mmap is a very common system call in user space, whether it is allocating memory, reading and writing large files, linking dynamic library files, or sharing memory between multiple processes. This article first introduces the process address space and mmap, then analyzes the kernel code to understand its implementation, and finally deepens the understanding of mmap with a simple demo driver example.
Process address space and vma
As a pre-knowledge, let’s start with a brief introduction to process address space to better understand what follows. Modern operating systems cannot manage memory without hardware support, such as segmentation mechanisms and paging mechanisms. They are used for memory isolation, protection and efficient use. The address space between processes is isolated from each other, and each process has a set of page tables that implement the conversion from linear to physical addresses.
Virtual Memory Mapping
The following is the process address space layout for a 32-bit system (x86)
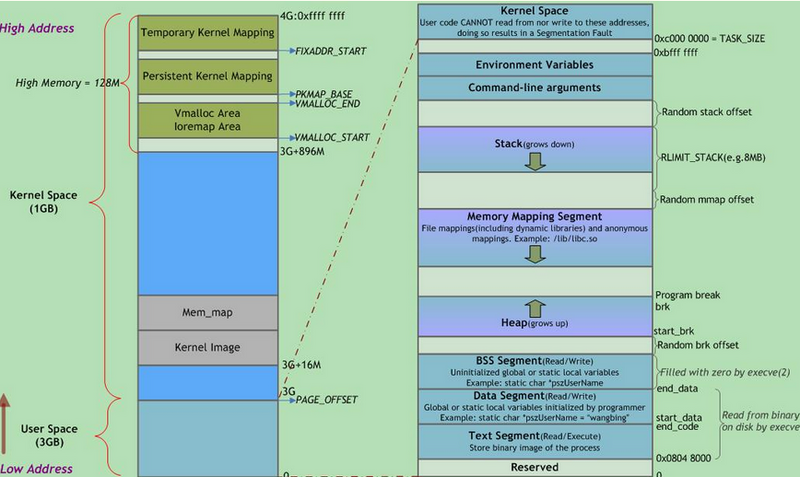
The 0 to 3G section is the user space address, and the 3G to 4G section is the kernel address space. The virtual addresses from low to high are code segment, data segment (initialized static variables), bss segment (uninitialized static variables), heap heap, mmap mapped area, stack, command line parameters, and environment variables.
Starting from 0xc0000000 is the kernel address space. The kernel address space is further divided into linear memory area and high end memory area. The high end memory area is used for the vmalloc mechanism, fixmap, etc. In x86 systems, the minimum 16MB of physical memory is the DMA memory area, which is used to perform DMA operations.
On 64-bit systems (x86_64), the available space for memory addresses is 0x0000000000000000 ~ 0xFFFFFFFFFFFFFFFF, which is a very large address space. Linux actually uses only the lower 47 bits (128T) and the upper 17 bits for expansion. The actual address space used is 0x0000000000000000 ~ 0x00007FFFFFFFFFFF (user space) and 0xFFFF800000000000 ~ 0xFFFFFFFFFFFFFFFFFFFF (kernel space).
In 64-bit processors, there is no need for high-end memory as a management area since there is enough kernel space to map physical memory linearly. More detailed information can be found in the kernel documentation.
VMA
Process address spaces are described in the Linux kernel using struct vm_area_struct, or VMA for short. Since these address spaces are attributed to individual user processes, they have corresponding members in the struct mm_struct of the user process. Processes can dynamically add or remove these memory areas through the kernel’s memory management mechanism.
Each memory area has associated permissions, such as readable, writable, and executable. If a process accesses a memory area that is not in the valid range, or if it accesses memory illegally, then the processor will report a missing page exception, or in severe cases, a segment error.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
|
// include/linux/mm_types.h
/*
* This struct defines a memory VMM memory area. There is one of these
* per VM-area/task. A VM area is any part of the process virtual memory
* space that has a special rule for the page-fault handlers (ie a shared
* library, the executable area etc).
*/
struct vm_area_struct {
/* The first cache line has the info for VMA tree walking. */
unsigned long vm_start; /* Our start address within vm_mm. */
unsigned long vm_end; /* The first byte after our end address
within vm_mm. */
/* linked list of VM areas per task, sorted by address */
struct vm_area_struct *vm_next, *vm_prev;
struct rb_node vm_rb;
/*
* Largest free memory gap in bytes to the left of this VMA.
* Either between this VMA and vma->vm_prev, or between one of the
* VMAs below us in the VMA rbtree and its ->vm_prev. This helps
* get_unmapped_area find a free area of the right size.
*/
unsigned long rb_subtree_gap;
/* Second cache line starts here. */
struct mm_struct *vm_mm; /* The address space we belong to. */
pgprot_t vm_page_prot; /* Access permissions of this VMA. */
unsigned long vm_flags; /* Flags, see mm.h. */
/*
* For areas with an address space and backing store,
* linkage into the address_space->i_mmap interval tree.
*/
struct {
struct rb_node rb;
unsigned long rb_subtree_last;
} shared;
/*
* A file's MAP_PRIVATE vma can be in both i_mmap tree and anon_vma
* list, after a COW of one of the file pages. A MAP_SHARED vma
* can only be in the i_mmap tree. An anonymous MAP_PRIVATE, stack
* or brk vma (with NULL file) can only be in an anon_vma list.
*/
struct list_head anon_vma_chain; /* Serialized by mmap_sem &
* page_table_lock */
struct anon_vma *anon_vma; /* Serialized by page_table_lock */
/* Function pointers to deal with this struct. */
const struct vm_operations_struct *vm_ops;
/* Information about our backing store: */
unsigned long vm_pgoff; /* Offset (within vm_file) in PAGE_SIZE
units */
struct file * vm_file; /* File we map to (can be NULL). */
void * vm_private_data; /* was vm_pte (shared mem) */
atomic_long_t swap_readahead_info;
#ifndef CONFIG_MMU
struct vm_region *vm_region; /* NOMMU mapping region */
#endif
#ifdef CONFIG_NUMA
struct mempolicy *vm_policy; /* NUMA policy for the VMA */
#endif
struct vm_userfaultfd_ctx vm_userfaultfd_ctx;
} __randomize_layout;
|
Explain a few key members.
- vm_start and vm_end: denote the start and end addresses of vma, subtracting them is the length of vma
- vm_next and vm_prev: chain table pointers
- vm_rb: red-black tree node
- vm_mm: memory descriptor mm_struct data structure of the process it belongs to
- vm_page_prot: access rights of vma
- vm_flags: flags of vma
- anon_vma_chain and anon_vma: used to manage RMAP reverse mapping
- vm_ops: points to the operation method structure
- vm_pgoff: offset of the file mapping.
- vm_file: points to the mapped file
mmap introduction
1
2
3
|
// include<sys/mman.h>
void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset);
int munmap(void *addr, size_t length);
|
- addr: specify the starting address, generally set to NULL for portability
- length: indicates the size of the mapped process address space
- prot: read and write attributes, PROT_EXEC, PROT_READ, PROT_WRITE, PROT_NONE
- flags: flags, such as shared mapping, private mapping
- fd: file descriptor, set to -1 for anonymous mapping.
- offset: for file mapping, indicates offset
flag flag
- MAP_SHARED: create a shared mapping area. Multiple processes can map the same file in this way, and the modified content will be synchronized to the disk file.
- MAP_PRIVATE: Creates a private mapping for copy-on-write. Multiple processes can map the same file privately, and the modifications are not synchronized to disk.
- MAP_ANONYMOUS: Creates anonymous mappings, i.e., mappings that are not associated with a file.
- MAP_FIXED: Creates a mapping with the parameter addr, and returns failure if the specified address cannot be mapped. addr requires page alignment. If the specified address space overlaps with an existing VMA, the overlapping area will be destroyed first.
- MAP_POPULATE: For file mapping, it will pre-read the file content to the mapping area in advance, this feature only supports private mapping.
4 types of mappings
Depending on the different combinations of prot and flags, there are 4 types of mappings as follows.
- private anonymous: usually used for memory allocation (large blocks)
- private file: usually used for loading dynamic libraries
- Shared anonymous: usually used for sharing memory between processes, with the special device file
/dev/zero open by default
- Shared files: usually used for memory mapping I/O, inter-process communication
mmap memory mapping principle
- When mmap is called in user space, the system looks for a contiguous segment of virtual addresses that meet the requirements and then creates a new vma to insert into the mm system’s chain and red-black tree.
- Call kernel space mmap to establish a mapping between the physical address of the file block/device and the process virtual address vma
- If it is a disk file, this is just to establish the mapping without actually allocating memory if no special flags are set.
- If it is a device file, the mapping from the device physical address to the virtual address is established directly by the remap_pfn_range function.
- (If it is a disk file mapping) When the process accesses this mapped address space, a page-out exception is raised and the data is copied from disk to physical memory. The user space can then read and write directly to this physical memory in the kernel space, eliminating the need for a copy between the user space and the kernel space.
Kernel code analysis
When we call mmap in user space, we first enter the kernel space through a system call, and we can see that here the offset is converted to a page-based unit.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
// arch/x86/kernel/sys_x86_64.c
SYSCALL_DEFINE6(mmap, unsigned long, addr, unsigned long, len,
unsigned long, prot, unsigned long, flags,
unsigned long, fd, unsigned long, off)
{
long error;
error = -EINVAL;
if (off & ~PAGE_MASK)
goto out;
error = sys_mmap_pgoff(addr, len, prot, flags, fd, off >> PAGE_SHIFT);
out:
return error;
}
|
Look at the system call sys_mmap_pgoff, if it is not an anonymous map, it will get the file structure via fd.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
// mm/mmap.c
SYSCALL_DEFINE6(mmap_pgoff, unsigned long, addr, unsigned long, len,
unsigned long, prot, unsigned long, flags,
unsigned long, fd, unsigned long, pgoff)
{
struct file *file = NULL;
unsigned long retval;
if (!(flags & MAP_ANONYMOUS)) {
// ...
file = fget(fd);
// ...
}
// ...
retval = vm_mmap_pgoff(file, addr, len, prot, flags, pgoff);
return retval;
}
|
Then look at the vm_mmap_pgoff function, which mainly uses a semaphore to do a protection of the process address space, then according to the value of populate will prefault the page table, and if it is a file map then it will preread the file.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
// mm/util.c
unsigned long vm_mmap_pgoff(struct file *file, unsigned long addr,
unsigned long len, unsigned long prot,
unsigned long flag, unsigned long pgoff)
{
unsigned long ret;
struct mm_struct *mm = current->mm;
unsigned long populate;
LIST_HEAD(uf);
ret = security_mmap_file(file, prot, flag);
if (!ret) {
if (down_write_killable(&mm->mmap_sem))
return -EINTR;
ret = do_mmap_pgoff(file, addr, len, prot, flag, pgoff,
&populate, &uf);
up_write(&mm->mmap_sem);
userfaultfd_unmap_complete(mm, &uf);
if (populate)
mm_populate(ret, populate);
}
return ret;
}
|
do_mmap_pgoff is simply a call to do_mmap.
1
2
3
4
5
6
7
8
9
|
// include/linux/mm.h
static inline unsigned long
do_mmap_pgoff(struct file *file, unsigned long addr,
unsigned long len, unsigned long prot, unsigned long flags,
unsigned long pgoff, unsigned long *populate,
struct list_head *uf)
{
return do_mmap(file, addr, len, prot, flags, 0, pgoff, populate, uf);
}
|
Let’s look at the do_mmap implementation.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
// mm/mmap.c
unsigned long do_mmap(struct file *file, unsigned long addr,
unsigned long len, unsigned long prot,
unsigned long flags, vm_flags_t vm_flags,
unsigned long pgoff, unsigned long *populate,
struct list_head *uf)
{
struct mm_struct *mm = current->mm;
// ...
len = PAGE_ALIGN(len);
// ...
addr = get_unmapped_area(file, addr, len, pgoff, flags);
// ...
addr = mmap_region(file, addr, len, vm_flags, pgoff, uf);
if (!IS_ERR_VALUE(addr) &&
((vm_flags & VM_LOCKED) ||
(flags & (MAP_POPULATE | MAP_NONBLOCK)) == MAP_POPULATE))
*populate = len;
return addr;
}
|
This function mainly aligns the mapped length pages, checks and processes the prot attribute and flags flags, and sets the vm_flags. The get_unmapped_area function checks the specified address or automatically selects an available virtual address. Then mmap_region is called, and you can see that after returning, populate is set according to the flags set when the interface was called. If MAP_LOCKED is set, or if MAP_POPULATE is set but MAP_NONBLOCK is not, then the prefault operation mentioned earlier is performed.
Then continue to mmap_region.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
// mm/mmap.c
unsigned long mmap_region(struct file *file, unsigned long addr,
unsigned long len, vm_flags_t vm_flags, unsigned long pgoff,
struct list_head *uf)
{
// ...
vma = vma_merge(mm, prev, addr, addr + len, vm_flags,
NULL, file, pgoff, NULL, NULL_VM_UFFD_CTX);
if (vma) // 可以跟之前的映射合并
goto out;
vma = kmem_cache_zalloc(vm_area_cachep, GFP_KERNEL);
vma->vm_mm = mm;
vma->vm_start = addr;
vma->vm_end = addr + len;
vma->vm_flags = vm_flags;
vma->vm_page_prot = vm_get_page_prot(vm_flags);
vma->vm_pgoff = pgoff;
INIT_LIST_HEAD(&vma->anon_vma_chain);
if (file) {
// ...
vma->vm_file = get_file(file);
error = call_mmap(file, vma); // 调用文件的mmap
//...
} else if (vm_flags & VM_SHARED) {
error = shmem_zero_setup(vma);
}
// ...
return addr;
// ...
}
|
This function first does some address space checks, then vma_merge checks if it can be merged with the old mapping, then it allocates the vma and initializes it. If it’s a file map, call call_mmap; if it’s an anonymous shared map, call shmem_zero_setup, which does /dev/zero file-related setup.
call_mmap simply calls the mmap operation function in the file handle.
1
2
3
4
5
|
// include/linux/fs.h
static inline int call_mmap(struct file *file, struct vm_area_struct *vma)
{
return file->f_op->mmap(file, vma);
}
|
If it is a file in a normal file system, we take ext4 as an example, which mainly sets vma->vm_ops to ext4_file_vm_ops.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
// fs/ext4/file.c
static int ext4_file_mmap(struct file *file, struct vm_area_struct *vma)
{
//...
vma->vm_ops = &ext4_file_vm_ops;
//...
return 0;
}
static const struct vm_operations_struct ext4_file_vm_ops = {
.fault = ext4_filemap_fault,
.map_pages = filemap_map_pages,
.page_mkwrite = ext4_page_mkwrite,
};
|
Later when this vma address space is accessed, the corresponding operation function is called to handle it, for example, the page error handling function will call ext4_filemap_fault, which in turn will call filemap_fault.
If it is a device file, the corresponding device driver implements the mmap method to establish the mapping from the device physical memory to the vma address space inside. The next step is to demonstrate this with a simple driver demo.
To briefly summarize
1
2
3
4
5
6
7
8
9
|
mmap // offset转成页为单位
+-- sys_mmap_pgoff // 通过fd获取file
+-- vm_mmap_pgoff // 信号量保护,映射完成后populate
+-- do_mmap_pgoff // 简单封装
+-- do_mmap // 映射长度页对齐,prot和flags检查,设置vm_flags,获取映射虚拟地址
+-- mmap_region // 地址空间检查,vma_merge,vma分配及初始化
|-- call_mmap // 文件映射,简单封装
| +-- file->f_op->mmap // 调用实际文件的mmap方法
|-- shmem_zero_setup // 匿名共享映射,/dev/zero
|
driver demo
We wrote a simple misc device, using alloc_pages to allocate the physical memory of the device (4 pages) when the driver is loaded, but of course you can also use kmalloc or vmalloc. Then we implemented several operation methods, the main one is the mmap method, and for testing purposes we also implemented read, write, and The main method is the mmap method, in order to facilitate testing we also implemented read, write, llseek and other methods.
ps: driver and test program code has been uploaded to github, catbro666/mmap-driver-demo
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
|
#include <linux/init.h>
#include <linux/module.h>
#include <linux/fs.h>
#include <linux/mm.h>
#include <linux/gfp.h> // alloc_page
#include <linux/miscdevice.h> // miscdevice misc_xxx
#include <linux/uaccess.h> // copy_from/to_user
#define DEMO_NAME "demo_dev"
#define PAGE_ORDER 2
#define MAX_SIZE (PAGE_SIZE << PAGE_ORDER)
static struct device *mydemodrv_device;
static struct page *page = NULL;
static char *device_buffer = NULL;
static const struct file_operations demodrv_fops = {
.owner = THIS_MODULE,
.open = demodrv_open,
.release = demodrv_release,
.read = demodrv_read,
.write = demodrv_write,
.mmap = demodev_mmap,
.llseek = demodev_llseek
};
static struct miscdevice mydemodrv_misc_device = {
.minor = MISC_DYNAMIC_MINOR,
.name = DEMO_NAME,
.fops = &demodrv_fops,
};
static int __init demo_dev_init(void)
{
int ret;
ret = misc_register(&mydemodrv_misc_device);
if (ret) {
printk("failed to register misc device");
return ret;
}
mydemodrv_device = mydemodrv_misc_device.this_device;
printk("succeeded register misc device: %s\n", DEMO_NAME);
page = alloc_pages(GFP_KERNEL, PAGE_ORDER);
if (!page) {
printk("alloc_page failed\n");
return -ENOMEM;
}
device_buffer = page_address(page);
printk("device_buffer physical address: %lx, virtual address: %px\n",
page_to_pfn(page) << PAGE_SHIFT, device_buffer);
return 0;
}
static void __exit demo_dev_exit(void)
{
printk("removing device\n");
__free_pages(page, PAGE_ORDER);
misc_deregister(&mydemodrv_misc_device);
}
module_init(demo_dev_init);
module_exit(demo_dev_exit);
MODULE_AUTHOR("catbro666");
MODULE_LICENSE("GPL v2");
MODULE_DESCRIPTION("mmap test module");
|
Let’s look at the implementation of the mmap method. The core function is remap_pfn_range, which is used to create a mapping of actual physical addresses to vma virtual addresses. The first one is the user space vma to be mapped, the second one is the starting address of the mapping, the third one is the physical page frame number of the kernel memory, the fourth one is the size of the mapped area, and the fifth one is the page protection flag for this mapping.
Most of the parameters we use are obtained through vma, and as seen in the previous section, the outer function has already done the vma initialization. Since we are allocating memory with alloc_pages, whose physical addresses are contiguous, the mapping is also relatively simple.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
static int demodev_mmap(struct file *file, struct vm_area_struct *vma)
{
struct mm_struct *mm;
unsigned long size;
unsigned long pfn_start;
void *virt_start;
int ret;
mm = current->mm;
pfn_start = page_to_pfn(page) + vma->vm_pgoff;
virt_start = page_address(page) + (vma->vm_pgoff << PAGE_SHIFT);
/* 映射大小不超过实际分配的物理内存大小 */
size = min(((1 << PAGE_ORDER) - vma->vm_pgoff) << PAGE_SHIFT,
vma->vm_end - vma->vm_start);
printk("phys_start: 0x%lx, offset: 0x%lx, vma_size: 0x%lx, map size:0x%lx\n",
pfn_start << PAGE_SHIFT, vma->vm_pgoff << PAGE_SHIFT,
vma->vm_end - vma->vm_start, size);
if (size <= 0) {
printk("%s: offset 0x%lx too large, max size is 0x%lx\n", __func__,
vma->vm_pgoff << PAGE_SHIFT, MAX_SIZE);
return -EINVAL;
}
// 外层vm_mmap_pgoff已经用信号量保护了
ret = remap_pfn_range(vma, vma->vm_start, pfn_start, size, vma->vm_page_prot);
if (ret) {
printk("remap_pfn_range failed, vm_start: 0x%lx\n", vma->vm_start);
}
else {
printk("map kernel 0x%px to user 0x%lx, size: 0x%lx\n",
virt_start, vma->vm_start, size);
}
|
Let’s look at the implementation of the read method, which mainly copies data from the device memory to the buf in user space and then updates the file offset. The write method is similar, so we won’t show it here.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
static ssize_t
demodrv_read(struct file *file, char __user *buf, size_t count, loff_t *ppos)
{
int actual_readed;
int max_read;
int need_read;
int ret;
max_read = PAGE_SIZE - *ppos;
need_read = max_read > count ? count : max_read;
if (need_read == 0)
dev_warn(mydemodrv_device, "no space for read");
ret = copy_to_user(buf, device_buffer + *ppos, need_read);
if (ret == need_read)
return -EFAULT;
actual_readed = need_read - ret;
*ppos += actual_readed;
printk("%s actual_readed=%d, pos=%lld\n", __func__, actual_readed, *ppos);
return actual_readed;
}
|
Test program
Installing the driver
We first compile and install the driver and the device node file has been created automatically. Checking the kernel logs you can see that the device has been successfully created and memory has been allocated. The starting physical address is 0x5b1558000 and the kernel virtual address is 0xffff8d1ab1558000.
1
2
3
4
5
6
|
$ sudo insmod mydemodev.ko
$ ll /dev|grep demo
crw------- 1 root root 10, 58 12月 12 23:33 demo_dev
$ dmesg | tail -n 2
[110047.799513] succeeded register misc device: demo_dev
[110047.799517] device_buffer physical address: 5b1558000, virtual address: ffff8d1ab1558000
|
Test program 1
Next, we wrote several test programs to test this driver. First of all, we open the driver device file /dev/demo_dev, and then mmap the size of 1 page, here we sleep 5 seconds before and after respectively, in order to provide observation time. Then we performed a read and write test with the mapped user space virtual address to verify that mmap was mapped correctly. First write by virtual address, followed by read with read for comparison check. Then write by write, followed by read with virtual address for comparison check.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
|
// test1.c
#include <stdio.h> // printf
#include <fcntl.h> // open
#include <unistd.h> // read, close, getpagesize
#include <sys/mman.h> // mmap
#include <string.h> // memcmp, strlen
#include <assert.h> // assert
#define DEMO_DEV_NAME "/dev/demo_dev"
int main()
{
char buf[64];
int fd;
char *addr = NULL;
int ret;
char *message = "Hello World\n";
char *message2 = "I'm superman\n";
fd = open(DEMO_DEV_NAME, O_RDWR);
if (fd < 0) {
printf("open device %s failed\n", DEMO_DEV_NAME);
return -1;
}
sleep(5);
addr = mmap(NULL, (size_t)getpagesize(), PROT_READ | PROT_WRITE,
MAP_SHARED | MAP_LOCKED, fd, 0);
sleep(5);
/* 测试映射正确 */
/* 写到mmap映射的虚拟地址中,通过read读取设备文件 */
ret = sprintf(addr, "%s", message);
assert(ret == strlen(message));
ret = read(fd, buf, 64);
assert(ret == 64);
assert(!memcmp(buf, message, strlen(message)));
/* 通过write写入设备文件,修改体现在mmap映射的虚拟地址 */
ret = write(fd, message2, strlen(message2));
assert(ret == strlen(message2));
assert(!memcmp(addr + 64, message2, strlen(message2)));
munmap(addr, (size_t)getpagesize());
close(fd);
return 0;
}
|
We compile and run the test program and the result is as we expected. From the kernel log, we can see that the mapping starts at physical address 0x5b1558000 with an offset of 0. The vma size is 1 page, and the mapping size is also 1 page. The kernel space virtual address 0xffff8d1ab1558000 is mapped to user space 0x7f21c0f58000.
1
2
3
4
5
6
|
$ sudo ./test1
$ dmesg|tail -n 4
[110691.745381] phys_start: 0x5b1558000, offset: 0x0, vma_size: 0x1000, map size:0x1000
[110691.745388] map kernel 0xffff8d1ab1558000 to user 0x7f21c0f58000, size: 0x1000
[110696.745816] demodrv_read actual_readed=64, pos=64
[110696.745822] demodrv_write actual_written=13, pos=77
|
Meanwhile, we use pmap to observe the address space of the process before and after mmap.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
|
$ sudo pmap -x $(pgrep test1)
[sudo] password for ssl:
30830: ./test1
Address Kbytes RSS Dirty Mode Mapping
0000557b19475000 4 4 0 r-x-- test1
0000557b19475000 0 0 0 r-x-- test1
0000557b19676000 4 4 4 r---- test1
0000557b19676000 0 0 0 r---- test1
0000557b19677000 4 4 4 rw--- test1
0000557b19677000 0 0 0 rw--- test1
00007f21c0941000 1948 888 0 r-x-- libc-2.27.so
00007f21c0941000 0 0 0 r-x-- libc-2.27.so
00007f21c0b28000 2048 0 0 ----- libc-2.27.so
00007f21c0b28000 0 0 0 ----- libc-2.27.so
00007f21c0d28000 16 16 16 r---- libc-2.27.so
00007f21c0d28000 0 0 0 r---- libc-2.27.so
00007f21c0d2c000 8 8 8 rw--- libc-2.27.so
00007f21c0d2c000 0 0 0 rw--- libc-2.27.so
00007f21c0d2e000 16 8 8 rw--- [ anon ]
00007f21c0d2e000 0 0 0 rw--- [ anon ]
00007f21c0d32000 156 156 0 r-x-- ld-2.27.so
00007f21c0d32000 0 0 0 r-x-- ld-2.27.so
00007f21c0f41000 8 8 8 rw--- [ anon ]
00007f21c0f41000 0 0 0 rw--- [ anon ]
00007f21c0f59000 4 4 4 r---- ld-2.27.so
00007f21c0f59000 0 0 0 r---- ld-2.27.so
00007f21c0f5a000 4 4 4 rw--- ld-2.27.so
00007f21c0f5a000 0 0 0 rw--- ld-2.27.so
00007f21c0f5b000 4 4 4 rw--- [ anon ]
00007f21c0f5b000 0 0 0 rw--- [ anon ]
00007ffdacdf1000 132 8 8 rw--- [ stack ]
00007ffdacdf1000 0 0 0 rw--- [ stack ]
00007ffdacf3c000 12 0 0 r---- [ anon ]
00007ffdacf3c000 0 0 0 r---- [ anon ]
00007ffdacf3f000 4 4 0 r-x-- [ anon ]
00007ffdacf3f000 0 0 0 r-x-- [ anon ]
ffffffffff600000 4 0 0 --x-- [ anon ]
ffffffffff600000 0 0 0 --x-- [ anon ]
---------------- ------- ------- -------
total kB 4376 1120 68
$ sudo pmap -x $(pgrep test1)
30830: ./test1
Address Kbytes RSS Dirty Mode Mapping
0000557b19475000 4 4 0 r-x-- test1
0000557b19475000 0 0 0 r-x-- test1
0000557b19676000 4 4 4 r---- test1
0000557b19676000 0 0 0 r---- test1
0000557b19677000 4 4 4 rw--- test1
0000557b19677000 0 0 0 rw--- test1
00007f21c0941000 1948 888 0 r-x-- libc-2.27.so
00007f21c0941000 0 0 0 r-x-- libc-2.27.so
00007f21c0b28000 2048 0 0 ----- libc-2.27.so
00007f21c0b28000 0 0 0 ----- libc-2.27.so
00007f21c0d28000 16 16 16 r---- libc-2.27.so
00007f21c0d28000 0 0 0 r---- libc-2.27.so
00007f21c0d2c000 8 8 8 rw--- libc-2.27.so
00007f21c0d2c000 0 0 0 rw--- libc-2.27.so
00007f21c0d2e000 16 8 8 rw--- [ anon ]
00007f21c0d2e000 0 0 0 rw--- [ anon ]
00007f21c0d32000 156 156 0 r-x-- ld-2.27.so
00007f21c0d32000 0 0 0 r-x-- ld-2.27.so
00007f21c0f41000 8 8 8 rw--- [ anon ]
00007f21c0f41000 0 0 0 rw--- [ anon ]
00007f21c0f58000 4 0 0 rw-s- demo_dev
00007f21c0f58000 0 0 0 rw-s- demo_dev
00007f21c0f59000 4 4 4 r---- ld-2.27.so
00007f21c0f59000 0 0 0 r---- ld-2.27.so
00007f21c0f5a000 4 4 4 rw--- ld-2.27.so
00007f21c0f5a000 0 0 0 rw--- ld-2.27.so
00007f21c0f5b000 4 4 4 rw--- [ anon ]
00007f21c0f5b000 0 0 0 rw--- [ anon ]
00007ffdacdf1000 132 8 8 rw--- [ stack ]
00007ffdacdf1000 0 0 0 rw--- [ stack ]
00007ffdacf3c000 12 0 0 r---- [ anon ]
00007ffdacf3c000 0 0 0 r---- [ anon ]
00007ffdacf3f000 4 4 0 r-x-- [ anon ]
00007ffdacf3f000 0 0 0 r-x-- [ anon ]
ffffffffff600000 4 0 0 --x-- [ anon ]
ffffffffff600000 0 0 0 --x-- [ anon ]
---------------- ------- ------- -------
total kB 4380 1120 68
|
You can see that after mmap there is an additional segment called demo_dev, whose starting address is the user space address 0x7f21c0f58000 that we mapped.
1
2
|
00007f21c0f58000 4 0 0 rw-s- demo_dev
00007f21c0f58000 0 0 0 rw-s- demo_dev
|
Test program 2
Test program 2 is not very different, it opens the same device file, mmap creates the same mapping, and then reads the contents written by the previous program via read and virtual address respectively.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
// test.2
int main()
{
char buf[64];
int fd;
char *addr = NULL;
int ret;
char *message = "Hello World\n";
char *message2 = "I'm superman\n";
/* 另一进程打开同一设备文件,然后用mmap映射 */
fd = open(DEMO_DEV_NAME, O_RDWR);
if (fd < 0) {
printf("open device %s failed\n", DEMO_DEV_NAME);
return -1;
}
addr = mmap(NULL, (size_t)getpagesize(), PROT_READ | PROT_WRITE,
MAP_SHARED | MAP_LOCKED, fd, 0);
/* 通过read读取设备文件 */
ret = read(fd, buf, sizeof(buf));
assert(ret == sizeof(buf));
assert(!memcmp(buf, message, strlen(message)));
/* 通过mmap映射的虚拟地址读取 */
assert(!memcmp(addr + sizeof(buf), message2, strlen(message2)));
munmap(addr, (size_t)getpagesize());
close(fd);
return 0;
}
|
Compiled and run, the test results are as we expected. The same kernel virtual address is now mapped to a different user space virtual address. With mmap we have implemented inter-process communication.
1
2
3
4
5
|
$ sudo ./test2
$ dmesg|tail -n 3
[111333.818374] phys_start: 0x5b1558000, offset: 0x0, vma_size: 0x1000, map size:0x1000
[111333.818378] map kernel 0xffff8d1ab1558000 to user 0x7f015ee94000, size: 0x1000
[111333.818381] demodrv_read actual_readed=64, pos=64
|
Test program 3
This time let’s test some special cases, the size of the mapping is changed to 1 byte, according to the previous code analysis, the mapping needs page alignment, so it is expected to actually map a page. It is possible to read and write normally in the range of one page. Then try to write outside the vma mapping range, and expect a segment error.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
|
int main()
{
char buf[64];
int fd;
char *addr = NULL;
off_t offset;
int ret;
char *message = "Hello World\n";
char *message2 = "I'm superman\n";
fd = open(DEMO_DEV_NAME, O_RDWR);
if (fd < 0) {
printf("open device %s failed\n", DEMO_DEV_NAME);
return -1;
}
/* 映射1个字节 */
addr = mmap(NULL, 1, PROT_READ | PROT_WRITE,
MAP_SHARED | MAP_LOCKED, fd, 0);
/* 写到mmap映射的虚拟地址中,通过read读取设备文件 */
ret =sprintf(addr, "%s", message);
assert(ret == strlen(message));
ret = read(fd, buf, sizeof(buf));
assert(ret == sizeof(buf));
assert(!memcmp(buf, message, strlen(message)));
/* 写到一页的尾部 */
ret = sprintf(addr + getpagesize() - sizeof(buf), "%s", message2);
assert(ret == strlen(message2));
offset = lseek(fd, getpagesize() - sizeof(buf), SEEK_SET);
assert(offset == getpagesize() - sizeof(buf));
ret = read(fd, buf, sizeof(buf));
assert(ret == sizeof(buf));
assert(!memcmp(buf, message2, strlen(message2)));
/* 写到一页之后,超出映射范围 */
printf("expect segment error\n");
ret = sprintf(addr + getpagesize(), "something");
printf("never reach here\n");
munmap(addr, 1);
close(fd);
return 0;
}
|
We compiled and ran the tests and the results were as we expected, actually mapping 1 page in size, with a segment error (SIGSEGV) when trying to write beyond the mapped range.
1
2
3
4
5
6
7
8
9
10
|
$ sudo ./test3
expect segment error
Segmentation fault
$ dmesg|tail -n 6
[111762.605089] phys_start: 0x5b1558000, offset: 0x0, vma_size: 0x1000, map size:0x1000
[111762.605093] map kernel 0xffff8d1ab1558000 to user 0x7f96b5d08000, size: 0x1000
[111762.605105] demodrv_read actual_readed=64, pos=64
[111762.605110] demodrv_read actual_readed=64, pos=4096
[111762.605165] test3[31001]: segfault at 7f96b5d09000 ip 0000560c0fd3ad25 sp 00007ffc5a515330 error 7 in test3[560c0fd3a000+2000]
[111762.605170] Code: e8 80 fb ff ff 48 8d 3d 1a 02 00 00 e8 14 fb ff ff e8 cf fb ff ff 48 63 d0 48 8b 45 80 48 01 d0 48 bb 73 6f 6d 65 74 68 69 6e <48> 89 18 66 c7 40 08 67 00 c7 85 7c ff ff ff 09 00 00 00 48 8d 3d
|
Test program 4
This time we modified the mmap parameters again, this time mapping 2 pages in size, with the offset set to 3 pages. Since the physical memory size allocated for our device is 4 pages, the mapped page 2 has exceeded the actual physical memory of the device. It is expected that the first page of the mapping can be read and written normally, and the second page will have a bus error.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
int main()
{
char buf[64];
int fd;
char *addr = NULL;
off_t offset;
int ret;
char *message = "Hello World\n";
char *message2 = "I'm superman\n";
fd = open(DEMO_DEV_NAME, O_RDWR);
if (fd < 0) {
printf("open device %s failed\n", DEMO_DEV_NAME);
return -1;
}
/* 映射2页,offset 3页 */
addr = mmap(NULL, getpagesize() * 2, PROT_READ | PROT_WRITE,
MAP_SHARED | MAP_LOCKED, fd, getpagesize() * 3);
/* 写到mmap映射的虚拟地址中,通过read读取设备文件 */
ret =sprintf(addr, "%s", message);
assert(ret == strlen(message));
offset = lseek(fd, getpagesize() * 3, SEEK_SET);
ret = read(fd, buf, sizeof(buf));
assert(ret == sizeof(buf));
assert(!memcmp(buf, message, strlen(message)));
/* 写到一页之后,超出实际物理内存范围 */
printf("expect bus error\n");
ret = sprintf(addr + getpagesize(), "something");
printf("never reach here\n");
munmap(addr, getpagesize() * 2);
close(fd);
return 0;
}
|
Compile and run the test program and the result is as expected. Although the size of vma is 2 pages, only 1 page of physical memory is actually mapped, and a bus error (SIGBUS) occurs when trying to write to the second page.
1
2
3
4
5
6
7
|
$ sudo ./test4
expect bus error
Bus error
$ dmesg|tail -n 3
[112105.841706] phys_start: 0x5b155b000, offset: 0x3000, vma_size: 0x2000, map size:0x1000
[112105.841710] map kernel 0xffff8d1ab155b000 to user 0x7fe662ec4000, size: 0x1000
[112105.841723] demodrv_read actual_readed=64, pos=12352
|