Today we share Apache EventMesh event-driven distributed application runtime, which is a relatively new concept, and we hope we can bring some inspiration to you through this sharing.
We all understand two concepts - message and event. Message refers to the update of a specific event, and this update is sent from one point to another after the message is deleted, and the message is a temporary state of existence; while event refers to what happens at a specific time, it is not bound to a specific recipient or client, and it is often can be replayed, backtracked and reworked.
According to a report by Gartner, the value of data will diminish over time. In many real-time scenarios, it would bring great value if events could be analyzed and data mined in real time, like the very hot streaming computing Flink, Spark, and ClickHouse, etc. They are all very concerned about the real-time nature of data, and EventMesh can deliver data in a timely manner.
EventMesh
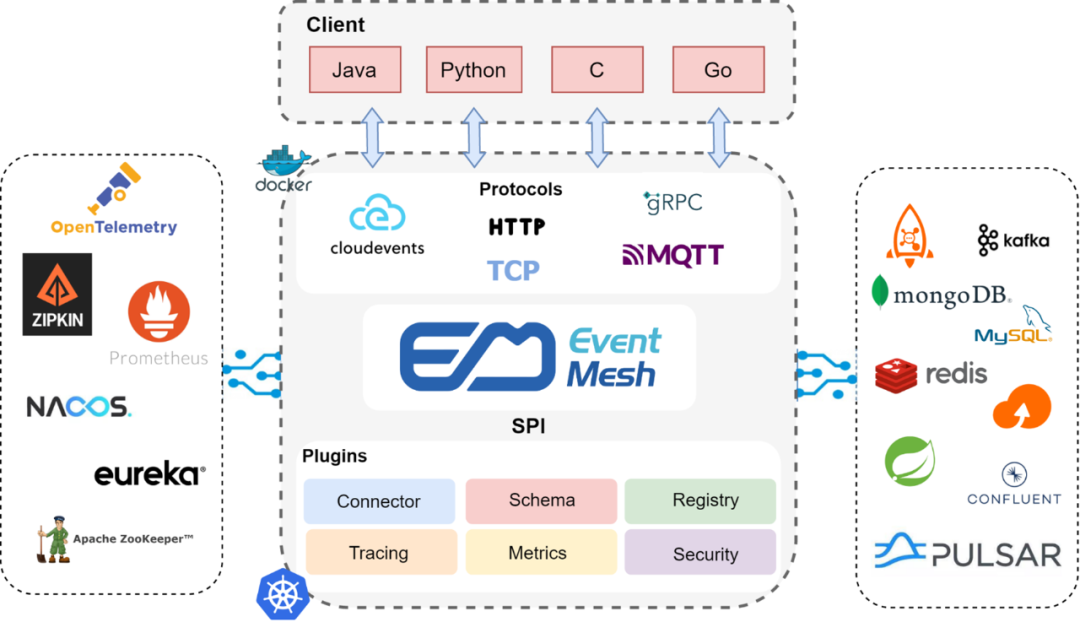
Let’s start with the EventMesh architecture diagram, EventMesh is positioned as an event-driven distributed application runtime. EventMesh can provide a very lightweight, multi-language client and a wide variety of protocols such as MQTT, Cloudevents, Web Socket and MQP, along with gRPC, TCP and HTTP transport protocols.
EventMesh Runtime is a plug-in architecture that can be connected to back-end middleware or services, such as event storage RocketMQ, Kafaka and Apache Pulsar, etc. If there is a need for some state update maintenance, it can be connected to back-end Redis, MySQL and Mongo DB, etc. If there is a need for some cold data update, it can also be connected to S3, ES and other storage through a plug-in form.
At the control level, EventMesh Runtime can also interface to ETCD, NACOS, Prometheus, Zipkin, Skywalking, OpenTelemetry, etc. if there is a need for event call chain tracking, metadata management, and distributed orchestration. The most common plugins we use internally are RocketMQ and Redis, but EventMesh can also be easily integrated with Kubernetes because EventMesh Runtime can be deployed as Sidecar or as a Gateway.
Let’s take a look at the current REST Drive and Event Drive in the microservices space, their respective advantages and disadvantages are very obvious. In the case of Spring Cloud, HTTP2, and gRPC communication, when REST calls a service, it is very easy to develop due to the industry’s very well-documented tools and development tool clients, but all calls to REST Drive are synchronous, and synchronous means blocking. If there is a slow call or failure of a service at any node in a chain, it affects the front-end service calls and costs more when Spring Cloud establishes communication with Dubbo services.
However, in the event-driven domain, when accessing the gateway or performing business-level framework layer adaptation, it is invoked asynchronously, all states are ultimately consistent, and can be decoupled from many services and middle layers. In addition, like the Queue subscription publishing method, it is very easy to scale. But it needs to rely on a layer of middleware, the complexity of the middleware needs to be handled manually, but this layer of complexity can be shielded using EventMesh, so for the application development itself, lightweight and convenient.
SeviceMesh vs EventMesh
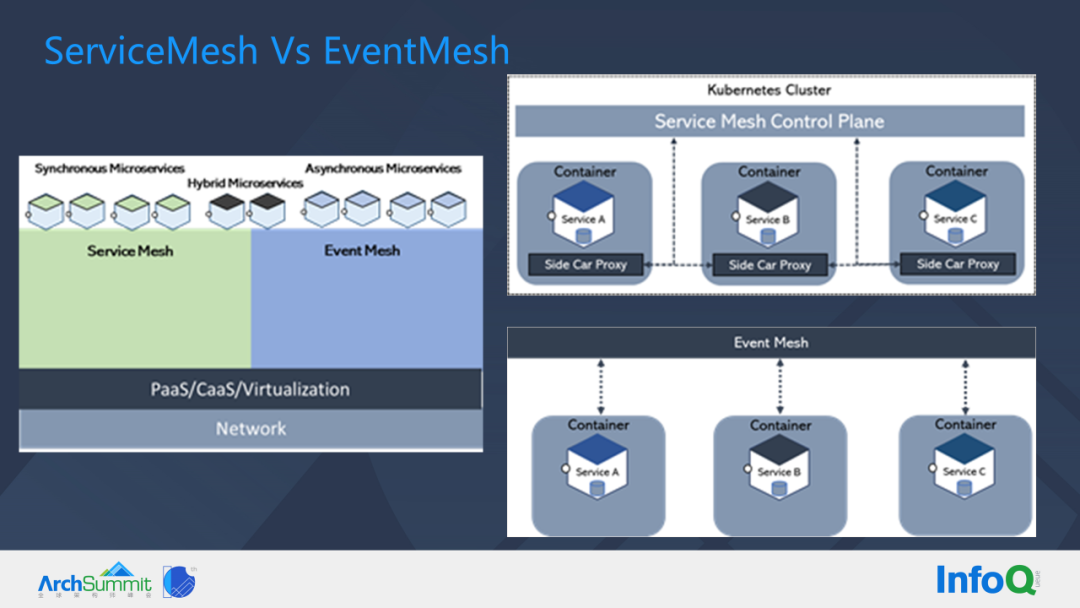
Next we share the difference between SeviceMesh vs EventMesh.
SeviceMesh requires Sidecar and all data level communication is forwarded between Sidecar, but in EventMesh, we see that single or multiple services can hang on a single node of EventMesh, EventMesh has strong microservice orchestration capabilities, but EventMesh does not solve all the problems. The advantage of EventMesh is that it is event-driven, and it can also do Request, Reply.
There are synchronous and asynchronous services, and SeviceMesh can be used for synchronous calls, while EventMesh can be used for asynchronous calls. Of course, EventMesh can also do synchronous calls, and SeviceMes can also do asynchronous calls, but the positioning of the two themselves and the scenarios they handle are different, so SeviceMesh and EventMesh can be used in combination.
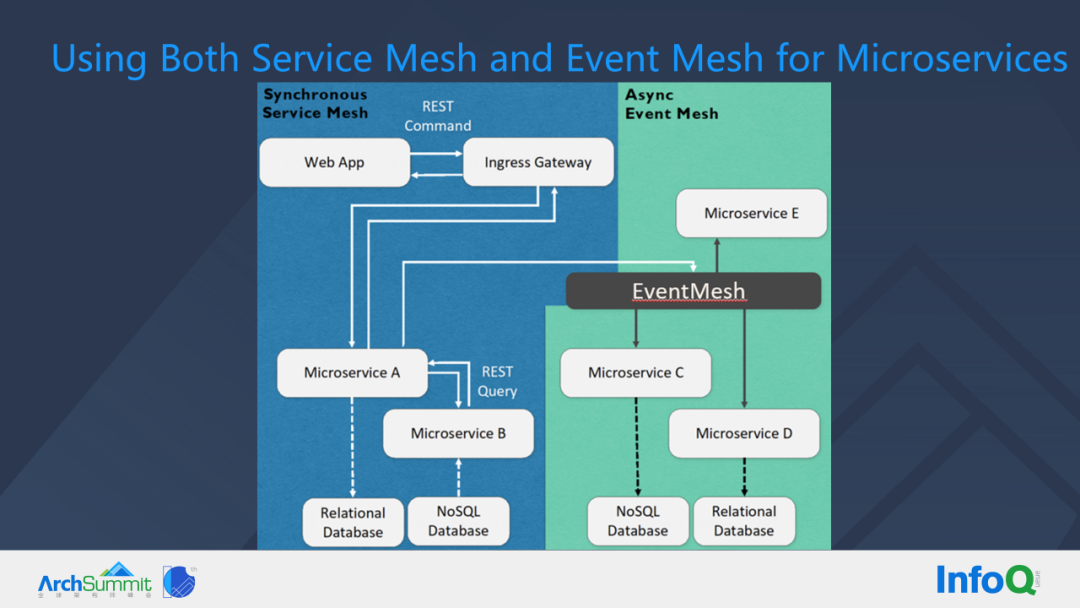
For example, the front-end Web App forwards the calls that come in through the API gateway to the front-end or to a service in a business domain, and it makes calls between internal services, and this process generates data that goes to a relational database or a NoSQL database. But this action of entering the database may need to be subscribed or noticed by other services. At this time, we can forward the events or services to EventMesh, and let EventMesh drive the services that care about these events for follow-up work.
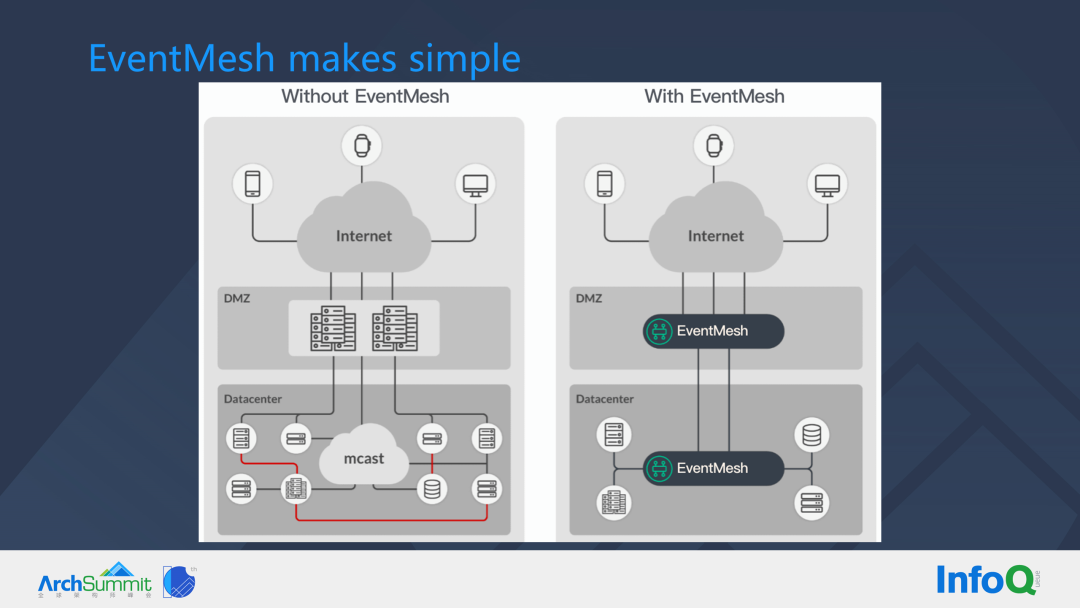
Next, let’s take a look at what EventMesh does.
In a DMZ or ECN zone, the purpose of deploying a gateway or front-end service is to perform protocol translation - from an external service with an HTTP or HTTPS interface protocol to an internal protocol with a different service framework (e.g. Dubbo, Spring Cloud). When external, public or partner traffic enters this area, the internal area will form a very complex mesh and the border zone traffic governance is very inconvenient.
The common practice now is to place gateways at the boundary, but with EventMesh, we only need two EventMesh (either clusters or nodes) in the outbound and internal areas, so that services in the boundary area only need to communicate between the EventMesh, and when the request comes to the internal services, through the internal area EventMesh can form many meshes, and each EventMesh mesh proxies the services registered to it. By connecting the different EventMesh and the services it proxies to form a larger event grid, the governance of many complex invocation scenarios becomes extremely simple.
EventMesh Feature
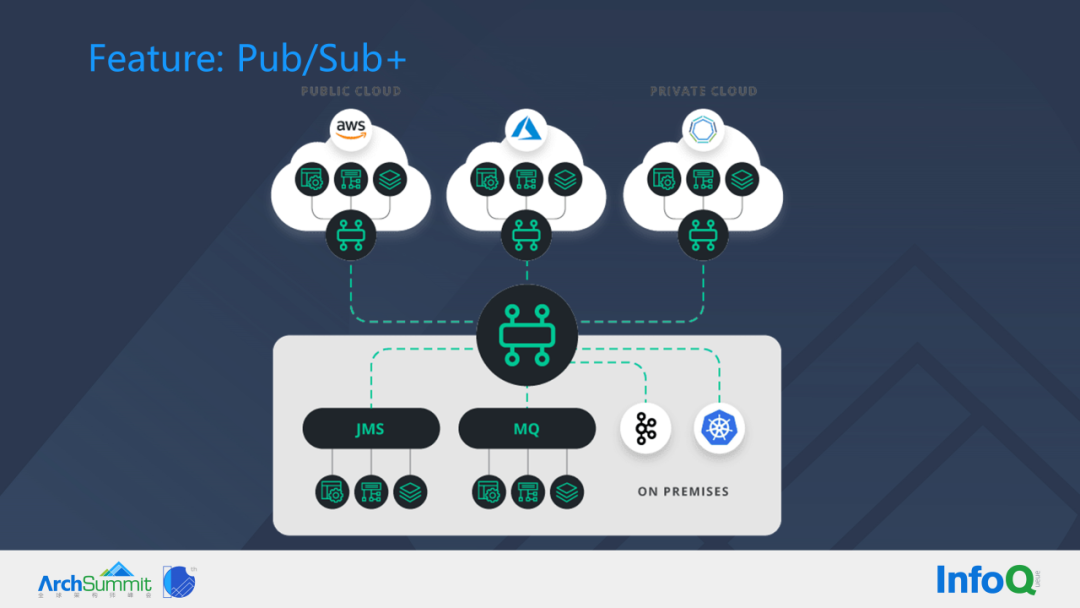
In this section I will introduce a few important EventMesh Features.
Pub/Sub+
Nowadays there are very many services in various cloud and private deployment environments, and the connection between services can be done through EventMesh. Services in different regions use different protocols and languages, but any protocols, nodes, and services added in the form of Pub/Sub+ can be unified and aggregated into the grid formed by EventMesh.
As an example, when everyone publishes an event on Amazon Cloud and a service node in a private deployment of Kubernetes subscribes to the message, the message can be routed across many nodes to the Kubernetes service. Also, when services in multiple regions subscribe to the same topic, just send the message to the corresponding topic and the corresponding service will automatically take the message down. eventMesh can address the diversity of connection protocols, languages, and can address connectivity issues in boundary zones.
Event Bus
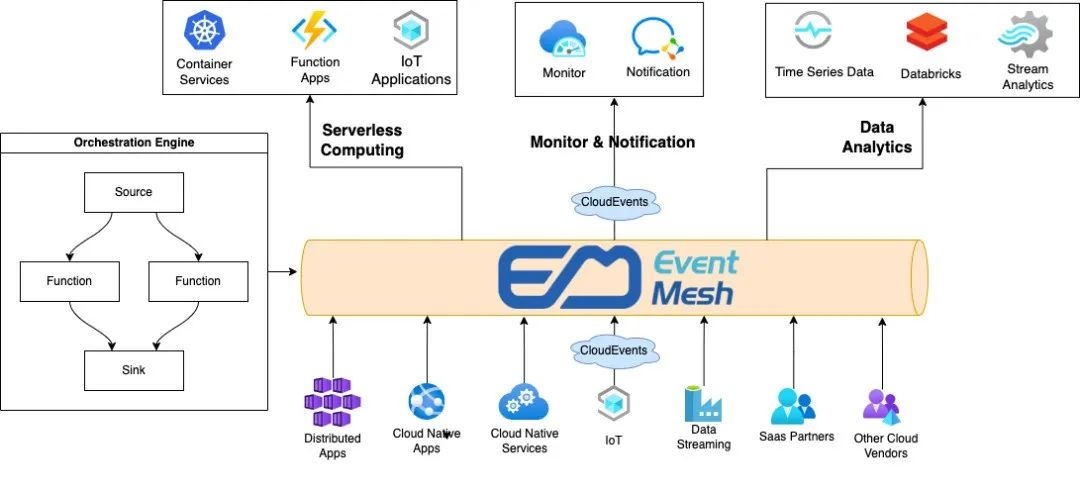
Event-driven architecture (EDA) is an asynchronous architecture design model that decouples different systems using events as a link. In EDA, the event-driven operational flow naturally delineates the business semantics of each system, and the user can flexibly customize the event and the response to that event according to the requirements, which makes it easy to build highly scalable applications based on EDA architecture.
HTTP Source event source is one of the event sources supported by EventMesh, which exposes the HTTP request address for publishing events in the form of a Webhook, allowing users to configure HTTP Source event source in scenarios with URL callbacks or to publish events directly using the simplest HTTP client. HTTP Source provides Webhook URLs that support different request methods and network environments such as HTTP and HTTPS, public cloud VPC, etc., making it easy for users to integrate them into various applications. No client is required to access the Webhook URL, just ensure that the application can access it, making the access process simple and efficient.
When converting HTTP requests to CloudEvent, EventMesh places the header and message body parts of the request in the CloudEvents field, and the rest of the fields are populated based on user EventMesh resource properties and system default rules. The user can filter and extract the required content from the event rules, and finally assemble the required message content to be delivered to the event target according to the template.
Streaming
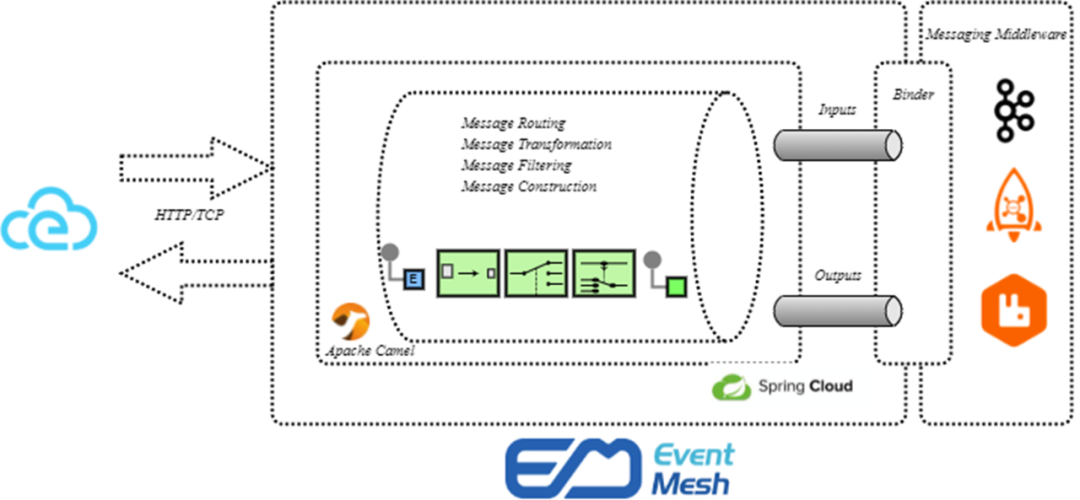
In current microservices, when we do traffic scheduling, we definitely need to decode the message headers and route to the corresponding service in order to add policies based on the specific fields in the message headers.
In fact, in event-driven, we do not need to decode messages in the first place, we can solve similar problems in its message topic design. For example, it is possible to design a very large number of Topic levels, with progressive relationships between levels, to achieve dynamic filtering. Second, when the message arrives, it can be easily parsed for the message, and on top of the generated events, we can add a lot of Match processing functions, and the generated messages can be processed by the filter chain in real time. The processing of events can be done by EventMesh.
Orchestration and coordination
In the left area of the diagram above, when writing complex Cases, If else conditions or introducing workflows, it has a lot of serial branches in the orchestration, but with EventMesh orchestration, it will look very clean.
We only need to subscribe to the event of interest and send the corresponding event to the other party’s topic, we do not need to pay attention to the location of the other party’s IP, nor do we need to pay attention to whether the service is deployed on a virtual machine or a container, and the number of instances of the other party’s service, and of course, we do not need to pay attention to whether we need to fuse the other party’s instance after it hangs, etc. The downstream EventMesh can do everything, for example, when its downstream service fails, the message will be automatically distributed to the current online service instance. From the above diagram, you can see that the use of EventMesh makes the orchestration and coordination process much clearer.
Dynamic expansion and contraction
Next is the scaling scenario. There are two common scenarios when existing Kubernetes is being scaled.
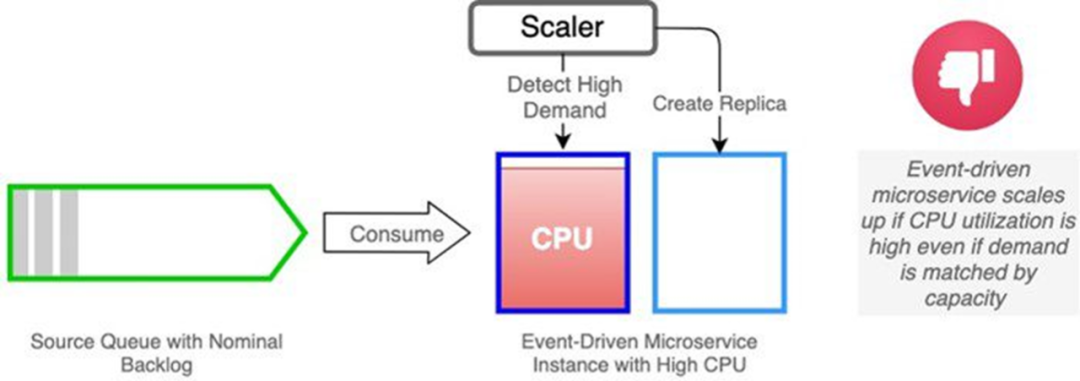
The first is the expansion scenario, for example, when the current CPU occupancy is high, the normal situation will trigger the expansion event, but we do not see a particularly large number of messages stacked in the message queue, that is, this time does not need to expand the capacity, in fact, this expansion is wasted; second is the scaling scenario, for example, in the message queue, there is currently no message stacking, theoretically the instance can be scaled down, even to zero, but because of the CPU usage can not be smoothly scaled down.
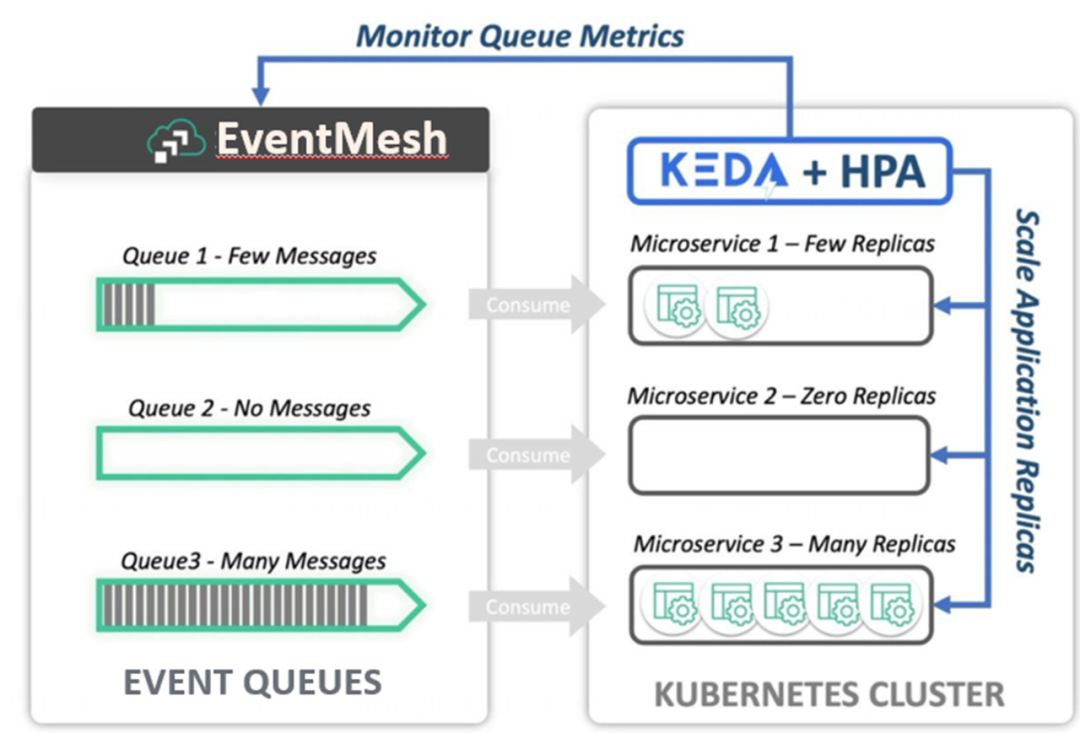
However, for both scenarios, if we use Queue queue stacking monitoring with event-driven services, we can achieve the following effects. Firstly, if the resource usage is high but the queue tasks are not stacked, no scaling can be done; secondly, if the current CPU resources are occupied but no tasks are processed, scaling can be done. In my opinion, the metrics for scaling monitoring should be judged based on the current stack of processed tasks.
Bridge(Federated Governance)
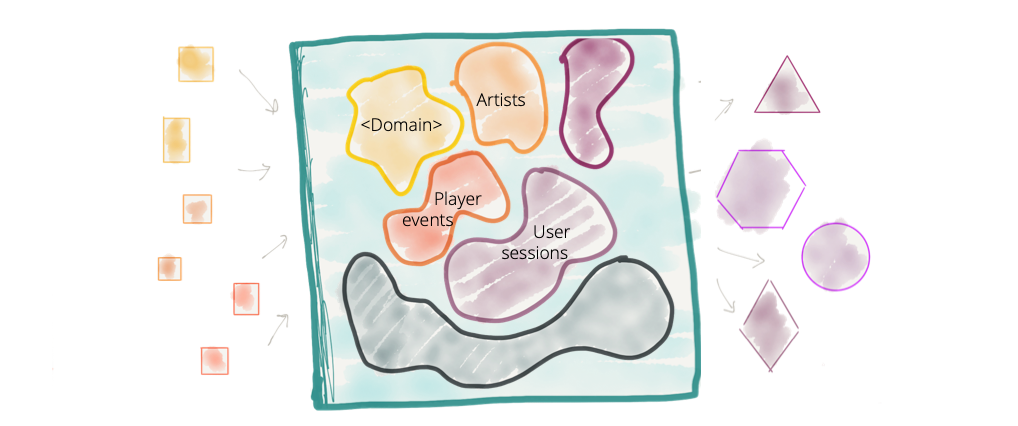
Before governance, it was like the figure below, where silos of data were formed between different regions.
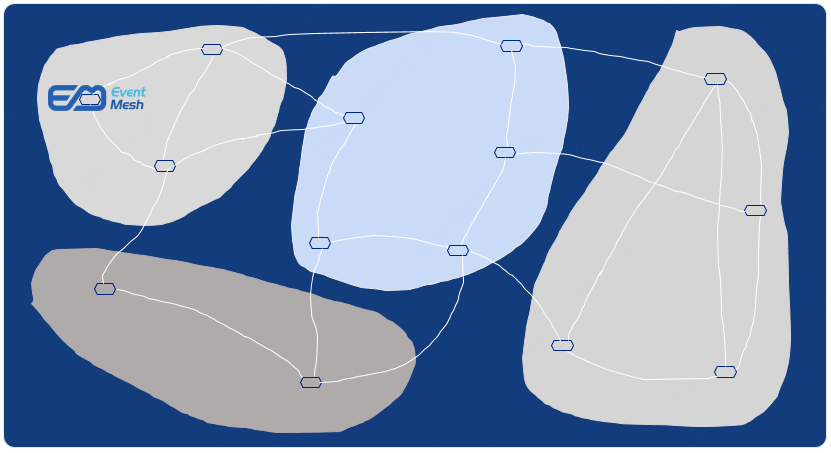
But when governed, it becomes a grid state like the one below, clear and concise.
For most of the last decade, enterprises have struggled with data silos, isolated persistent stores with countless but inaccessible knowledge, whose primary weapon is the data lake: a giant centralized data store that holds terabytes of domain-specific data in one logical location. Data experts without domain knowledge have difficulty trying to extract data value from disparate datasets, and there is little incentive for data producers who contribute high-quality data to the data lake.
With EventMesh’s capabilities for real-time analytics, large-scale data collection, platform-agnostic connectivity, and support for open standards, ideally any changes to customer data should be pushed to dependent consumers in real-time via something like an EventMesh, but if the data is less important or untimely, data consumers can pull (or query) the data when needed.
We are transitioning from data anarchy to federated governance and mature enterprise data policies - ideally, policies that can be effectively represented as the end state of the code. Federated governance requires standards such as task-specific tools, event catalogs, and AsyncAPI. Enterprise data policies also include features/functions such as access control, regulations (i.e. GDPR), confidentiality (e.g. PII and PHI), redaction, and encryption. Examples of features may include mandatory header metadata (to contextualize data), observability requirements, topic structure (for routing), and data quality achieved through schema validation and other tools.
EventMesh in WeBank Message Bus(DeFiBus)
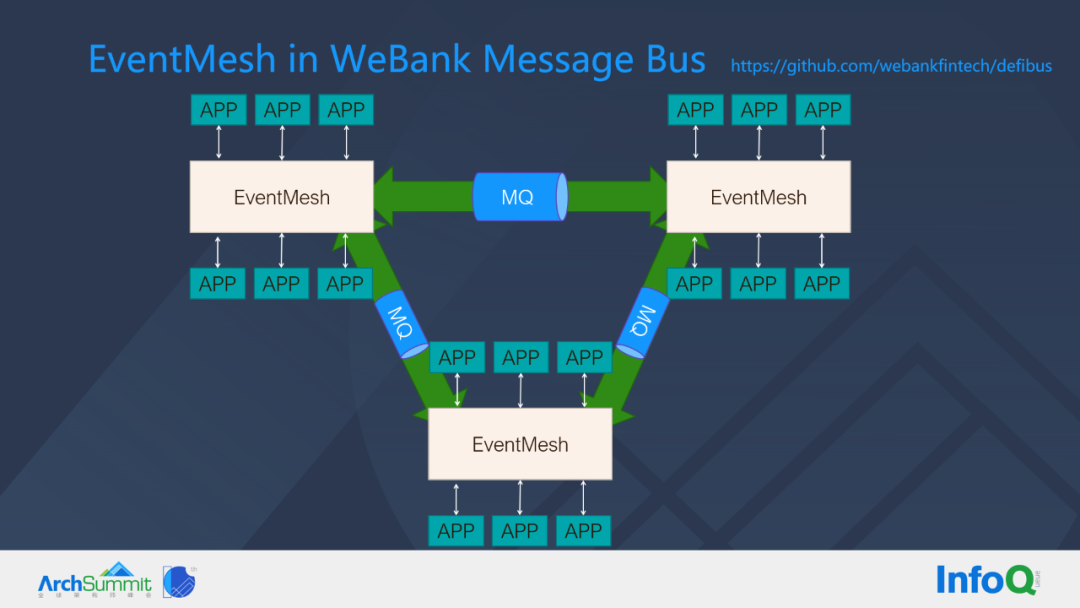
In WeBank, DeFiBus, a messaging bus that has been open sourced, is shown in the figure above. Here is an example of three nodes of EventMesh, each EventMesh node, can subscribe to services on it. When the sender publishes an event, any service on the other EventMesh that subscribes to Topic can send this event to the corresponding service, which can automatically learn and update the routing table.
EventMesh solves the following problems within WeBank, first of all, it is a multi-language governance problem, for example, AI computing uses Python, many banks’ systems use C language, EventMesh can simplify the complexity of accessing the message bus, and we know that it is very troublesome to upgrade the SDK that drives the business, when the SDK is light and simplified, we only need to be responsible for When the SDK is light and simplified, we only need to be responsible for the release of the middleware layer, which saves the cost of application-driven upgrades. In addition to the application in the business system, EventMesh is also used in traffic replication playback platform, message bypass filtering, message multi-live routing, AI federal learning, blockchain and other scenarios, more scenarios are in the process of continuous exploration and practice, and we will share them with you in the future.
Summary
Today’s IT systems are generating, collecting and processing more data than ever before. And, they are handling highly complex processes (which are being automated) and integration between systems and devices that span typical organizational boundaries. At the same time, IT systems are expected to be faster and less expensive to develop, while also being highly available, scalable and resilient. To achieve these goals, developers are adopting architectural styles and programming paradigms such as microservices, event-driven architecture, DevOps, etc. New tools and frameworks are being built to help developers meet these expectations. Developers are combining event-driven architecture (EDA) and microservices architectural styles to build systems that are highly scalable, available, fault-tolerant, concurrent, and easy to develop and maintain.
EventMesh, the event infrastructure, is responsible for the transport, routing and serialization of events. The event infrastructure provides support for multiple serialization formats and has a significant impact on architectural quality (e.g., fault tolerance, elastic scalability, throughput, etc.), as well as storing events to create event stores, which are a key architectural pattern for recovery and resiliency.
That concludes this sharing, thank you for reading.
Reference https://mp.weixin.qq.com/s/9mpn8jhVoV5NQ2I6Aoae3Q