1 Preface
Caching can be a powerful tool for high-performance systems, and it can be found in many systems. When cache resources are tight, we always expect cache entries that will be used in the future to remain in the cache, and eliminate cache entries that will not be used in the future. According to the locality principle of caching, the more recently accessed cache entries are more likely to be used again in the future, and the most recently accessed cache entries are more likely to be used again in the future. That is, the ideal cache item elimination mechanism needs to consider two main constraints: the time of recent accesses and the frequency of cache item accesses. In most of the currently used in-heap local caches, the elimination mechanism focuses on one of these constraints, either on the time of recent access (LRU) or on the frequency of recent access (LFU), while caffeine considers both constraints together and is a near-optimal cache. Currently, caffeine cache can be said to be the king of local caching within the java heap, and it is the more ideal local caching solution that I have learned about, and there is a lot to learn and learn from its design ideas.
2 Mainstream cache elimination mechanisms
Cache elimination mechanisms mainly answer the question of which cache items are eliminated at what time, and the mainstream elimination mechanisms are as follows.
2.1 Access time
As long as the last access time of a cache item exceeds a certain time value, the cache item is eliminated and evicted from the cache (evict), regardless of how much space is actually used by the current cache and regardless of the high probability that the eliminated cache item will be used in the future. Access can be either write (expireAfterWrite) or read/write (expireAfterAccess). For expireAfterWrite, the cache item is eliminated as soon as it has been written to the cache for a certain amount of time; for expireAfterAccess, the cache item is eliminated after a certain amount of time when it has neither been read nor written (updated). The time to trigger the expiration judgment can be when the cache item is accessed (to determine if the cache item is timed out when reading the cache item), or it can be a timed task cycle to scan the cache to determine if a cache item has timed out, or it can be when there is not enough cache space to scan the cache to determine if a cache item has timed out. Many caches such as redis and caffeine support this kind of elimination mechanism.
2.2 Weak reference and soft reference
The key and value of a cache item are weakly or softly referenced, so that if the cache item is not used in the business (strong reference), the JVM automatically recovers the cache item object during garbage collection (GC) to achieve the elimination of the cache item. guava cache and caffeine both support this elimination mechanism.
2.3 Cache space
The system generally limits the maximum space of the cache. When the cache is full and new cache items need to be written, there needs to be a mechanism to determine which cache items are eliminated from the cache.
2.3.1 FIFO
Set the maximum space of FIFO, the first cache item into the FIFO (write cache) is eliminated first, regardless of whether the eliminated cache item has been accessed later (read or write), the FIFO approach is very simple to implement, but the cache hit rate (hit rate) is not ideal, the general-purpose cache is basically not considered.
2.3.2 LRU
LRU (Least Recent Use) actually sorts the cache items based on their last access time (read or write), the cache items with the earliest access time (i.e. furthest from the current time, the oldest cache items) are eliminated first, and the cache items with the last access time closest to the current time (the meaning of last recent) are kept. the advantage of LRU is that Because the most recently accessed cache items are kept, the probability of these cache items being used again is relatively high according to the locality principle, so the hit rate of LRU is still good, and at the same time, the implementation of LRU is relatively simple (although a bit more complex than the FIFO approach), and an intermediate to senior java developer can implement a basic functional LRU cache without much cost, so LRU’s are used very frequently. The cache we see in most systems is basically an LRU cache. lRU can handle a small amount of sparse traffic very well (sparse burst, i.e., not used after a few uses in a short period of time), but it cannot handle a large amount of sparse traffic, because it will then eliminate the cache items that are used very frequently, and these caches will be accessed frequently later. For example, some patrol items in the system write a lot of cache items that are only used once to the cache, thus crowding out which cache items are really used frequently.
2.3.3 LFU
LFU (Least Frequecy Use) keeps the cache items that are accessed frequently, taking into account the time factor, for example, if one cache item has been used 50 times in the last 100ms and another cache item has been used 50 times in the last 200ms, there is no doubt that the cache item that has been used 50 times in the last 100ms should be kept as a priority. The advantage of LFU is that the most recently used cache items are retained, and the probability that these cache items will be used again in the future is very high, which is very much in line with the needs and goals of the system.The disadvantages of LFU are
- the frequency statistics need to be maintained for each cache item, and the corresponding statistics need to be updated for each access, which requires some storage and performance overhead. Also, how the maintained frequency information reflects the most recent (last) is a less manageable problem. If the frequency counter only maintains the number of visits in a specified recent period, then the corresponding logic is needed to clear the statistical frequency before that period.
- scenarios where sparse traffic (sparse burst) cannot be handled. Because sparse traffic has only a small number of visits, it is at a disadvantage when comparing visit frequencies to decide whether to stay or go, which may lead to frequent elimination of sparse traffic cache items and frequent failure to hit access sparse traffic.
3 caffeine cache core principle
The caffeine cache uses the W-TinyLFU algorithm, which combines the advantages of LRU and LFU and properly improves the disadvantages of LRU and LFU.
3.1 Count-Min Sketch Frequency Statistics Method
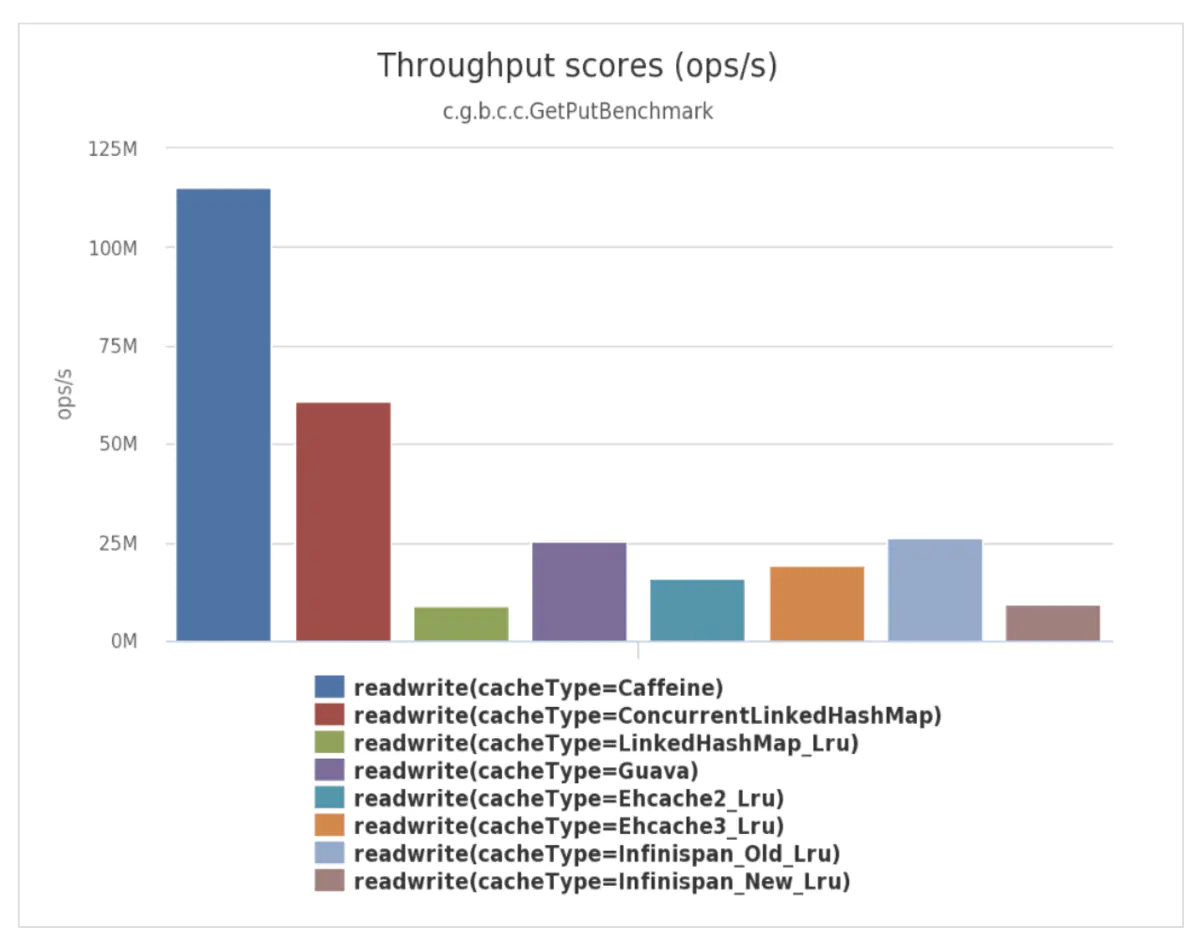
To solve the first drawback of LFU introduced above, the LFU frequency statistic method of caffeine cache uses the Count-Min Sketch algorithm. This algorithm borrows the idea of boomfilter, except that the value corresponding to the hash key is not a true or false flag indicating the existence, but a counter. It uses four hash functions, and the four hash functions simultaneously calculate the hash value for the cache item key, adding one to the counter corresponding to the hash value. The counter only has 4 bits, so the counter can only count up to 15, and when it exceeds 15, it will keep 15 unchanged and will not increase the count upwards. The counter can only count up to 15, the capacity is smaller than the pre-tuning, but from the actual test, the effect is better than the pre-tuning. Because of the positive false problem of bloomfilter (in fact, there is a hash conflict), the frequency value of the cache item takes the minimum value of the four counters (this is the meaning of Count-Min). When the sum of all counter values exceeds a set threshold (default is 10 times the maximum number of cache items), all counter values are reduced to half of their original value.
The detailed implementation scheme of the Count-Min Sketch algorithm is as follows.
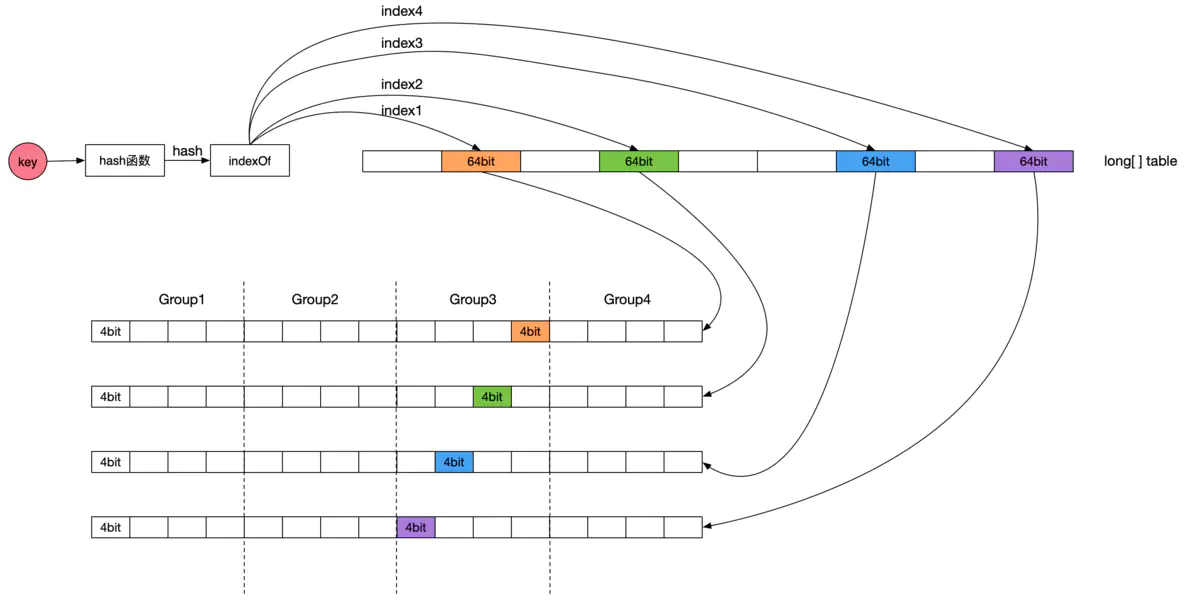
Count-Min Sketch maintains a long[] table array, the size of which is the cache space capacity (the maximum number of cache items) rounded up to the nth power of 2. The counter of Count-Min Sketch is 4 bits, and the size of each element of the table array is 64 bits, which is equivalent to the table element containing 16 counters. The 16 counters are further divided into 4 groups, so each group contains 4 counters, which is exactly equal to the number of bloom hash functions, and the four counters of the same key use the counters of the corresponding positions in the group. Each table element contains 16 counters, and the offset of the 4 hash counters in the corresponding table element is not the same, which can effectively reduce hash conflicts.
The process of counting cache items is as follows: first calculate the hash value of the cache item key, and then use four different seed values to calculate the subscripts of the four elements of the table array respectively. The first counter position is the first counter in the corresponding group of the first table array element, the second counter position is the second counter in the corresponding group of the second table array element, the third counter position is the third counter in the corresponding group of the third table array element, and the fourth counter position is the third counter in the corresponding group of the third table array element. element and the fourth counter position is the fourth counter in the corresponding group of the fourth table array element.
From the description of Count-Min Sketch frequency statistical calculation method, it can be seen that the counter size is only 4bit, which greatly reduces the storage space requirement of LFU frequency statistics. At the same time, the upper limit of counter statistics is 15 and all counter values are halved when the count sum reaches the threshold, which is equivalent to the introduction of count saturation and decay mechanism, which can effectively solve the problem that sudden large traffic cannot be effectively eliminated in a short period of time. For example, there is a burst hot event, which has hundreds or thousands of times more visits than other events, but the hot event cools down quickly, and the traditional LFU elimination mechanism will keep the cache of the event in the cache for a long time without eliminating it, although the type of event has been visited very little or no one is interested in it anymore.
3.2 W-TinyLFU algorithm
As mentioned above, the LFU of caffeine cache uses the Count-Min Sketch frequency statistical calculation method, and the counter of this LFU is only 4bit in size, so it is called TinyLFU. TinyLFU solves the first problem listed above for LFU, but does not solve the second problem. The second problem listed above is solved by introducing a Window Cache based on LRU based on TinyLFU algorithm, and this new algorithm is called W-TinyLFU (Window-TinyLFU).
The framework of the W-TinyLFU algorithm is shown below.
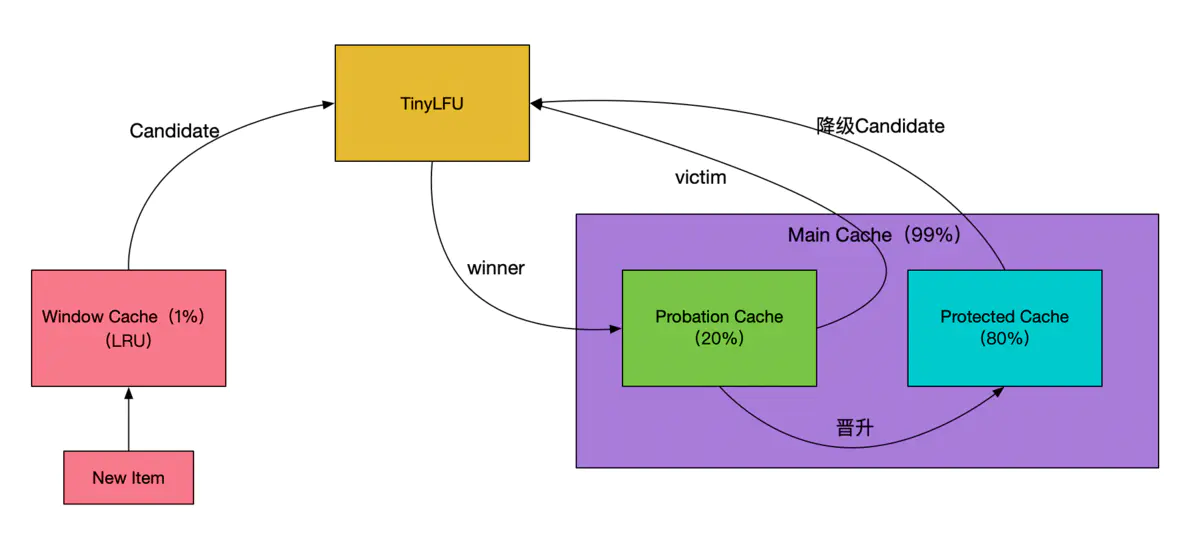
W-TinyLFU divides the cache storage space into two large areas: Window Cache and Main Cache. Window Cache is a standard LRU Cache and Main Cache is a SLRU (Segmemted LRU) cache, as Main Cache is further divided into Protected Cache (Protected Area) and Probation Cache (Observation Area), both of which are LRU-based Cache. protected is a protected area in which cache items are not eliminated. probation area, on the other hand, is an observation area, and when a new cache item needs to enter the If the Probation area is full, the new cache entry is compared with the cache entries in the Probation area that need to be eliminated (evict) according to the LRU rule, and the failed entries are eliminated and the winning entries are entered or kept in the Probation area. window Cache defaults to The Window Cache defaults to 1% of the total cache size, and the Main Cache defaults to 99% of the total cache size. the Protected Cache defaults to 80% of the Main Cache size, and the Probation Cache defaults to 20% of the Main Cache size. Of course the size of these cache areas will be dynamically adjusted.
When a new cache item is written to the cache, it is first written to the Window Cache area, and when the Window Cache space is full, the oldest cache item is moved out of the Window Cache. if the Probation Cache is not full, the cache item moved from the Window Cache is written directly to the Probation Cache; if the If the Probation Cache is full, the cache items removed from the Window Cache will be discarded (eliminated) or written to the Probation Cache according to the TinyLFU algorithm; if the cache items in the Probation Cache are accessed a certain number of times, they will be promoted to the Protected Cache; if the If the Protected Cache is also full, the oldest cache items are also moved out of the Protected Cache, and then the TinyLFU algorithm determines whether they are discarded (eliminated) or written to the Probation Cache.
The TinyLFU elimination mechanism is.
The cache item removed from Window Cache or Protected Cache is called Candidate, and the oldest cache item in Probation Cache is called Victim. if the access frequency of Candidate cache item is greater than the access frequency of Victim cache item, then Victim is eliminated. if Candidate is less than or equal to the frequency of Victim, then if the frequency of Candidate is less than 5, then Candidate is eliminated; otherwise, one of Candidate and Victim is eliminated randomly.
From the above description of the principle of W-TinyLFU, we can see that caffeine integrates the advantages of LFU and LRU, and stores cache items with different characteristics in different cache areas, the recently generated cache items enter Window area and will not be eliminated; the cache items with high access frequency enter Protected area and will not be eliminated; the cache items in between exist in When the cache space is full, the cache items in the Probation area will be kept or eliminated according to the access frequency; through this mechanism, the two dimensions of access frequency and freshness of access time are well balanced, and fresh cache items with high access frequency are kept in the cache as much as possible. At the same time, when maintaining the access frequency of cache items, a counter saturation and decay mechanism is introduced, which saves storage resources and can also better handle scenarios that cannot be handled well by traditional LRU and LFU, such as sparse traffic and short-time super-hot traffic.