Introduction
In Increasing the Effectiveness of Directory Caches by Deactivating Coherence for Private Memory Blocks, the authors describe a dynamic predictive approach to diverting memory regions that are only used by one processor Cache performance can be improved by discarding the coherence protocol.
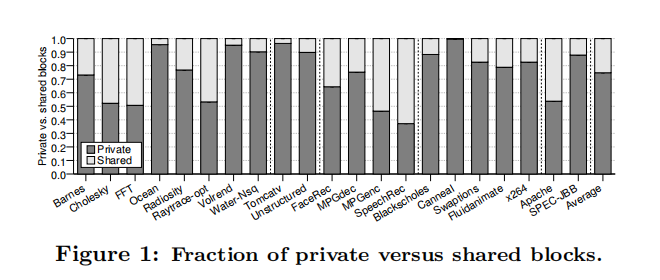
Using directory-based consistency protocols in most shared-memory multicore processors would not result in insufficient bus bandwidth, but recording all memory blocks in main memory would require the use of a large amount of storage requirements. Researchers have found that tracking most areas of memory is unnecessary because they are used by only one core, and that directory-based storage space can be greatly utilized and efficiency improved if the consistency protocol is not used for these memories.
Details
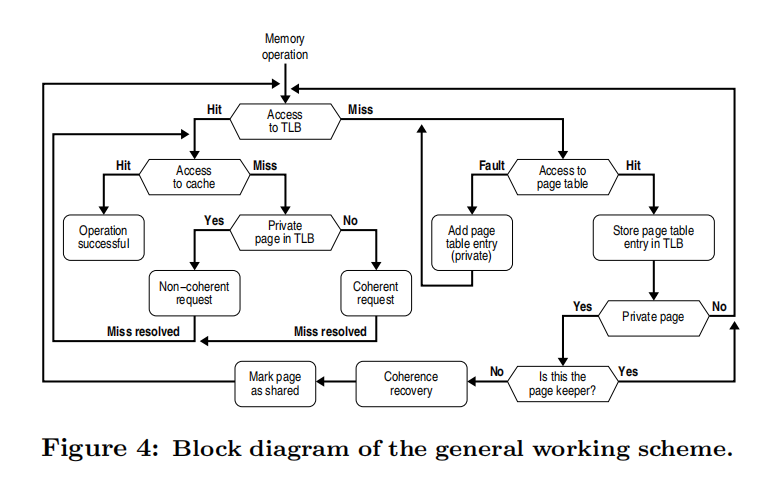
The implementation in this paper uses Page to manage memory blocks because the more fine-grained inner village is not well managed. When a Page is first loaded from main memory it is set to private and the consistency protocol is disabled. This does not require any major changes for the OS because it uses the original TLB, page table, MSHR and other structures.
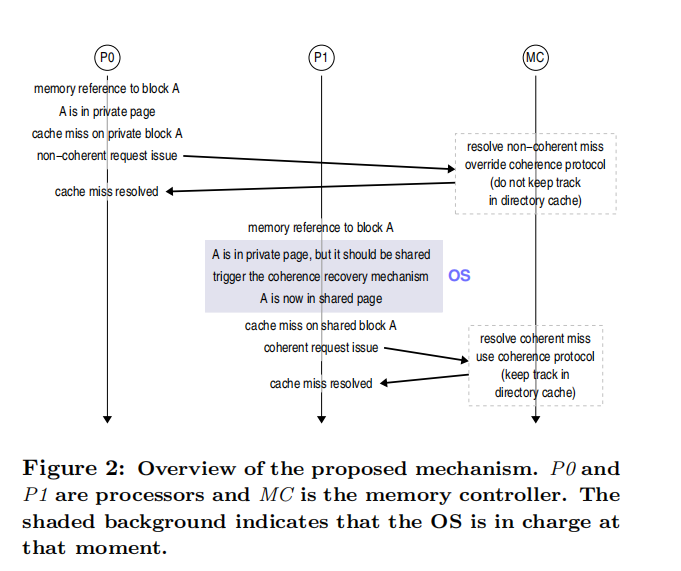
A relatively simple example is given in Figure 2 above: first, P0 processor requests memory block A from the Cache, which is not in the Cache, resulting in a Cache Miss, then the Cache reads memory block A from main memory, which is private and does not use the consistency protocol; subsequently, P1 references memory block A and a TLB Miss occurs, when the When the OS handles the TLB Miss, it will realize that the page has been asked before, and then it will trigger the hardware Cache consistency policy and set its state to shared.
In order to allow the OS to probe the memory we need to make some corresponding changes to the OS. Generally speaking, the TLB Entry contains two main parts, the tag, which holds the virtual address, and the data, which holds the physical address. In order to perform memory probing, we need to add two bits to it, one is the private bit§, which distinguishes whether the page is private or shared, and the other is the locked bit(L), which is used to avoid race conditions. We have in fact discussed above the use of the P bit, sending a non-consistent request when the page is private and a consistent request when the page is shared.
Similarly, our page table entry needs to have three additional fields: private bit§, cached-in-TLB©, keeper. if P is set to private, keeper will contain its TLB and processor identifier; and the C bit is used to indicate whether keeper is valid. After a Page Table Fault occurs, the OS will assign a new page table entry, and whenever a new page is loaded, P will be set to 1 and C will be erased. When TLB Miss occurs, the handler will search the page table and when it finds it, if C is erased, the page is still private; if both P and C are set, it will check if the page is shared. The algorithm for setting the flag bit is shown in the following pseudo-code.
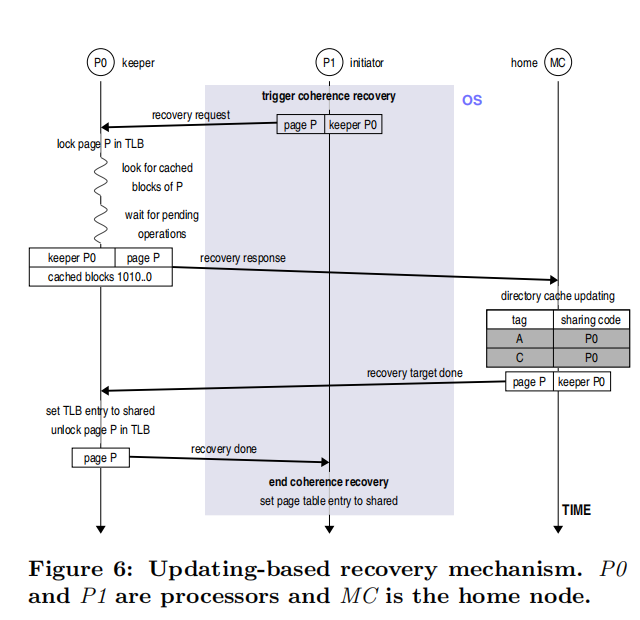
In addition, we need to consider the question of how to recover this part of memory when the page state is changed from private to shared. In the paper, two methods are mentioned, called Flushing-based Recovery Mechanism and Updating-based Recovery Mechanism respectively.
Flushing-based Recovery Mechanism Firstly, the node that triggers the consistency recovery will send a recovery request to the node involved, and before the recovery request arrives, the keeper will perform three operations. Second, the keeper performs a Cache lookup and updates each relevant Cache block and writes the data back to main memory; finally, the keeper checks its MSHR structure to see the pending operations. When any Page Block has at least one pending Miss or Evication, the keeper must wait for it to complete. Once this happens, the block in question is evicted. Afterwards, the keeper marks the corresponding TLB entry as shared, unlocks it, and notifies the initiator by resuming the completion message.
When the initiator receives the message that the recovery operation is complete, the page is set as a shared page in the page table and the local TLB, during which the OS prohibits other processors from accessing the page table entry, which would otherwise cause unpredictable results. The following figure shows an illustration of this operation.
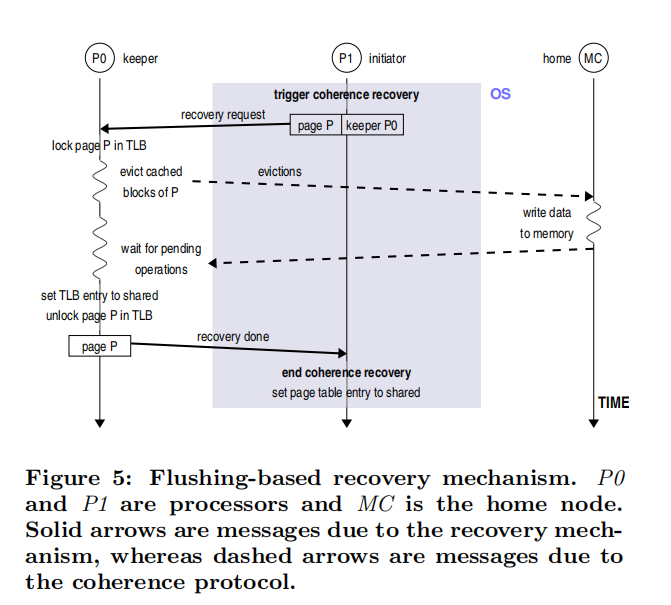
The Flushing-based Recovery Mechanism approach is simple and easy to implement, however, the disadvantage is that it needs to flush all the blocks that have been cached, which may increase the Cache miss rate and thus affect the system performance. In order to provide system performance, the paper proposes the Updating-based Recovery Mechanism model to solve the problem.
As in the previous method, the recovery request is first sent from the originating node to the keeper, and when the recovery request reaches the keeper, it locks the TLB entry and finds the blocks of the page cached in the Cache, which are encoded as bit vectors, and then a recovery response is sent to the home memory node. To simply encode the addresses of the cached blocks, they are encoded in a way similar to a unique hotcode, e.g., the first encoding is set to 1 to indicate that the first block in the page is cached. Before sending the recovery response, you still need to check the MSHR register to see if there is a pending operation, and if so, send the response afterwards, otherwise send the response directly.
When the home memory controller receives the response, it finds the corresponding address block according to the bit vector, creates a new entry in the directory cache for it, and evicts the old entry, and sends an end message to the keeper node when it is done.
When the keeper node receives the message, it unlocks the TLB entry and sets it to shared, and sends the message to the initiator (i.e., the sender). A simple illustration is shown below: