This article describes the steps a process born from a Linux shell has to go through to become a daemon process.
A background process, as you can imagine, executes in the background, without a terminal, without a login shell, and processes when certain Events occur, or periodically performs a task. Usually, daemon processes end in d, but it is not required. For example, the daemon processes for Redis and Nginx do not end in d. In short, a daemon needs to have two basic requirements:
- be a child of the init process.
- not connected to any terminal.
In addition, the daemon process usually does several things.
- Close all file descriptors, especially input output error. because these file descriptors may be shells, or other processes. You can use the
open_maxorgetrlimitsyscall to get the largest file descriptor currently open, and close it in order. You can also iterate through the files under/proc/self/fdand close them in order. - Switch the working directory to the / directory. daemon’s lifecycle usually lasts for the entire operating system, so if it keeps working in the working directory inherited from the parent process, it will affect the file system mount operations during the operating system. Some processes can also switch to work in their own specific directories
- Set umask to its default value, usually 0. This is because the daemon process will want to set its own file permissions when it creates a file, without the interference of umask. If a third-party library is used, the daemon can set the umask value itself and restrict the permissions of the third-party library used.
- leave the process group of the parent process so that it does not receive the SIGHUP signal.
- leaving the controlling terminal and ensuring that it will not be reassigned to it in the future either.
- Handle the SIGCLD signal.
- Redirects stdin stdout stderror to
/dev/null. This is because processes running in the background do not require user input and have no standard output. This also ensures that the daemon’s output is not seen when other users login the shell.
This is what daemon processes typically do, and is described in more detail in man 7 daemon. Next, the best part of daemon is discussed, which is how it finishes detaching from the terminal with two fork()s.
two times fork()
The previous section describes some of the simpler processes, such as chdir, reset umask, etc. The next section discusses how to get out of terminal.
To make it easier for the reader to understand, I’ll draw a diagram and label what changes occur at each step of the action, and then explain exactly what happens.
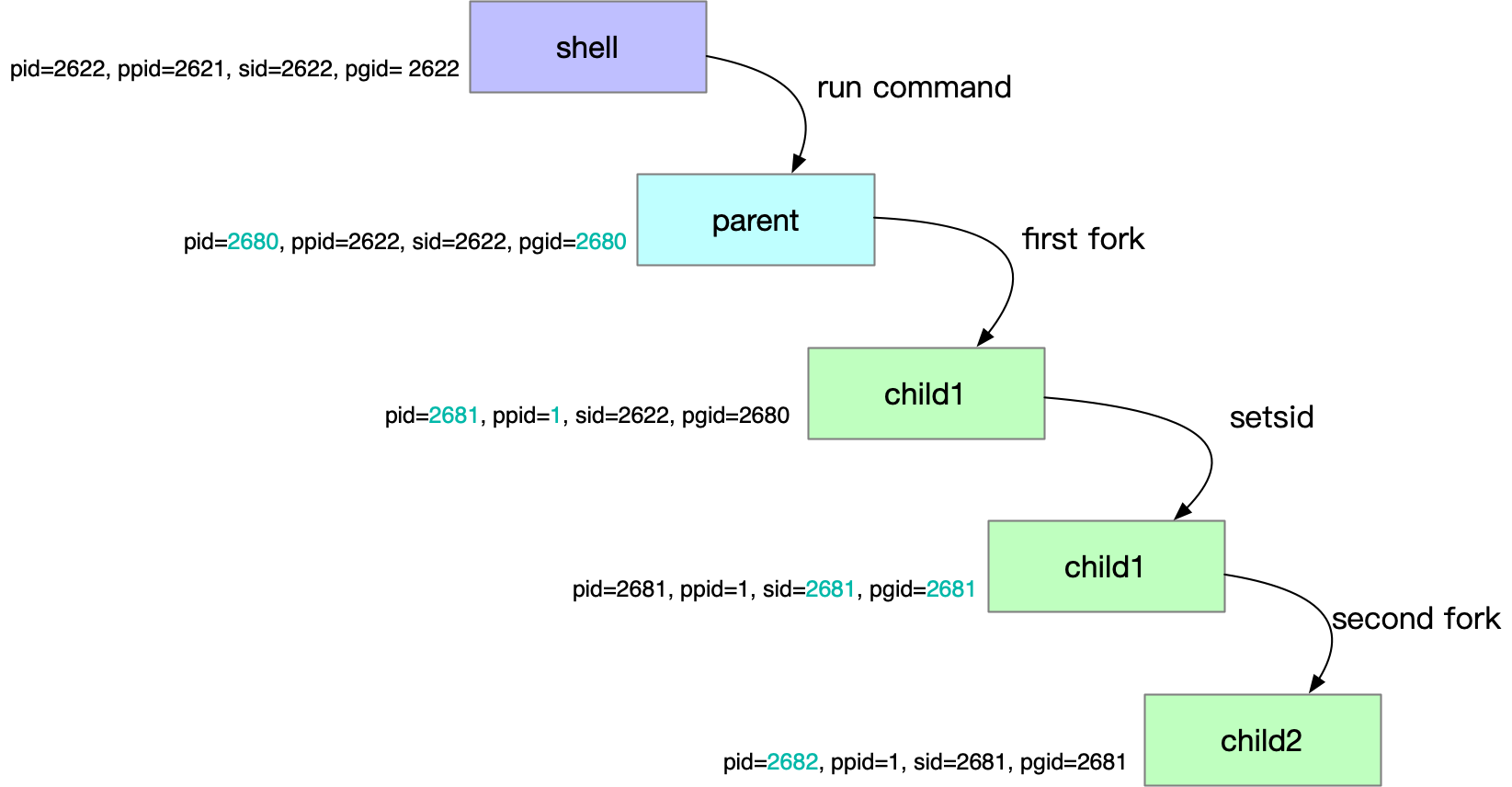
The shell creates processes. 1) What is a pid? The kernel assigns a pid. 2) What is a ppid? The process that created this process, that is, the parent process, here is the shell’s pid. sid What is it? 3) sid refers to the session id, this article does not introduce too much, the reader can think of the shell and the shell in a group of session processes, so that when the shell exits will give the session leader id for the shell id processes are When the shell exits, it will send a SIGHUP to all processes with the shell id, and the child processes it created will all exit together, which is convenient for management. So, the sid of the newly created process is also shell pid, which is automatically added to the shell’s session. 4) What is pgid? pgid is process group id, which is a group of process ids. consider this command: grep GET accessl.log | awk '{print $1}' | sort | uniq, if we want to end this command, we will not want to grep, awk… but want to end them all one by one. To make it easier to manage, the shell will put such pipelined processes into a group, so that they can be terminated together by pgid for easy management. So, the pgid of a newly created process is itself, and it is also called group leader.
First fork(). When fork() is called, the parent process exits immediately (for the sake of subsequent discussion, we will call this child process child1). First, the process is started from the shell, and if it doesn’t end, the shell’s command line will be blocked here, and this time fork() makes the shell think that the parent process has ended properly. Second, when child1 forked out, it joined the progress group of the parent process by default, which makes child1 no longer a group leader (its pgid is not equal to pid), which is a requirement for calling setsid. In fact, since the parent process exited, the process group child1 is in is already an Orphaned Process Group. Third, since the parent process has exited, child1’s parent process is the init process.
setsid. Since the child’s sid is still the shell’s id, it will still be taken away when the shell exits. But after setsid, its pgid and sid are both equal to its pid, which means it becomes the session leader and group leader. This is actually the reason why we need to fork a second time, and it is also the place where I was most confused and spent the most time to understand.
Second fork(). Why do I need a second fork()? I have read a lot of incorrect Stack Overflow discussions on this issue, and there is no implementation of a second fork(), for example, the daemon code in Linux System Programming 5.7 Daemons does not have a second fork(), and the man 3 daemon provided by the Kernel does not have a second fork. The reason for the second fork() is simple: if a process is a session leader, it still has a chance to get tty (on SysV-based systems), and we want to make sure that it cannot get tty by fork() again and exiting child1 to make sure that child2, which will eventually provide daemon child2 is not a session leader.
This process can also be seen in the daemon function inside daemonize, which is the same as the above process.
I wrote a code to demonstrate twice fork() various pid changes, the result will be the same as the above figure.
|
|
The results of the run are as follows.
Protocol Mismatch
If you use systemd as a task control mechanism, be aware that you need to set up your process according to these system-defined readiness protocols, i.e. you can delegate things like chdir, umask to systemd, but you need to follow systemd’s protocols to tell it that your process is ready to be served.
A common mistake is to fork() twice in your own process, but use Type=simple in systemd, thinking that this is telling systemd that your process is a normal process that handles its own daemon, when in fact it is telling systemd that your process is ready immediately after it starts. The process that ExecStarted is the target process, so when the parent process fork() and exits for the first time, systemd thinks your process is hung. Many times, when you control a service like Redis Nginx with systemd, it always times out, usually because of this same problem. There are many examples of common errors here, so I won’t explain them one by one, and I’ll write another article to introduce the use of systemd.