The Singleton service pattern ensures that only one instance of an application is active at a time, yet highly available. This pattern can be implemented from within the application, or can be delegated entirely to Kubernetes.
Existence of problems
One of the main features provided by Kubernetes is the ability to easily and transparently scale applications. pods can be forced to scale with a single command (e.g. kubectl scale), or declaratively with a controller definition (e.g. ReplicaSet), or even dynamically based on the application load Elastic Scale. By running multiple instances of the same service (not a Kubernetes service, but a component of a distributed application represented by a Pod), the system typically increases throughput and availability. Availability is increased because if a service instance becomes unhealthy, the request scheduler forwards future requests to other healthy instances. In Kubernetes, multiple instances are replicas of a Pod, and Service resources are responsible for request scheduling.
However, in some cases, only one instance of a service is allowed to run at a time. For example, if a service has a task that executes periodically and there are multiple instances of the same service, each instance will trigger the task at a predetermined interval, resulting in duplication, rather than only one task being triggered as expected. Another example is a service that performs polling on a specific resource (file system or database), where we want to make sure that only one instance, or maybe even one thread, performs the polling and processing. A third case occurs when we want to consume messages sequentially from a message broker with a single-threaded consumer that is also a singleton service.
In all these and similar cases, we need some control over how many instances of the service (usually only one) are active at a time, regardless of how many instances are started and kept running.
Solution
Running multiple copies of the same Pod creates a master - master topology, where all instances of a service are master. What we need is a master - passive (or master-slave) topology where only one instance is the master and all other instances are the passive. Essentially, this can be achieved at two possible levels: out-of-application locking and in-application locking.
Out-of-application locking
As the name implies, this mechanism relies on a management process outside the application to ensure that only one instance of the application is running. The application implementation itself is not aware of this constraint, but runs as a single instance. From this perspective, it is similar to having a Java class that is instantiated only once by the management runtime (e.g. Spring framework). The class implementation is not aware that it is running as a single instance, nor does it contain any code constructs to prevent instantiation of multiple instances. The following diagram shows how to implement out-of-application locking with a replica with the help of a StatefulSet or ReplicaSet controller.
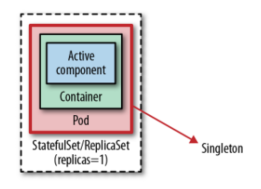
The way to implement this in Kubernetes is to start a Pod with a single replica. this activity alone does not guarantee high availability of a single Pod. What we need to do is to also support the Pod with a controller (such as a ReplicaSet) that turns the monolithic Pod into a highly available monolith. This topology isn’t exactly active-active (no passive instances), but the effect is the same because Kubernetes guarantees that an instance of the Pod is always running. In addition, the single Pod instance is highly available thanks to the controller performing health checks, HealthProbe and healing in case of Pod failure.
The main thing to watch out for in this approach is the number of replicas, which should not be accidentally increased, as there is no platform-level mechanism to prevent the number of replicas from changing.
It’s not entirely true that only one instance is running at any given time, especially when things go wrong. Kubernetes primitives such as ReplicaSet favor availability over consistency-a deliberate decision to achieve a highly available and scalable distributed system. This means that ReplicaSet uses “at least” rather than “at most” semantics for its replicas. If we configure a ReplicaSet as a single instance with replicas:1 the controller ensures that at least one instance is always running, but occasionally there can be more instances.
The most common case here is when a node with a controller-managed Pod becomes unhealthy and disconnects from the rest of the Kubernetes cluster. In this case, the ReplicaSet controller will start another Pod instance on a healthy node (assuming there is enough capacity) without ensuring that the Pod on the disconnected node is shut down. Similarly, when changing the number of replicas or migrating Pods to a different node, the number of Pods may temporarily exceed the required number. The purpose of this temporary increase is to ensure high availability and avoid outages, which are required for stateless and scalable applications.
A singleton can be resilient and resilient, but it is not, by definition, highly available. Singletons typically favor consistency over availability. a Kubernetes resource that also favors consistency over availability and provides the strict singleton guarantees needed is StatefulSet. if ReplicaSets don’t provide the guarantees your application needs and you have strict singleton requirements, StatefulSets may be the answer. StatefulSets are designed to provide many features for stateful applications, including stronger singleton guarantees, but they also add complexity. We will discuss issues related to single instances and cover StatefulSets in more detail in the subsequent chapter, Stateful Service.
Typically, a singleton application running in a Pod on Kubernetes opens an outgoing connection to a message broker, relational database, file server, or other system running on the Pod or to an external system. Occasionally, however, your singleton Pod may need to accept incoming connections, and the way to enable this on Kubernetes is through Service resources.
We cover Kubernetes services in depth in the following chapter, “Service Discovery,” but we’ll briefly discuss the parts that apply to monads here. A normal Service (type: ClusterIP) creates a virtual IP and performs load balancing across all Pod instances matched by its selector. But a single instance Pod managed through StatefulSet has only one Pod and a stable network identity. In this case, it is better to create a headless service (by setting type: ClusterIP and clusterIP: None). It is called headless because such a Service has no virtual IP address, kube-proxy does not handle these Services, and the platform does not execute proxies.
However, such a service is still useful because a headless service with a selector creates endpoint records in the API server and generates DNS A records for matching Pods, so that the service’s DNS queries do not return its virtual IP, but the IP address of the supporting Pod. This allows the singleton Pod to be accessed directly through the service’s DNS record without going through the service’s virtual IP. for example, if we create a headless service named my-singleton, we can use my-singleton.default.svc.cluster.local to access the Pod’s IP address directly.
In summary, for a non-strict singleton, a ReplicaSet with one copy and a normal Service is sufficient. For strict singleton and better performance service discovery, it is better to use a StatefulSet and a headless Service. you can find a complete example in later chapter Stateful Service, where you have to change the number of replicas to one to make it a singleton.
In-Application Locks
One way to control the number of service instances in a distributed environment is through distributed locks, as shown in Figure 1-2. Whenever a service instance or a component inside an instance is activated, it can attempt to acquire a lock, and if it succeeds, the service becomes active. Any subsequent service instance that fails to acquire a lock waits and keeps trying to acquire a lock in case the currently activated service releases the lock.
Many existing distributed frameworks use this mechanism to achieve high availability and resiliency. For example, the messaging middleware Apache ActiveMQ can run in a highly available master - passive topology where data sources provide shared locks. The first instance of the middleware to start gets the lock and becomes the master, while other instances that start later become the being and wait for the lock to be released. This strategy ensures that there is a single master middleware instance and also protects against failures.
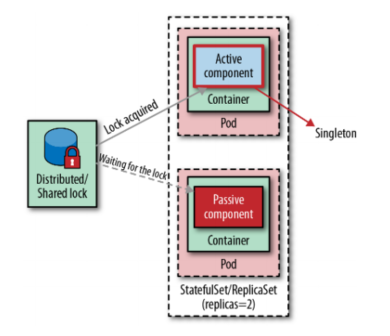
We can compare this strategy with the classical singleton in object-oriented: a singleton is an instance of an object stored in a static class variable. In this instance, the class is aware that it is a singleton, and it is written in a way that does not allow multiple instances to be instantiated for the same process. In a distributed system, this means that the containerized application itself must be written in a way that does not allow multiple active instances at the same time, regardless of the number of Pod instances launched. To achieve this in a distributed environment, we first need a distributed locking implementation such as those provided by Apache ZooKeeper, HashiCorp’s Consul, Redis, or Etcd.
A typical implementation of ZooKeeper uses temporary nodes that exist for as long as there is a client session and are deleted once the session ends. The first service instance that is started initiates a session on the ZooKeeper server and creates a temporary node that becomes the active node. All other service instances in the same cluster become the being and must wait for the temporary node to be released. This is how the ZooKeeper-based implementation ensures that there is only one master service instance in the entire cluster, ensuring master/behind failover behavior.
In the world of Kubernetes, instead of managing ZooKeeper clusters just for the locking feature, you can use the Etcd feature exposed through the Kubernetes API and running on the master node. etcd is a distributed key-value store that uses the Raft protocol to maintain its replica state. Most importantly, it provides the building blocks necessary to implement leader election, which has been implemented in a number of client libraries. For example, Apache Camel has a Kubernetes connector that also provides leader election and singleton capabilities. This connector goes a step further by not directly accessing the Etcd API, but instead uses the Kubernetes API to leverage ConfigMaps as distributed locks. It relies on the Kubernetes optimistic locking guarantee to edit resources such as ConfigMaps and can only update the ConfigMap of one Pod at a time.
The Camel implementation uses this guarantee to ensure that only one Camel routing instance is active, and that other instances must wait and obtain a lock before they can be activated. This is a custom implementation of a lock, but achieves the same goal: when there are multiple Pods using the same Camel application, only one of them becomes the master singleton and the others wait in slave mode.
An implementation using ZooKeeper, Etcd, or any other distributed lock will be similar to the one described: only one application instance becomes the leader and activates itself, while the other slave instances wait for the lock. This ensures that even if multiple Pod copies are started and all are healthy, up and running, only one service is active and performs business functions as a single instance, and the other instances are waiting to acquire a lock in case the master fails or shuts down.
od disruption scheduling
While monolithic services and leader elections attempt to limit the maximum number of instances of a service running simultaneously, Kubernetes’ Pod DisruptionBudget feature provides a complementary and somewhat opposite feature-limiting the number of instances that are down for maintenance at the same time.
At its core, PodDisruptionBudget ensures that a certain number or percentage of Pods are not voluntarily evicted from a node at any one point in time. Voluntary here means that eviction can be delayed for a specific amount of time, for example, when it is triggered by node exhaustion for maintenance or upgrades (kubectl drain), or cluster shrinkage, rather than the node becoming unhealthy, which cannot be predicted or controlled.
The PodDisruptionBudget in Example 1-1 applies to Pods that match its selector and ensures that both Pods must be available at all times.
In addition to .spec.minAvailable, there is an option to use .spec.maxUnavailable, which specifies the number of Pods in the set that can be unavailable after an eviction. You cannot specify both fields, however, and PodDisruptionBudget typically only applies to Pods managed by the controller. for Pods that are not managed by the controller (also known as bare or naked Pods), other restrictions around PodDisruptionBudget should be considered.
This feature is useful for quorum-based applications that require a minimum number of copies running at any given time to ensure quorum. Or when an application is serving critical traffic that should never fall below a certain percentage of the total number of instances. This is another primitive of Kubernetes that controls and influences runtime instance management and is worth mentioning in this chapter.
Discussion
If your use case requires strong single instance guarantees, you cannot rely on the out-of-application locking mechanism of ReplicaSets. Kubernetes ReplicaSets are designed to maintain the availability of their Pods, not to ensure the most single instance semantics of a Pod. As a result, there are many failure scenarios (e.g., when the node running a single Pod is partitioned with other nodes in the cluster, such as when replacing a deleted Pod instance with a new one) where two copies of a Pod run concurrently for a short period of time. If this is not acceptable, use StatefulSets or the locking option in the research application, which gives you more control over the leader election process and provides stronger guarantees. The latter can also prevent accidental scaling of Pods by changing the number of replicas.
In other cases, only a portion of a containerized application should be a singleton. For example, there may be a containerized application that provides an HTTP endpoint that can safely scale to multiple instances, but there is also a polling component that must be a singleton. Using an out-of-application locking approach would prevent scaling to the entire service. Also, as a result, we either split the singleton component in its deployment unit so that it maintains its singleton identity (good in theory, but not always practical and worth the overhead), or use an in-app locking mechanism that locks only the components that must be singleton. This will allow us to transparently scale the entire application, allowing HTTP endpoints to scale and letting other parts act as master - monads.