Redis has become the de facto standard for high-performance caching solutions in current technology selection, and as a result, Redis has become one of the basic skill trees for back-end developers, and the underlying principles of Redis are logically a must-learn.
Redis is essentially a web server, and for a web server, the network model is the essence of it. If you understand the network model of a web server, you will understand the essence of it.
This article introduces the Redis network model in a step-by-step manner, and analyzes how it evolved from single-threaded to multi-threaded. In addition, we also analyze the thinking behind many of the choices made in the Redis network model to help the reader understand the design of the Redis network model better.
How fast is Redis?
According to the official benchmark, a single instance of Redis running on a Linux machine with average hardware can typically achieve QPS of 8w+ for simple commands (O(N) or O(log(N)), and up to 100w with pipeline batching.
Judging by performance alone, Redis can be called a high-performance caching solution.
Why is Redis fast?
The high performance of Redis is due to the following fundamentals.
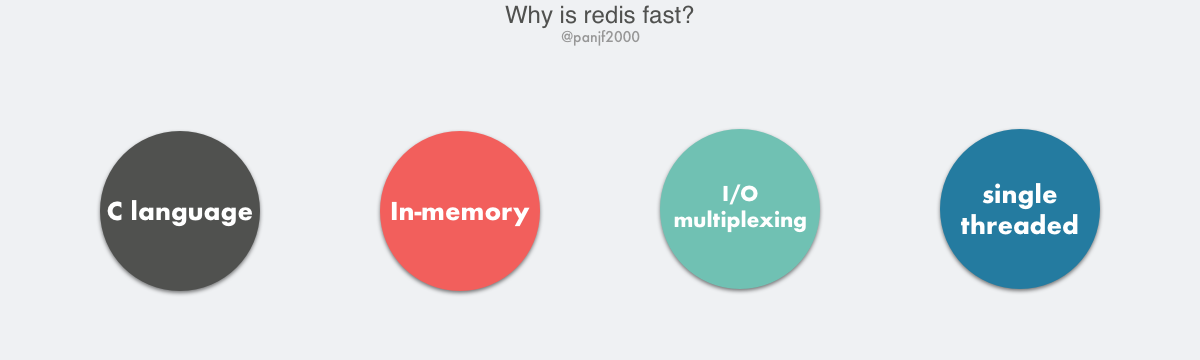
- C implementation, while C contributes to Redis’ performance, the language is not the core factor.
- In-memory-only I/O, Redis has a natural performance advantage over other disk-based DBs with pure memory operations.
- I/O multiplexing for high-throughput network I/O based on epoll/select/kqueue and other I/O multiplexing techniques.
- Single-threaded model , single-threaded can not take advantage of multi-core, but on the other hand, it avoids the frequent context switching of multiple threads, and the overhead of synchronization mechanisms such as locks.
Why did Redis choose to be single-threaded?
Redis’ core network model is single-threaded, which caused a lot of confusion at the beginning, and the official Redis answer to this is:
It’s not very frequent that CPU becomes your bottleneck with Redis, as usually Redis is either memory or network bound. For instance, using pipelining Redis running on an average Linux system can deliver even 1 million requests per second, so if your application mainly uses O(N) or O(log(N)) commands, it is hardly going to use too much CPU.
At its core, this means that CPU is usually not the bottleneck for a DB, because most requests are not CPU-intensive, but rather I/O-intensive. In the case of Redis specifically, if you don’t consider persistence schemes like RDB/AOF, Redis is a completely in-memory operation, which is very fast. The real performance bottleneck for Redis is network I/O, which is the latency of network transfers between the client and server, so Redis chooses single-threaded I/O multiplexing to implement its core network model.
The above is a more general official answer, but in fact the more specific reasons for choosing single-threaded can be summarized as follows.
Avoid excessive context switching overhead
In the process of multi-thread scheduling, it is necessary to switch the thread context between CPUs, and the context switch involves a series of register replacement, program stack reset and even CPU cache and TLB fast table retirement such as program counter, stack pointer and program status word. Because multiple threads within a single process share the process address space, the thread context is much smaller than the process context, and in the case of cross-process scheduling, the entire process address space needs to be switched.
In case of single-threaded scheduling, the frequent thread switching overhead within the process can be avoided because the program always runs within a single thread in the process and there is no multithreaded switching scenario.
Avoiding the overhead of synchronization mechanisms
If Redis chooses a multi-threaded model, and because Redis is a database, it will inevitably involve underlying data synchronization issues, which will inevitably introduce some synchronization mechanisms, such as locks, and we know that Redis provides not only simple key-value data structures, but also lists, sets, hash, and other rich data structures. Different data structures have different granularity of locking for synchronous access, which may lead to a lot of overhead in locking and unlocking during data manipulation, increasing program complexity and reducing performance.
Simple and Maintainable
The author of Redis, Salvatore Sanfilippo (alias antirez), has an almost paranoid philosophy of simplicity in the design and code of Redis, and you can feel this paranoia when reading the Redis source code or submitting PRs to Redis. So simple and maintainable code was necessarily one of the core guidelines of Redis in its early days, and the introduction of multithreading inevitably led to increased code complexity and decreased maintainability.
In fact, multi-threaded programming is not perfect. First of all, the introduction of multi-threaded programming will no longer keep the code logically serial, and the order of code execution will become unpredictable, which will lead to various concurrent programming problems if you are not careful; secondly, multi-threaded mode also makes debugging more complicated and troublesome. There is an interesting picture on the web that vividly depicts the dilemma faced by concurrent programming.
What you expect from multithreaded programming VS Actual multithreaded programming.

If Redis uses a multi-threaded model, then all of the underlying data structures must be implemented as thread-safe. This in turn makes the Redis implementation more complex.
In short, Redis’ choice of single-threaded is a trade-off between keeping the code simple and maintainable while maintaining adequate performance.
Is Redis really single-threaded?
Before we get to that question, we need to clarify the boundaries of the concept of ‘single-threaded’: does it cover the core network model or Redis as a whole? If the former, then the answer is yes. The network model was single-threaded until Redis formally introduced multithreading in v6.0; if the latter, then the answer is no. Redis introduced multithreading as early as v4.0.
Therefore, when discussing multi-threading in Redis, it is important to delineate two important points in the Redis release.
- Redis v4.0 (which introduced multithreading for asynchronous tasks)
- Redis v6.0 (formally implements I/O multithreading in the network model)
Single-threaded event loops
Let’s start by dissecting the core network model of Redis. From Redis v1.0 until v6.0, the core network model of Redis has been a typical single Reactor model: using multiplexing techniques such as epoll/select/kqueue to process events (client requests) in a single-threaded event loop, and finally writing back the response data to the client.
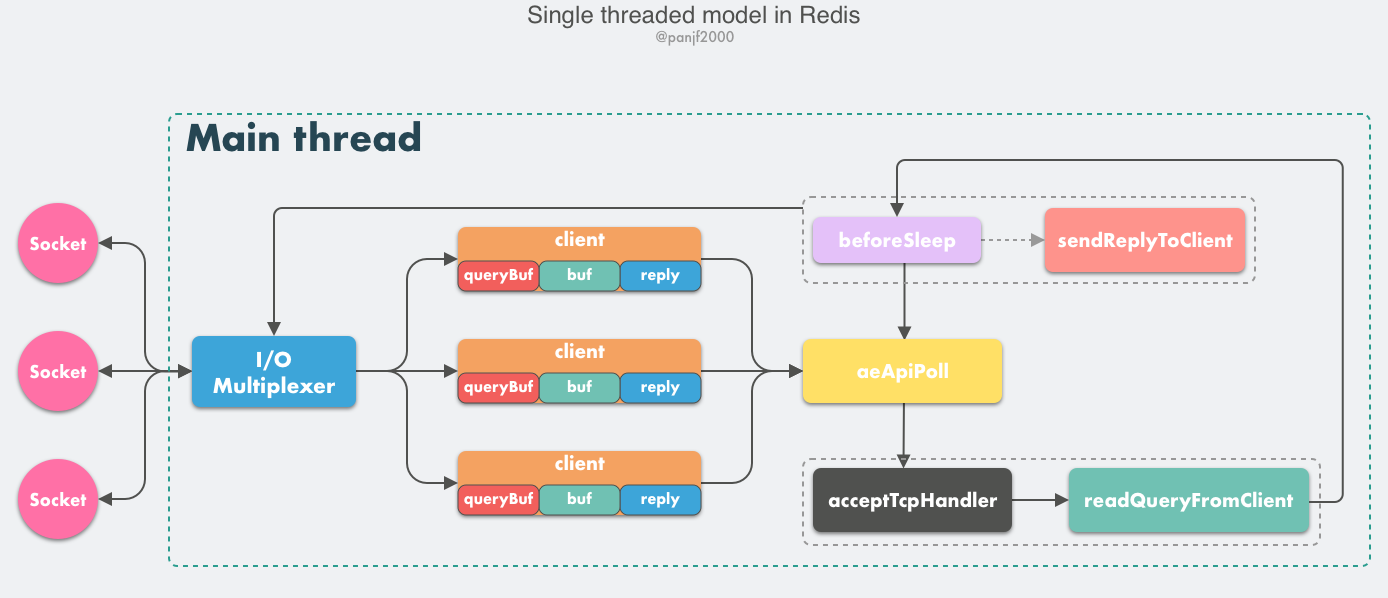
There are several core concepts to learn here.
- client: client object, Redis is a typical CS architecture (Client <–> Server), where the client establishes a network channel with the server via socket and then sends the requested command, and the server executes the requested command and replies. Redis uses the structure client to store all relevant information about the client, including but not limited to
wrapped socket connection -- *conn,currently selected database pointer -- *db,read buffer -- querybuf,write buffer -- buf,write data linked list -- reply, etc. - aeApiPoll : I/O multiplexing API, is based on epoll_wait/select/kevent and other system calls wrapped, listening for read and write events to trigger, and then processing, it is the core function in the Event Loop (Event Loop), is the basis for the event driver to run.
- acceptTcpHandler : connection answer processor, the underlying use of the system call
acceptto accept new connections from the client, and the new connection to register the binding command read processor for subsequent processing of new client TCP connections; in addition to this processor, there is a correspondingacceptUnixHandlerfor handling Unix Domain Socket andacceptTLSHandlerfor handling TLS encrypted connections. - readQueryFromClient : A command reading processor that parses and executes the client’s requested commands.
- beforeSleep : The function that is executed before the event loop enters aeApiPoll and waits for the event to arrive. It contains some routine tasks, such as writing the response from
client->buforclient->reply(two buffers are needed here) back to the client, persisting the data in the AOF buffer to disk, etc. There is also an afterSleep function that is executed after aeApiPoll. - sendReplyToClient: command reply handler, when there is still data left in the write buffer after an event loop, this handler will be registered and bound to the corresponding connection, and when the connection triggers a write ready event, it will write the remaining data in the write buffer back to the client.
Redis internally implements a high-performance event library, AE, based on epoll/select/kqueue/evport, to implement a high-performance event loop model for Linux/MacOS/FreeBSD/Solaris. The core network model of Redis is formally built on AE, including I/O multiplexing, and the registration of various processor bindings, all of which are based on it.
At this point, we can depict the workings of a client requesting a command from Redis.
- the Redis server starts, opens the main thread Event Loop, registers the
acceptTcpHandlerconnection answer processor to the file descriptor corresponding to the user-configured listening port, and waits for a new connection to arrive. - the establishment of a network connection between the client and the server.
acceptTcpHandleris called and the main thread uses AE’s API to bind thereadQueryFromClientcommand read processor to the file descriptor corresponding to the new connection and initialize aclientto bind this client connection.- the client sends the request command, triggering the read-ready event, and the main thread calls
readQueryFromClientto read the command sent by the client via socket into theclient->querybufread buffer. - next call
processInputBuffer, in whichprocessInlineBufferorprocessMultibulkBufferis used to parse the command according to the Redis protocol, and finally callprocessCommandto execute the command. - depending on the type of the requested command (SET, GET, DEL, EXEC, etc.), assign the appropriate command executor to execute it, and finally call a series of functions in the
addReplyfamily to write the response data to the write buffer of the correspondingclient:client->buforclient->reply,client->bufis the preferred write-out buffer, with a fixed size of 16KB, which can generally buffer enough response data, but if the client needs a very large response within the time window, then it will automatically switch to theclient->replylinked list, which can theoretically hold an unlimited amount of data (limited by the physical memory of the machine) Finally, addclientto a LIFO queueclients_pending_write. - In the Event Loop, the main thread executes
beforeSleep–>handleClientsWithPendingWrites, traverses theclients_pending_writequeue, and callswriteToClientto return the data inclient’s write buffer to the client, and if there is any data left in the write buffer, register thesendReplyToClientcommand to reply to the processor with a write ready event for the connection, and wait for the client to write before continuing to write back the remaining response data in the event loop.
For those who want to take advantage of multi-core performance, the official Redis solution is simple and brutal: run more Redis instances on the same machine. In fact, to ensure high availability, it is unlikely that an online business will be in standalone mode. It is more common to use Redis distributed clusters with multiple nodes and data sharding to improve performance and ensure high availability.
Multi-threaded asynchronous tasks
The above is the core network model of Redis, which was not transformed into a multi-threaded model until Redis v6.0. But that doesn’t mean that Redis has always been single-threaded.
Redis introduced multithreading in v4.0 to do some asynchronous operations, mainly for very time-consuming commands. By making the execution of these commands asynchronous, it avoids blocking the single-threaded event loop.
We know that the Redis DEL command is used to delete one or more stored values of a key, and it is a blocking command. In most cases, the key you want to delete will not have many values stored in it, at most a few dozen or a few hundred objects, so it can be executed quickly. But if you want to delete a very large key-value pair with millions of objects, then this command may block for at least several seconds, and because the event loop is single-threaded, it will block other events that follow, resulting in reduced throughput.
Redis author antirez has given a lot of thought to solving this problem. At first, he came up with an incremental solution: using timers and data cursors, he would delete a small amount of data at a time, say 1000 objects, and eventually clear all the data. But this solution had a fatal flaw: if other clients continued to write data to a key that was being progressively deleted at the same time, and the deletion rate could not keep up with the data being written, then memory would be consumed endlessly, which was solved by a clever solution, but this implementation made Redis more complex. Multi-threading seemed like a watertight solution: simple and easy to understand. So, in the end, antirez chose to introduce multithreading to implement this class of non-blocking commands. More of antirez’s thoughts on this can be found in his blog: Lazy Redis is better Redis.
So, after Redis v4.0, some non-blocking commands like UNLINK, FLUSHALL ASYNC, FLUSHDB ASYNC have been added.
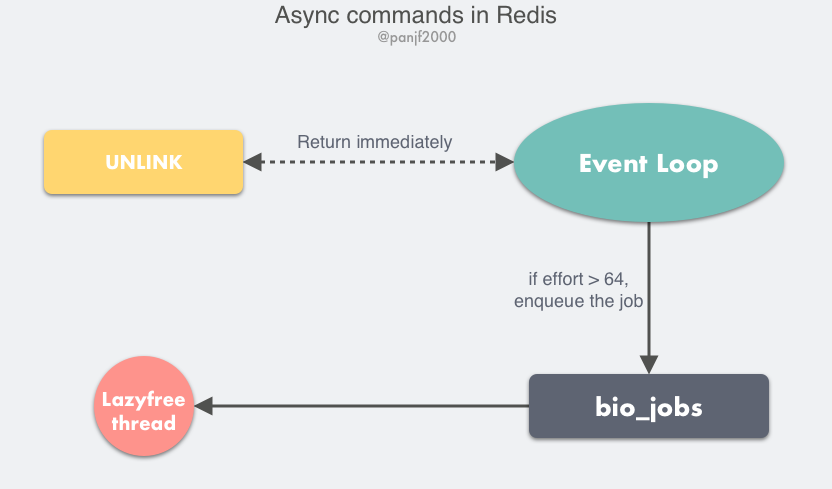
The UNLINK command is actually an asynchronous version of DEL, it doesn’t delete data synchronously, it just removes the key from the keyspace temporarily, then adds the task to an asynchronous queue, and finally the background thread will delete it. But here we need to consider a situation that if we use UNLINK to delete a very small key, it will be more overhead to do it in an asynchronous way, so it will first calculate an overhead threshold, and only when this value is greater than 64 will we use the asynchronous way to delete the key, for the basic data types such as List, Set, and Hash, the threshold is the number of objects stored in them The number of objects stored.
Redis Multi-Threaded Network Model
As mentioned earlier Redis originally chose the single-threaded network model for the reason that the CPU is usually not a performance bottleneck, the bottlenecks tend to be memory and network, so single-threaded is sufficient. So why is Redis now introducing multithreading? The simple fact is that the network I/O bottleneck for Redis is becoming more and more obvious.
With the rapid growth of the Internet, Internet business systems are handling more and more online traffic, and Redis’ single-threaded mode causes the system to consume a lot of CPU time on network I/O, thus reducing throughput. There are two ways to improve the performance of Redis.
- Optimized network I/O modules
- Improving the speed of machine memory reads and writes
The latter depends on the development of hardware and is temporarily unsolvable. Therefore, we can only start from the former, and the optimization of network I/O can be divided into two directions.
- Zero-copy technology or DPDK technology
- Take advantage of multi-core
Zero-copy technology has its limitations and cannot be fully adapted to complex network I/O scenarios like Redis. (For more on network I/O consumption of CPU time and Linux zero-copy techniques, read the previous article.) The DPDK technique of bypassing the kernel stack by bypassing NIC I/O is too complex and requires kernel or even hardware support.
Therefore, taking advantage of multiple cores is the most cost effective way to optimize network I/O.
After version 6.0, Redis formally introduced multithreading into the core network model, also known as I/O threading, and Redis now has a truly multithreaded model. In the previous section, we learned about the single-threaded event loop model of Redis before 6.0, which is actually a very classic Reactor model.
Reactor mode is used in most of the mainstream high-performance networking libraries/frameworks on Linux platforms, such as netty, libevent, libuv, POE (Perl), Twisted (Python), etc.
Reactor pattern essentially refers to the use of I/O multiplexing (I/O multiplexing) + non-blocking I/O (non-blocking I/O) pattern.
The core network model of Redis, until version 6.0, was a single Reactor model: all events were processed in a single thread, and although multithreading was introduced in version 4.0, it was more of a patch for specific scenarios (removing oversized key values, etc.) and could not be considered multithreading for the core network model.
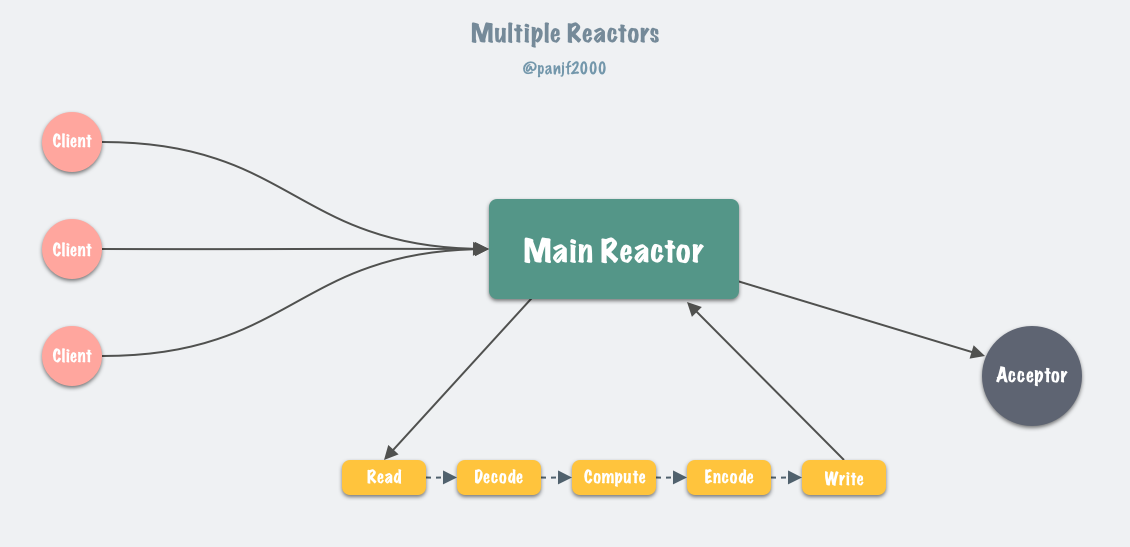
In general, the single Reactor model, after the introduction of multi-threading, evolves into the Multi-Reactors model, with the following basic working model.
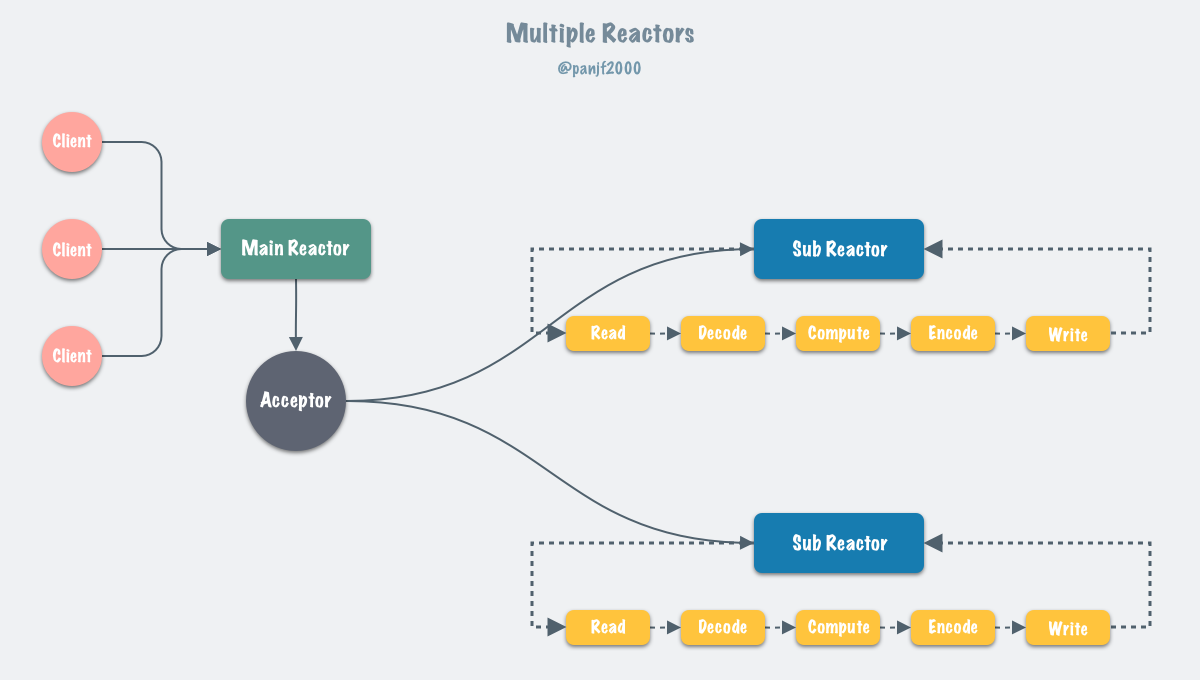
Instead of a single-threaded event loop, this pattern has multiple threads (Sub Reactors) each maintaining a separate event loop, with the Main Reactor receiving new connections and distributing them to the Sub Reactors for independent processing, and the Sub Reactors writing back responses to the client.
The Multiple Reactors pattern can often be equated to the Master-Workers pattern, such as Nginx and Memcached, which use this multi-threaded model, and although the implementation details vary slightly from project to project, the pattern is generally consistent.
Design Thinking
Redis also implements multithreading, but not in the standard Multi-Reactors/Master-Workers pattern, for reasons we will analyze later. For now, let’s look at the general design of the Redis multi-threaded network model.
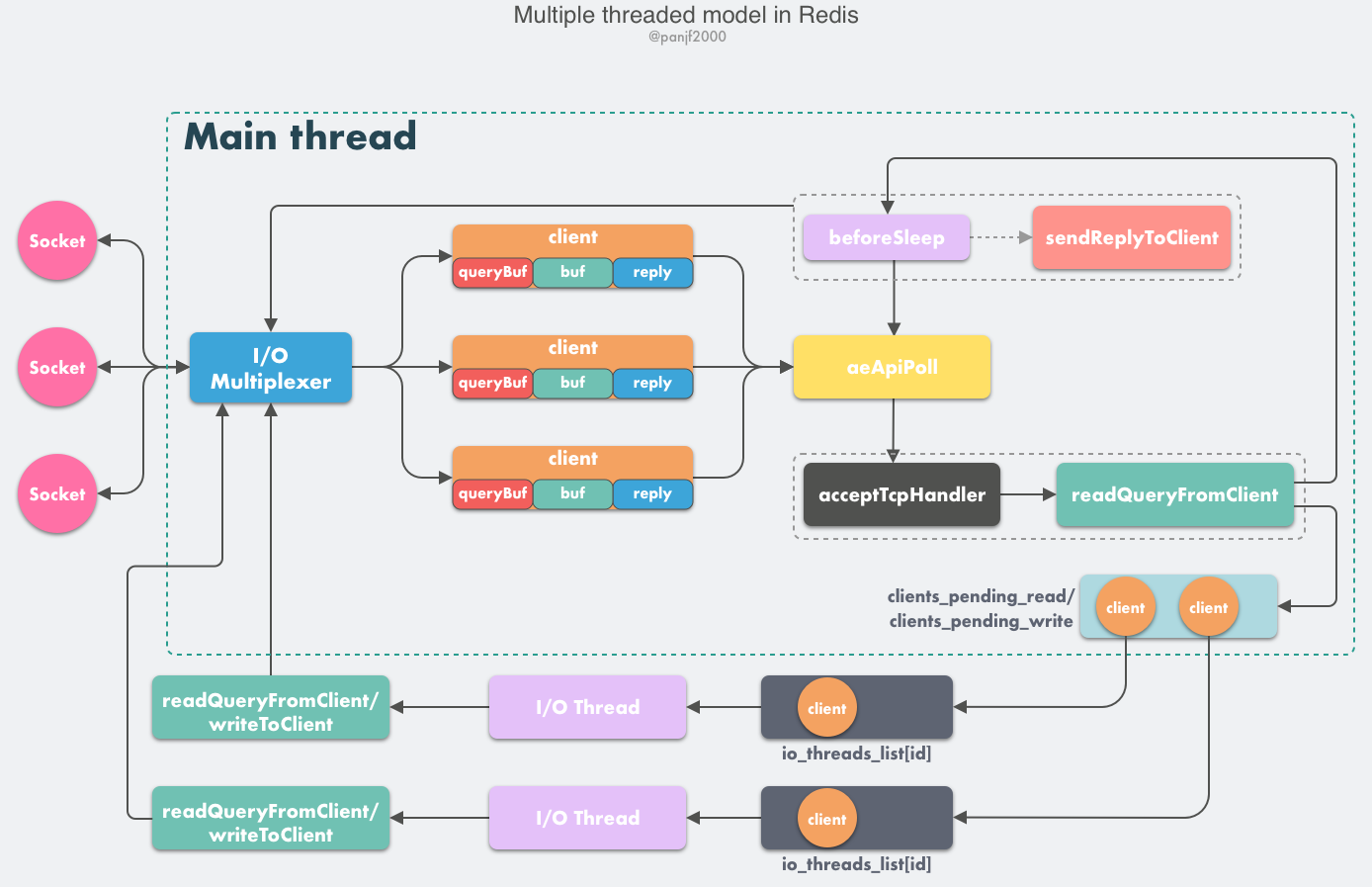
- the Redis server starts, opens the main thread Event Loop, registers the
acceptTcpHandlerconnection answer processor to the file descriptor corresponding to the user-configured listening port, and waits for a new connection to arrive. - the establishment of a network connection between the client and the server.
acceptTcpHandleris called and the main thread uses AE’s API to bind thereadQueryFromClientcommand read processor to the file descriptor corresponding to the new connection and initialize aclientto bind this client connection.- the client sends a request command, triggering a read-ready event. instead of reading the client’s request command through the socket, the server’s main thread first puts
clientinto a LIFO queueclients_pending_read. - In the Event Loop, the main thread executes
beforeSleep–>handleClientsWithPendingReadsUsingThreads, using a Round-Robin polling load balancing strategy to evenly distribute the connections in theclients_pending_readqueue between the I/O threads The I/O thread reads the client’s requested command via socket, stores it inclient->querybufand parses the first command, but does not execute it, while the main thread is busy polling and waiting for All I/O threads complete the read task. - When the main thread and all I/O threads have finished reading, the main thread finishes busy polling, traverses the
clients_pending_readqueue, executes all client-connected request commands, and first callsprocessCommandResetClientto execute the first command that has been parsed. Then callprocessInputBufferto parse and execute all commands connected by the client, useprocessInlineBufferorprocessMultibulkBufferto parse the commands according to the Redis protocol, and finally callprocessCommandto execute the commands which is calledprocessCommandto execute the command. - Depending on the type of the requested command (SET, GET, DEL, EXEC, etc.), the corresponding command executor is assigned to execute it, and finally a series of functions in the
addReplyfamily are called to write the response data to the correspondingclientwriteout buffer:client->buforclient->reply,client->bufis the preferred write-out buffer, with a fixed size of 16KB, which generally buffers enough response data, but automatically switches to theclient->replylinked list if the client needs to respond to a very large amount of data within a time window. Theoretically, a linked list can hold an infinite amount of data (limited by the physical memory of the machine), and finally addclientto a LIFO queueclients_pending_write. - In the Event Loop, the main thread executes
beforeSleep–>handleClientsWithPendingWritesUsingThreads, using a Round-Robin polling load balancing strategy to evenly distribute the connections in theclients_pending_writequeue to the I/O threads and to the main thread itself. The I/O threads write back the data inclient’s write buffer to the client by callingwriteToClient, and the main thread is busy polling for all I/O threads to complete their write tasks The main thread is busy polling and waiting for all I/O threads to complete their write tasks. - When the main thread and all I/O threads have finished writing out, the main thread finishes busy polling and traverses the
clients_pending_writequeue. If there is data left in theclientwrite buffer, it registerssendReplyToClientto the write ready event for that connection and waits for the client to write before continuing to write back the remaining response data in the event loop.
Most of the logic here is the same as in the previous single-threaded model, the only change is to asynchronize the logic of reading the client request and writing back the response data to the I/O thread. One special note here: I/O threads only read and parse client commands and do not actually execute them, the execution of client commands is ultimately done on the main thread.
Source code dissection
All of the following code is based on the Redis v6.0.10 release.
Multi-threaded initialization
|
|
initThreadedIO is called at the end of the initialization effort at Redis server startup to initialize the I/O multithreading and start it.
Redis multithreading mode is turned off by default and needs to be enabled by the user in the redis.conf configuration file.
Read Request
When a client sends a request command, it triggers an event loop in the Redis main thread and the command handler readQueryFromClient is called back. In the previous single-threaded model, this method would read and parse the client command directly and execute it. In multi-threaded mode, however, the client is added to the clients_pending_read task queue, and the main thread is then assigned to the I/O thread to read the client’s requested command.
|
|
The main thread then calls handleClientsWithPendingReadsUsingThreads in the beforeSleep() method of the event loop.
|
|
The core work here is.
- Iterate over the
clientqueueclients_pending_readto be read, and assign all tasks to I/O threads and the main thread to read and parse client commands via the RR policy. - Busy polling waiting for all I/O threads to complete their tasks.
- Finally iterate through
clients_pending_readand execute allclientcommands.
Write back the response
After reading, parsing and executing the command, the response data of the client command has been stored in client->buf or client->reply. Next, you need to write the response data back to the client. Again, in beforeSleep, the main thread calls handleClientsWithPendingWritesUsingThreads.
|
|
The core work here is to.
- Check the current task load, and if the current number of tasks is not enough to be processed in multi-threaded mode, hibernate the I/O threads and write the response data back to the client directly and synchronously.
- Wake up the I/O threads that are hibernating (if any).
- Iterate through the
clientqueueclients_pending_writeand assign all tasks to the I/O threads and the main thread to write the response data back to the client via the RR policy. - Busy polling waits for all I/O threads to complete their tasks.
- Finally iterate through
clients_pending_write, register the command reply handlersendReplyToClientfor thoseclientsthat still have response data left, and wait for the client to be writable before continuing to write back the remaining response data in the event loop.
I/O thread main logic
|
|
After the I/O thread is started, it first enters busy polling to determine the number of tasks in the atomic counter. If it is non-zero, the main thread has assigned it a task and starts executing it, otherwise it stays busy polling for a million times and waits. If it is still 0, it tries to add a local lock, because the main thread has already locked the local locks of all I/O threads in advance when it starts them, so the I/O threads will sleep and wait for the main thread to wake up.
The main thread will try to call startThreadedIO in each event loop to wake up the I/O thread to perform the task. If a client request command is received, the I/O thread will be woken up and start working to perform the task of reading and parsing the command or writing back the response data according to the io_threads_op flag set by the main thread. After receiving notification from the main thread, the I/O thread will iterate through its own local task queue io_threads_list[id] and take out one client to execute the task.
- If the current operation is a write operation, call
writeToClientto write the response data fromclient->buforclient->replyback to the client via the socket. - If the current operation is a read operation, call
readQueryFromClientto read the client command via socket, store it inclient->querybuf, and then callprocessInputBufferto parse the command, which will only end up with the first command, and then finish without executing it. - Set its own atomic counter to 0 after all tasks have been executed to tell the main thread that it has finished its work.
|
|
Additional attention should be paid to the CPU affinity of the current thread when the I/O thread is first started, i.e., binding the current thread to the user-configured CPU. The same CPU affinity is set when starting the main Redis server thread, which is the core network model of Redis. Redis itself is an extremely throughput- and latency-sensitive system, so users need Redis to have finer-grained control over CPU resources. There are two main considerations here: the CPU cache and the NUMA architecture.
First, the CPU cache (we are talking about a hardware architecture where both the L1 Cache and L2 Cache are integrated into the CPU). Imagine a scenario where the main Redis process is running on CPU-1, serving data to clients, and Redis starts a child process for data persistence (BGSAVE or AOF). After system scheduling, the child process takes over CPU-1 of the main process, and the main process is scheduled to run on CPU-2, causing the instructions and data in CPU-1’s cache to be eliminated and CPU-2 to reload the instructions and data into its own local cache, wasting CPU resources and reducing performance.
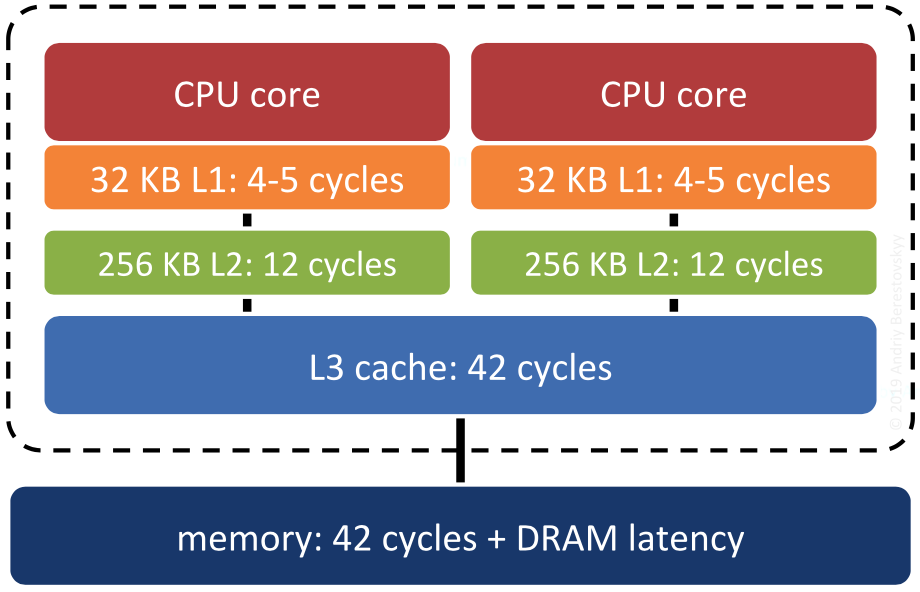
Therefore, by setting CPU affinity, Redis can isolate the main process/thread and child processes/threads by binding them to different cores so that they do not interfere with each other, which can effectively improve system performance.
The second consideration is based on the NUMA architecture. Under the NUMA system, the memory controller chip is integrated inside the processor to form the CPU local memory. Access to local memory is only through the memory channel and not through the system bus, which greatly reduces the access latency, while multiple processors are interconnected by QPI data links, and the memory access overhead across NUMA nodes is much higher than that of local memory access.
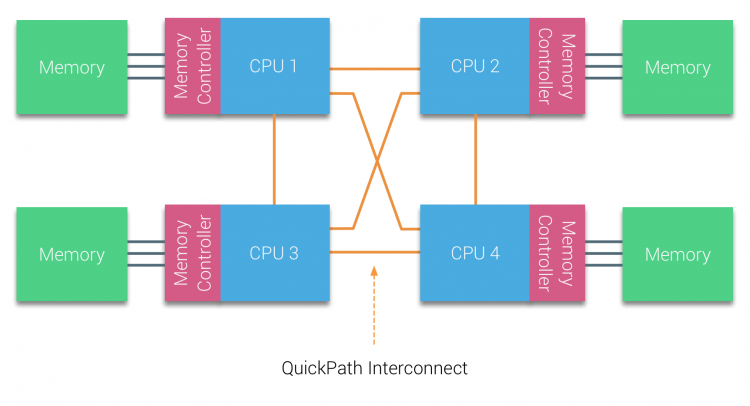
Therefore, Redis can also greatly improve performance by setting CPU affinity so that the main process/thread runs on a fixed CPU on a NUMA node as much as possible, using more local memory instead of accessing data across nodes.
For more information about NUMA, please check it yourself. I’ll write a separate article about it later when I have time.
One final point that readers who have read the source code may wonder is that Redis does not seem to lock data in multi-threaded mode. In fact, Redis’ multi-threaded model is lock-free throughout, which is achieved through atomic operations + interleaved access, with three variables shared between the main thread and the I/O thread: io_threads_pending counters, io_threads_op I/O identifiers, and io_threads_list list` thread-local task queue.
io_threads_pending is an atomic variable that does not require lock protection, while io_threads_op and io_threads_list are two variables that circumvent the shared data competition problem by controlling staggered access between the main thread and the I/O thread: the I/O thread starts and waits for a signal from the main thread through busy polling and lock hibernation. After starting, the I/O thread waits for a signal from the main thread through busy polling and lock sleep. It does not access its own local task queue io_threads_list[id] until it has assigned all tasks to the local queue of each I/O thread before waking up the I/O thread to start work, and the main thread will only access its own local task queue io_threads_list[ 0] and will not access the I/O thread’s local queue, which ensures that the main thread will always access io_threads_list before the I/O thread and never again, ensuring interleaved access. Similarly for io_threads_op, the main thread sets the value of io_threads_op before waking up the I/O thread and does not access this variable again while the I/O thread is running.
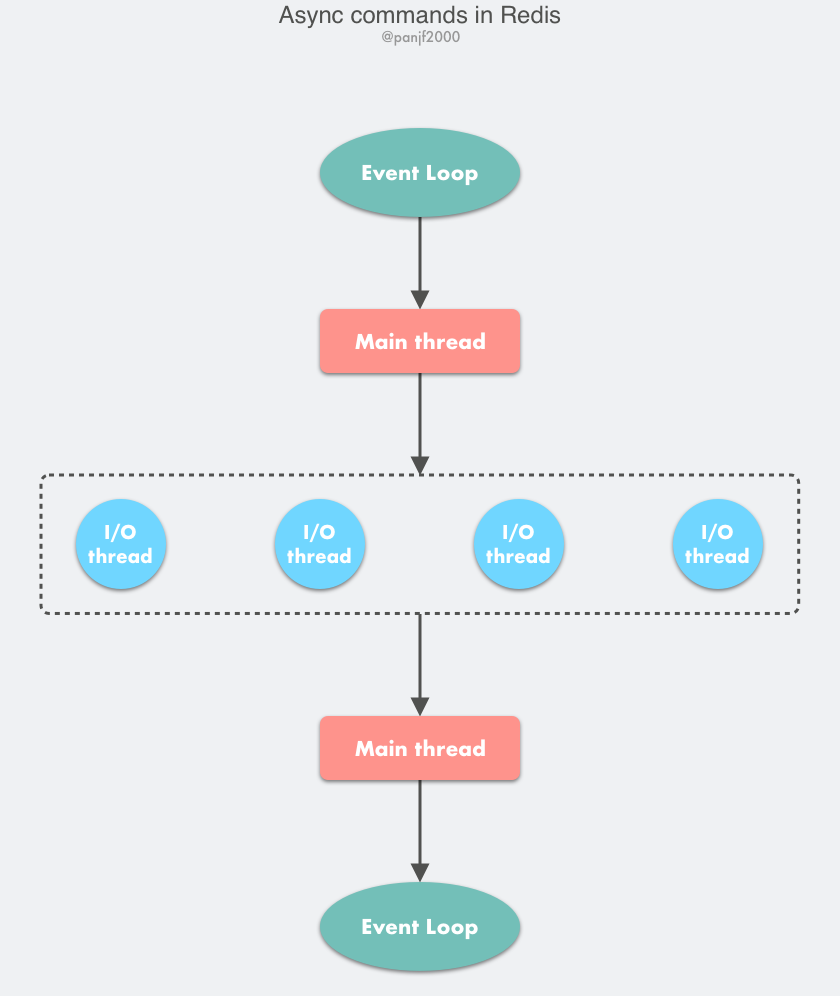
Performance Improvements
Redis transforms the core network model into multi-threaded mode in pursuit of the ultimate performance improvement, so the benchmark data is the real deal.
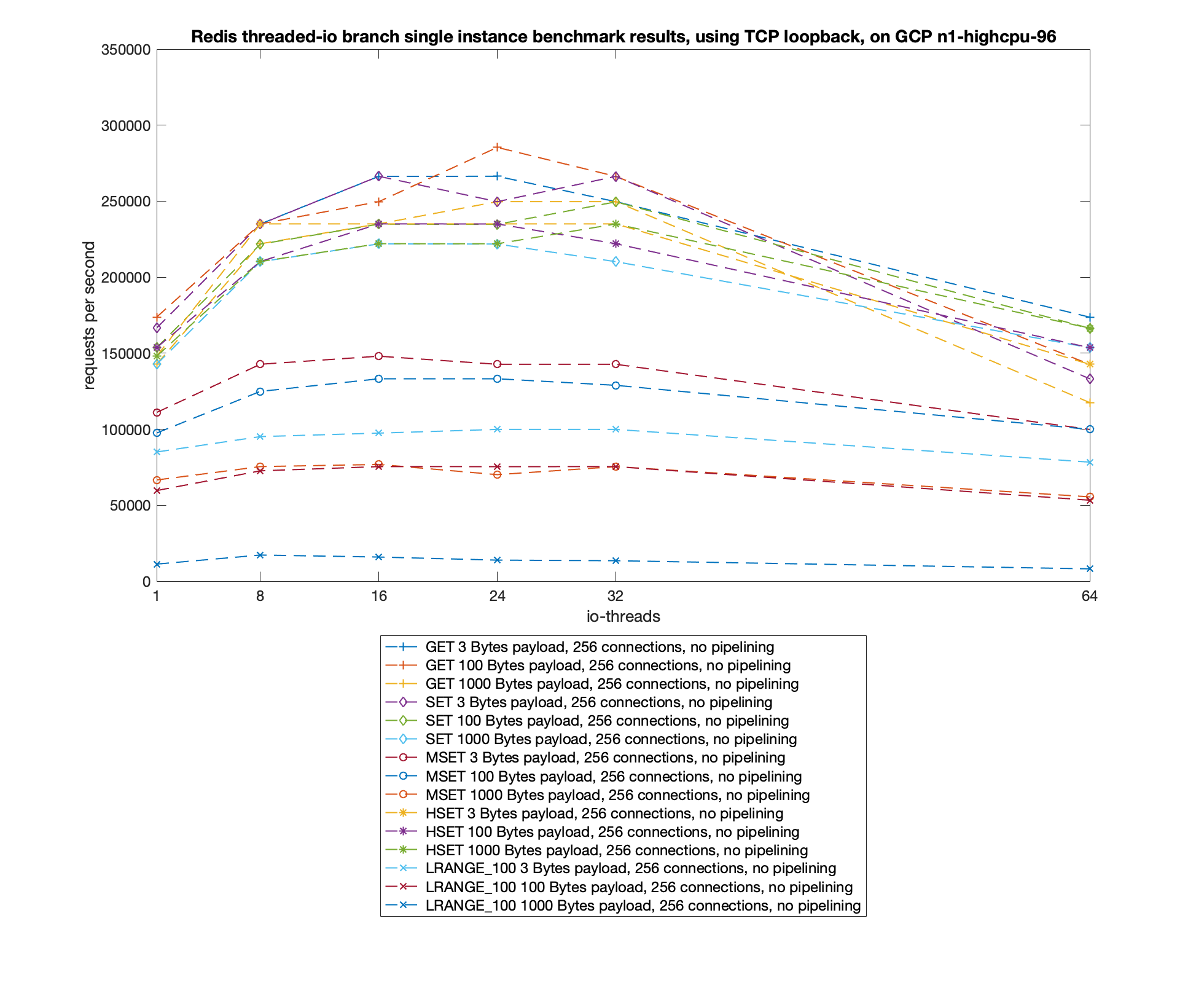
The test data shows that Redis performance is dramatically improved by a factor of two when using multi-threaded mode. More detailed performance crunching data can be found in this article: Benchmarking the experimental Redis Multi-Threaded I/O.
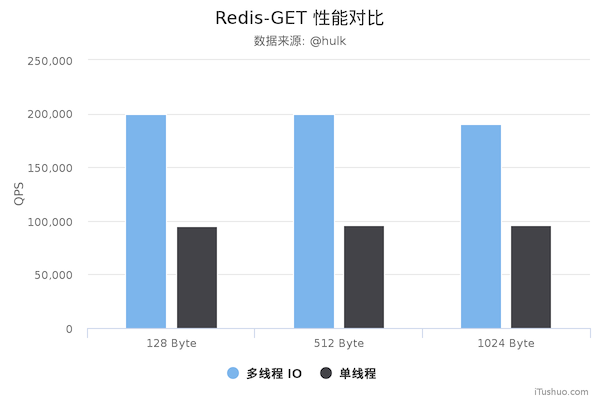
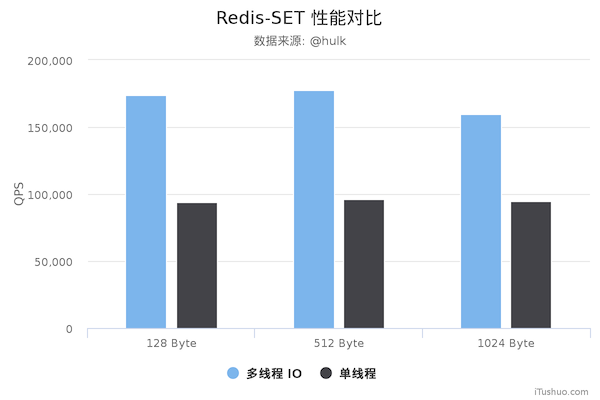
The following is a comparison of the performance of the old and new Redis versions as measured by the Mito technical team, for reference only.
Model flaws
First of all, as I mentioned earlier, Redis’ multi-threaded network model is not actually a standard Multi-Reactors/Master-Workers model, and differs from other mainstream open source web server models. Workers model, Sub Reactors/Workers will complete the network read -> data parsing -> command execution -> network write process, and Main Reactor/Master is only responsible for assigning tasks. In Redis’ multi-threaded scenario, the I/O threads are only tasked with reading and parsing client requests through the socket, but not actually executing the commands. All client-side commands eventually need to be returned to the main thread for execution, so the utilization of multiple cores is not very high. Moreover, each time the main thread must be busy polling for all I/O threads to complete their tasks before continuing with the rest of the logic.
I think the main reason why Redis was designed with a multi-threaded network model was to maintain compatibility, because Redis was previously single-threaded and all client commands were executed in a single-threaded event loop, so all data structures in Redis were non-thread-safe. Now with multi-threading, if we follow the standard Multi-Reactors/Master-Workers model, all the built-in data structures would have to be refactored to be thread-safe, which is a huge amount of work and hassle.
So, in my opinion, Redis’ current multi-threading solution is more of a compromise: it maintains the compatibility of the original system while leveraging multiple cores to improve I/O performance.
Second, the current multi-threaded model of Redis is too simple and brutal in its communication between the main thread and the I/O threads: busy polling and locking, because waiting via spin busy polling causes Redis to have occasional high occupancy caused by brief CPU idle at startup and during runtime. The final implementation of this communication mechanism looks very unintuitive and uncomplicated, and we hope that Redis will improve on the current solution later.
Summary
Redis is the de facto standard for caching systems, and its underlying principles are worth a deep dive. But author antirez, a developer of simplicity, was extremely cautious about adding any new features to Redis, so the core Redis network model was finally converted to a multi-threaded model a decade after the initial release of Redis, during which time a number of Redis multi-threaded alternatives were even born. Although antirez has been postponing the multithreading solution, it has never stopped thinking about the feasibility of multithreading. The transformation of the Redis multithreaded network model did not happen overnight, and involved all aspects of the project, so we can see that the final Redis solution was not perfect, and did not use the mainstream multithreaded design.
Let’s review the design of the Redis multi-threaded network model.
- Multi-threaded network I/O using I/O threads, where I/O threads are only responsible for network I/O and command parsing, and do not execute client commands.
- Implement a lock-free multi-threaded model using atomic operations + interleaved access.
- Isolating the main process from other sub-processes by setting CPU affinity, so that the multi-threaded network model can maximize performance.
After reading through this article, I believe that readers should be able to understand the various technologies involved in the computer domain to implement a good network system: design patterns, network I/O, concurrent programming, operating system underlays, and even computer hardware. It also requires a careful approach to project iteration and refactoring, and deep thinking about technical solutions, not just the hard part of writing good code.