In a nutshell: In skyzh/uring-positioned-io, I wrapped the underlying io_uring interface provided by Tokio and implemented io_uring based asynchronous random file reading in Rust. You can use it like this.
|
|
This article introduces the basic use of io_uring, then describes the implementation of an asynchronous read file library I wrote, and finally does a benchmark to compare performance with mmap.
Click here to visit the GitHub project.
io_uring Introduction
io_uring is an asynchronous I/O interface provided by the Linux kernel. It was introduced in Linux 5.1 in May 2019 and is now used in various projects. For example.
- RocksDB’s MultiRead is currently doing concurrent reads of files via
io_uring. - Tokio wraps a layer of API for
io_uring. With the release of Tokio 1.0, the developers have indicated that true asynchronous file operations will be provided via io_uring in the future (see Announcing Tokio 1.0). Currently Tokio’s asynchronous file operations are implemented by opening a separate I/O thread to call the synchronous API. - QEMU 5.0 already uses
io_uring(see ChangeLog).
Most of the current tests on io_uring compare the performance of Direct I/O with Linux AIO. io_uring can typically achieve twice the performance of AIO.
Random file reading scenarios
In database systems, we often need multiple threads to read the contents of a file at any location (<fid>, <offset>, <size>). The often used read / write API cannot do this (because it has to seek first and needs an exclusive file handle). The following method allows for random reads of files.
- Map the file directly into memory via
mmap. Reading a file becomes a direct memory read, and can be done concurrently in multiple threads. preadcan readcountbytes starting from a certain locationoffset, also supporting concurrent reads in multiple threads.
However, both of these options block the current thread. For example, if a page fault occurs after mmap reads a block of memory, the current thread will block; pread itself is a blocking API. Asynchronous APIs (e.g. Linux AIO / io_uring) can reduce context switching and thus improve throughput in some scenarios.
Basic usage of io_uring
The io_uring related syscall can be found at here. The liburing provides an easier-to-use API. Tokio’s io_uring crate builds on this by providing a io_uring API for the Rust language. language’s io_uring API. Here is an example of how to use io_uring.
To use io_uring, you need to create a ring, and here we use the concurrent API provided by tokio-rs/io-uring, which supports multiple threads using the same ring.
Each ring corresponds to a commit queue and a completion queue, where the queue is set to hold up to 256 elements.
The process of I/O operations via io_uring is divided into three steps: adding tasks to the commit queue, submitting tasks to the kernel, and retrieving tasks from the completion queue. Here is an example of the process of reading a file.
You can construct a read file task with opcode::Read, and add the task to the queue with ring.submit().push(entry).
Once the task has been added, commit it to the kernel.
|
|
Final polling for completed tasks.
In this way, we implement random reads of files based on io_uring.
io_uring currently has three execution modes: default mode, poll mode and kernel poll mode. If you use kernel poll mode, you do not necessarily need to call the function that commits the task.
Implementing an asynchronous read file interface with io_uring
Our goal is to implement an interface like this, wrapping io_uring and exposing only a simple read function to the developer.
|
|
After referring to tokio-linux-aio for asynchronous wrapping of Linux AIO, I used the following method to implement io_uring based asynchronous reads.
- The developer needs to create a
UringContextbefore usingio_uring. - While the
UringContextis created, one (or more)UringPollFutureis run in the background to submit and poll for completed tasks. (corresponds to the second and third operations of the read file in the previous section). - A developer can call the interface for reading a file from
ctx, creating aUringReadFuturewithctx.read. After callingctx.read.await.UringReadFuturecreates an objectUringTaskthat is fixed in memory, and then puts the read file task into a queue, using the address ofUringTaskas the user data for the read operation. There is a channel insideUringTask.UringPollFuturesubmits the task in the background.UringPollFuturepolls for completed tasks in the background.UringPollFuturefetches the user data, reduces it to aUringTaskobject, and notifiesUringReadFuturethrough the channel that the I/O operation has completed.
The whole process is shown in the following figure.
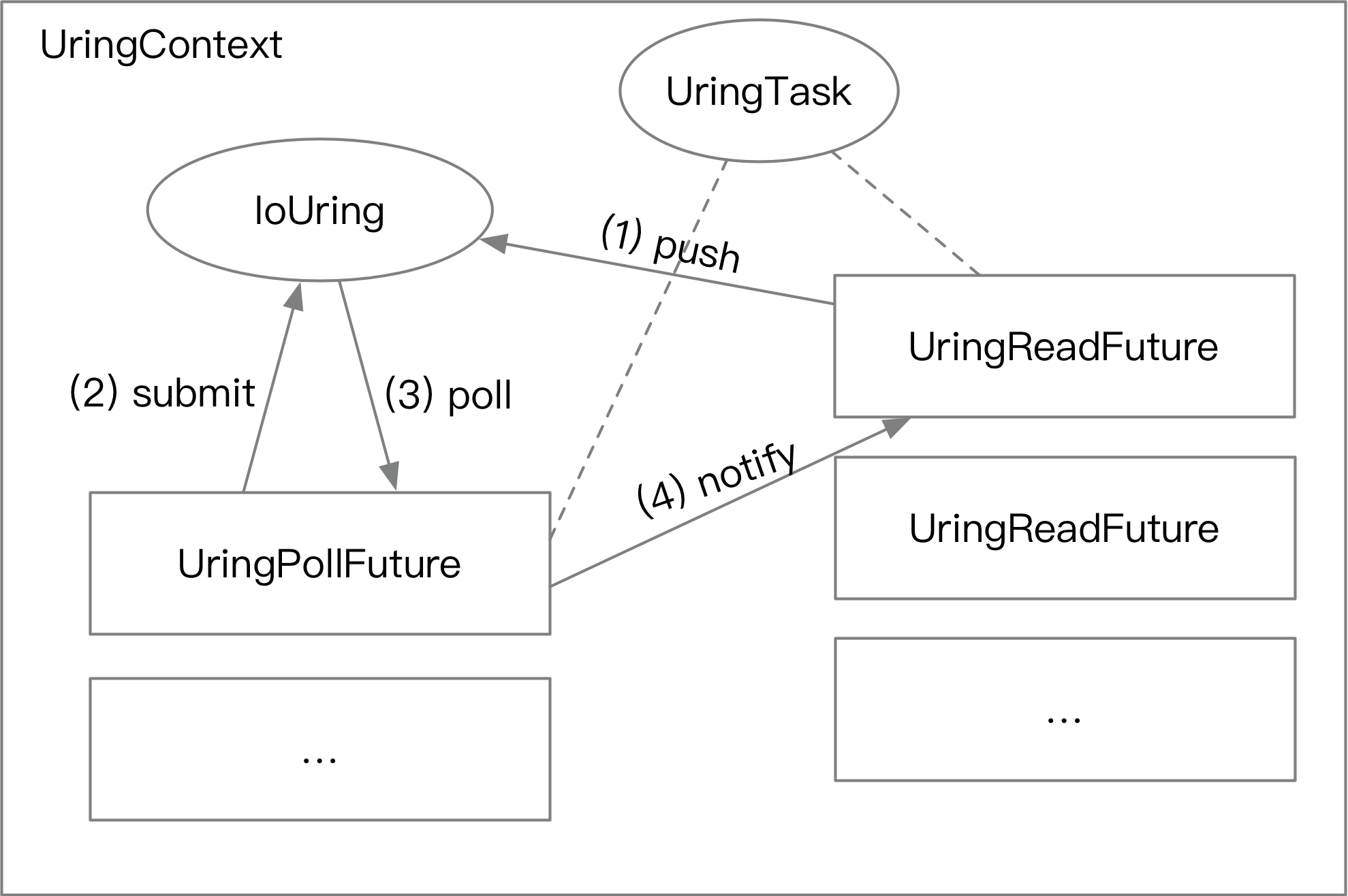
This makes it easy to call io_uring to read the file asynchronously. This also has a side benefit: task commits can be automatically batching. Normally, an I/O operation would generate a syscall, but since we use a single Future to commit and poll tasks, there may be multiple uncommitted tasks in the queue at commit time, and they can all be committed at once. This reduces the overhead of syscall context cutting (and of course increases latency). From the benchmark results, we can see that each commit can pack about 20 read tasks.
Benchmark
Compare the performance of wrapped io_uring with that of mmap. The test load is 128 1G files with random read aligned 4K blocks. My computer has 32G of RAM and a 1T NVMe SSD. 6 cases were tested as follows.
- 8-thread mmap. (mmap_8)
- 32 thread mmap. (mmap_32)
- 512-thread mmap. (mmap_512)
- 8 threads 8 concurrent
io_uring. (uring_8) - 8 threads 32 concurrent
io_uring. That is, 8 worker threads, 32 future simultaneous reads.(uring_32) - 8 threads of 512 concurrent
io_uring. (uring_512)
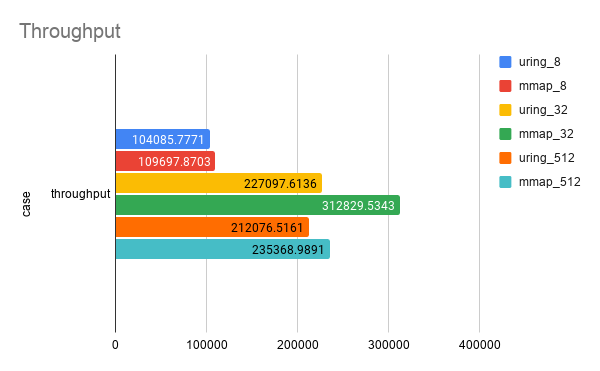
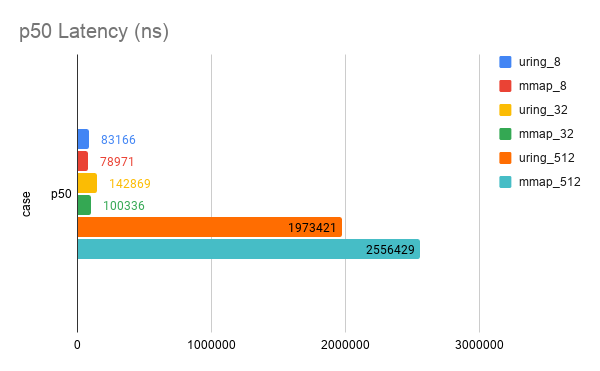
Tested Throughput (op/s) and Latency (ns).
| case | throughput | p50 | p90 | p999 | p9999 | max |
|---|---|---|---|---|---|---|
| uring_8 | 104085.77710777053 | 83166 | 109183 | 246416 | 3105883 | 14973666 |
| uring_32 | 227097.61356918357 | 142869 | 212730 | 1111491 | 3321889 | 14336132 |
| uring_512 | 212076.5160505447 | 1973421 | 3521119 | 19478348 | 25551700 | 35433481 |
| mmap_8 | 109697.87025744558 | 78971 | 107021 | 204211 | 1787823 | 18522047 |
| mmap_32 | 312829.53428971884 | 100336 | 178914 | 419955 | 4408214 | 55129932 |
| mmap_512 | 235368.9890904751 | 2556429 | 3265266 | 15946744 | 50029659 | 156095218 |
Found that mmap is far superior to io_uring. Well, it’s true that this wrapper is not very good, but it’s barely usable. Here is a heatmap with one minute latency, each set of data is presented in the order of mmap first and then io_uring.
mmap_8 / uring_8


mmap_32 / uring_32


mmap_512 / uring_512


Some possible improvements
- It looks like right now
io_uringis not performing very well after my wrapping with Tokio. You can later test the overhead introduced by this wrapping of Tokio by comparing the performance of Rust / C on theio_uringnop instruction. - Test the performance of Direct I/O. Only Buffered I/O has been tested so far.
- Compare to Linux AIO, performance is not worse than Linux AIO.
- Use perf to see where the bottlenecks are now. Currently
cargo flamegraphis hooked up andio_uringcan’t request memory. - Currently, the user must ensure that
&mut bufis valid throughout the read cycle. If Future is aborted, there will be a memory leak. A similar problem with futures-rs can be found at https://github.com/rust-lang/futures-rs/issues/1278 . Tokio’s current I/O solves this problem by copying twice (first to the cache, then to the user). - Maybe wrap write files and other operations along the way as well.