Starting with C++11, the standard library has been extended for associative containers to provide associative containers based on hash table implementations. A hash table will take up more memory than the stored elements in exchange for evenly spreading O(1) performance.
Hash Tables
There are many strategies for resolving conflicts, the standard library chooses to use the separate linking method, where conflicting elements are placed in one location and stored in a linked table.
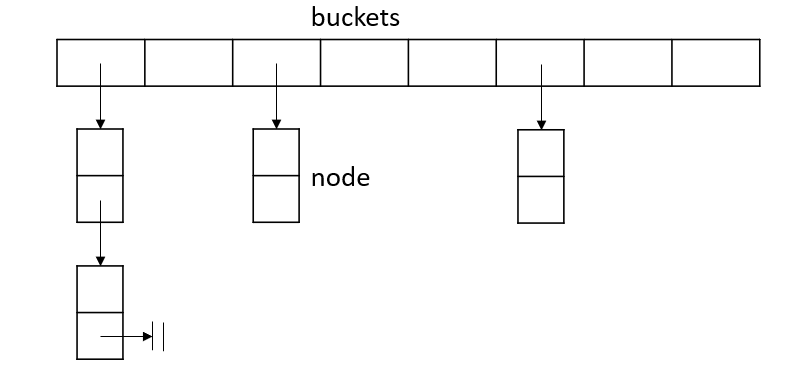
Data structure
Here each element in the hash table is called a bucket, and each inserted element is mapped to the corresponding bucket using the hash function and then placed into it as a node.
1
2
3
4
5
6
7
8
|
template<class Value>
struct _hash_table_node
{
Value val;
_hash_table_node* next;
_hash_table_node(Value v) :val(v), next(nullptr) {}
};
|
Prime number selection
Hash table for better performance, the number of buckets needs to be prime, and a batch is predefined in order to get prime numbers quickly.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
static const int _stl_num_primes = 28;
static const size_t _stl_prime_list[_stl_num_primes] = {
53ul, 97ul, 193ul, 389ul,
769ul, 1543ul, 3079ul, 6151ul, 12289ul,
24593ul, 49157ul, 98317ul, 196613ul, 393241ul,
786433ul, 1572869ul, 3145739ul, 6291469ul, 12582917ul,
25165843ul, 50331653ul, 100663319ul, 201326611ul, 402653189ul,
805306457ul, 1610612741ul, 3221225473ul, 4294967291ul
};
inline size_t max_bucket_count() {
return _stl_prime_list[_stl_num_primes - 1];
}
inline size_t _stl_next_prime(size_t n) {
const size_t* first = _stl_prime_list;
const size_t* last = _stl_prime_list + _stl_num_primes;
// lower_bound 用于找到 [first,last) 中第一个不小于 n 的元素
const size_t* pos = lower_bound(first, last, n);
return pos == last ? *(last - 1) : *pos;
}
|
Declarations
To allow the number of buckets to grow dynamically, vector is used as the container for the buckets.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
template<class Value, class Key, class HashFunc, class ExtractKey,
class EqualKey, class Alloc = allocator<Value>>
class hash_table
{
public:
using hasher = HashFunc;
using key_equal = EqualKey;
using size_type = size_t;
using value_type = Value;
using key_type = Key;
using iterator = _hash_table_iterator<Value, Key, HashFunc,
ExtractKey, EqualKey, Alloc>;
private:
hasher hash_;
key_equal equal_;
ExtractKey get_key_;
std::vector<node*> buckets;
size_type num_elements;
node_allocator alloc_;
};
|
Template parameters reflect the core of the entire hash table.
Value: the value type. It is worth noting that this is not the value in the key-value pair concept, but the type that is actually stored in the node, as you can see the difference later when we introduce map.Key: The key type.HashFunc : Hash function. Used to map elements to buckets, as defined in the standard library.ExtractKey : A method to extract a key from a value, you can see exactly what it does later.EqualKey : A method to determine if keys are identical.Alloc : Memory allocator.
Internally, except for the member type declarations common to STL containers, the data members are instances corresponding to the template parameters.
Iterators
Iterators are an integral part of a container, but elements in a hash table are mapped to different buckets, meaning that storage is unordered.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
template<class Value, class Key, class HashFunc,
class ExtractKey, class EqualKey, class Alloc>
struct _hash_table_iterator
{
using node = _hash_table_node<Value>;
using hashtable = hash_table<Value, Key, HashFunc,
ExtractKey, EqualKey, Alloc>;
using iterator = _hash_table_iterator<Value, Key, HashFunc,
ExtractKey, EqualKey, Alloc>;
using iterator_category = forward_iterator_tag;
using value_type = Value;
using difference_type = ptrdiff_t;
using size_type = size_t;
using reference = value_type & ;
using pointer = value_type * ;
node* cur;
hashtable* ht;
_hash_table_iterator(node* nodeptr, hashtable* htptr)
:cur(nodeptr), ht(htptr) {}
reference operator*() const { return cur->val; }
pointer operator->() const { return &(operator*()); }
iterator& operator++();
iterator operator++(int);
bool operator==(const iterator& it) const { return cur == it.cur; }
bool operator!=(const iterator& it) const { return cur != it.cur; }
};
|
A common member type declaration in iterators, where the iterator is unidirectional and can only move forward, so iterator_category is declared as forward_iterator_tag. Because of this, the key to iterator implementation is the self-incrementing operator.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
iterator& operator++() {
node* old = cur;
//用 next 指针获得下一个元素
cur = cur->next;
if (cur == nullptr) {
//如果到达了桶底,就去下一个有元素的桶
cur = ht->next_bkt(old->val);
}
return *this;
}
iterator operator++(int) {
iterator tmp = *this;
++*this;
return tmp;
}
|
Function implementation
Element Mapping
The most central aspect of a hash table is the hash function, which determines where elements will be placed.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
// n 代表桶的数量
size_type bkt_num(const value_type& obj, size_t n) const
{
return bkt_num_key(get_key_(obj), n);
}
size_type bkt_num(const value_type& obj) const
{
return bkt_num_key(get_key_(obj));
}
size_type bkt_num_key(const key_type& key) const
{
return bkt_num_key(key, buckets.size());
}
size_type bkt_num_key(const key_type& key, size_t n) const
{
return hash_(key) % n;
}
|
In total, there are four versions, whether they provide keys or values, the number of buckets provided or not can be mapped, and eventually it all comes down to the fourth version calling the hash function.
Memory management
buckets is a container for storing node*, and it has its own well-established constructor and destructor, so there is no need to think much about its memory. So the core of memory management here is node, using allocator’s to allocate (free) memory and construct (destructure).
1
2
3
4
5
6
7
8
9
10
11
|
node* new_node(const value_type& obj) {
node* n = node_allocator::allocate(1); //分配内存
n->next = nullptr;
allocator_traits<node_allocator>::construct(alloc_, n, obj); //构造
return n;
}
void delete_node(node* n) {
allocator_traits<node_allocator>::destroy(alloc_, n); //析构
node_allocator::deallocate(n); //释放内存
}
|
The general size of a vector is specified internally, but here we require it to be a prime number, so we need to call the corresponding function to display it.
1
2
3
4
5
6
|
void initialize_buckets(size_type n) {
//保留大于 n 的质数大小的空间
buckets.reserve(next_size(n));
//以空指针填充
buckets.insert(buckets.end(), buckets.capacity(), nullptr);
}
|
This way you can have a perfect constructor.
1
2
3
4
5
|
hash_table(size_type n, const HashFunc& func, const EqualKey& eql)
:hash_(func), equal_(eql), get_key_(ExtractKey()),
num_elements(0), alloc_() {
initialize_buckets(n);
}
|
Inserting elements
Whether the inserted element is repeatable or not is optional, so two versions are provided as with the associative container insert_unique and insert_equal.
For the insert operation, there are two steps, first determining whether the table size needs to be expanded, and then inserting the element afterwards.
1
2
3
4
5
6
|
std::pair<iterator, bool> insert_unique(const value_type& val) {
//扩充大小
resize(num_elements + 1);
//实施插入
return insert_unique_aux(val);
}
|
resize
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
void resize(size_type num_elements_hint) {
const size_type old_n = buckets.size();
// 这里 resize 权衡的是元素数量与桶数量之间大小关系
if (num_elements_hint > old_n) {
const size_type n = next_size(num_elements_hint);
if (n > old_n) {
//构造一个新的 vector 作为新的 buckets
std::vector<node*> tmp(n, nullptr);
for (size_type bucket = 0; bucket < old_n; ++bucket) {
node* first = buckets[bucket];
while (first != nullptr) {
size_type new_bucket = bkt_num(first->val, n);
//将元素移动到 tmp 中
buckets[bucket] = first->next;
first->next = tmp[new_bucket];
tmp[new_bucket] = first;
first = buckets[bucket];
}
}
// 与新的交换,tmp 就会成为旧的 buckets,随着函数结束析构
buckets.swap(tmp);
}
}
}
|
Here resize is an implementation in the SGI STL, and there is no standard condition for what happens. If the expansion function is not needed it will return directly, so there is no need to care about space as long as it is called in the insert operation.
insert_unique
The irreducible version returns a pair, an iterator pointing to the inserted element (even if the element itself exists), and a bool indicating whether it is a new element.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
std::pair<iterator, bool> insert_unique_aux(const value_type& val) {
const size_type n = bkt_num(val);
node* first = buckets[n];
for (node* cur = first; cur; cur = cur->next) {
if (equal_(get_key_(cur->val),get_key_(val))) {
//发现存在键值相同的则返回
return std::pair<iterator, bool>(iterator(cur, this), false);
}
}
//插入新节点
node* tmp = new_node(val);
tmp->next = first;
buckets[n] = tmp;
++num_elements;
return std::pair<iterator, bool>(iterator(tmp, this), true);
}
|
insert_equal
The implementation that allows key duplication is similar to the one that does not allow it, except that it inserts immediately when it finds the same instead of returning false, and always returns the iterator of the inserted element.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
std::pair<iterator, bool> insert_equal_aux(const value_type& val) {
const size_type n = bkt_num(val);
node* first = buckets[n];
for (node* cur = first; cur; cur = cur->next) {
if (equals(get_key(cur->val), get_key_(val))) {
//发现存在键值相同的则立即插入
node* tmp = new_node(val);
tmp->next = cur->next;
cur->next = tmp;
++num_elements;
return iterator(tmp, this);
}
}
node* tmp = new_node(val);
tmp->next = first;
buckets[n] = tmp;
++num_elements;
return iterator(tmp, this);
}
|
unordered_set
With a sound hash table implementation in place, designing a set is simply a matter of re-calling the hash table function.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
template<class Key, class Hash = std::hash<Key>,
class KeyEqual = std::equal_to<Key>, class Allocator = allocator<Key>>
class unordered_set
{
private:
using hashtable = hash_table<Key, Key, Hash,
identity<Key>, KeyEqual, Allocator>;
public:
using key_type = typename hashtable::key_type;
using value_type = typename hashtable::value_type;
using hasher = typename hashtable::hasher;
using key_equal = typename hashtable::key_equal;
using size_type = typename hashtable::size_type;
using iterator = typename hashtable::iterator;
unordered_set() :ht(100, hasher(), key_equal()) {}
explicit unordered_set(size_type n) :ht(n, hasher(), key_equal()) {}
size_type size() const { return ht.size(); }
bool empty() const { return ht.empty(); }
iterator begin() const { return ht.begin(); }
iterator end() { return ht.end(); }
std::pair<iterator, bool> insert(const value_type& val) {
return ht.insert_unique(val);
}
iterator find(const value_type& val) { return ht.find(val); }
private:
hashtable ht;
};
|
identity
It can be said that this implementation is not very bright, the only noteworthy thing is the declaration of hashtable.
1
|
using hashtable = hash_table<Key, Key, Hash, identity<Key>, KeyEqual, Alloc>;
|
What is identity<Key> here?
As mentioned before, this parameter is ExtractKey, which is the method used to convert a value to a key. So for a set, the key is the value, so the conversion returns the value.
1
2
3
4
5
6
7
|
template<class T>
struct identity
{
constexpr T&& operator()(T&& t) const noexcept {
return std::forward<T>(t);
}
};
|
The () operator is overloaded here, making it possible to have a function-like call method, where the return value is the return of the incoming one.
unordered_map
The call to hashtable is the same as unordered_set, with more changes to the declaration of hashtable.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
template<class Key, class T, class Hash = std::hash<Key>,
class KeyEqual = std::equal_to<Key>, class Allocator = allocator<Key>>
class unordered_map
{
private:
using hashtable = hash_table<std::pair<Key, T>, Key, Hash,
select1st<Key, T>, KeyEqual, Allocator>;
public:
using key_type = typename hashtable::key_type;
using value_type = typename hashtable::value_type;
using hasher = typename hashtable::hasher;
using key_equal = typename hashtable::key_equal;
using size_type = typename hashtable::size_type;
using iterator = typename hashtable::iterator;
unordered_map() :ht(100, hasher(), key_equal()) {}
explicit unordered_map(size_type n) :ht(n, hasher(), key_equal()) {}
size_type size() const { return ht.size(); }
bool empty() const { return ht.empty(); }
iterator begin() const { return ht.begin(); }
iterator end() { return ht.end(); }
std::pair<iterator, bool> insert(const value_type& val) {
return ht.insert_unique(val);
}
iterator find(const Key& val) { return ht.find_by_key(val); }
private:
hashtable ht;
};
|
Let’s take a closer look at this membership type.
1
2
|
using hashtable = hash_table<std::pair<Key, T>, Key, Hash,
select1st<Key, T>, KeyEqual, Allocator>;
|
Here Value uses std::pair<Key, T> instead of simply Value. As mentioned before, the template parameter is the type of data stored in the node, so if I store a Value alone, I won’t find the corresponding element when I map it to the corresponding bucket using Key. Here the hashtable is linked separately, which means that all conflicting ones are stored in it, so there must be a Key stored together with the Value to distinguish it. At the same time, it would be a burden on the set implementation if only the original types of Key and Value were provided in the hashtable with template parameters and then stored internally directly in pairs, so now the hashtable must provide the type of internal storage. However, these details should be encapsulated when using unordered_map, so you don’t have to think too much about it.
select1st
Here ExtractKey uses a method called select1st. Since we are storing a pair<Key, Value> of type, the method to extract the key from it is to extract the first element, which is what the name of the method means.
1
2
3
4
5
6
7
|
template<class T1,class T2>
struct select1st
{
constexpr T1 operator()(std::pair<T1, T2> t) const noexcept {
return t.first;
}
};
|