I recently helped a colleague troubleshoot a problem where the same message was being consumed repeatedly when using Pulsar.
Troubleshoot
I was skeptical when he told me about this phenomenon, based on my previous experience with Pulsar, which is explained in the official documentation and API.

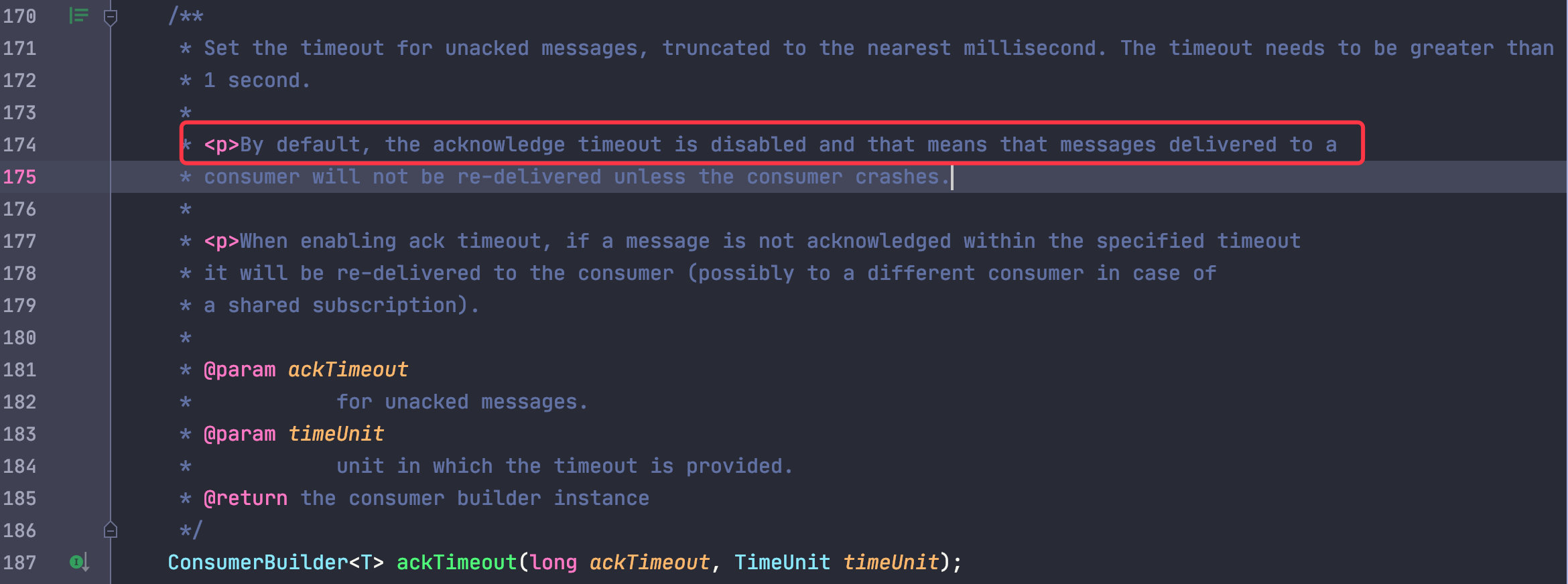
Only when the ackTimeout for consumption is set and the consumption timeout is timed out will the message be recast, which is off by default and really not on by looking at the code.
Could that be a call to the negativeAcknowledge() method (which also triggers redelivery)? Because we use a third-party library https://github.com/majusko/pulsar-java-spring-boot-starter that only calls this method when an exception is thrown.
After checking the code there is no exception thrown anywhere, not even during the whole process; that’s a bit weird.
Replication
In order to clarify the whole story, a detailed understanding of his use of the process.
In fact, there is a bug in the business, and he debugged and then debugged in a single step when the message was consumed, and when he finished debugging once, he received a generic message right away.
But the strange thing is that not every debug can be repeated after consumption, and we all say that if a bug can be 100% completely reproduced, it is basically a big part of the solution.
So the first step of our troubleshooting is to reproduce the problem completely.
Since the problem is generated when debug, it actually translates to the code which is sleep, so we plan to sleep directly in the consumption logic
for a while to see if we can reproduce it.
After testing, sleep for a few seconds to a few tens of seconds could not be reproduced, and finally just sleep for a minute, something magical happened, every time successfully reproduced!
Since I can reproduce it successfully, it’s good to know that my own business code also uses Pulsar, so I’m going to reproduce it again in my own project to facilitate debugging.
The weird thing happened again, I couldn’t reproduce it again.
Although this is what is expected, it’s impossible to adjust it.
In the spirit of believing in modern science, the only difference between the two of us is that the project is different, for which I compared the code of both sides.
|
|
As expected, my colleague’s code added a lock; it was a Redis-based distributed lock, so I slapped my head in the air and threw an exception due to a timeout while unlocking.
To verify this, I set a breakpoint at the Pulsar consumption on the basis that I could reproduce it.


Sure enough, the exception hint is already very clear: the locking has passed the timeout.
The negative message was directly entered after the exception, and the exception was eaten at the same time, so it was not found before.
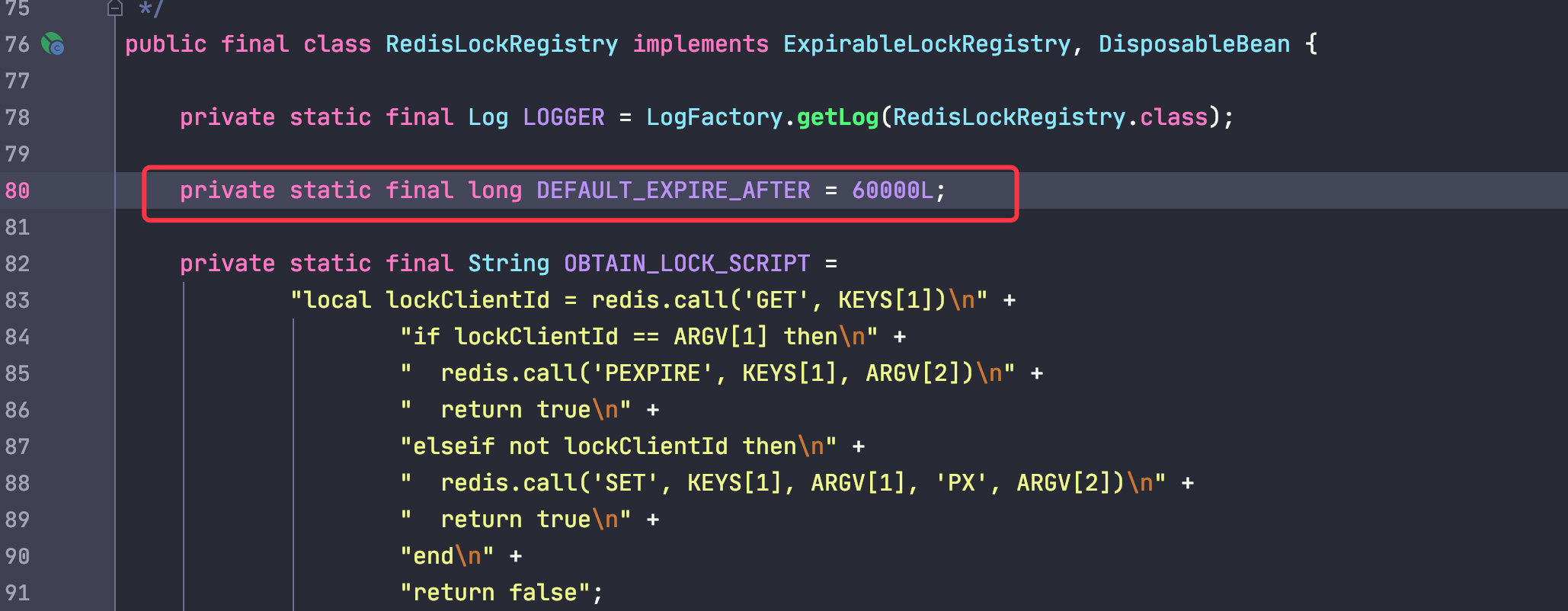
After checking the source code of RedisLockRegistry, the default timeout is exactly one minute, so we were unable to reproduce the problem even after sleep for a few tens of seconds.
Summary
Afterwards, I asked my colleague why we needed to add a lock here, because I didn’t see the need to add a lock at all; it turned out that he added it because he copied the code from someone else and didn’t think about it that much.
So there are some lessons to be learned from this.
- ctrl C/V is convenient, but you have to consider your business scenario.
- When using some third-party APIs, you need to fully understand their role, parameters.