
In the article “Go Classical Blocking TCP Stream Parsing in Practice”, we implemented a custom TCP stream-based parsing protocol based on Go’s classical blocking I/O model. The advantage of this one-connection-per-goroutine model is that it is simple, well-written, and well-understood, reducing the mental burden on developers. However, once the number of connections is up, the number of goroutines increases linearly. When faced with a large number of connections, this model is overwhelmed: there will be a large number of goroutines in the system, and the overhead of goroutine scheduling and switching will be too much.
So how should we solve the massive connection scenario? The industry’s mature solution: use I/O multiplexing model . If you know the implementation of Go net package, you will know that Go also uses I/O multiplexing at runtime, and its implementation is netpoll in runtime. Conn (both Accept and Dial) at the goroutine level exhibit “blocking” characteristics, but the fd (file descriptor) of the underlying net. The Go runtime is responsible for calling multiplexing mechanisms such as epoll to monitor whether these fd’s are readable or writable, and wake up the goroutine to continue network I/O operations when appropriate, which reduces system calls and reduces the frequency of M (OS threads) running the goroutine getting stuck in kernel state waiting due to system calls and having to create new threads due to blocking and losing M. to create new threads.
So what are the shortcomings of building your own I/O multiplexing at the user level? Complex, not easy to write, not easy to understand . But there doesn’t seem to be any other better way. Unless you change the language, you’ll have to tough it out ^_^. The good thing is, the Go community already has several good Go user-level non-blocking I/O multiplexing development framework libraries available, such as evio, gnet, easygo, etc. We choose gnet. We choose gnet. But note: choosing does not mean recommending, here is only to do this practice only, whether to use gnet development on the production program, you need to determine your own evaluation.
1. gnet-based development of TCP stream protocol parser
One of the thresholds for using the framework is that you have to go and learn the framework itself . The good thing is that gnet provides several very typical examples, which we can base custom_codec to quickly develop our TCP stream protocol parser.
The following is a key loop for implementing custom codec based on gnet framework. Understanding this loop, we know where to call Frame codec and packet codec, which determines the structure of the subsequent demo program.
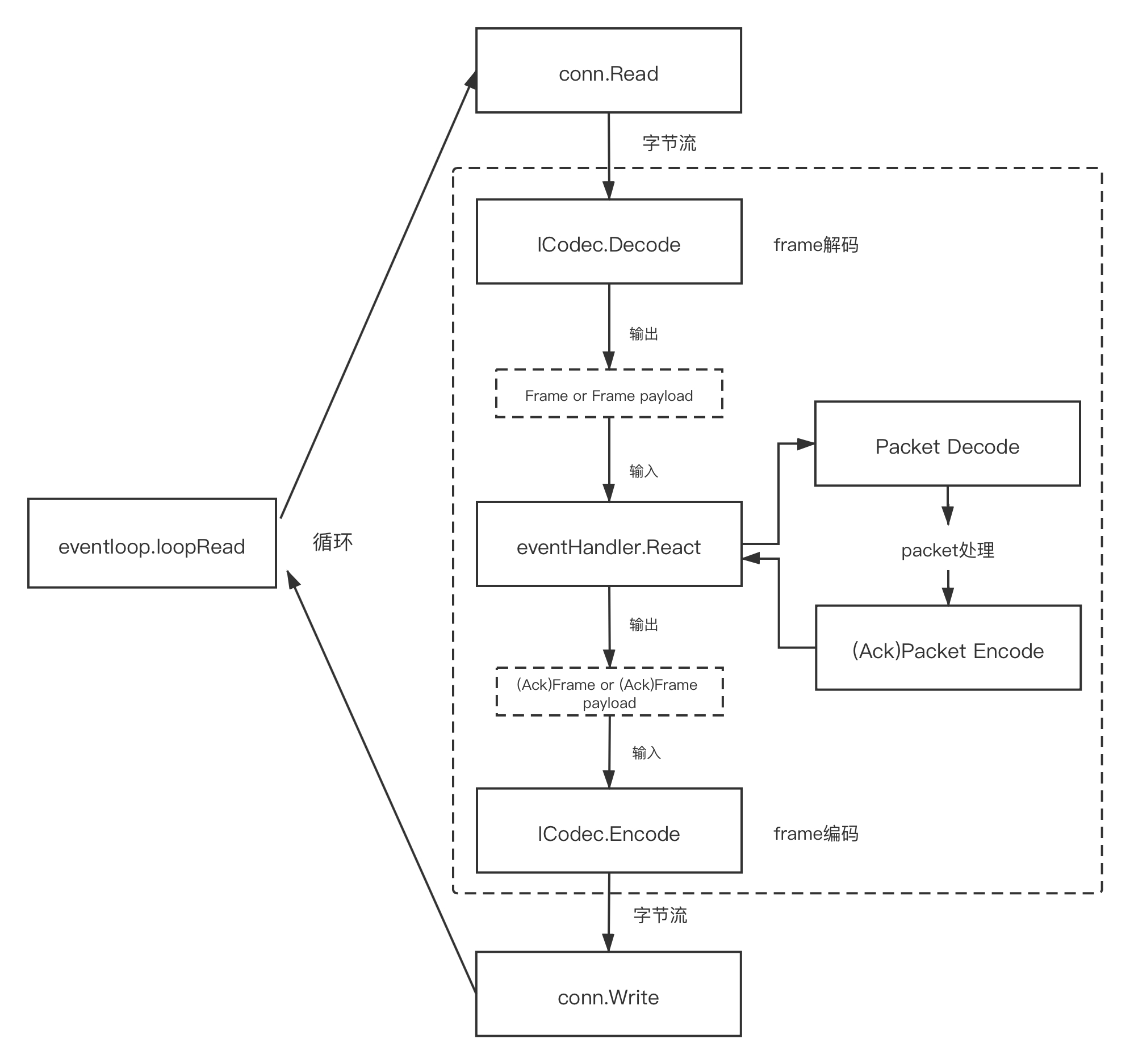
The frame codec, packet codec and React in the dashed box on the right in the above figure are to be implemented by the user. The eventloop.loopRead method of the gnet framework will call the frame codec and React in a loop to realize the processing of TCP streams and the return of responses. With such a “map”, we can clarify the general location of each package in the demo program.
Our demo is adapted from gnet’s example custom_codec, whose main package structure comes from custom_codec.
|
|
Two things to note about the above code.
- The third parameter of customCodecServe we pass in false, i.e. we choose to reply to the answer synchronously instead of asynchronously.
- We pass the custom frame codec (which implements the gnet.ICodec interface) instance to the customCodecServer instance, so that the subsequent gnet loopRead call is our custom frame codec.
In the order of the flowchart above, the byte stream read by gnet from conn will be passed to our frame codec, and we will see the implementation of gnet-based Frame codec below (our custom protocol definition can be found in the article “Practice of Go Classical Blocking TCP Protocol Stream Parsing”).
|
|
The Decode implementation of Frame above is responsible for both frame decoding and checking the integrity of the current data of the frame, if a complete frame is not yet ready, Decode will return an error, and then gnet will call the Decode function again when the connection (conn) is readable. ReadN method, which is essentially a Peek operation (called lazyRead by gnet), that is, it only previews the data without moving the position of the “read pointer” in the data stream. When the frame is not fully ready, gnet uses the RingBuffer to store some of the data of the frame that is already in place. If the frame is ready, Decode calls the gnet.
If the pre-read frame length is too long (the 100 in the code is a magic number for demo purposes only, you can use the maximum possible value for the frame), the current cache will be cleared and an error will be returned. (But gnet does not disconnect from the client because of this, whether this piece of gnet’s mechanism is reasonable is still open to question.)
If the decoding goes well, according to our custom protocol spec, we will return the payload of the frame, i.e. from the fifth byte of the frame.
As seen in the above figure, the payload returned by frame Decode will be passed as input data to the eventHandler.React method, which is also implemented by ourselves.
|
|
In React, we use the packet package to Decode the incoming frame payload and process the resulting Packet, and encode the packet response after processing (encode), and the byte sequence (ackFramePayload) obtained after encoding will be returned as the first return value out of React.
Frame will Encode the ackFramePayload returned by React, and the encoded byte sequence will be written to the outbound tcp stream by gnet.
|
|
This completes a loopRead loop. We can test this program using the client from the article “Go Classic Blocking TCP Protocol Stream Parsing in Practice”.
|
|
2. Compression test comparison
gnet has made many optimizations for memory allocation, cache reuse, etc. Let’s do a simple performance comparison with the blocking I/O model program (due to limited resources, our crush test here is also the same as in the previous article, using 100 client connections sent with best effort (best effort) instead of a huge number of connections).
The following is a performance comparison of demo1 (blocking I/O model without optimization), demo3 (blocking I/O model after optimization) and demo4 (io multiplexing model).
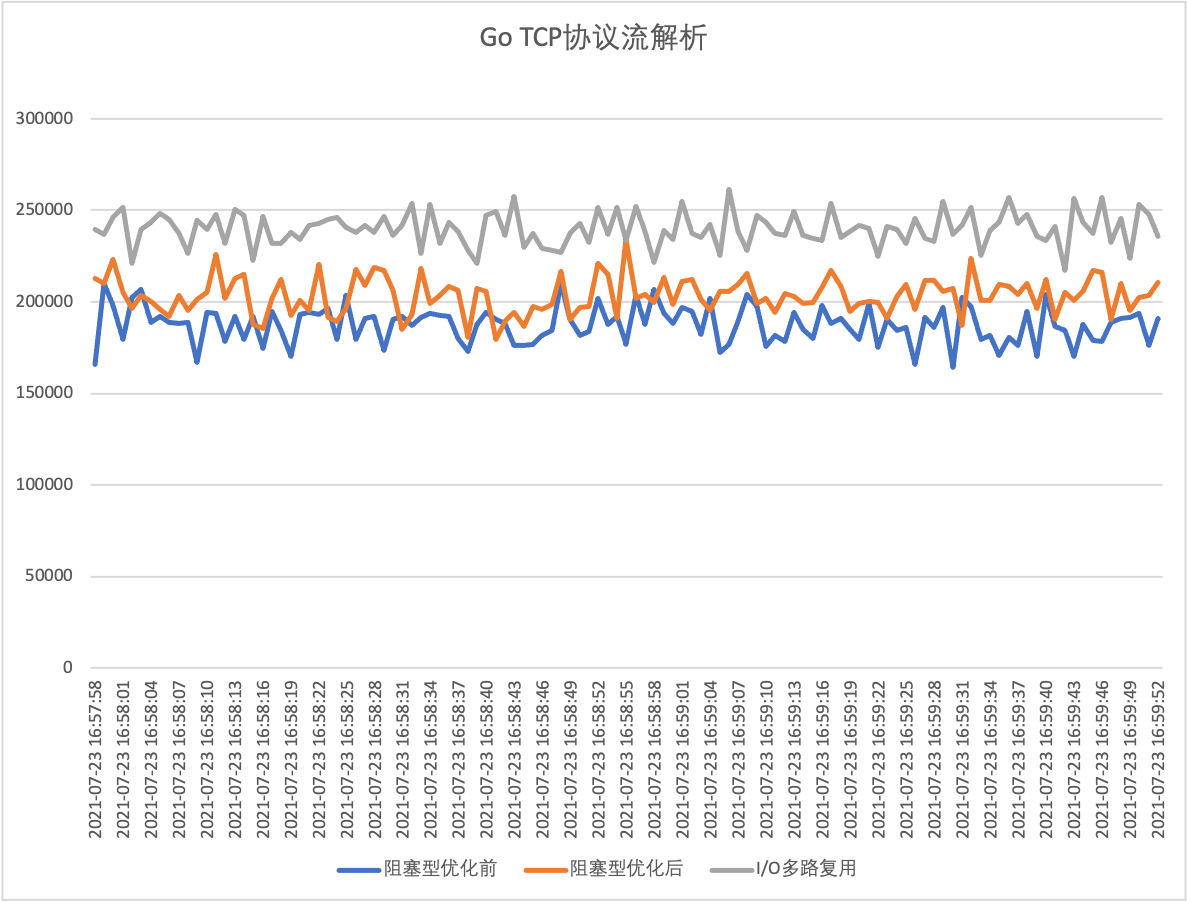
Roughly speaking, the program with the gnet I/O multiplexing model (demo4) is on average 15%-20% higher in performance than the program with the blocking I/O model optimized (demo3).
In addition, the system monitoring data collected by dstat also shows that the cpu system time (sys) usage is also about 5 points less when running demo4 than demo3.
The output of dstat -tcdngym when running demo3.
|
|
Output of dstat -tcdngym when running demo4.
|
|
2. Asynchronous reply
In the above example, we use the gnet synchronous reply method. gnet also supports the asynchronous reply method, that is, the ackFramePayload obtained in React is submitted to a goroutine worker pool created by gnet, and one of the free goroutines in the worker pool will subsequently encode the The ackFramePayload is encoded into a complete ackFrame and returned to the client.
To support asynchronous replies, we need to make several changes to demo4 (see demo5), the main changes are in cmd/server/main.go.
The first one: when the main function calls customCodecServe, set the third parameter async to true.
Second place: In the React method of customCodecServer, after we get the encoded ackFramePayload, we don’t assign it to out and return it immediately, but judge whether to return the answer asynchronously. If the answer is returned asynchronously, the ackFramePayload will be submitted to the workerpool, and the workerPool will subsequently allocate the goroutine and write the answer back to the client via AsyncWrite of gnet. If it is not asynchronous, the ackFramePayload is assigned to out and returned after.
|
|
Other than that, the rest of the package code remains the same. We still also do a pressure test to see how the demo5 performance of asynchronous answerback really is!
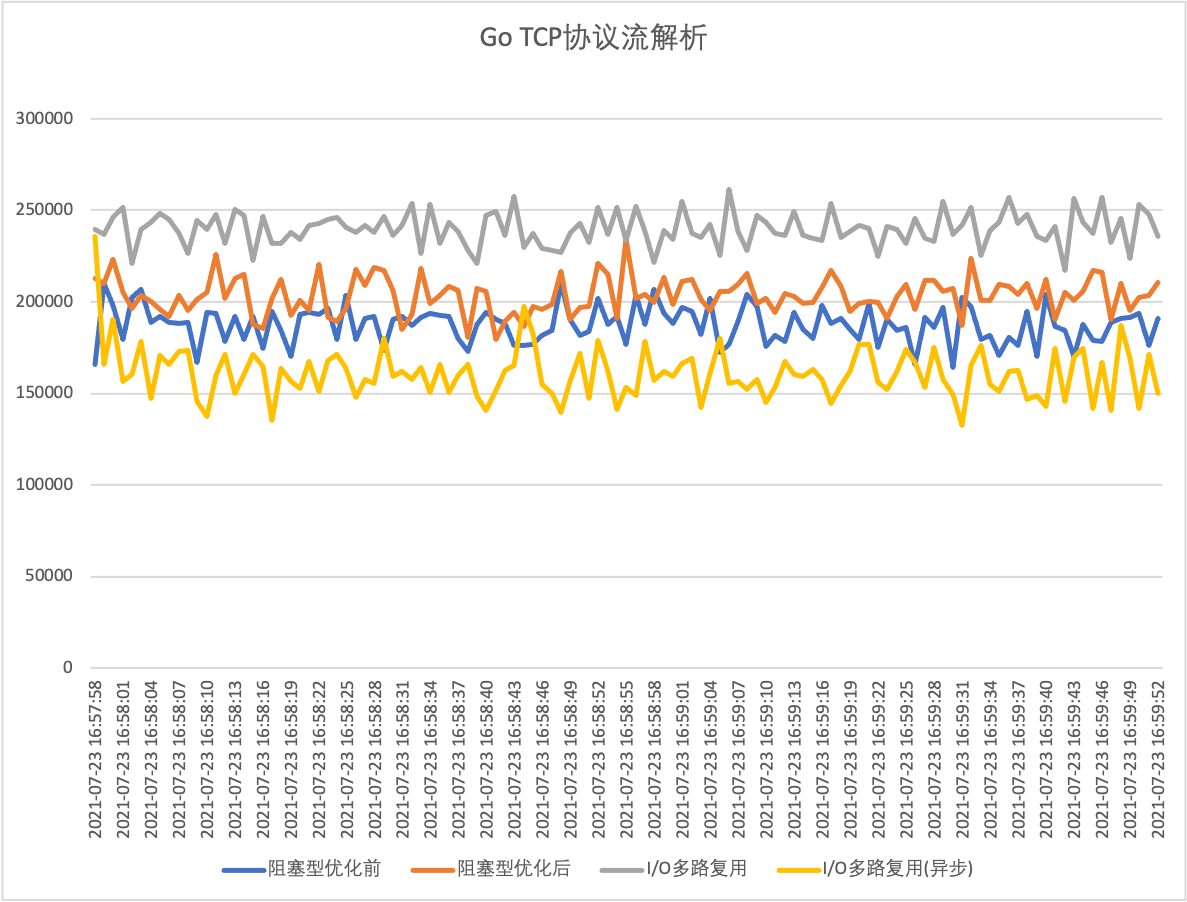
From the above figure, the performance of this scenario is much lower than that of the blocking I/O model by means of asynchronous replies. I didn’t look deeper into this, but I guess it is possible that the workerpool creates many goroutines when there are too many replies and concentrated replies at the same time, which not only does not play the role of pooling, but also brings the overhead of goroutine creation and scheduling.
3. Summary
In this paper, we have replaced the blocking I/O model with an I/O multiplexing model and re-implemented a custom TCP stream protocol parser based on the gnet framework. With the strategy of synchronous answer-back, the performance of the TCP stream protocol parser developed based on gnet has been improved compared to the blocking I/O model program.
All the code covered in this paper can be downloaded from here.