It is the essence of an operating system to provide the ability to run programs. And in Linux, light and correspondingly fast process management is one of its good features. In this article, the focus is on the description, and life cycle of Linux processes.
Descriptors and task structures
A process is a program in execution and usually includes some resources, such as files, pending signals, internal kernel data, processor state, memory space, and one or more threads of execution. Therefore, a process can be considered as a collection of executable programs and computer resources.
Process descriptions
In the Linux kernel, there is a two-way circular chain called a task list that is used to hold the process description (as will be discussed later, Linux threads are not distinguished from processes, and the task queue is also used to hold the thread description). Each element of the list is a structure of type task_struct (defined in linux/sched.h), task_struct is relatively large, about 1.7KB in size on a 32-bit machine, and contains data that completely describes an executing program: open files, address space, signals, status, etc. signals, status, etc.
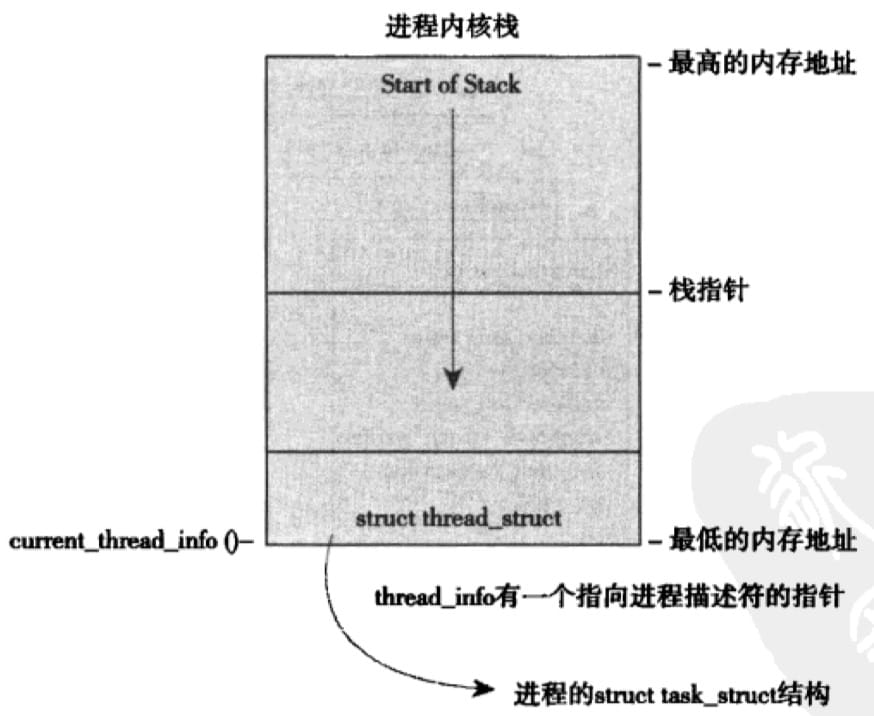
Linux allocates the task_struct structure through the slab allocator. Prior to 2.6, the task_struct of each process was stored at the end of their kernel stack, which allowed hardware architectures with fewer registers, such as x86, to calculate its location simply by using the stack pointer. A thread_info (defined in asm/thread_info.h) is kept, which records basic information about the executing thread and keeps a pointer to the task_struct in the task field.
Linux allocates the task_struct structure through the slab allocator. Prior to 2.6, the task_struct of each process was stored at the end of their kernel stack, which allowed hardware architectures with fewer registers, such as x86, to calculate its location simply by using the stack pointer. A thread_info (defined in asm/thread_info.h) is kept, which records basic information about the executing thread and keeps a pointer to the task_struct in the task field.
PID
The kernel represents each process by a unique process identification value (PID), which is a macro of type pid_t, actually a short int (short type for compatibility, maximum value is only 32768), for how big the PID is It is actually limited by the definition in linux/threads.h and can be increased up to 4 million by modifying /proc/sys/kernel/pid_max. But considering that process descriptions are stored in a two-way circular chain table, fewer processes means a faster turn, and a huge number of processes does not mean a good thing.
The state of a process
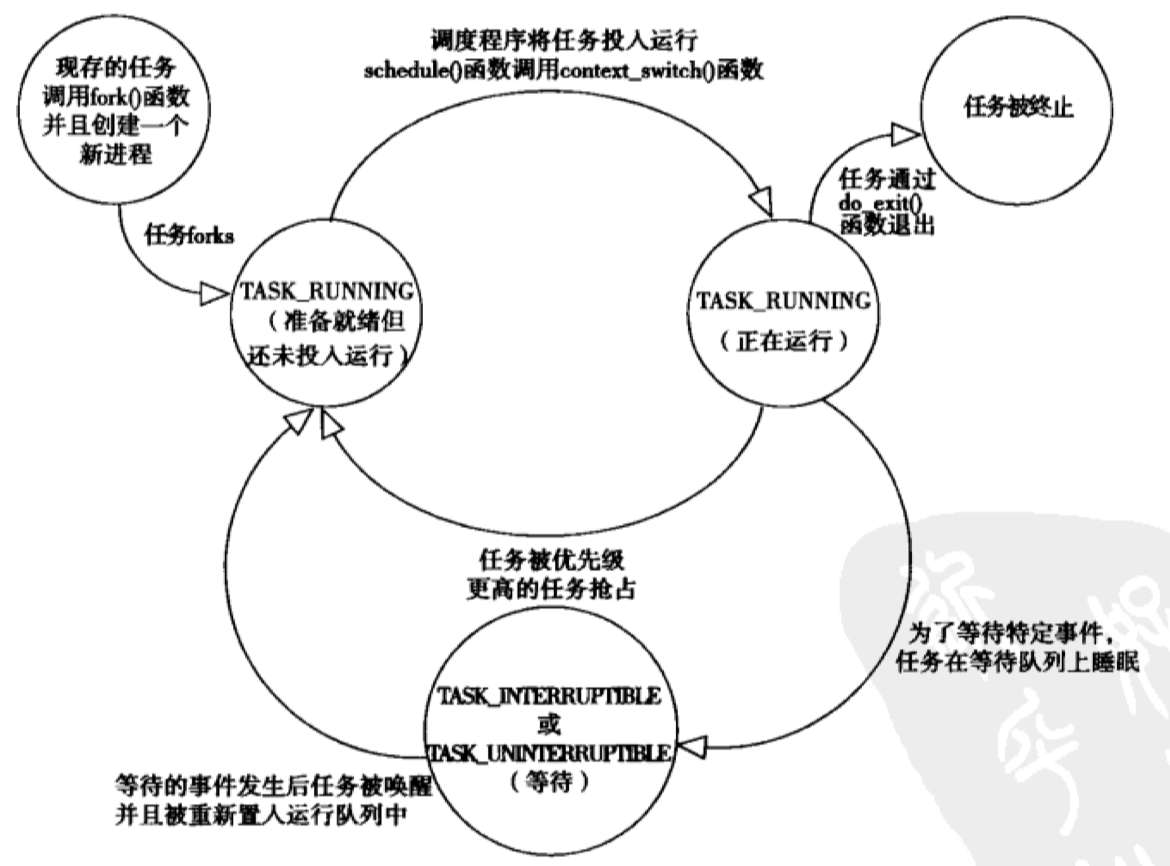
In task_struct, state is used exclusively to describe the current state of a process, and every process in the system must be in one of the following five states.
- TASK_RUNNING (running)
- TASK_INTERRUPTIBLE (interruptible)
- TASK_UNINTERRUPTIBLE (non-interruptible)
- __TASK_TRACED (tracked by other processes)
- __TASK_STOPPED (stopped)
The TASK_RUNNING state means that the process is available for execution, perhaps the process is executing or waiting to be executed in the run queue (covered later in Process Scheduling), and only in this state is the process available for execution.
The TASK_INTERRUPTIBLE state means that the process is dormant, perhaps because it is blocked, or waiting for certain conditions to be met.
TASK_UNINTERRUPTIBLE is similar to TASK_INTERRUPTIBLE, but the difference is that the process is not woken up or ready to run even if it receives a signal. A process in this state can be in an undisturbed state, waiting for certain conditions to be completed, such as at the beginning of the process creation, when it has not completed initialization.
__TASK_TRACED implies being tracked by other processes, e.g. by debugger processes.
__TASK_STOPPED means that the process has stopped execution, for example, when receiving SIGSTOP, SIGTSTP, SIGTTIN, SIGTTOU, etc. In addition, any signal received during the debugging period will enter this state. More on what happens when a process stops will be covered later.
Contexts and family trees
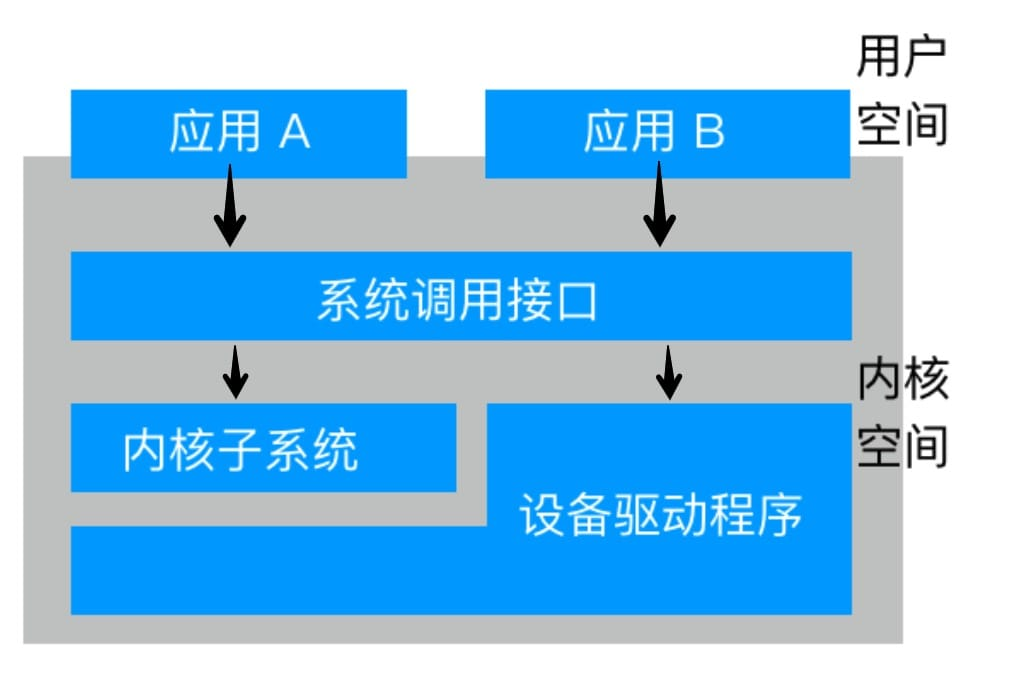
Generally programs execute in user space, but when a program executes a system call or triggers an exception, it falls into kernel space, at which point it is called the kernel “executing on behalf of the process” and is in process context. In general, on kernel exit, programs revert to user space to continue execution, and system calls and exception system calls and exception handlers are explicitly defined interfaces to the kernel through which processes can only fall into kernel execution, i.e., all accesses to the kernel must be through these interfaces. The system calls will be covered in a separate article later.
There is an obvious inheritance relationship between processes on Unix systems, as well as on Linux systems, where all processes are descendants of the init process with a PID of 1. The init process is the first process started at the end of the system boot process. This process is responsible for reading the system’s initialization script and executing other related programs to complete the final process of system booting.
Except for the init process, each process of the system must have a parent process, and each process can also have zero to multiple child processes. The tree-like relationship presented between processes makes two child processes with the same parent process called “brothers”. The relationships of processes are stored in process descriptors, and each task_struct contains a pointer to its parent process task_struct (known as the parent pointer). It also contains a chain of child processes called children. With this data structure, it is possible to traverse the entire family tree that exists in the system from the task_struct of any process.
Process creation
Unix systems are unique in that all other systems provide a Spawn process mechanism that first creates a process in a new address space, reads in the executable, and ideally starts execution. This is an intuitive way to create processes, but Unix takes a different approach by splitting the process into two steps (into two separate functions), fork and exec.
First fork() creates a child process by copying the current process, which differs from the parent process only by its PID (process ID), PPID (PID of the parent process), some resources and statistics (resources that are unnecessarily inherited, such as hung signals). Besides, the newly created child process will use the resources of the parent process directly (by pointing the relevant pointer directly to the resources of the parent process). The exec() function is responsible for reading the executable and loading it into the address space to start running. Using these two functions together can do what other systems can do with the spawn function alone.
Linux’s fork() is implemented using copy-on-wirte pages, which means that copying the data of the parent process can be deferred or even eliminated when creating a child process. Instead of copying the entire process address space at fork time, the kernel lets the parent and child processes share the same copy, and only when it is time to write, the data is copied, so that each process has its own copy. In other words, resources are copied only when they need to be written, until then, they are shared in a read-only manner. So the only real overhead of fork is copying the page table of the parent process and creating unique process descriptors for the child processes. Linux also does a clever optimization by running an executable immediately after the process is created, i.e. the child process is executed first, thus avoiding the parent process modifying the memory space and triggering a copy on write.
Linux implements fork through the clone() system call, while the fork() vfork() and __clone() functions all call the clone() system call with different arguments, and clone() does most of the work of fork through do_frok() (defined in kernel/fork.c). fork most of the work.
do_frok() prefers to call the copy_process function to copy the process and get it running, and the copy_process function is a concrete implementation of the Linux copy process:
copy_processfirst callsdup_task_struck()to create the kernel stack,thread_infostructure andtask_structfor the child process, which are currently identical to the parent process.- Check and make sure that the number of processes owned by the user does not exceed the allocated resource limit after creating the child process.
- Proceed to distinguish the child process from the parent process, and zero out or initialize the non-inheritable members of the process descriptor.
- set the process state to TASK_UNINTERRUPTIBLE to avoid being put into operation.
- Call
copy_flags()to update the flag variables oftask_struct, for example, PF_SUPERPRIV, which indicates whether the process has superuser privileges, is cleared, and PF_FORKNOEXEC, which indicates that the process did not call the exec() function, is set. - call
alloc_pid()to get a valid PID - copy or share open files, file system information, signal handling functions, process address space, namespace, etc. based on the arguments obtained from the
clone()system call. - Finally,
copy_processdoes some finishing work and returns a pointer to the child process.
At this point, runtime returns to do_frok(), which checks the pointer returned by copy_process and puts the child process into operation, giving it priority over the parent process, as mentioned above. The creation of a child process is now complete.
Threads
The thread mechanism is an abstraction commonly used in modern programming technology that provides the same set of threads running in a shared memory address space within the same program. These threads can also share other resources such as open files, but as mentioned above, there is no concept of threads from the Linux kernel’s point of view, which is related to the Linux threads implementation.
Linux does not have a special scheduling algorithm or a special data structure for threads, but is considered as a process that shares some resources with other processes. Each thread has its own unique task_struct, and from the kernel’s point of view, it is a normal process (only the thread shares some resources with some other processes).
Therefore, the implementation of threads in Linux is very different from that of other operating systems such as Windows, which provide a dedicated mechanism for supporting threads in the kernel (these systems often refer to threads as lightweight processes). The phrase “lightweight processes” is itself an expression of how Linux differs from other systems. Whereas in other systems threads are abstracted as a unit of execution that consumes fewer resources and runs faster than heavy processes, in Linux processes themselves are lightweight enough and threads are simply a means of sharing resources between processes.
Therefore, threads are also created by the clone() system call, except that some arguments are passed to the clone() call to mark the resources to be shared.
In addition to user-space threads, the kernel often needs to perform some operations in the background, which are usually done through kernel threads. Kernel threads are standard processes that run independently in kernel space. The difference between kernel threads and normal processes is that kernel threads do not have a separate address space (the mm pointer to the address space is NULL), they run only in kernel space and never switch to user space, and kernel processes can be scheduled and preempted just like normal processes.
Kernel threads can be viewed on Linux via ps -ef. Kernel threads can only be created via kernel threads, and the kernel creates all new kernel threads by deriving them from the kthreadd kernel process, whose interface is declared in linux/kthread.h. Kernel threads are started and run until do_exit() is called, or kthread_stop() is called by other parts of the kernel, and the end of a thread or process is described below.
Ending of processes
When a process (thread) terminates, the kernel must release the resources it occupies and inform its parent process, and these two steps complete the resource release and deletion of the process descriptor.
Freeing resources
Generally, the end of a process is caused by itself, e.g. by executing exit(). But whether active or passive, the end of a process relies on the do_exit() function (defined in kernel/exit.c) to perform some cleanup tasks.
- set the flag member of
task_structto PF_EXITING - call
del_timer_sync()to remove the kernel timer to ensure that no timers are queued and no timer handlers are running. - output the bookkeeping information if the process bookkeeper function of BSD is enabled.
- call
exit_mm()to release the process-occupiedmm_struct, or to release it completely if no other process is sharing it. - call
sem_exit()to get the process out of the queue if it is queued for an IPC signal. - call
exit_file()andexit_fs()to decrement the reference count of file descriptors and file system data, respectively, and release them completely if the reference count decreases to zero. - Set the exit_code member stored in
task_structto the exit code provided by theexit()function. - Call
exit_notify()to signal the parent process and find a foster parent for the child process of the exiting process (the foster parent is any other process in the thread group or the init process), and set the process state of the exiting process to EXIT_ZOMBIE, i.e., the dead state. - Call
schedule()to release execution rights, because the process has been set to the dead state, so the process will never be executed again anddo_exit()will never return.
At this point, all the resources of the process have been released, but the task_struct of the process is kept until the parent process executes the wait() function in order to make it easier for the parent process to query the status of the exiting process (exit code, etc.).
Deleting process descriptors
The wait() family of functions is implemented by the unique system call wait4(), which implements a process that hangs itself until one of its children exits, at which point the function returns the PID of that child process. in addition, the pointer provided when the function is called contains the exit code of the child when it exits.
When it is finally time to release the process descriptor, release_task() will be called and perform the following tasks.
- call
__exit_signal()which calls_unhash_process()which in turn callsdetach_pid()which removes the process from the pidhash and also removes the process from the task list. _exit_signal()releases all remaining resources used by the currently dead process, and does the final count and logging.- If this process is the last process in the thread group and the lead process has died, proceed to notify the parent process of the dead lead process.
- Call
put_task_struct()to free the process kernel stack and the pages occupied by thethread_infostructure, and to free the slab cache occupied bytask_struct.
At this point, the process descriptors and process exclusive resources are all freed.
Orphaned processes
If the parent process exits before the child process does, there must be a mechanism to ensure that the child process finds a new father, otherwise these orphaned processes will be frozen forever on exit. The system iterates through the other processes in the thread group where the process is located to find a foster father, and if there are no other processes in the thread group, he is hung up on the init process.
Once the system has successfully found and set up a new parent for the process, there is no risk of a resident dead process, and the init process will routinely call wait() to check on its children and remove any dead processes associated with it.
Summary
Processes are a very basic and critical abstraction that lies at the heart of every modern operating system. This article describes the basic concept of processes and their lifecycle by introducing them, and the next article will describe what they look like when they are running by introducing their scheduling.