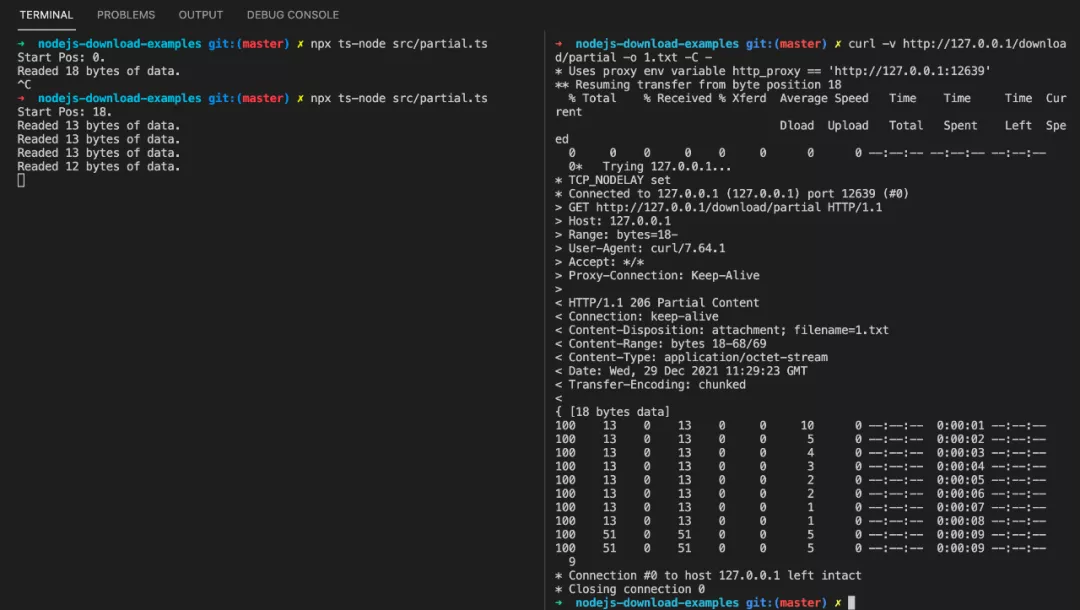
You can see that the rest of the form has been passed in 4 passes.
Dynamic tables
After understanding the basics of the above file download implementation, let’s look at a practical problem: read all the records of a table in the database according to the request parameters and export them to a table.
Bottleneck
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
// Controller.js
const sequelize = new Sequelize(name, user, password, {
dialect: 'mysql',
host,
port,
});
const model = sequelize.import('/path/to/model');
const { rows } = await model.findAndCountAll({
where: conditions,
attributes: ['f_user_id'],
group: 'f_user_id',
});
const list = awaitPromise.all(
rows.map((item) => {
const { f_user_id } = item;
const userRows = await model.findAll({
where: { ...conditions, f_user_id },
// ordering, eager loading, ...
});
// formating userRows -> userData
return userData;
})
);
const headers = ['ID', /*...*/];
const sheetData = [headers, ...list];
ctx.attachment(`${sheetName}.xlsx`);
ctx.body = await exportXlsx(sheetName, sheetData);
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
// xlsx
const ExcelJS = require('exceljs');
const fs = require('fs');
module.exports = {
exportXlsx: async (name = 'sheet', data) => {
const tempFilePath = `./xlsx/${Date.now()}.xlsx`;
const workbook = new ExcelJS.stream.xlsx.WorkbookWriter({
filename: tempFilePath
}); // 创建一个流式写入器
const sheet = workbook.addWorksheet('My Sheet'); // 添加工作表
const { length } = data;
for (let i = 0; i < length; i++) {
sheet.addRow(data[i]);
}
sheet.commit(); // 提交工作表
await workbook.commit(); // 交工作簿,即写入文件
return fs.createReadStream(tempFilePath);
},
};
|
Most people do the requirements at the beginning of the business, considering that the amount of data is not much and the schedule is tight, they implement like the above.
- No consideration of data volume, when the number of database table records exceeds 2w, the memory can’t take it anymore and the Node process quits
- No consideration of memory limit, find a mature
exceljs library, but do not use the stream API it provides
- Data query logic implementation does not consider performance at all, get the ORM library is to call the query, do not consider the number of concurrent SQL queries
Optimization
Segmentation
The simplest strategy is to group several w database data by 1w items each and process them in batches, there are many good open source libraries to use such as async.
Simple code illustration.
1
2
3
4
5
6
7
8
9
10
11
12
13
|
let total = await model.count(/* ... */)
let page = 0;
const tasks = [];
const size = 10000;
while (total > 0) {
tasks.push(() => queryModel({
limit: size,
offset: size * page
}))
page++;
total -= size;
}
await async.series(tasks)
|
Reduce the number of SQL queries
In the source code, it appears that after group by querying out the heavy f_user_id, then query all records of a user concurrently.
Here we should use IN in SQL to check first before matching.
1
2
3
4
5
6
|
model.findAll({
where: {
...conditions,
f_user_id: rows.map(x =>`${x.f_user_id}`)
}
})
|
Stream processing
In the xlsx.js file above, a file is output first and then streamed using fs.createReadStream
The exceljs library provides API to implement stream writing.
1
2
3
4
|
const workbook = new Excel.stream.xlsx.WorkbookWriter(options);
const sheet = workbook.addWorksheet('My Sheet');
// .,,
ctx.body = workbook.stream;
|
more
Of course, in addition to the above-mentioned optimizations, there are also offline generation, caching and many other optimizations available, so I will not expand here.
Summary
File export is one of the most common requirements, and a good implementation of this feature is the best reflection of professionalism.
This article is limited in space, so you can learn more about the principle details such as the xlsx specification zip stream processing in Exceljs’ dependencies.