URIs and URLs and URNs
URLs are familiar, the other two terms are more unfamiliar. URIs, URLs and URNs are standard ways to identify, locate and name resources on the Internet. invented by Tim Berners-Lee in 1989, the World Wide Web (WWW) is considered a globally interconnected collection of physical and abstract resources -It provides information entities on demand - accessible via the Internet. The actual resources range from documents to people, while the abstract resources include database queries.
Because resources have to be identified in a variety of ways (people may have the same name, yet computer files can only be accessed by a unique combination of path names), a standard way of identifying WWW resources is needed. To meet this need, Tim Berners-Lee introduced standard ways of identifying, locating, and naming: URIs, URLs, and URNs.
- URI: Uniform Resource Identifier
- URL: Uniform Resource Locator
- URN: Uniform Resource Name, Uniform Resource Name
The URI, URL, and URN are related to each other in this system; the scope of the URI is at the top of the system, and the scope of the URL and URN are at the bottom of the system. This arrangement shows that both URLs and URNs are subcategories of URIs.
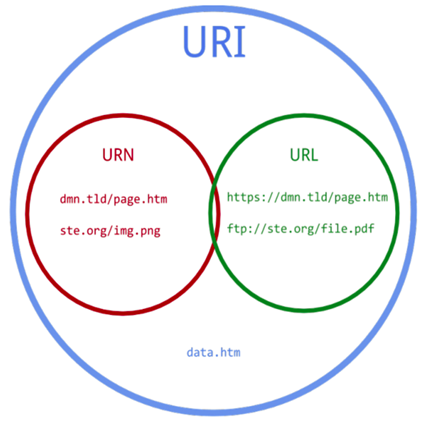
A URI can be considered a locator (URL), a name (URN), or both. A Uniform Resource Name (URN) is like the name of a person, while a Uniform Resource Locator (URL) represents the address of a person. In other words, a URN defines the identity of something, while a URL provides a way to find that thing.
The ISBN system used to mark unique titles is a typical example of the use of URNs. For example, ISBN 0-486-27557-4 identifies a particular edition of Shakespeare’s play Romeo and Juliet without dichotomy. In order to access that resource and read the book, one needs its location, which is a URL address. In a Unix-like operating system, a typical URL address might be a file directory, such as file:///home/username/RomeoAndJuliet.pdf. This URL marks out the ebook file stored on the local hard drive. Thus, URLs and URNs have complementary roles.
URL
URL is a string used to describe information resources on the Internet, and is mainly used in various WWW client and server programs. URLs can be used to describe various information resources in a uniform format, including files, server addresses, directories, etc.
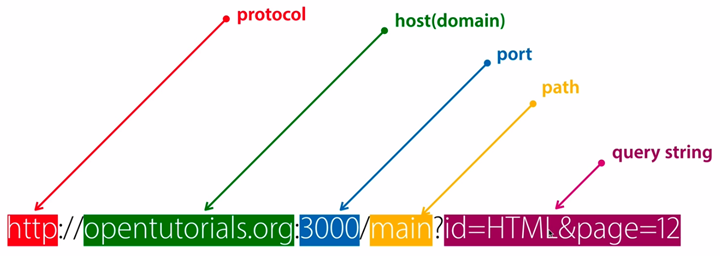
The format of a URL consists of the following three parts.
- the protocol (or service method)
- the IP address of the host where the resource is stored (and sometimes the port number)
- The specific address of the host resource. Such as directory and file names
The first part is separated from the second part by a “://” symbol, and the second part is separated from the third part by a “/” symbol. The first part and the second part are indispensable, and the third part can sometimes be omitted.
The biggest drawback at present is that when the location of the information resource changes, the URL must be changed accordingly. Therefore new methods of representing information resources are being investigated.
URN
A URN (Uniform Resource Name) is a standard format URI that refers to a resource without specifying its location or existence. This example is from RFC3986⚱oasis:names:specification:docbook:dtd:xml:4.1.2
There are still significant differences between URNs and URLs.
- A URN identifies a resource persistently.
- A URL primarily identifies a path for a resource. The path may change over time for two reasons: first, the resources available at a particular URL may change (content changes very frequently on the Internet). In addition, resources may be moved to other locales, or they may appear in multiple locales at the same time. As a result, URLs are often not unique or persistent.
Therefore, URLs and URNs are designed to be similar and have different purposes.
URNs are designed to ensure interoperability with existing standard identifier systems, such as ISSN or any other new standard system. Thus, URNs have a namespace tied to an identifier system, as opposed to other persistent identifier systems (e.g., the DOI prefix does not represent any identifier system, but rather indicates the relevant organization providing the identifier). URLs and URIs do not consider traditional identifier systems at all. Thus, a journal’s URN is based on its ISSN number, and the URN:ISSN namespace applies ISSN-related rules. In contrast, the URL of a journal’s home page is often independent of the ISSN number.
The structure of URN
URN uses URI syntax.
|
|
Thus, the URN consists of at least three parts.
- URN: The URN is first marked with the URN scheme Scheme
- NID: namespace identifier registered with IANA (Internet Assigned Numbers Authority)
- NSS: NSS (Namespace Specific String) is precisely identified
ISSN vs. URN
ISSN was the first bibliographic identifier to accept the URN scheme with a view to its use and expression on the Internet by standard means. Each ISSN number can be expressed in URN form according to the following syntax.
- URN:ISSN:xxxx-xxxx
- Urn:issn:xxxx-xxxx
- UrN:IsSn:xxxx-xxxx
xxxx-xxxx is converted into the ISSN number of the URN, for example: urn:issn:1234-1231
It is recommended that the URN:ISSN be recorded in the embedded metadata of accessible web resources (e.g., newspapers and magazines published online, etc.). In the case of HTML documents, for example, the URN:ISSN should be entered in the HEAD section at.
|
|
URI
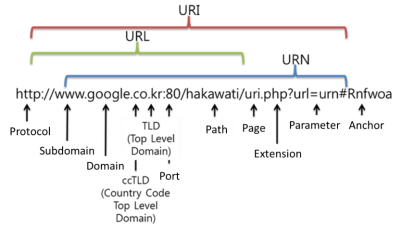
A URI is a simple string that identifies a resource in some uniform (standardized) way and generally consists of three parts.
- the naming mechanism for accessing the resource
- the name of the host where the resource is stored
- the name of the resource itself, represented by a path
A Uniform Resource Identifier URI is the ability to uniquely identify a resource under a certain rule. URLs are a subset of URIs.
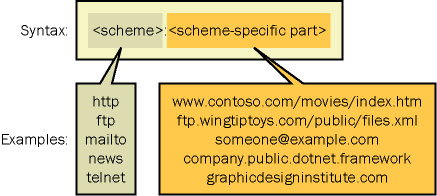
Typically, such strings begin with a scheme and have the following syntax.
There are URIs that point to the inside of a resource. Such URIs end with a “#” and are followed by an anchor flag (called fragment flag).
A relative URI does not contain any naming convention information. Its path usually refers to a resource on the same machine. Relative URIs may contain relative paths (e.g., “…” denotes a higher-level path) and may also contain piecewise identifiers.
Common problems with URIs
- Difficult to type, unnecessarily long URIs
- Inexplicable capitalization
- Unusual punctuation
- Difficult to display on paper media, some characters are not easily legible when printed on paper
- Problems with host and port In addition to the scheme-specific part, domain and port can also be confusing for users.
Immature Technology: Data URI
Data URI is a scheme defined by RFC 2397 for embedding small files directly into documents. A small file can be embedded directly into a page with a specified encoding by using the following syntax.
|
|
MIME-type: specifies the MIME of the embedded data, which is of the form [type]/[subtype]; parameter, for example, the MIME of a png image is image/png. parameter can be used to specify additional information, more often it is used to specify text/plain, text/htm, etc. The charset parameter is used to specify the encoding of the text. The default is text/plain; charset=US-ASCII.
base64: declares that the encoding of the data that follows is base64, otherwise the data must be encoded in percentages (i.e., urlencode the content).
Advantages of Data URI.
- Reduces the number of HTTP requests without the TCP connection consumption and the limit of concurrency of browsers under the same domain.
- For small files will reduce bandwidth. Although the amount of data increases after encoding, it reduces the http header, and when the amount of data in the http header is greater than the incremental amount of file encoding, then bandwidth is reduced.
- For HTTPS sites, there are security tips for mixing HTTPS and HTTP, and HTTPS has more overhead compared to HTTP, so Data URI has more advantages in this regard.
- The entire multimedia page can be saved as a file.
Disadvantages of Data URI.
- Cannot be reused, if the same content is applied multiple times to the same document, it needs to be repeated multiple times, which increases the amount of data by a large amount and increases the download time.
- Cannot be cached alone, so when its containing document is reloaded, it also has to be reloaded.
- The client needs to re-decode and display it, increasing the point consumption. Does not support data compression, base64 encoding increases the size by 1/3, and the amount of data increases even more after urlencode.
- Not conducive to filtering by security software, and there are also certain security risks.
Conversion tool: Data URI Generator
A good URI doesn’t change
What makes a URI a great URI? A great URI is a URI that doesn’t change. what forces a URI to make changes? It’s the URI that doesn’t change: it’s the people who change. In theory there is no reason for people to change URIs, but in practice there are hundreds of reasons. Theoretically, the owner of a domain owns all the URIs under that domain. theoretically all the URIs under your domain are completely under your control, so you are able to make the URIs as stable as you like. The reason that forces a file address to disappear is because the domain name has expired or the server is not continuing to operate. This is why there are so many links that change around. Part of this is due to a lack of foresight. Here are some of the reasons you can hear.
- We just revamped the site to make it better.
- We had a lot of outdated, confidential, and invalid documents that needed to be distinguished.
- We found we had to move documents.
- We were using a CGI script, now we are using a binary program.
- I don’t think URIs need to be persistent, the one that needs to be persistent is the URN.
When you change the URI on the server, you don’t know how many other people are going to use the old URI. they may have posted your link to other sites, they may have saved your link as a bookmark. They may have told someone about your URI. When some people click on the link, but find that it doesn’t open, they lose confidence in the site owner. They get frustrated because they can’t accomplish what they want.
How do I go about designing a URI?
It is a webmaster’s responsibility to make a URI last 2 years, 20 years, 200 years. It takes thought, organization and commitment. Generally URIs change because some information in the document has changed, which is critical to the design of the URI. The creation date of the document this is not changed. This is useful to separate the old system from the new one. This is a good way to start designing a URI that will have only one creation date, even though the document will be modified several times. The only exception is when a page is intentionally “up-to-date”, such as the channel’s home page.
|
|
The main reason this URI does not require a date is that this page is constantly being updated, so if you need an archive of the person’s page, the archive address can be
|
|
(This URI looks good, except for “98″ and “.html” which are a bit redundant)
What information needs to be discarded?
Putting any information into a URI after the use by date can cause problems.
- Author’s name: The copyright may change due to version changes, such as when someone on the team leaves to make a transaction change hands.
- Title: This is tricky, it always seems to fit perfectly now, but needs to be changed after some time.
- Status: files such as “old”, “new”, “latest”, etc. are likely to change status.
- Access rights: The access rights of a file may change depending on the situation, do not put the document under “public”, “team”.
- File extensions: Even “.html” may change.
- Program mechanisms: such as “cgi” and “exec”.
- Disk name: This is also useful!
Sort by article topic
This is a very dangerous operation. Typically, the classification of documents in your URI is differentiated by the work you are doing. This can pose the danger that the field you are working in may change in the future. At the W3C, we expect “MarkUp” to be changed to “Markup” and later to “HTML”, and there is no guarantee that the current naming will apply in the There is no guarantee that the current naming will work in the future.
Categorization by topic is a very good solution, as is categorizing the Internet as a whole, but it has serious drawbacks in the long run. Everyone has a different understanding of the subject matter of each cluster in a language, and the thematic relationships between networks are not as simple as a tree. In fact, when you bind a classification in your URI, there is a good chance that you will go ahead and change that classification in the future, and the URI will need to change with it then.
One reason to use topics for classification in URIs is that you need a name as a part of the URI to organize content, such as content segmentation, which is usually still very safe when the date exists (the date is on the left), 1998/pics can be interpreted as, we are in the year 1998 for photos. Instead of the photo what we are doing in 1998.
Don’t forget your domain name
Remember that this applies not only to the URI “path”, but also to the server name. Be very, very careful in the domain name whether it stands for company, or file status, or access level, or security level division, especially when using multiple domains to access a file, and don’t forget that you can use redirects on the server side.
URL as UI
Although APPs and applets are replacing WEB sites. But WEB sites will eventually be difficult to replace completely. URLs will also be part of the user interface for many years to come. So a good usable website needs.
- A domain name that is easy to remember and spell
- A short URL URL
- URLs that are easy to type
- A visual URL structure
- The user can remove the last level of the URL to reach the parent directory
- URLs remain unchanged
Users do not need to know each URL as well as the server, in fact more people visit the site by a general impression of.
- Many people will guess the domain name of the website without visiting it, so you’d better use the company name or brand as the domain name
- More people prefer to remember the site name than to bookmark the site, so it is better to register a domain name that is easy to spell
- When users email your URL to others, make sure your URL is less than 78 characters because if the URL process may cause a line break
- If many people type through then it is better to use short URLs
- Don’t mix upper and lower case in URLs, because many people will ignore case, but some servers won’t
- Spell check on the server to reduce the problems caused by spelling errors
Outbound links from third sites are important for traffic, so generate your URLs with ease of distribution in mind.
- Make sure that all URLs are consistently accessible and that the pages they link to do not change.
- Don’t change the URL of a file around, make sure there is only one URL before and after the same file.
Many people consider whether a .COM domain name is better than a .CN (country domain)? Yes, many people have gotten used to domain names ending in .COM. This is due to the fact that early browsers developed by Americans automatically complemented .COM (and now Apple’s iPad has a .COM button by default), and based on this, my advice is.
- If the site is in English or international it is best to use a .com domain name
- If the site is in another language you can use a country domain name instead
- If the website content is regional, it doesn’t matter which domain name to use
The main advantage of country-specific domain names over .COM domain names is that there are still many short, easy-to-remember domain names that can be registered.
In the long run, a large number of names (according to human language habits) will be needed to identify every entity in the world. New TLDs will keep appearing, but good domain names will still be influential for many years because of old user habits and old browsers or software will still be around for many years.
How to design a good URL
URLs are part of a website’s UI, so a usable website should meet these URL requirements.
- Simple, memorable domain name
- Short URLs
- URIs that are easy to enter
- URLs that reflect the structure of the site
- URLs that can be guessed and hacked by users (and are encouraged to be so)
- Permanent links
Keep the following four statements in mind, and you’ll know what kind of URLs to design.
- URLs should be user-friendly
- URLs should be readable
- URLs should be predictable
- URLs should be uniform
The root of the URL (level section) is very valuable
For any URL, its most valuable aspect is in its level section. My opinion is that it must be determined before you write any code, and he will determine how your site is finally organized. When you want to create a new site, be sure to think about which root URLs are to be kept.
Namespaces are a very useful solution for expanding URLs
Namespaces are a solution for building good URL structures that are easy to remember. So what does namespace mean? The following is an example.
|
|
In the URL above, pallets/flask is the namespace. Why is this useful? Because any section that follows a namespace will become a level section. in can follow any <user>/<repo> with /issues or /wiki to generate pages.
For the sake of namespace generality and to keep namespaces simple, do not add content before or after, like /feature/<user>/<repo> or /<user>/<repo>/feature.
query strings are very useful for sorting and filtering
Websites have some query strings, and many use multiple query strings. They usually use the same pattern for sorting or filtering pages or content (sort=alpha&dir=desc), and they can be URLs that are simpler and easier to remember.
It is important to remember that a different page needs to be displayed when the URL does not carry any query strings.
Non-ASCII characters appear in URLs
Non-ASCII characters are not only difficult to type, they are also difficult to remember. It is not uncommon for keywords to be stacked in URLs, such as the following URL: Such URLs worked well for SEO before Google changed its algorithm in 2003, but some SEO tutorials still tell you to write keywords into URLs. they are wrong, ignore them.
In addition to that, you need to remember the following two points.
- Underscores are bad, use mid-underscores in your URLs.
- Use some short, colloquial words in the URL. If a URL has characters where the underscore would be special, then it might be a little long.
URLs are for human use and are designed for human use.
A URL is a protocol
A URL is an agreement, and you need to let it stay that way long enough. Once someone clicks on your URL, they are signing an agreement with you and they expect to see the same content the next time they open the URL. After your URL is published, don’t change it lightly. If you really have to change it, do a jump to the original URL.
Any page needs to have a URL
Ideally, each individual page would need a URL that is accessible when copied to another browser. In fact doing so was completely impossible until the advent of the new HTML5 browser history Javascript API, where there are two methods.
- onReplaceState: This method replaces the URL in the browser history, causing the URL to leave a back button.
- onPushState: This method pushes a new URL to the browser history, which is used to replace the history stack in the browser.
These two new methods can change the access history in the browser and with this new feature we need to design the back page for the page. Before using it you need to ask yourself: does this action need to generate new content or display the same content in a different way.
- Generate new content: you should use onPushState (e.g. pagination links)
- Display the same content in a different way: you should use onReplaceState (e.g. sorted filter)
Use your own judgment and think about what you need to achieve.
Link needs to look like a link
Many methods of generating links such as <a>, <button>, if you click on them they will open new pages. When you mouse over the <a> tag, your browser’s status bar will tell you what the URL address is. Don’t break such rules when using onReplaceState and onPushState.
Post-POST sites need to be redirected
In the past many developers liked to generate URLs that could not be re-used, also known as Post-specific URLs, where you would not notice any change in the URL in the address bar when you submitted a form, only to get an error page when you reopened the copied URL. There is nothing inherently wrong with such URLs, their main purpose is for redirection and use in the API, and they should not be used by users.
Must be short
For URIs to be easily entered, written down, spelt and remembered, they should be as short as possible. According to w3c, a URI should ideally be no longer than 80 bytes (this is not a technical limit, experience and statistics provide data), including schema and host, port etc.
Case Policy
The case policy for URIs should be appropriate, either all lower case or initial capitalisation, and confusing case combinations should be avoided. In the Unix world, file path teams are case sensitive, whereas in the Windows world, they are not case sensitive.
Allows URL management URL mapping
Administrators can reorganise the file system structure on the server without changing the URI, which requires a mapping mechanism between the URI and the real server file system structure. Rather than a raw correspondence. This mapping mechanism can be achieved by the following technical means.
- Aliases, aliases, directory aliases on Apache, virtual directories on IIS
- Symbolic links, the Unix world of symbolic links
- Table or database of mappings, where the correspondence between the URI and the file system structure is stored in a database.
Standard redirects
Administrators can achieve URL compatibility after changes to the server file system structure simply by modifying the HTTP Status Code, which can be utilised as follows
- 301 Moved Permanently ([RFC2616] section 10.3.2)
- 302 Found (undefined redirect scheme, [RFC2616] Section 10.3.3)
- Temporary Redirect ([RFC2616] Section 10.3.8)
Use independent URIs
Technology-agnostic URIs
- When serving dynamic content, use technology-agnostic URIs, i.e. URIs that do not expose the scripting language or platform engine used on the server side, and changes to these languages, platforms and engines will not result in changes to the URI. Therefore, words such as sevelet, cgi-bin, etc. should not appear in the URI.
- When serving static content, the techniques that should be used instead of file extensions are content-negotiation, proxy, and URI mapping
Identity flags and session mechanisms
- Use a standard authentication mechanism rather than a specific URI per user
- Use standard session mechanisms rather than putting session IDs in URIs
Use standard steering when content changes:
- Use standard redirection for changed content
- Use HTTP 410 for deleted resources
Provide indexing proxy: Indexing policy
- Content-Location
- Content-MD5
Provide appropriate caching information:
- Cache-related HTTP headers
- Caching policies
- Cache generated content HTTP HEAD and HTTP GET
Summary
- URIs are part of the web UI and should be treated like a website logo and company branding
- URIs are the only interface between the website and the average user and should be treated like your business phone number
The role of the # sign in the URL
- The
#sign in the URL specifies a location on the page. The#sign appears in the URL as a page locator, and the browser reads this URL and automatically scrolls the position to the specified area. - The data after the
#sign is not sent to the HTTP request. The parameters after the#sign work for the browser and not the server side. - Any character following a
#sign is a positional identifier. Any parameter following the#sign is treated as a position identifier, regardless of what parameter follows the first#sign. For example, a link like this (http://example.com/?color=#fff&;shape=circle) is followed by the parameters colour and shape, but the server does not understand the meaning of the URL. All the server receives is:http://example.com/?color= - Changing the parameters after the
#sign will not trigger a page reload but will leave a history. Changing only the content after the#sign will only cause the browser to scroll to the appropriate position and will not reload the page. The browser does not re-request the page, but the action will add a record to the browser’s history, i.e. you can go back to the last position with the back button. This feature is particularly useful for Ajax, where different#values can be set to indicate different access states and return different content to the user. - The value after the
#sign can be changed via javascript using location.hash. The property window.location.hash can make changes to the#sign parameter in the URL. Based on this principle, we can create a new access record without reloading the page. In addition to this, HTML 5 has a new onhashchange event, which is triggered when the#value changes. - Googlebot’s filtering mechanism for the
#sign. By default Google ignores the parameters after the#sign when indexing a page and does not execute the javascript in the page, however Google has defined that to support indexing of Ajax generated content if “#!” is used in the URL in the URL, Google will automatically convert the content after it into the value of the query string escaped_fragment. For example, the latest twitter URL:http://twitter.com/#!/username, Google will automatically requesthttp://twitter.com/?_escaped_fragment_=/usernameto get the Ajax content.
Example: URL rules in the Flickr API
The URL rules in the Flickr API are well worth learning about, so here’s how to unlock the mystery of Flickr URLs.
Flickr image addresses
There are three main categories of URLs.
http://farm{farm-id}.static.flickr.com/{server-id}/{id}_{secret}.jpghttp://farm{farm-id}.static.flickr.com/{server-id}/{id}_{secret}_[mstzb].jpghttp://farm{farm-id}.static.flickr.com/{server-id}/{id}_{o-secret}_o.(jpg|gif|png)s
Size letter suffix description.
| s | small square,75×75 |
|---|---|
| t | thumbnail,thumbnail,longest side 100 |
| m | small thumbnail, 240 |
| - | medium, medium, 500 |
| z | medium 640, medium 640, 640 on the longest side |
| b | large, large, with 1024 as the longest side |
| o | original image, the original image, may be a jpg, or png, or gif |
Note: The original images are somewhat different in that they have their own key, referred to as originalsecret in the returned data, in addition to the original image format, referred to as originalformat. these values are returned when the original image is requested from the API.
The following is an example of an image address URL.
http://farm1.static.flickr.com/2/1418878_1e92283336_m.jpg
- farm-id: 1
- server-id: 2
- photo-id: 1418878
- secret: 1e92283336
- size: m
Flickr page address URLs
The URLs for profile and photo pages use either the NSID (a number with an @ symbol) or a custom URL (which needs to be set), which can be obtained by requesting flickr.people.getInfo. The NSID is always valid, regardless of whether the user sets a custom URL or not. So you can use the user ID for all requests.
You can very easily create URLs for profiles, photobooks, all photos, individual photos or photobooks at.
http://www.flickr.com/people/{user-id}/– profilehttp://www.flickr.com/photos/{user-id}/– photostreamhttp://www.flickr.com/photos/{user-id}/{photo-id}– individual photohttp://www.flickr.com/photos/{user-id}/sets/– all photosetshttp://www.flickr.com/photos/{user-id}/sets/{photoset-id}– single photoset
It is also possible to construct other pages, for example where users are logged in, so that they can link to http://www.flickr.com/photos/me/* or http://www.flickr.com/people/me/*, which will use their own ID instead of ‘me’.
Example link.
http://www.flickr.com/photos/12037949754@N01/http://www.flickr.com/photos/12037949754@N01/155761353/http://www.flickr.com/photos/12037949754@N01/sets/http://www.flickr.com/photos/12037949754@N01/sets/72157594162136485/
Short URL service
Flickr offers a short URL service for uploaded images. Each photo on Flickr has a mathematically calculated short URL: http://flic.kr/p/{base58-photo-id}
The photo ID is compressed by combining numbers and letters using Base58, which is similar to base62 [0-9a-zA-Z], except that the confusing 0, O, I, and l have been removed to make it more recognisable.