Recently, Docker founder Solomon Hykes announced the launch of a new product Dagger, a new DevOps platform designed to solve some of the problems in the DevOps process for developers. Dagger has raised $20 million in Series A funding led by Redpoint Ventures, with participation from Nat Fireman, former CEO of GitHub, Brian Stevens, former CTO of Red Hat, and Ellan Pao, former CEO of Reddit.

Dagger wants to help DevOps developers write CI/CD pipelines as declarative models in CUE, so that they can describe their own pipelines and interface the various parts of them, all in pure code.
Install
If you are on macOS and have Homebrew installed, you can use the following command to install dagger with one click.
|
|
The above command will install dagger into the /opt/homebrew/bin directory.
If you do not have Homebrew or another system installed, or if you want to install a specific version of dagger, you can use the following command to do so.
Since dagger uses Docker to perform tasks, you need to install and run the Docker Engine before you can use it officially.
Example
Now let’s use the official todo sample application to demonstrate how to use dagger to run its CI/CD pipeline.
First get the sample application code.
Go to the root of the sample application code and execute the dagger do build command to execute the CI/CD pipeline.
The first time the task is executed, the test build for the sample application takes a while to complete because there is no cache and all dependencies need to be installed.
The above result shows the execution of our build command above, which takes place in a local container named dagger-buildkitd throughout the execution process.
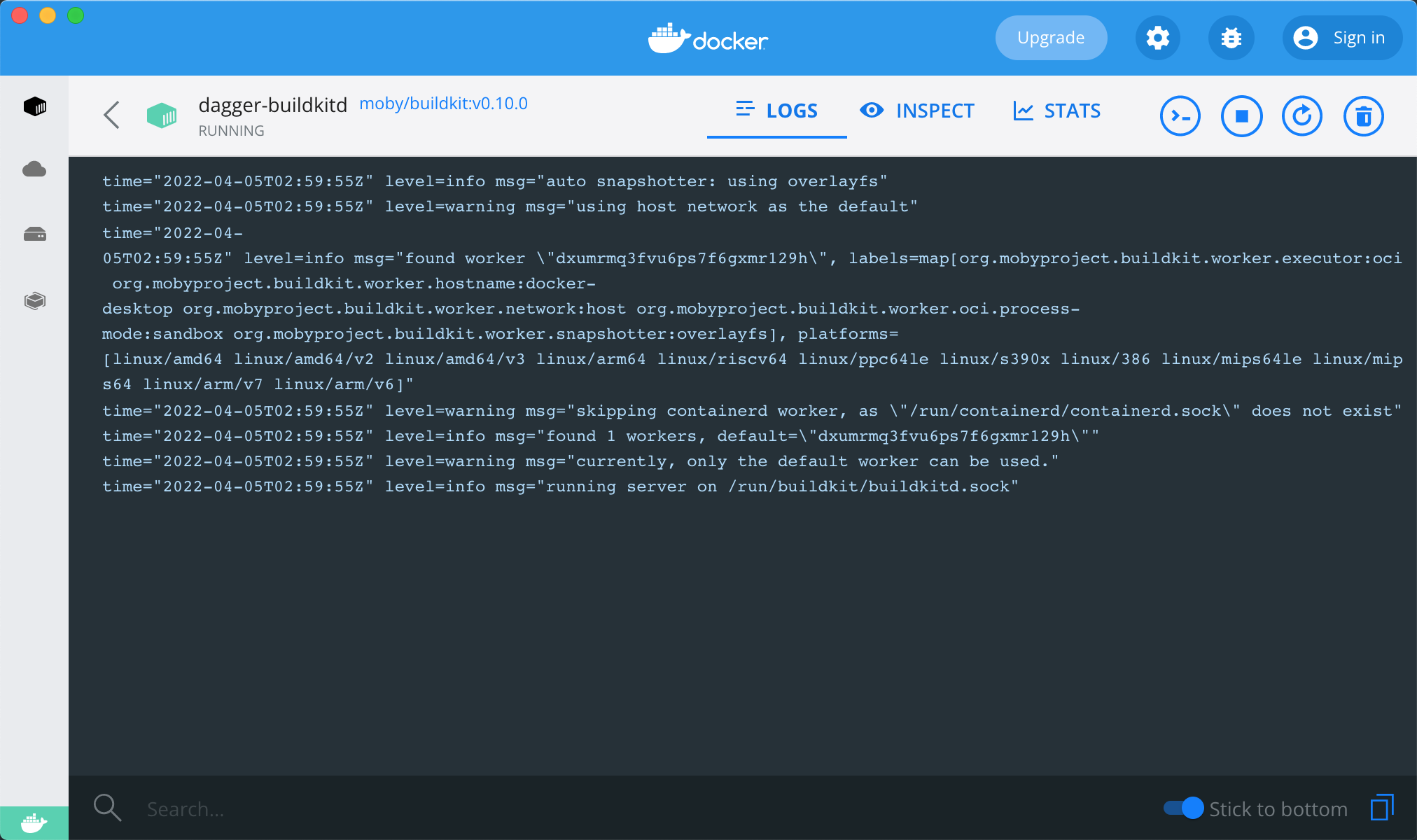
This proves that dagger is going to execute the task in Docker’s execution engine BuildKit.
Since this is a static application, we can open the final generated file in the browser, here we are defining the final copy of the build result to the _build directory on the host. We can execute the open _build/index.html command to preview the application.
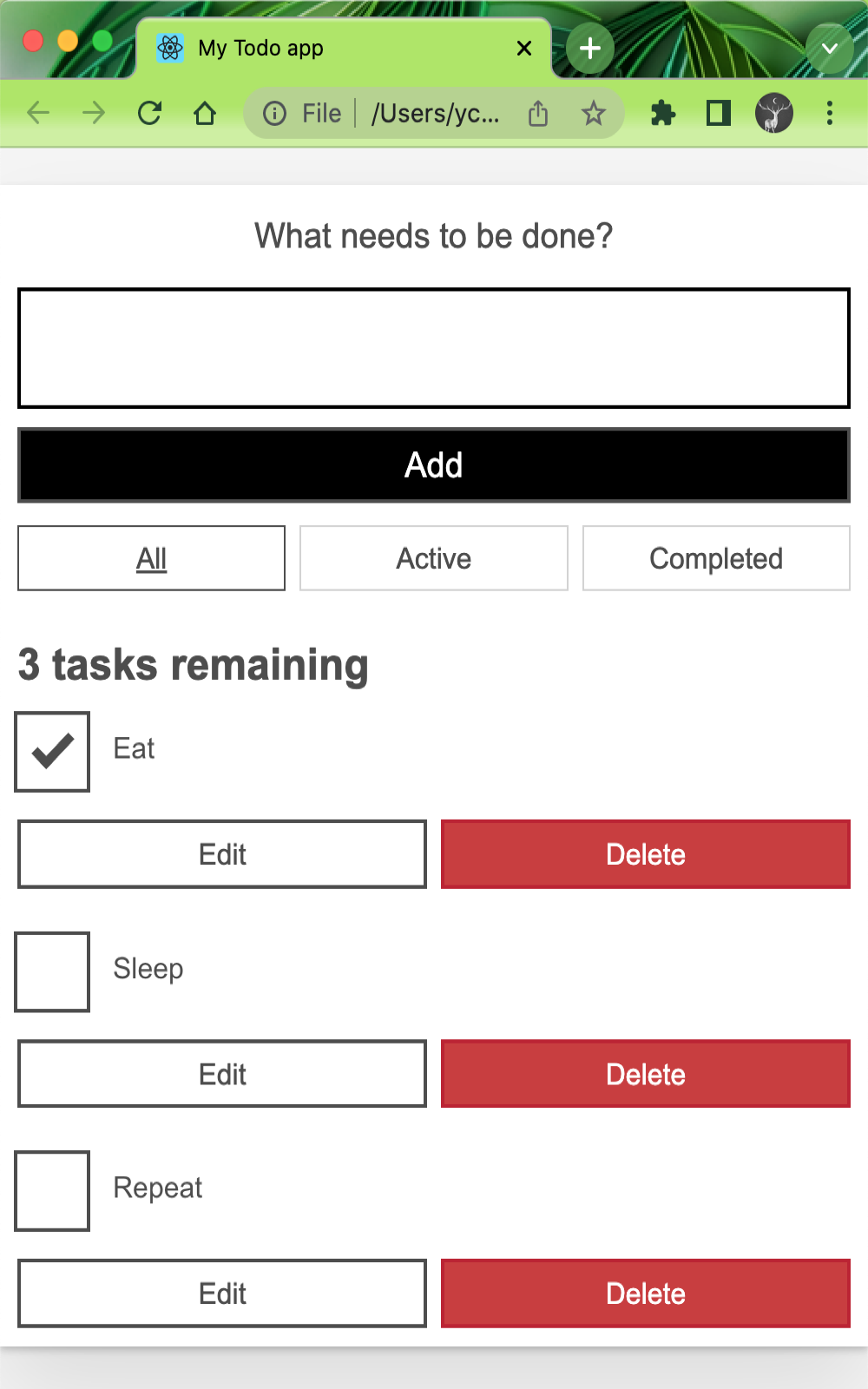
Now we don’t need to install any application-specific dependencies, dagger manages all these intermediate steps, and with dagger we don’t need to commit and push the code every time to see the results of the application, and each executed action is cached so that subsequent runs are very fast.
For example, in the todoapp directory, edit line 25 of src/components/Form.js, change the line to What must be done today? and save the file, then run the build command locally again.
We can see that the execution time of the entire pipeline has been drastically reduced and the results are output correctly.
Pipeline Definition
dagger uses the CUE language to define the pipeline, so we have to understand the language first, as we described in the previous article about the basic use of the CUE language.
The pipeline definition for our sample application here is shown below.
|
|
The CUE file above shows that the dagger pipeline starts with a #Plan in which we can.
- interact with the
clientclient file system.- read files, usually using
.for the current directory. - write to files, usually build output as
_builddirectory.
- read files, usually using
- Read environment variables, such as
NETLIFY_TOKENas defined above. - Declare some actions, such as test, build, deploy, etc. The names of the actions can be arbitrary.
The overall architecture of the pipeline we defined above is shown below, where the client section defines client-related interactions and the actions section defines the pipeline actions.
|
|
When we executed the dagger do build command earlier, the following output was generated.
Since we only execute the build action, no deploy related information appears. We can choose to run a specific action by simply specifying the action name after dagger do <action>, and since the input to the build action is the test.output, we will also execute test. Similarly the input to the test action is the output of deps, so that action will be executed as well.
Each specific action is basically defined using a package that is imported off-the-shelf. For example, the build action defines the flow of execution via bash.#Run, and the code is shown below.
So the output of the test action is used as the input to this project via input: test.output, then the directory to mount is specified via mounts, so that the cached nodemodules directory can be used, workdir specifies the working directory as /src, and then the script specifies the command to execute The overall definition structure is actually defined by base.#Run, which can be found in the package universe.dagger.io/bash.
To improve the developer experience, dagger has released a toolkit library called Dagger Universe to help developers import their own Dagger configurations flexibly, and many of the pipelines above are defined in that toolkit.
Client-side interaction
For details on what properties or operations can be defined in dagger.#Plan, we can look at the code in the imported package dagger.io/dagger at https://github.com/dagger/dagger/blob/main/pkg/dagger.io/dagger/plan.cue. This file defines all the properties of #Plan, such as client-side interaction via client.
Accessing the file system
Access to the filesystem can be defined via client.filesystem.
|
|
Get Local Socket
|
|
Environment Variables
Environment variables can be read from the host as strings or Secret, just specify the type.
Execute commands
Sometimes you need to execute some local commands, which can also be defined in client.
Get platform information
You can get platform information via client.platform.
Building an image
Again, we can use dagger to build the container image. The code is shown below.
|
|
Here we import the universe.dagger.io/docker package, so a docker.#Dockerfile definition is used in the build action, which first reads the ./src directory, then specifying the build context in the build action, and then defining the Dockerfile to use directly via dockerfile.contents, or we can just provide a build context in the ./src directory.
In addition to using the Dockerfile directly, we can also build the image directly in CUE, as shown in the code below, which is exactly the same as the result above.
|
|
Here we are using the docker.#Build definition for configuration. steps defines the build steps, docker.#Pull specifies the base image, docker.#Copy copies the source file directory, docker.#Run configures the image build command, and docker.#Set specifies the image start command. This is actually equivalent to implementing the Dockerfile declaration through CUE.
Summary
dagger uses the CUE language to configure the pipeline, so this naturally adds a bit of a barrier, but if you get familiar with CUE, you’ll find that dagger’s pipeline is very easy to configure, basically by looking at the package definitions and knowing how to use it.
The tagline of dagger is a portable development toolkit for CI/CD pipelines, which allows DevOps engineers to quickly build powerful CI/CD pipelines, run them anywhere, unify development and CI environments, and test and debug pipelines locally, which is undoubtedly the biggest benefit of dagger so far, but you’d say it’s going to be a disruptive product in the DevOps space? We haven’t seen any of these disruptions yet, at least not yet, but of course dagger is still in the very early stages, so maybe there will be more and more surprising features to come.