Kubernetes Multi-tenant Model
Along with the development and promotion of cloud-native technologies, Kubernetes has become the operating system of the cloud computing era. In the mainframe era, the operating system had the need for multiple tenants sharing the same physical machine resources; in the cloud computing era, the need for multiple tenants sharing the same Kubernetes cluster has emerged. In this regard, the community’s Kubernetes Multi-tenancy Working Group has defined three models of multi-tenancy for Kubernetes.
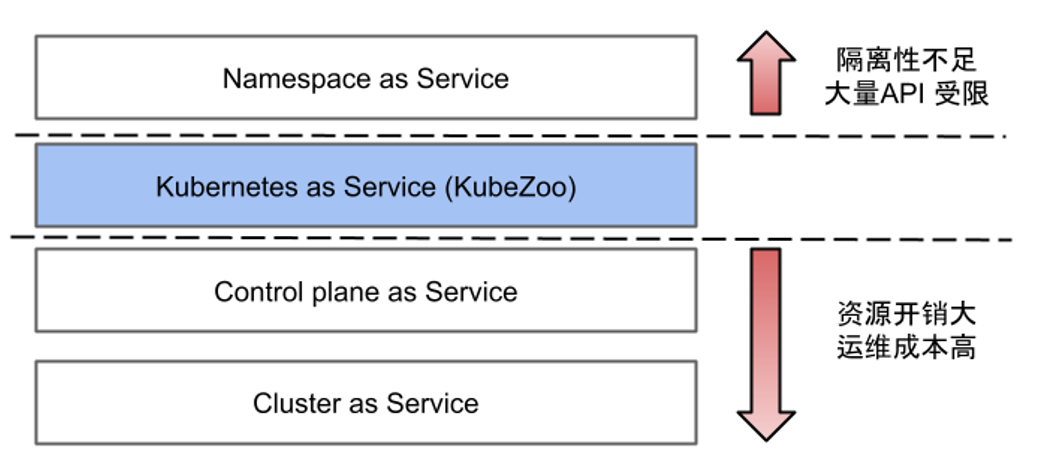
The first is Namespaces as a Service, a model in which multiple tenants share a Kubernetes cluster, with each tenant limited to its own Namespace, borrowing the isolation of the native Namespace to achieve tenant load isolation Tenants can generally only use Namespace-level resources and cannot It has limited API compatibility.

The latter two models are Clusters as a Service and Control planes as a Service. Both are physical cluster isolation solutions between tenants. Each tenant has a separate Master, which may be managed through a Cluster API or Virtual Cluster, etc. The Master is an exclusive physical resource, so each tenant has a separate set of control plane components, including API Server, Controller Manager, and its own Scheduler. Each component may also have multiple copies. Under this scenario, the tenants are independent of each other.

Why do we need to propose a new multi-tenant solution on top of the three existing models?
First, let’s look at Namespaces as a Service, which has the drawback that tenants cannot use cluster-level APIs, such as subdividing Namespace within a tenant or creating CRD resources, which are Cluster-wide resources and require system administrators to coordinate, which means that it is detrimental to the user experience.
Second, the isolation scheme of Cluster or Control plane introduces too much extra overhead, such as the need to create separate control plane components for each tenant, which reduces resource utilization; at the same time, the establishment of a large number of tenant clusters also brings the burden of operation and maintenance.
In addition, both public and private clouds have scenarios where a large number of small tenants co-exist. In these scenarios, the resource requirements of each tenant are relatively small, and at the same time, the tenant wants to use the cluster immediately after it is created.
Lightweight Multi-tenancy Solution Kubezoo
For this scenario where a large number of small tenants co-exist, we propose a lightweight multi-tenant solution - KubeZoo.
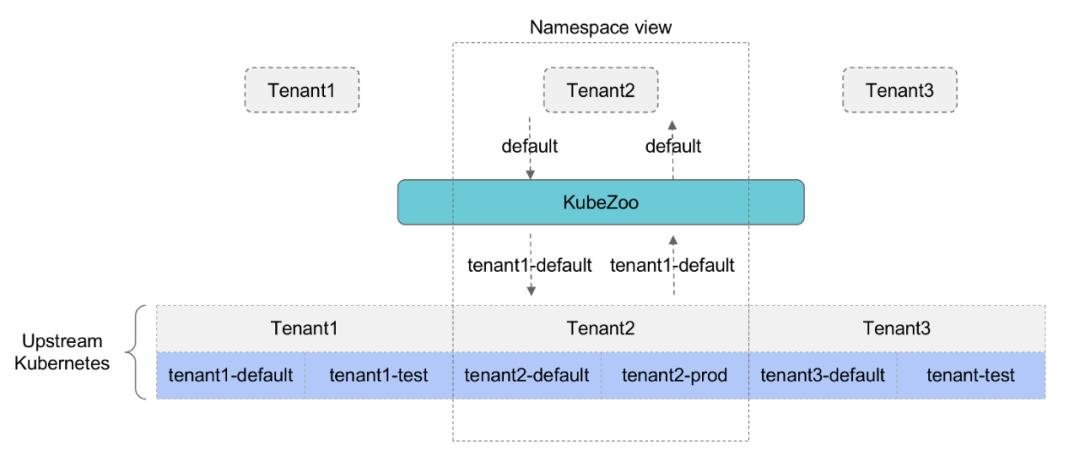
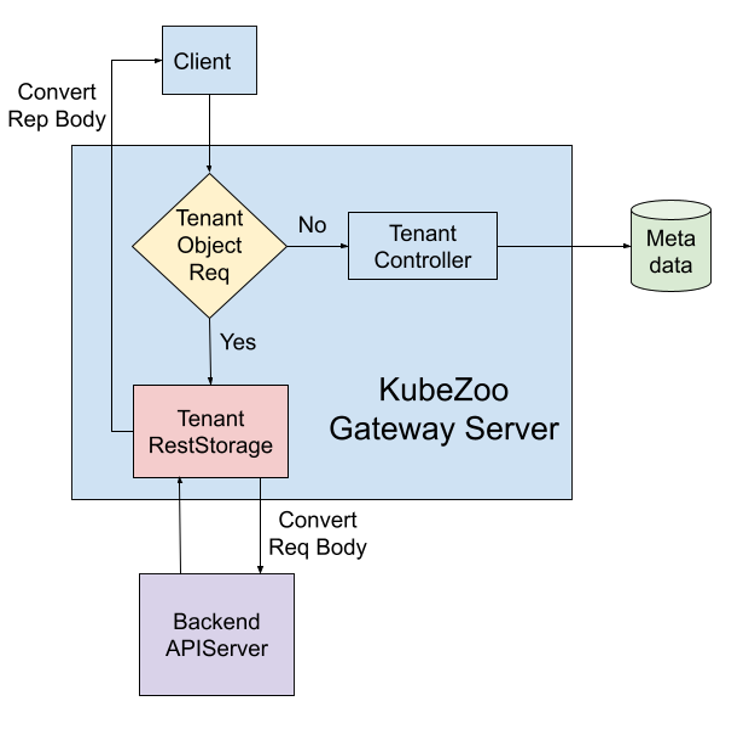
KubeZoo is deployed as a gateway service on the front end of the API Server. It catches all API requests from tenants, injects information about the tenant, forwards the request to the API Server, and also processes the response from the API Server and returns the response to the tenant.
The core functionality of KubeZoo is to perform protocol translation of tenant requests so that each tenant sees an exclusive Kubernetes cluster. For back-end clusters, multiple tenants actually share the resources of the same cluster using the native isolation mechanism of Namespace.
As you can see from the architecture diagram above, KubeZoo has some unique features as a multi-tenant solution.
First, KubeZoo provides sufficient tenant isolation.
- Each tenant’s requests are pre-processed by KubeZoo. Requests from different tenants are mapped to different Namespace or Cluster scope objects in the backend cluster, so that tenants do not interfere with each other.
- At the same time, it provides a more complete Kubernetes API, allowing tenants to use both Namespace-level resources and cluster-level resources. Each tenant’s experience can be thought of as having exclusive access to the full Kubernetes cluster itself.
Second, KubeZoo is efficient: each time you add a new tenant, you don’t need to initialize a new cluster control plane for that tenant, you just need to create a Tenant object at the KubeZoo gateway level. This results in tenant clusters that are created in seconds and used instantly.
Finally, KubeZoo is a very lightweight multi-tenant solution. Because all tenants share the same back-end cluster control plane, it has very high resource utilization and, of course, very low operational costs.
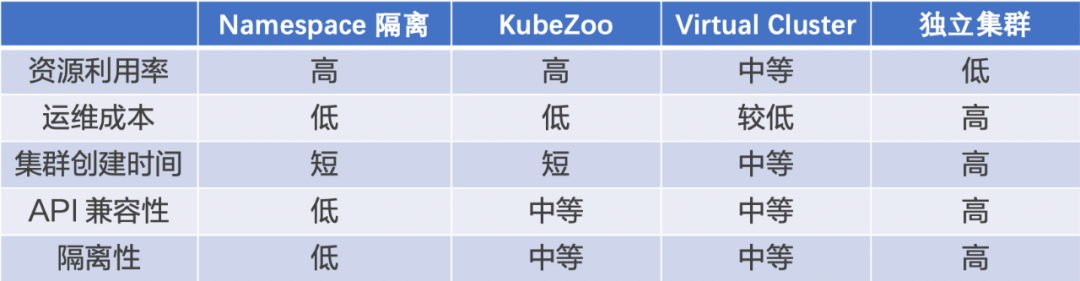
The table above shows how KubeZoo compares to some existing solutions.
Resource Utilization: Namespace Isolation and KubeZoo are both shared back-end clusters, and both have the highest resource utilization; Virtual Cluster requires a separate control plane for each tenant, so resource utilization is medium; the standalone cluster solution has the lowest resource utilization.
Operation and Maintenance Cost: Namespace Isolation and KubeZoo solutions only need to maintain a back-end cluster, so the lowest O&M cost; Virtual Cluster solution maintains the tenant control plane through the controller, so the O&M cost is low; Independent Cluster solution has the highest O&M cost.
Cluster creation time: Namespace Isolation and KubeZoo both require only one API call for tenant cluster creation, so the cluster creation time is the shortest; Virtual Cluster requires starting the tenant control plane component, so the cluster creation time is medium; Independent Cluster solution has the longest cluster creation time.
API Compatibility: In the Namespace isolation scheme, tenants cannot create and use cluster-level resources arbitrarily, and the API compatibility is the lowest; in the KubeZoo and Virtual Cluster schemes, tenants can use any Namespace-level or cluster-level resources except for node-related resources such as Node, Daemonset, etc. In the KubeZoo and Virtual Cluster solutions, tenants can use any Namespace-level or cluster-level resources except for Node, Daemonset, etc. API compatibility is medium.
Isolation: The Namespace solution has the lowest tenant isolation; the KubeZoo and Virtual Cluster solutions have medium isolation as tenant requests go through gateways or standalone Apiserver; the standalone cluster solution has the highest isolation.
In a comprehensive comparison of the above dimensions, KubeZoo achieves a balance between tenant experience, cluster resource efficiency and operation and maintenance efficiency, especially in the case of a large number of small tenants sharing a pool of resources, with significant advantages.
KubeZoo Key Technical Details
Let’s take a look at some of the key technical details of KubeZoo’s implementation.
Tenant Management
KubeZoo itself can be understood as a special kind of API Server that also needs its own metadata storage service, for example, we typically use Etcd to store tenant-related information. Tenant objects are managed in the same way that Kubernetes manages native resource objects.
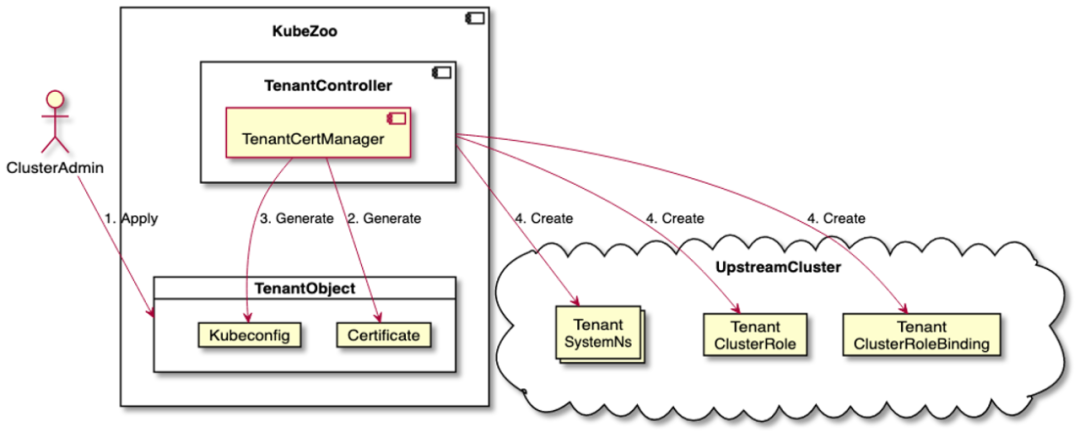
When the administrator creates a tenant object, the TenantController issues a certificate for the tenant that carries the tenant’s ID and generates the corresponding Kubeconfig for the tenant, which is written in the annotation field of the Tenant object.
Next, the TenantController initializes some resources for the tenant in the back-end cluster, including the tenant’s Namespace, Role and Rolebinding objects that manage the tenant’s privileges.
Tenant Request Conversion
KubeZoo itself handles two types of requests: one from the administrator and one from the tenant. So when a request arrives, KubeZoo first determines if the request is for a Tenant-related object.
-
If it deals with Tenant objects, it is directly handed over to the TenantController for processing and will eventually be stored in KubeZoo’s metadata server, i.e. Etcd.
-
Otherwise, it is a tenant-related request.
- At this time, the identity of the tenant will be verified by the certificate, then the Tenant ID will be extracted from the certificate, and finally the tenant request will be converted through the Tenant RestStorage interface and sent to the back-end API Server.
- The response returned by the back-end API Server is also returned to the tenant after processing.
API Object Transformation
Kubernetes resources can be divided into two categories: Namespace level and Cluster level. There are differences in how these two types of resource objects are converted:
-
Namespace-level objects: The namespace of the resource object needs to be converted to ensure that the resources of different tenants are mapped to different namespaces in the backend cluster, which cleverly leverages Kubernetes’ native namespace isolation mechanism to achieve API view isolation for different tenants.
-
Cluster level objects: The names of the objects of resources need to be converted to ensure that there are no naming conflicts between the Cluster level objects of different tenants in the backend cluster.
In addition to native objects, KubeZoo also supports user-defined CRD resources, which run under a tenant-defined API group and are transformed by the KubeZoo protocol so that multiple tenant-defined resource objects can co-exist in the backend cluster without conflict. KubeZoo also provides a comprehensive filtering mechanism to make tenant-defined resource objects visible only to the tenant itself.
Tenant Request Fairness
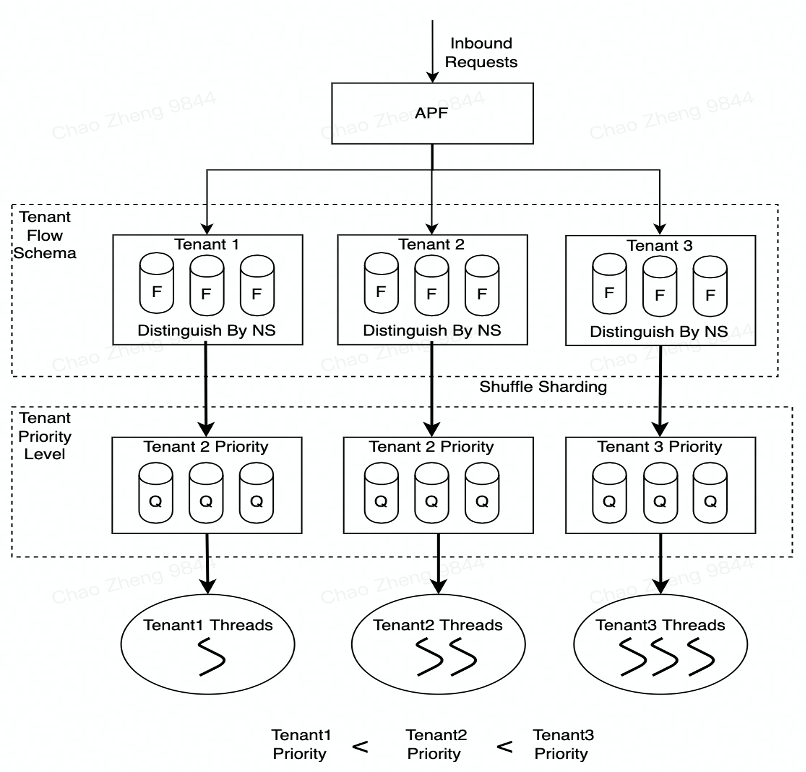
Since all tenant requests pass through KubeZoo’s unified gateway, it is important to avoid a large number of requests from one tenant filling up the gateway or cluster resources and affecting the requests from other tenants. In this case we use the API Server’s priority and fairness mechanism, specifically creating a Flow Schema for each tenant (to match the tenant’s traffic) and a Priority Level for each Flow Schema object (to represent the weight of the tenant). Finally, the flow policy is configured to ensure the fairness of requests between different tenants.
Tenant Network Isolation (VPC)
Two scenarios can be subdivided in terms of network isolation.
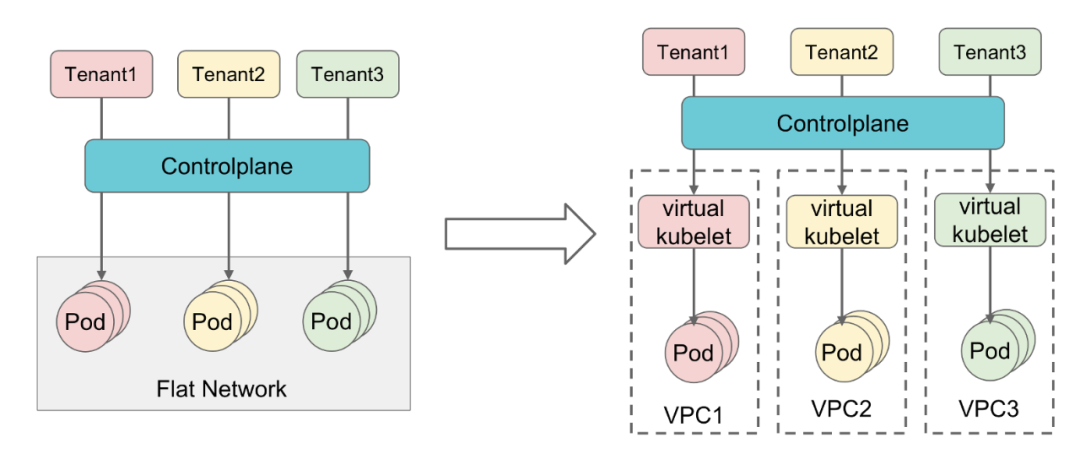
The first scenario is where all the tenants are from internal to the same company . In this scenario trust is higher, and security and auditing are better. In this case, the back-end cluster can usually use a flat network, i.e., the network between Pods of different tenants is interoperable.
The other scenario is a public cloud or a scenario with strong requirements for tenant network isolation, where we can assign the corresponding VPC and subnet when creating the tenant object. When the resource pool is shared via Virtual Kubelet, the Pod is synchronized to the back-end cluster, and the network configuration of this VPC and subnet is also synchronized during this synchronization. This way, each tenant runs inside a separate VPC, ensuring interoperability between the networks within the tenant, while the networks between the tenants are isolated from each other.
The KubeZoo solution has several typical scenarios of applicability.
- The first one is with extreme requirements for resource utilization and tenant experience of the cluster.
- The second is a huge number of small tenants sharing a large resource pool, where each tenant requires a small amount of resources, but the overall number of tenants is relatively large, and KubeZoo can make it possible to achieve a very efficient shared resource pool.
Q & A
Q: Are there some other restrictions besides DS?
A: Essentially KubeZoo is a Serverless Kubernetes solution similar to Virtual Cluster, KubeZoo is not limited to Pod, Deployment, Statefulset and other tenant level objects. KubeZoo is unrestricted for objects at the tenant level such as Pod, Deployment, and Statefulset, but restricted for objects at the cluster shared resource level such as Daemonset and Node. Simply put, if multiple tenants share a cluster, we don’t want any of them to do anything to the nodes in the cluster, so it can’t use Daemonset and it can’t manipulate the Nodes in the cluster.
Q: RBAC support for tenants?
A: Yes. As mentioned earlier, we initialize three resources for the tenant, including the tenant’s own Role and RoleBinding objects, and then KubeZoo simulates the tenant’s identity through the impersonate mechanism. So the RBAC experience is the same as the native cluster experience.
Q: Can CRDs created by different tenants be shared?
A: Regarding CRDs, here are some details. We have designed our solution to divide CRDs into two categories.
One is the tenant-level CRD, which each tenant can create and is completely isolated from each other.
The other is a system-level CRD provided in a public cloud scenario, which is handled by the same Controller on the back-end cluster. The system-level CRD can be configured as a special policy to ensure that it is open to one or some tenants who can create objects for the system-level CRD.
Q: What about the performance impact of deploying Pods from different tenants to the same Node?
A: Generally speaking, in a public cloud scenario, Pods may be deployed through some higher isolation (such as lightweight virtual machines like Kata). There will definitely be some corresponding measures on isolation and performance optimization of single nodes to ensure that the resource occupation of each tenant will not exceed its maximum application and the performance will not affect each other.
Q: Is there any difference in the CTL command?
A: No. KubeZoo supports the full Kubernetes API view, so each tenant uses Kubectl in exactly the same way as a single cluster, there is no difference. The only difference is that KubeZoo issues separate certificates for tenants, sends Kubeconfig, and users just need to specify the correct Kubeconfig.
Q: What are the advantages and disadvantages of KubeZoo compared to Kubernetes’ own multi-tenant solution, HNC?
A: The HNC solution implements a hierarchical Namespace structure that is still evolving and has not yet become a standard Kubernetes API, and the advantage of KubeZoo is that it is on par with the existing standard Kubernetes API. In other words, if the standard Kubernetes API also supports HNC, then every tenant of KubeZoo will be able to use HNC, which is a superset of the HNC capabilities.
Q: Can you give me a few examples of practical application scenarios for KubeZoo?
A: For example, within ByteDance, there are some relatively small businesses that require a small amount of resources when they are accessed, but if a cluster is maintained independently for these businesses, the cost of operation and maintenance resources is relatively high. In this internal scenario, there is actually a certain amount of business access. In the public cloud scenario, not all tenants may be big customers, and there may be some small users who do not have a large amount of demand. But somewhat similar to Kubernetes’ Sandbox, they need to experience the API or they do prototype validation, and this scenario is also very applicable.