Modern languages like Go, Julia and Rust don’t need a garbage collector as complex as the one used by Java c#. But why is that?
We first need to understand how garbage collectors work and how the various languages differ in the way they allocate memory. First, let’s look at why Java needs such a complex garbage collector.
This article will cover many different garbage collector topics.
- Why Java relies on fast GC I will cover some of the design choices in the Java language itself that can put a lot of pressure on GC.
- Memory fragmentation and its impact on GC design. Why this is important for Java, but not so much for Go.
- Value types and how they change GC.
- Generational garbage collector and why Go doesn’t need it.
- Escape analysis – a trick Go uses to reduce GC pressure.
- Compressed garbage collector – this is important in Java, but Go doesn’t need it. Why?
- Concurrent garbage collection – Go solves many GC challenges by using multiple threads to run concurrent garbage collectors. Why is this more difficult to do with Java.
- Common criticisms of Go GC, and why many of the assumptions behind such criticisms are often flawed or completely wrong.
Why Java needs fast GC more than other languages
Basically, Java outsources memory management completely to its garbage collector. This has proven to be a huge mistake. However, in order to be able to explain this, I need to present more details.
Let’s start at the beginning. It is 1991 and work on Java has begun. Garbage collectors are now very popular. The related research looks promising, and the designers of Java are betting on an advanced garbage collector that will solve all the challenges in memory management.
For this reason, all objects in Java - except for basic types such as integers and floating-point values - are designed to be allocated on the heap. When discussing memory allocation, we usually distinguish between what is called the heap and the stack.
The stack is very fast to use, but has limited space and can only be used for those objects that are within the lifetime of a function call. The stack is only available for local variables.
The heap can be used for all objects. Java essentially ignores the stack and chooses to allocate everything on the heap except for basic types such as integers and floating point. Whenever you write new Something() in Java, it is the memory on the heap that is consumed.
However, this memory management is actually quite expensive as far as memory usage is concerned. You might think that creating a 32-bit integer object requires only 4 bytes of memory.
However, in order for the garbage collector to work, Java stores a header information that contains.
- Type/Type - Identifies the class the object belongs to or its type.
- Lock - Used to synchronize statements.
- Mark / Mark - Mark and sweep (mark and sweep) used by the garbage collector.
This data is usually 16 bytes. Therefore, the ratio of header information to actual data is 4:1. The c++ source code for the Java object is defined as: OpenJDK base class.
Memory fragmentation
The next problem is memory fragmentation. When Java allocates an array of objects, it actually creates an array of references that point to other objects in memory. These objects can end up scattered throughout the heap memory. This is very bad for performance, because modern microprocessors do not read individual bytes of data. Because it is slower to start transferring memory data, each time the CPU tries to access a memory address, the CPU reads a contiguous chunk of memory.
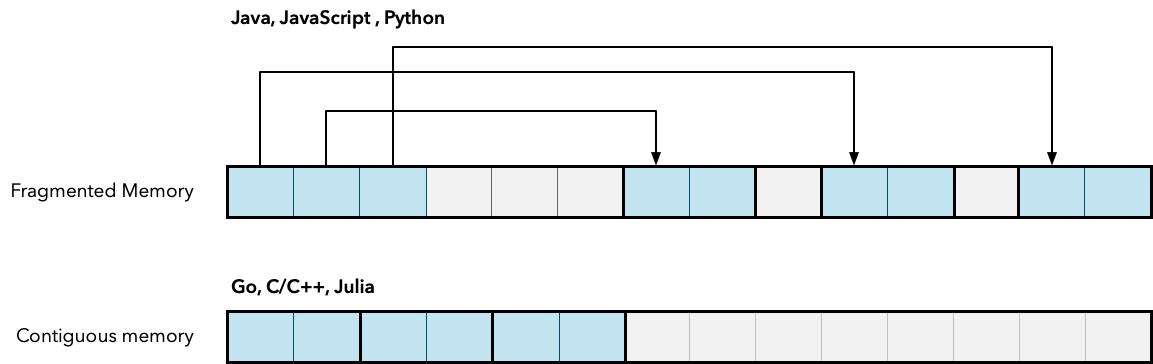
This contiguous block of memory is called a cache line . the CPU has its own cache, which is much smaller than memory. the CPU cache is used to store recently accessed objects, as these objects are likely to be accessed again. If the memory is fragmented, this means that the cache line will also be fragmented and the CPU cache will be filled with a lot of useless data. the hit rate of the CPU cache will be reduced.
How Java overcomes memory fragmentation
To address these major drawbacks, Java maintainers have invested a lot of resources in advanced garbage collectors. They came up with the concept of compact, that is, moving objects into adjacent blocks in memory. This operation is very expensive, as moving memory data from one location to another consumes CPU cycles, as does updating references to these objects.
The garbage collector cannot update these references while they are in use. So updating these references requires suspending all threads. This usually results in a complete pause of hundreds of milliseconds while the Java program moves objects, updates references, and reclaims unused memory.
Adding complexity
To reduce these long pauses, Java uses so-called generational garbage collectors. These are based on the following premises.
Most of the objects allocated in the program are released soon. Therefore, if the GC spends more time on recently allocated objects, it should reduce the pressure on the GC.
This is why Java divides the objects they allocate into two groups.
- Aged objects - objects that have survived multiple mark and purge operations by GC. Each mark and scan operation updates a generation counter to keep track of the object’s “age”.
- Young objects - These are objects that are younger in “age”, meaning they have been recently allocated.
Java more aggressively processes, scans for recently allocated objects, and checks to see if they should be recycled or moved. As objects get “older”, they are moved out of the younger generation area.
All these optimizations create more complexity, and it requires more development effort. It requires paying more money to hire better developers.
How modern languages avoid the same flaws as Java
Modern languages do not need a complex garbage collector like Java and c#. This is because these languages were not designed to rely on garbage collectors as Java does.
In the Go code example above, we allocated 15,000 Point objects. This allocates memory just once, producing a pointer. In Java, this would require 15,000 memory allocations, each of which produces a reference that these applications would also have to manage up separately. Each Point object has the 16-byte header information overhead mentioned earlier. And whether in the Go language, Julia or Rust, you don’t see header information; objects usually don’t have that header information.
In Java, the GC tracks and manages 15,000 separate objects. go only needs to track one object.
Value Types
In languages other than Java, value types are basically supported. The following code defines a rectangle with a Min and Max point to define its range.
This becomes a contiguous block of memory. In Java, this becomes a Rect object, which references two separate objects, the Min and Max objects. So in Java, a Rect instance requires 3 memory allocations, but in Go, Rust, C/c++ and Julia it only requires 1 memory allocation.
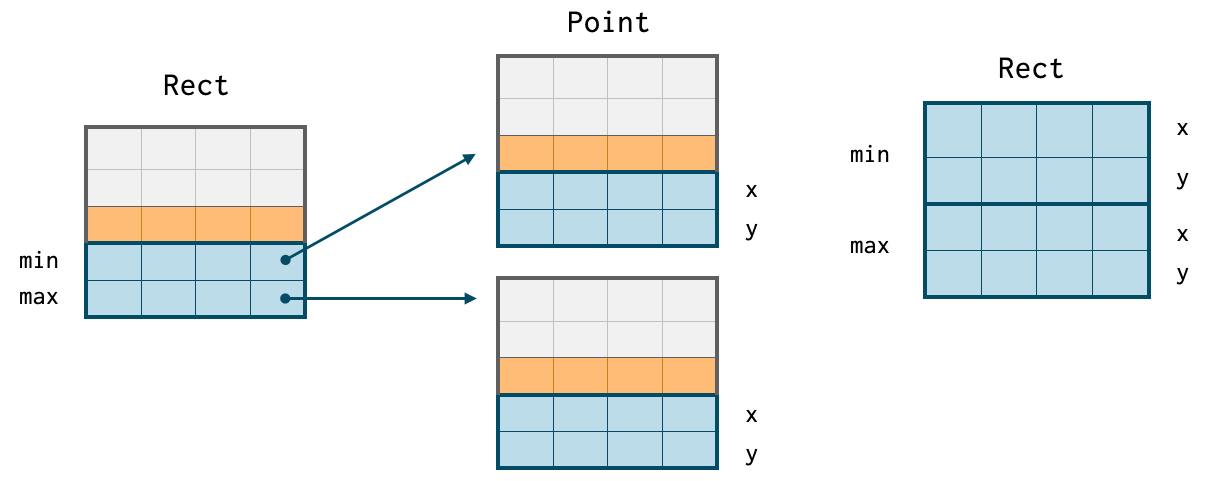
Java-style memory fragments on the left. In Go, C/C++, Julia, etc. programs, on the right on contiguous memory blocks.
The lack of value types causes serious problems when porting Git to Java. Without value types, it is difficult to get good performance. As Shawn O. Pearce on the JGit developer mailing list said.
JGit has struggled with not having an efficient way to represent SHA-1. C simply enters
unsigned char[20]and inlines it into the container’s memory allocation.byte[20]in Java would consume an additional 16 bytes of memory and be slow to access because the 10 bytes and the container object are in non-adjacent memory areas. We tried to solve this problem by converting abyte[20]to 5 int, but this costs extra CPU instructions.
What are we talking about? In Go, I can do the same thing as in C/C++ and define a structure like this:
These bytes will be located in a complete block of memory. And Java would create a pointer to somewhere else.
Java developers realized that they screwed up and that developers really need value types to get good performance. You can say that this statement is rather exaggerated, but you need to explain the Valhalla project. This is Oracle’s effort for Java value types, and it’s done so for exactly the reasons I’m talking about here.
Value types are not enough
So does the Valhalla project solve Java’s problems? Not really. It simply brought Java to the same level as c#. c# came along a few years after Java and realized that garbage collectors were not as magical as everyone thought. As a result, they added value types.
However, this did not put c#/Java on par with languages like Go and C/C++ in terms of memory management flexibility. Java does not support true pointers. In Go, I can write it like this.
Just like in C/C++, you can get the address of an object or a field of an object in Go and store it in a pointer. You can then pass this pointer and use it to modify the field it points to. This means that you can create large value objects in Go and pass them as function pointers to optimize performance. The situation is better in c# because it has limited support for pointers. The preceding Go example can be written in c# as:
However, c#’s pointer support comes with some warnings that don’t apply to Go:
- Code that uses pointers must be marked as unsafe. This produces code that is less safe and more likely to crash.
- Must be a pure value type allocated on the stack (all structure fields must also be value types).
- In the context of fixed, the fixed keyword turns off garbage collection.
Therefore, the normal and safe way to use value types in c# is to copy them, as this does not require defining unsafe or fixed code fields. However, for larger value types, this can create performance problems. go does not have these problems. You can create pointers to objects managed by the garbage collector in Go. there is no need to mark the code that uses pointers separately in Go, as you would in c#.
Customizing secondary allocators
Using the right pointers, you can do a lot of things that value types can’t do. One example is creating secondary allocators. Chandra Sekar S gives an example: Arena allocation in Go.
Why are these useful? If you look at some microbenchmarks, such as the algorithm for constructing a binary tree, you will usually find that Java has a big advantage over Go. This is because the construct binary tree algorithm is usually used to test how fast the garbage collector is when allocating objects. Java is very fast at this because it uses what we call bump pointers. It just adds a pointer value and Go will find a suitable location in memory to allocate the object. However, using the Arena allocator, you can also build binary trees quickly in Go.
This is why a real pointer would be beneficial. You can’t create a pointer to an element in a contiguous block of memory, as follows:
n := &(*arena)[len(*arena)-1]
Problems with Java Bump allocator
The bump allocator used by Java GC is similar to the Arena allocator in that you only need to move one pointer to get the next value. However, developers do not need to manually specify the use of the Bump allocator. This may seem smarter. But it causes some problems that are not present in the Go language.
- Sooner or later, memory will need to be compacted (compressed), which involves moving data and fixing pointers. the Arena allocator does not need to do this.
- In multi-threaded programs, bump allocators require locks (unless you use thread-local storage). This wipes out their performance benefits, either because locks degrade performance or because thread-local storage will lead to fragmentation, which will require compression later.
Ian Lance Taylor, one of the creators of Go, explains the problem with the bump allocator.
In general, it may be more efficient to use a set of per-thread caches to allocate memory, and at this point you’ve lost the advantage of the bump allocator. Therefore, I would assert that there is usually no real advantage to using a compressed memory allocator for multi-threaded programs, despite the many caveats.
Generational GC and escape analysis
The Java garbage collector has more work to do because it allocates more objects. Why? We just talked about it. Without value objects and real pointers, it will always end up with a lot of objects when allocating large arrays or complex data structures. Therefore, it requires generational GC.
The need to allocate fewer objects is beneficial to the Go language. But the Go language has another trick up its sleeve. both Go and Java perform escape analysis when compiling functions.
Escape analysis consists of looking at a pointer created inside a function and determining if the pointer escaped out of the scope of the function.
In the first example, values points to a slice, which is essentially the same as a pointer to an array. It escaped because it was returned. This means that values must be allocated on the heap.
However, in the second example, the pointer to values does not leave the nonEscapingPtr function. Therefore, values can be allocated on the stack, an action that is very fast and cost effective. The escape analysis itself only analyzes whether a pointer escapes.
Limitations of Java escape analysis
Java also does escape analysis, but there are more restrictions on its use. From the Java SE 16 Oracle documentation covering the hotspot VM.
It does not replace heap allocations with stack allocations for objects that are not globally escaped.
However, Java uses another technique called scalar substitution, which avoids the need to put objects on the stack. Essentially, it breaks up the object and puts its basic members on the stack. Remember, Java can already place basic values such as int and float on the stack. However, as Piotr Kołaczkowski found in 2021, in practice scalar substitution does not work even in very trivial cases.
On the contrary, the main advantage of scalar substitution is the avoidance of locks. If you know that a pointer will not be used outside of a function, you can also be sure that it does not need a lock.
Advantages of Go language escape analysis
However, Go uses escape analysis to determine which objects can be allocated on the stack. This greatly reduces the number of short-lived objects that could have benefited from a generational GC. But remember that the whole point of generational GC is to take advantage of the fact that recently allocated objects have a very short lifetime. However, most objects in the Go language will probably live a long time, because objects with short survival times are likely to be caught by escape analysis.
Unlike Java, in which escape analysis also applies to complex objects, Java can usually only successfully perform escape analysis on simple objects such as byte arrays. Even the built-in ByteBuffer cannot be allocated on the stack using scalar substitution.
Modern languages do not require compressed GC
You can read that many experts in garbage collectors claim that Go is more likely to run out of memory than Java due to memory fragmentation. The argument goes like this: because Go doesn’t have a compressed garbage collector, memory will fragment over time. When memory is fragmented, you will reach a point where loading a new object into memory will become difficult.
However, this problem is greatly reduced for two reasons.
- Go does not allocate as many small objects as Java does. It can allocate large arrays of objects as a single block of memory.
- Modern memory allocators such as Google’s TCMalloc or Intel’s Scalable Malloc do not segment memory.
Memory fragmentation was a big problem for memory allocators when Java was designed. People didn’t think this problem could be solved. But even back in 1998, shortly after Java was introduced, researchers began to address the problem. Here is a paper by Mark S. Johnstone and Paul R. Wilson.
This essentially reinforces our previous results, which show that the memory fragmentation problem is often misunderstood and that a good allocator strategy can provide good memory usage for most programs.
As a result, many of the assumptions made when designing Java memory allocation strategies are no longer true.
Generational GC vs Concurrent GC Suspension
The Java strategy of using generational GC is designed to make the garbage collection cycle shorter. Be aware that in order to move data and repair pointers, Java must stop all operations. If it pauses for too long, it will reduce the performance and responsiveness of the program. With generational GC, less data is checked each time, thus reducing the checking time.
However, Go solves the same problem with some alternative strategies.
- there is less work to do during the GC run because there is no memory to move and no pointers to fix. the Go GC does only one mark and cleanup: it looks in the object graph for objects that should be freed.
- It runs concurrently. Therefore, a separate GC thread can look for objects to be released without stopping other threads.
Why Go can run GC concurrently but Java can’t? Because Go does not repair any pointers or move any objects in memory. Therefore, there is no risk of trying to access a pointer to an object that has just been moved but the pointer has not been updated. An object that no longer has any reference will not suddenly gain a reference because some concurrent thread is running. Therefore, there is no risk of moving a “dead” object in parallel.
What’s going on here? Suppose you have 4 threads working in a Go program. One of the threads performs a temporary GC job at any time T seconds, for a total of 4 seconds.
Now imagine that a Java program’s GC does only 2 seconds of GC work. Which program squeezes out the most performance? Who did the most in T seconds? Sounds like a Java program, right? Wrong!
4 worker threads in a Java program will stop all threads for 2 seconds. This means that 2 x 4 = 8 seconds of work is lost in T seconds. So, although Go takes longer to stop, each stop has less impact on the program’s work because all threads are not stopped. Thus, a slow concurrent GC may outperform a faster GC that relies on stopping all threads to perform its work.
What if garbage is being generated faster than it can be cleaned up?
A popular argument against current garbage collectors is that active worker threads can generate garbage faster than the garbage collector threads can collect it. In the Java world, this is known as “concurrency mode failure”.
In this case, the runtime has no choice but to stop the program completely and wait for the GC cycle to complete. So, when Go claims that the GC pause time is very low, this only applies if the GC has enough CPU time and space over the main program.
But Go has a clever trick to get around this problem described by Go GC guru Rick Hudson. Go uses what is called a “Pacer”.
If needed, Pacer slows down allocation while speeding up tagging. At a higher level, Pacer stops Goroutine, which does a lot of allocating, and lets it do the marking. The workload is proportional to the allocation of Goroutine. This speeds up the garbage collector while slowing down the mutator.
Goroutines are kind of like green threads that are multiplexed on a thread pool. Basically, Go takes over the threads that are running workloads that generate a lot of garbage and lets them help the GC clean up that garbage. It will keep taking over threads until the GC is running faster than the garbage-generating concurrent threads.
In a nutshell
While advanced garbage collectors solve real problems in Java, modern languages, such as Go and Julia, avoid these problems from the start and therefore do not need to use Rolls Royce garbage collectors. When you have value types, escape analysis, pointers, multicore processors, and modern allocators, many of the assumptions behind Java’s design are thrown out the window. They no longer apply.
GC’s Tradeoff no longer applies
Mike Hearn has a very popular story on Medium in which he criticizes the Go GC claim: Modern Garbage Collection.
Hearn’s key message is that there are always trade-offs in GC design. His point is that because Go aims for low latency collection, they will suffer in many other metrics. This is an interesting read because it covers a lot of details about tradeoffs in GC design.
First, what does low latency mean?Go GCs pause for an average of 0.5 milliseconds, while various Java collectors can take hundreds of milliseconds.
I think the problem with Mike Hearn’s arguments is that they are based on the flawed premise that memory access patterns are the same for all languages. As I mentioned in this article, this is simply not the case. Go will generate far fewer objects that require GC management, and it will use escape analysis to clean up many of them in advance.
Old technology is inherently bad?
Hearn’s argument declares that simple collection is somehow bad:.
Stop-the-world (STW) markup/cleanup is the most common GC algorithm used in undergraduate computer science courses. When doing job interviews, I sometimes ask candidates to talk a bit about GC, but almost always, they either see GC as a black box and know nothing about it, or they think it is still used today with this very old technique.
Yes, it may be old, but this technology allows running GC concurrently, something that “modern” technology does not allow. In our modern hardware world with multiple cores, this is even more important.
Go not C#
Another way of saying :
Since Go is a relatively common imperative language with value types, its memory access model may be comparable to C#, where the assumption of partitioning certainly holds, and thus .NET uses a partitioned collector.
This is not the case. c# developers minimize the use of large-valued objects because code related to pointers cannot be used safely. We must assume that c# developers prefer to copy value types rather than use pointers, because this can be done safely in the CLR. This naturally brings a higher overhead.
As far as I know, C# also does not make use of escape analysis to reduce the generation of short-lived objects on the heap. Secondly, C# is not very good at running a large number of tasks simultaneously. go can take advantage of their concurrency to speed up collection at the same time, as Pacer mentions.
Memory compression tidying
Compression: Because there is no compression, your program will end up fragmenting the heap. I will discuss heap fragmentation further below. Neatly placing things in the cache will not benefit you either.
Mike Hearn’s description of allocators here is not up to date. modern allocators such as TCMalloc essentially eliminate this problem.
Program throughput:Since GC must do a lot of work for each cycle, this steals CPU time from the program itself and slows it down.
This does not apply when you have a concurrent GC. All other threads can continue to run while the GC is working - unlike Java, which has to stop the whole world.
Heap Overhead
Hearn raises the issue of “concurrent mode failure”, assuming that Go GC runs the risk of not being able to keep up with the garbage generator.
Heap overhead: Since collecting the heap by marking/clearing is very slow, you need a lot of free space to make sure you don’t experience “concurrent mode failures”. The default heap overhead is 100%, which doubles the amount of memory your program needs.
I’m skeptical of this claim, as many real-world examples I’ve seen seem to suggest that Go programs use less memory. Not to mention, this ignores the existence of Pacer, which will grab Goroutines and generate a lot of garbage for them to clean up.
Why low latency is important for Java too
We live in a world of Docker and microservices. This means that many smaller programs communicate and work with each other. Imagine a request going through several services. In a chain, if one of these services has a major stall, it will have a chain reaction. It causes all other processes to stop working. If the next service in the pipeline is waiting for garbage collection from STW, then it will not work.
Therefore, the latency/throughput tradeoff is no longer a tradeoff in GC design. When multiple services are working together, high latency will cause throughput to drop. Java’s preference for high throughput and high latency GC applies to a single block world. It no longer applies to the microservice world.
This is a fundamental problem with Mike Hearn’s view that there is no panacea, only trade-offs and trade-offs. It tries to give the impression that Java’s trade-offs are equally valid. But the trade-offs have to be adapted to the world we live in.
In short, I think the Go language has made a lot of smart moves and strategic choices. If it’s just a trade-off that anyone can do, then it’s not advisable to omit it.