Flow line work models are common in industry, dividing the workflow into multiple segments, each with the right number of personnel depending on the intensity of the work. A good assembly line design tries to balance the flow rate of each step to maximize productivity.
Go is a practical language, and the pipeline work model is very well integrated with Go.
pipeline
A pipeline consists of multiple links, specifically in Go, where the links communicate with each other via channels and the same link task can be processed by multiple goroutines at the same time.

The core of a pipeline is the data, which flows through the channels, and each link is processed by a goroutine.
Each link has an arbitrary number of input channels and output channels, except for the start link, which is called the sender or producer, and the end link, which is called the receiver or consumer.
Let’s look at a simple pipeline example, divided into three sessions.
The first link, the generate function, acts as a producer, writes data to a channel, and returns that channel. When all the data has been written, the channel is closed.
The second session, the square function: this is the data processing role that takes the data from the channel at the beginning of the session, calculates the square, writes the result to a new channel, and returns that new channel. When all the data has been calculated, the new channel is closed.
The main function orchestrates the entire pipeline and acts as a consumer: it reads the channel data from the second session and prints it out.
Fan-out,fan-in
In the above example, data is passed between links via unbuffered channels, and data in nodes are processed and consumed by a single goroutine.
This working model is not efficient and makes the efficiency of the entire pipeline dependent on the slowest link. Because the amount of tasks in each link is different, this means that we need different machine resources. Sessions with small tasks occupy as few machine resources as possible, and those with heavy tasks require more threads for parallel processing.
Take car assembly as an example, we can divide the job of assembling tires among 4 people, and when the tires are assembled, hand them over to the rest of the process.
Multiple goroutines can read data from the same channel until that channel is closed, which is called fan-out.
It is called fan-out because it spreads out the data. Fan-out is a mode of distributing tasks.
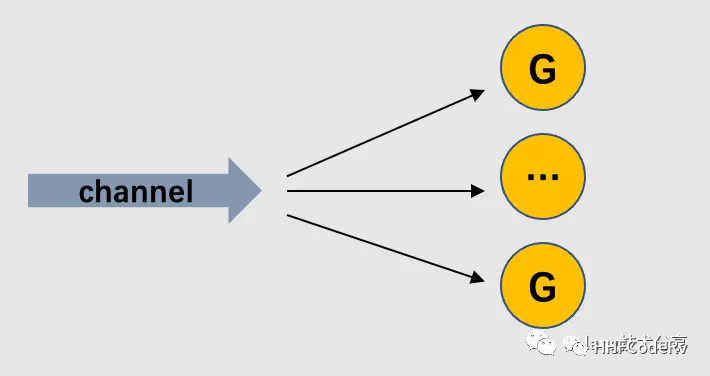
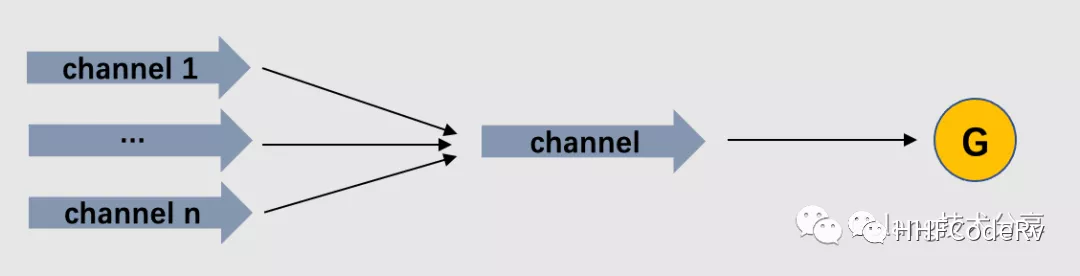
A single goroutine can read data from multiple input channels until all inputs are closed. This is done by multiplexing input channels onto the same channel, and when all input channels are closed, the channel is also closed, which is called fan-in.
It aggregates data, hence the name fan-in. Fan-in is a mode of integrating the results of a task.
In the car assembly example, distributing the tire task to each person is Fan-out, and merging the tire assembly results is Fan-in.
Multiplexing of channels
The encoding model for fanout is relatively simple and will not be studied in this article.
Create a generator function generate that controls the frequency of message generation with the interval parameter. The generator returns a message channel mc and a stop channel sc, which is used to stop the generator task.
|
|
The stopGenerating function calls close(mc) to close the message channel by passing an empty structure to sc and notifying generate to quit.
The multiplex function multiplex creates and returns a consolidated message channel and a control concurrency wg.
|
|
In the main function, two message channels are created and they are reused to generate mmc, which prints each message from mmc. In addition, we have implemented a graceful shutdown mechanism for receiving system break signals (CTRL+C is executed on the terminal to send break signals).
|
|
Summary
This article has briefly introduced the pipeline programming pattern, which is very similar to the familiar producer-consumer pattern.
In Go programming practice, the pipeline divides the data flow into multiple segments, with channels for data flow and goroutines for data processing. fan-out is used for distributing tasks and fan-in is used for data integration, making the pipeline more concurrent through the FAN pattern.
Of course, there are some details that need to be paid attention to, such as the stop notification mechanism, which can be found in the stopGenerating function in the channel multiplexing chapter of this article.
How to do concurrency control by sync.WaitGroup is something you need to learn in the actual coding.