Fluid is a cloud-native distributed data set orchestration and acceleration engine, mainly serving data-intensive applications in cloud-native scenarios, such as big data applications, AI applications, and so on. In this paper, we will introduce the main working principle of Fluid from two aspects: data orchestration and data acceleration.
Architecture
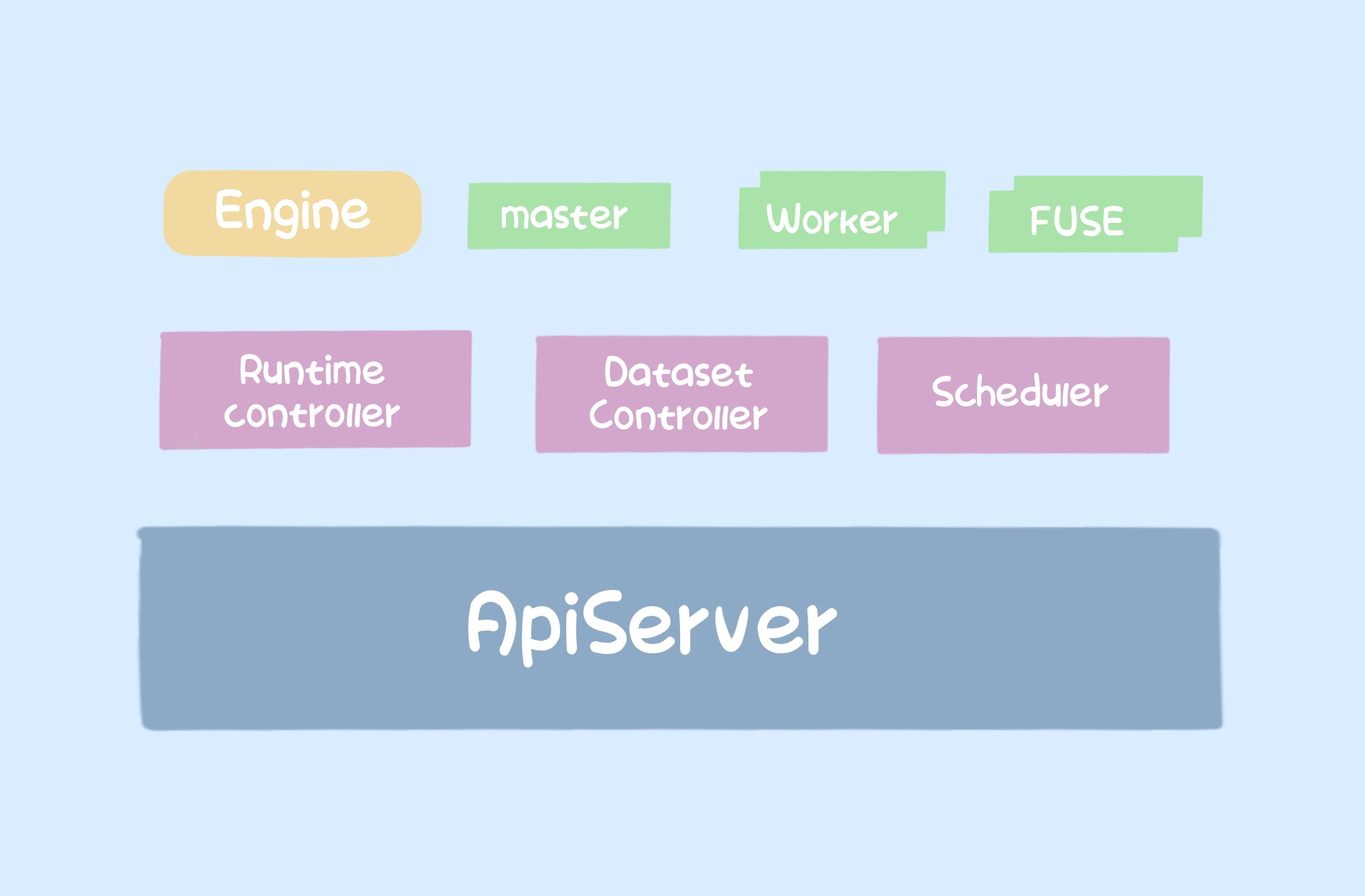
The whole architecture of Fluid is divided into two main parts.
One is the Controller, including RuntimeController and DatasetController, which manage the lifecycle of Runtime and Dataset respectively, and both of them work together to build a complete distributed caching system based on helm chart, usually in the form of master + worker + fuse to provide services upwards.
masteris the core component of the caching system, usually a pod.workeris the component that makes up the caching cluster, which can be multiple pods and can be set in number.fuseis the component that provides the POSIX interface services.
The second is the scheduler, which makes the upper application pods dispatch to the nodes with cache as much as possible based on the node information of the worker when cache is available.
Data Orchestration
Fluid has two main concepts: Runtime and Dataset.
Runtime refers to a system that provides distributed caching. The types of Runtime currently supported by Fluid are JuiceFS, Alluxio, and JindoFS, of which Alluxio and JindoFS are typical distributed caching engines; JuiceFS is a distributed file system with distributed caching capability. In this article, we will take JuiceFS as an example and introduce the core features of Fluid.
Dataset refers to a dataset, which is a collection of logically related sets of data that will be used by computing engines, such as Spark for big data and TensorFlow for AI scenarios. Corresponding to JuiceFS, Dataset can also be understood as a Volume of JuiceFS.
The following is an example of JuiceFS to build a set of Fluid environment, after building the components as follows.
|
|
Role of each component.
dataset-controller: manages the lifecycle of Datasetjuicefsruntime-controller: manages the JuiceFSRuntime lifecycle and quickly builds the JuiceFS environment.fluid-webhook: implements cache scheduling for Fluid applications.csi-nodeplugin: implements the connection work between the mount path of each engine and the application.
Then create the Runtime and Dataset. You can refer to the official documentation for details: https://github.com/fluid-cloudnative/fluid/blob/master/docs/zh/samples/juicefs_runtime.md.
Once the JuiceFSRuntime and Dataset are created, the Runtime Controller will create the JuiceFS environment based on the parameters it provides. The special feature of JuiceFS compared to other Runtime is that it does not have a master component (because of the specificity of its distributed cache implementation). So here we only see the worker component started, which constitutes a standalone cache cluster (currently only supported by the Cloud Service version).
The Runtime Controller starts the JuiceFS environment by launching a helm chart whose rendered values.yaml is stored in the cluster as a ConfigMap. View the chart as follows.
It is important to note here that starting with v0.7.0, Fluid has adopted a lazy start of the FUSE client, starting the FUSE pod only when there is an application working, to avoid unnecessary waste of resources.
Start an application that uses Fluid Dataset..
As you can see, after the application starts, the FUSE component also starts successfully.
Data Acceleration
Another important feature of Fluid is data pre-acceleration. To ensure the performance of applications when accessing data, data from remote storage systems can be pulled in advance to a distributed cache engine close to the compute node through data preloading, allowing applications consuming that dataset to enjoy the acceleration from the cache on the first run.
In Fluid, data acceleration corresponds to DataLoad, also a CRD, and the DatasetController is responsible for listening to this resource, starting a Job based on the corresponding DataSet, and performing data warm-up operations.
Still using JuiceFS DataLoad as an example.
For example, if there are two subdirectories /dir1 and /dir2 in the original filesystem, the target is specified to indicate that the data from both directories are preheated to the cache cluster.
After the warm-up starts.
The way DatesetController starts a dataload job is also to start a chart, which includes a job and configMap.
|
|
When the status of the pod named loader-job is Completed, it means that the warm-up process is complete. The status of DataLoad also becomes Complete.
And the CACHED and CACHED PERCENTAGE values of the Dataset are updated. CACHED indicates the amount of cached data, and CACHED PERCENTAGE indicates the ratio of cached data, i.e. CACHED / UFS TOTAL SIZE.
Summary
This article introduces the two core features of Fluid, data orchestration and data acceleration, using JuiceFS Runtime as an example. fluid adapts to multiple distributed cache engines to provide services to upper-level data-intensive applications in a unified data orchestration manner, allowing them to focus on their own data computation without being bound to the deployment of the underlying cache engine and many parameter details.