Azure Database for PostgreSQL is an on-cloud database service provided by Azure based on the open source PostgreSQL database. It is a fully managed database service with predictable performance, security, high availability, and dynamic scalability to handle mission-critical workloads.
Azure Database for PostgreSQL offers.
- Built-in high availability.
- Automatic backups and point-in-time restores (backup data is retained for up to 35 days).
- Automated maintenance of the underlying hardware, operating system, and database engine to keep services secure and versions up-to-date.
- Predictable performance, using a pay-as-you-go pricing model.
- second-level elastic scaling.
- Enterprise-class security and industry-leading compliance to protect sensitive data at rest and in motion.
- Rich monitoring and automation traits.
- Industry-leading support experience.
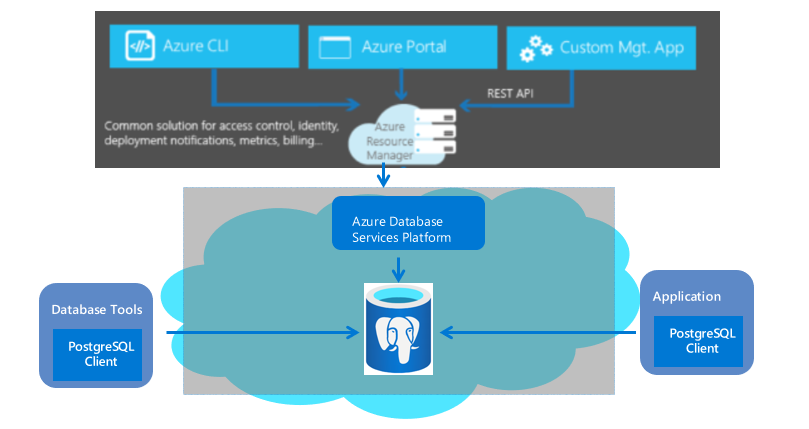
These features require little to no management, and all features are available at no additional cost. Enables you to focus on application development and accelerating time-to-market, rather than spending valuable time and resources on managing virtual machines and infrastructure.
Azure Database for PostgreSQL offers three deployment models: Single Server, Flexible Server, and Large Scale (Citus) Clustering. Each is described below.
1 Single Server
Azure Database for PostgreSQL Single Server is a central management point for multiple databases. It is the same construct as if you were building a PostgreSQL server in an On-Premise environment.
For a single server deployment of Azure Database for PostgreSQL.
- is created in an Azure subscription.
- Is the parent resource for the database.
- provides a namespace for the database.
- is a container with strong lifecycle semantics (deleting the server will delete the contained database).
- configures resources in a zone.
- provides connection points for server and database access.
- provides a range of administrative policies applicable to its databases: logins, firewalls, users, roles, configurations, etc.
- Support multiple PostgreSQL versions (what are they?).
- Support for PostgreSQL extensions (What extensions are supported?).
You can create one or more databases in a single server for exclusive use or shared resources by one or more applications. Pricing will be calculated based on pricing tier, vCore and storage (GB) configurations.
How to connect
-
Authentication
Azure Database for PostgreSQL single server supports native PostgreSQL authentication. You can connect using an administrator account.
-
Protocols
The service supports the message-based protocols used by PostgreSQL.
-
TCP/IP
Protocols such as the above are supported by TCP/IP and Unix domain sockets.
-
Firewall
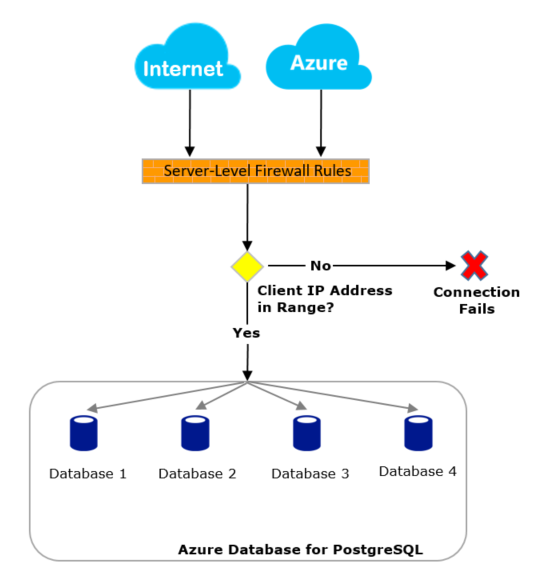
To protect data, Azure shuts down all access by default, and you set up firewall rules (IP whitelisting) on the Server side before opening access to the specified IP.
The firewall determines whether each request has access based on its original IP address. You need to set firewall rules (range of allowed IP addresses) on Server side via Azure portal or Azure CLI, and all databases under the same logical server follow these rules. Please use the subscription owner or subscription contributor to create the firewall rules.
You can choose to force TLS to be enabled for enhanced security.
This will allow you to download the certificate and connect using psql.
|
|
|
|
Server Administration
You can use the Azure portal or Azure CLI to manage Azure Database for PostgreSQL single server.
When you create a server, you set a password for the administrator user. The administrator user is the highest privileged user you have on the server. It belongs to the azure_pg_admin role. This role does not have full superuser privileges.
PostgreSQL superuser privileges are assigned to azure_superuser, which is held by the managed service. You do not have access to this role.
There are several default databases under this server as follows.
- postgres - the default database to which you can connect once the server is created.
- azure_maintenance - This database is used to separate the processes that provide the managed services from user operations, and you do not have access to this database.
- azure_sys - The database used for the Query Store. This database does not accumulate data when the Query Store is closed and is closed by default.
Server Parameters
Server parameters determine the configuration of the server. In Azure Database for PostgreSQL, the list of parameters can be viewed and edited using the Azure portal or the Azure CLI.
As a hosted service, the configurable parameters for Azure Database for PostgreSQL are a subset of the configurable parameters for self-built Postgres instances (for more information on Postgres parameters, see PostgreSQL Runtime Configuration).
Your Azure Database for PostgreSQL server is created using the default values for each parameter. Users cannot configure certain parameters that require a restart or superuser privileges to change.
2 Flexible Server
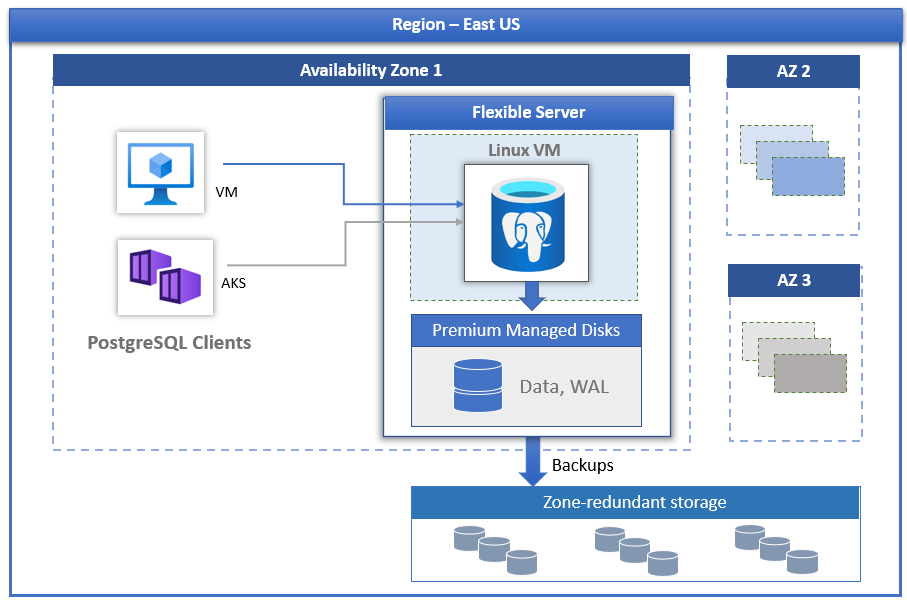
Azure Database for PostgreSQL Flexible Server is a fully managed database service designed to provide more granular control and flexibility over database management functions and configuration settings. The service provides more flexibility and customization of server configurations based on user requirements. The Flexible Server architecture allows users to co-locate the database engine with client services to reduce latency and select high availability in a single availability zone and across multiple availability zones. Flexible Server also provides better cost-optimized control with the ability to start and stop your servers and burstable compute tiers, ideal for workloads that do not require continuous full compute capacity. The service currently supports PostgreSQL 11, 12 and 13 community editions. The service is currently available in most Azure locales.
Flexible servers are well suited for the following situations.
- application development requiring better control and customization.
- Regional redundancy and high availability.
- Hosted maintenance windows.
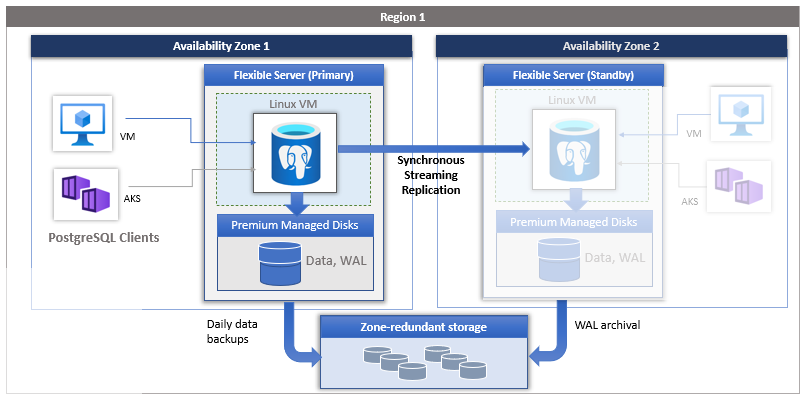
High Availability
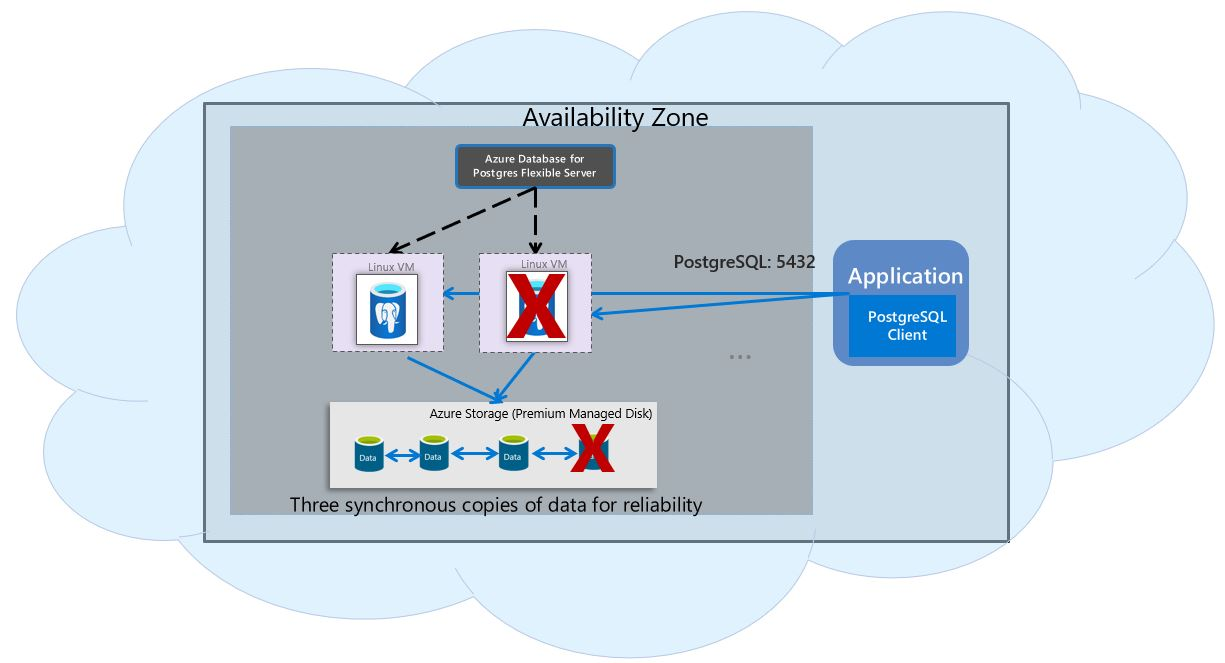
The Flexible Server Deployment Model is designed to support high availability for a single availability zone and across multiple availability zones. The architecture separates compute and storage. The database engine runs on a container inside a Linux virtual machine, while the data files are stored in Azure Storage. Storage maintains three local redundant synchronized copies of the database files to ensure data persistence.
In the event of a server failure during a planned or unplanned failover event, the service maintains high server availability using the following automated procedures.
- Pre-provisioning of a new computing Linux VM.
- Storage with data files mapped to the new VM.
- PostgreSQL database engine coming online on the new VM.
The following diagram shows the transition of VM and storage failures.
If regional redundancy high availability is configured, the service will pre-provision and maintain a hot standby server in an available region within the same Azure geography. Data changes on the source server are synchronized and replicated to the standby server, ensuring zero data loss. With region redundancy high availability, the standby server will come online to process the request as soon as a planned or unplanned failover event is triggered. This allows services to recover from failures that support multiple availability regions within the same Region, as shown in the figure below.
Automated patching using Managed Maintenance Window
This service performs automatic patching of the underlying hardware, operating system and database engine. This includes security patches and software updates. For the PostgreSQL engine, minor version upgrades are also included in the scheduled maintenance releases. Users can configure the patching schedule to be system-hosted or to customize maintenance times. During maintenance, patches will be applied and may require a server restart to complete the update. By customizing maintenance times, users can make their patch cycles predictable and choose the maintenance window that has the least impact on the business. Typically, the service is released once a month as part of continuous integration and release.
Automatic Backup
Flexible Server automatically backs up data and stores them on Zone Redundant Storage (ZRS) within the same Region. Backups can be used to restore your server to any point in time within the backup retention period. The default backup retention period is 7 days and can be configured to a maximum of 35 days. All backups are encrypted using the AES 256 encryption algorithm.
Expands in seconds
Flexible Server has three compute tiers to choose from: Burst, Generic, and Memory Optimized. Burst is best suited for low-cost development and low-concurrency workloads that do not require continuous full compute capacity. The general-purpose and memory-optimized models are better suited for production workloads that require high concurrency, large scale, and predictable performance. You can spend a few dollars a month to build your first application on a small database and then seamlessly scale to meet your solution needs.
Start and stop servers to reduce TCO
Flexible Server allows you to stop and start servers on demand to reduce your TCO. compute layer billing stops immediately when a server is stopped. This allows you to achieve significant cost savings during development, testing, and time-bound predictable production workloads. The server will remain down for 7 days unless restarted early.
Enterprise-grade security
The Flexible Server uses a FIPS 140-2 validated encryption module to store static data encrypted. Data created when running queries (including backups and temporary files) is encrypted. The service uses the AES 256 key included in Azure Storage Encryption, and the key can be managed by the system (by default). The service encrypts dynamic data using the default enhanced transport layer security (SSL/TLS). The service is only enhanced and supports TLS version 1.2.
Allows fully private access to servers using Azure Virtual Network (VNet integration). Servers in an Azure Virtual Network can only be accessed and connected to via private IP addresses. With VNet integration, public access is denied and the server cannot be accessed using public endpoints.
Monitoring and Alerting
Flexible Server is equipped with built-in performance monitoring and alerting capabilities. All Azure metrics are captured once a minute and each metric provides a 30-day history. You can configure alerts on the metrics. Host server metrics provide open access for monitoring resource utilization and allow configuration of slow query logs. Using these tools, you can quickly optimize your workloads and can optimize your configurations for optimal performance.
Built-In PgBouncer
Flexible Server comes with a built-in PgBouncer (a connection pool). You can choose to enable it and connect your applications to your database server via PgBouncer using the same hostname and port 6432.
Data Migration
This service runs the PostgreSQL Community Edition. This allows full application compatibility and minimal refactoring costs to migrate existing applications developed on the PostgreSQL engine to Azure Flexible Server.
- Dump and Restore For offline migrations, users can afford some downtime and use community tools such as pg_dump and pg_restore to perform dumps and restores.
- Azure Database Migration ServiceFor seamless migration to Flexible Server with minimal downtime, you can use Azure Database Migration Service.
3 Large-scale (Citus) clustering
A large scale (Citus) cluster is a deployment option that uses sharding to scale queries horizontally across multiple machines. Its query engine performs parallel queries on incoming SQL across these servers to provide faster responses to large data sets. It scales larger and performs better than the two deployment options above. The workload is typically close to or over 100 GB.
Large-scale clusters provide the ability to.
- Horizontal scaling across multiple machines using sharding.
- Parallel queries on multiple machines for faster response to large data sets.
- Excellent support for multi-tenant applications, real-time operational analysis, and high-throughput transactional workloads.
Applications built with PostgreSQL can run distributed queries on large-scale (Citus) clusters using standard join libraries and minimal changes.
Node Division of Labor
Large-scale (Citus) cluster hosting types allow Azure Database for PostgreSQL servers (called nodes) to coordinate with each other in a “no-share” architecture. Nodes in a server group share more data and use more CPU cores than a single server. The architecture also allows the database to be expanded by adding more nodes to the server group.
Each server group has a coordinating node and multiple worker nodes. Applications send their queries to the coordinating node (applications cannot connect directly to worker nodes), and the coordinating node forwards them to the relevant worker nodes and consolidates their results.
Large-scale (Citus) clusters allow the DBA to define table slicing rules to store different rows on different worker nodes. Distributed tables are the key to strong performance in large scale (Citus) clusters. An unsliced table would have the data entirely on the coordinating node, which means that the parallelism advantage of multiple machines cannot be taken advantage of.
For each query on a distributed table, the coordinator decides to route it to a single worker node or parallelize it to multiple nodes, depending on the distribution of the required data. The coordinator decides how to do this by querying metadata tables that keep track of the DNS names and operational status of the worker nodes, as well as the distribution of data across the nodes.
Table Type
There are three types of tables in a large scale (Citus) cluster server group, each stored differently on nodes and used for different purposes.
-
Distributed Tables
Distributed tables are like normal tables for SQL statements, but they are partitioned horizontally between the working nodes. This means that the rows of the table are stored on different nodes (in segmented tables called slices). Large-scale (Citus) clusters run not only SQL across the cluster, but also DDL statements. Changing the schema of a distributed table cascades the updates of table slices on all working nodes.
Large-scale (Citus) clusters use a sharding algorithm to store rows on different nodes, which is determined by the distribution column that must be specified by the DBA or cluster administrator when the table is distributed. The choice of this column is important for performance and functionality.
-
Referencing Tables
A reference table is a special type of distributed table whose entire contents are concentrated in a slice. The slice is replicated to each worker node. Queries from any worker node can be performed locally without requesting rows from other nodes, saving network overhead. Reference tables do not have distribution columns, because there is no need to distinguish separate slices for rows.
The reference table is typically small and is used to store data related to queries running on any worker node. Enumerated values are an example, such as order status or product categories.
-
Local Tables
When you are using a large-scale (Citus) cluster, the coordinator node you connect to is a regular PostgreSQL database. You can create regular tables on the coordinator and choose not to slice them.
A good scenario for local tables is small administrative tables that do not participate in join queries. A good example is the user table used for application login and authentication.
Slicing
Moving on from the above section, the technical details of sharding are discussed.
The pg_dist_shard metadata table on the coordinator records information about each shard for each distributed table in the system. This information is a match between the slice ID and a range of integers in the hash space (shardminvalue, shardmaxvalue).
|
|
If the coordinator node wants to determine which slice holds the row of github_events, it hashes the value of the distribution column in that row. Then it checks which slice’s range contains the hash value. The range is defined so that the image of the hash function is their disjoint set.
Assume that slice 102027 is associated with the row you want to request. The row is read or written in a table named github_events_102027 on one of the worker nodes. Which worker node? This is entirely determined by the metadata table. The mapping of slices to worker nodes is called slice placement.
The coordinator node rewrites the query as a slice that references a specific table (such as github_events_102027) and runs those slices on the appropriate worker node. The following is an example of running a query in the background to find the node holding slice ID 102027.
Table Colocation
Table Colocation means that related information is stored together on the same node. This saves network overhead by getting the desired data from one node at a time, and queries can be faster. Placing related data on different nodes allows queries to run efficiently and in parallel on each node.
If the value corresponding to the distribution column of a row falls within the hash range of a slice after hashing, the row is stored in that slice. Tracts with the same hash range are always placed on the same node. Rows with equal distribution column values are always located on different slice tables of the same node.
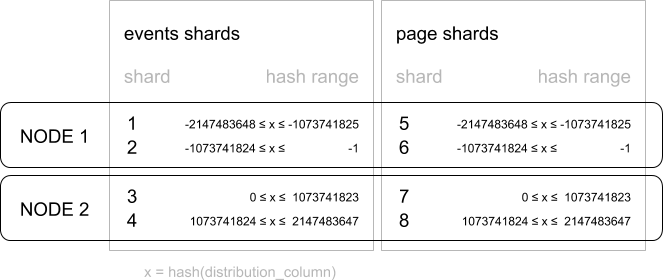
Consider the following tables that might be used by a web analytics system for a SaaS multi-tenant scenario.
Consider a query that might be launched by the Dashboard for this system’s web page: “Return the number of visits to all pages in Tenant 6 that start with ‘/blog’ in the past week”.
If our data exists in a single server, we can easily do the query using the following SQL.
|
|
When using large scale (Citus) clusters, certain modifications are required and there are two main options for sharding.
-
Sharding by ID
As the number of tenants increases and the data grows across tenants, single server queries start to slow down and both memory and CPU can become bottlenecks.
In this case, large-scale (Citus) clustering comes in handy. When we decide to slice, the most important thing is to determine the distribution columns. For now, try using
event_idandpage_idas the distribution columns for theeventandpagetables, respectively.When data is scattered across different worker nodes, we can’t perform join operations like we can on a single PostgreSQL node. We need to initiate two queries.
1 2 3 4 5 6 7 8 9 10-- (Q1) get the relevant page_ids SELECT page_id FROM page WHERE path LIKE '/blog%' AND tenant_id = 6; -- (Q2) get the counts SELECT page_id, count(*) AS count FROM event WHERE page_id IN (/*…page IDs from first query…*/) AND tenant_id = 6 AND (payload->>'time')::date >= now() - interval '1 week' GROUP BY page_id ORDER BY count DESC LIMIT 10;Running these two queries will access the data in the shards that are scattered across the nodes.
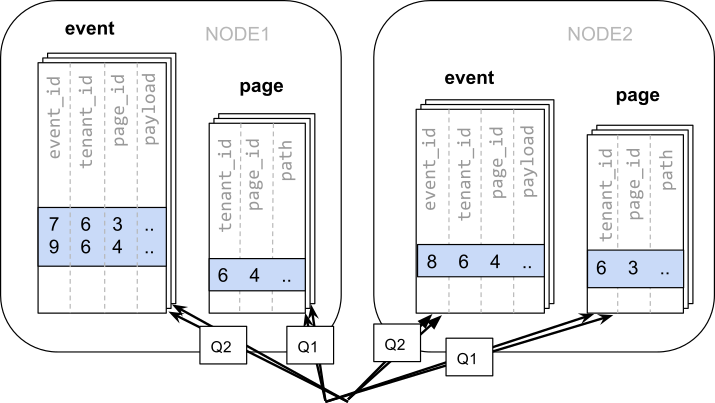
Afterwards, the application is required to integrate the results of these two steps.
In this case, data distribution creates significant drawbacks:
- the overhead of querying each slice and running multiple queries.
- the overhead of Q1 returning many rows to the client.
- Q2 becomes very large.
- Partitioning into multiple queries requires changes to the application.
Data is decentralized, so queries can be parallelized. It is only beneficial if the query is much larger than the overhead of querying many splits.
-
Slice by Tenant
In a large scale (Citus) cluster, rows with the same distribution column value are guaranteed to be located on the same node. Thus, it is only appropriate to choose
tenant_idas the distribution column.This way, no modifications are required for original queries that can be run on a single PostgreSQL node.
Because of the filtering and joining of tenant_id, large scale (Citus) clusters know that the entire query can be responded to by using a same-location slice set containing that particular tenant’s data. A single PostgreSQL node can respond to a query in a single step.
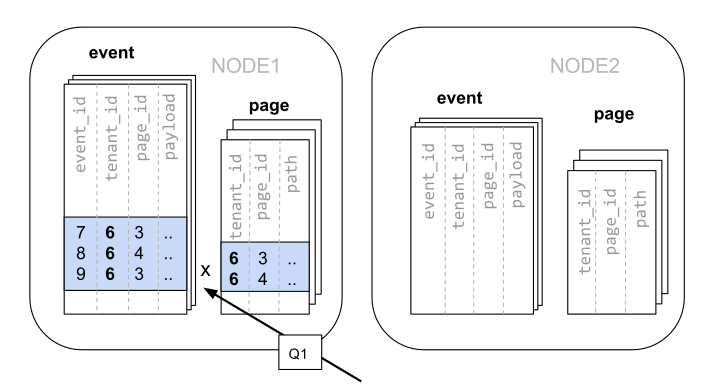
In some cases, the query and table schema must be modified to include the tenant ID in the unique constraints and join conditions. This modification is relatively straightforward.
This completes our initial look at the three types of PostgreSQL services offered by Azure.