The design of kubernetes is broadly divided into 3 parts.
- API-driven features.
- Control loops and conditional triggers (Level Trigger).
- API extensibility.
These design features are what make kubernetes work very stably.
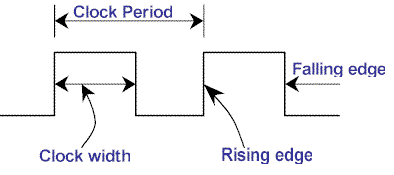
Level Trigger and Edge trigger
I saw an online source that explains the two belongings as follows.
- condition-trigger(level-trigger) LT means: Triggers an event whenever the condition is met (constant notification as long as there is data not fetched).
- edge-trigger(edge-trigger)ET: Triggers an event whenever the state changes.
By looking up some information, I don’t actually understand exactly which science these belong to in terms of theory, but the specific explanation is very clear to see.
LEVEL TRIGGERING : There are two levels of current, VH and VL. These represent the two trigger event levels. If VH is set to LED in positive clock. When the voltage is VH, the LED can be lit at any point in that timeline. This is called LEVEL TRIGGERING and triggers an event whenever the VH timeline is encountered. The event is started at any point in time until the condition is met.
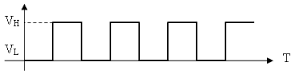
Edge TRIGGERING : As shown, you will see the rising and falling lines, when the event is triggered at the rising/falling edge (the intersection of the two states), it is called edge triggering (Edge TRIGGERING).
If the LED needs to be turned on, it will be on when the clock transitions from VL to VH, not when a family is on the corresponding clock line, but only at the transition.
Why kubernetes uses Level Trigger and not Edge trigger
As described in the figure, there are two different design patterns that respond to the shape of time. How to trigger the corresponding event when the system is shutting down or in an uncontrollable abnormal state when the system is going from high to low or from low to high.
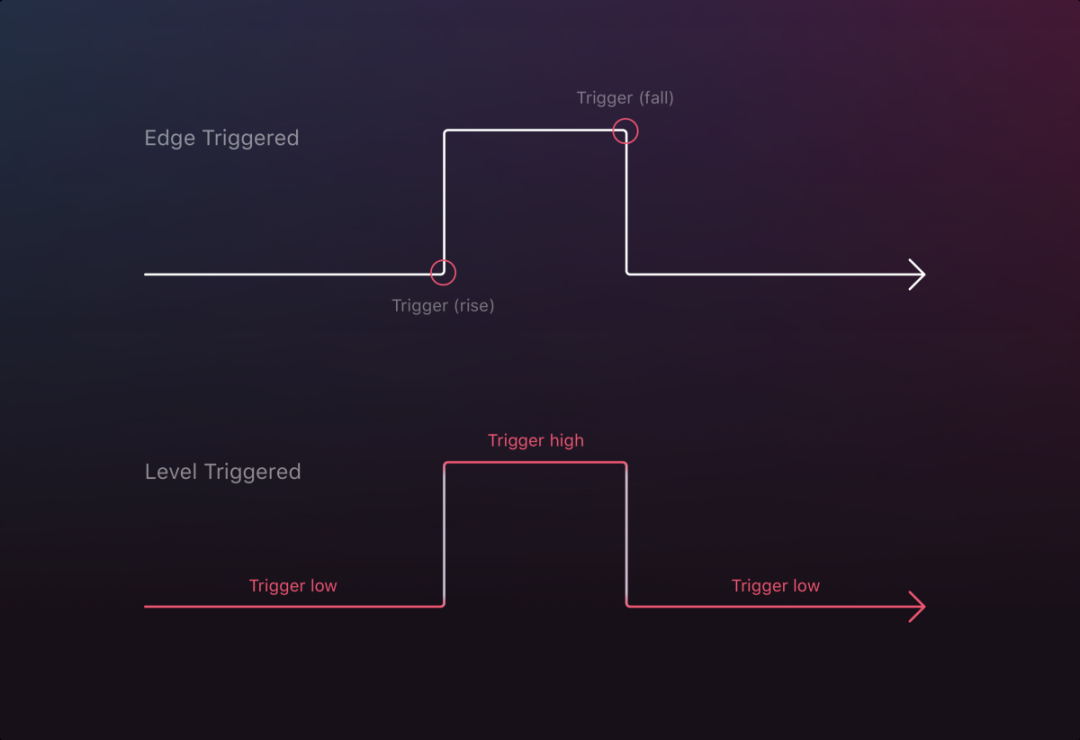
To put it another way, let’s say by addition, as follows, i=3, when giving I+4 as an operation to trigger an event.
When operating on Edge trigger, you will see i+4, while on level trigger you will see i=7. Here it will be i+4 until the next signal is triggered.
Interference of signals
Normally, there is no difference between the two, but in a large-scale distributed network environment, there are many factors that make any of them unreliable, in which case it changes our perception of the event signal.
As shown in the figure, there is no difference between the simulated signal generation of Level Trigger and Edge trigger in the ideal case.
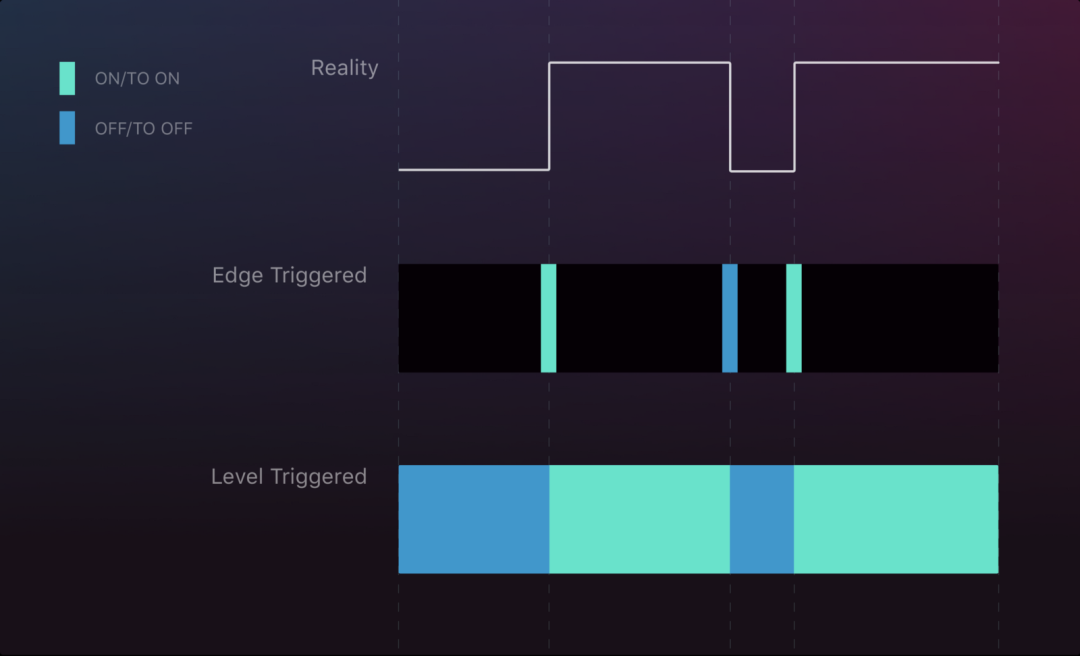
One interruption scenario
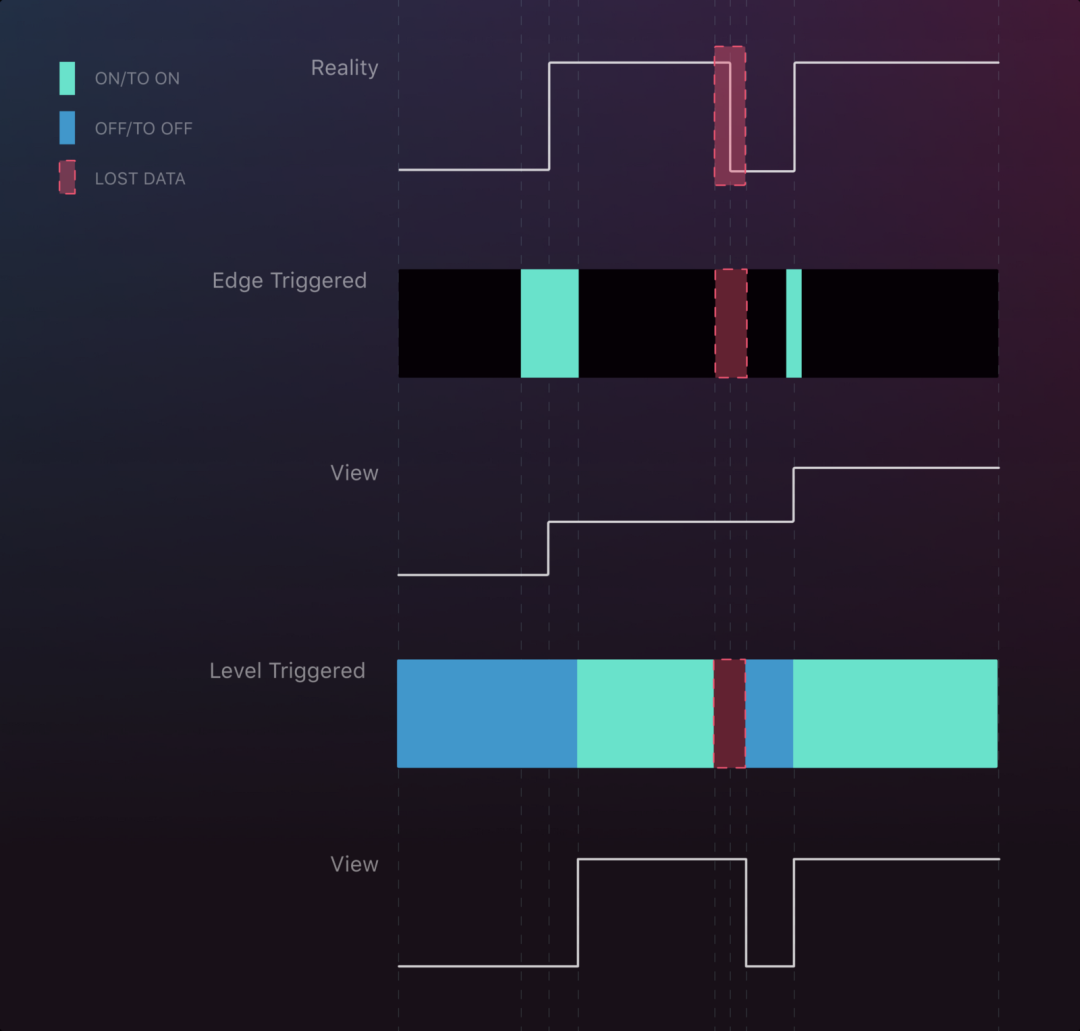
As can be seen from the figure, Edge trigger when the signal interruption occurs at the right point in time, it will have a great impact on the whole stream, even changing the whole state, for less disturbance does not have a better result on having a single interruption, so that Edge trigger misses the change from high to low, while level trigger basically guarantees all the changed states of the whole semaphore.
Two interruption scenarios
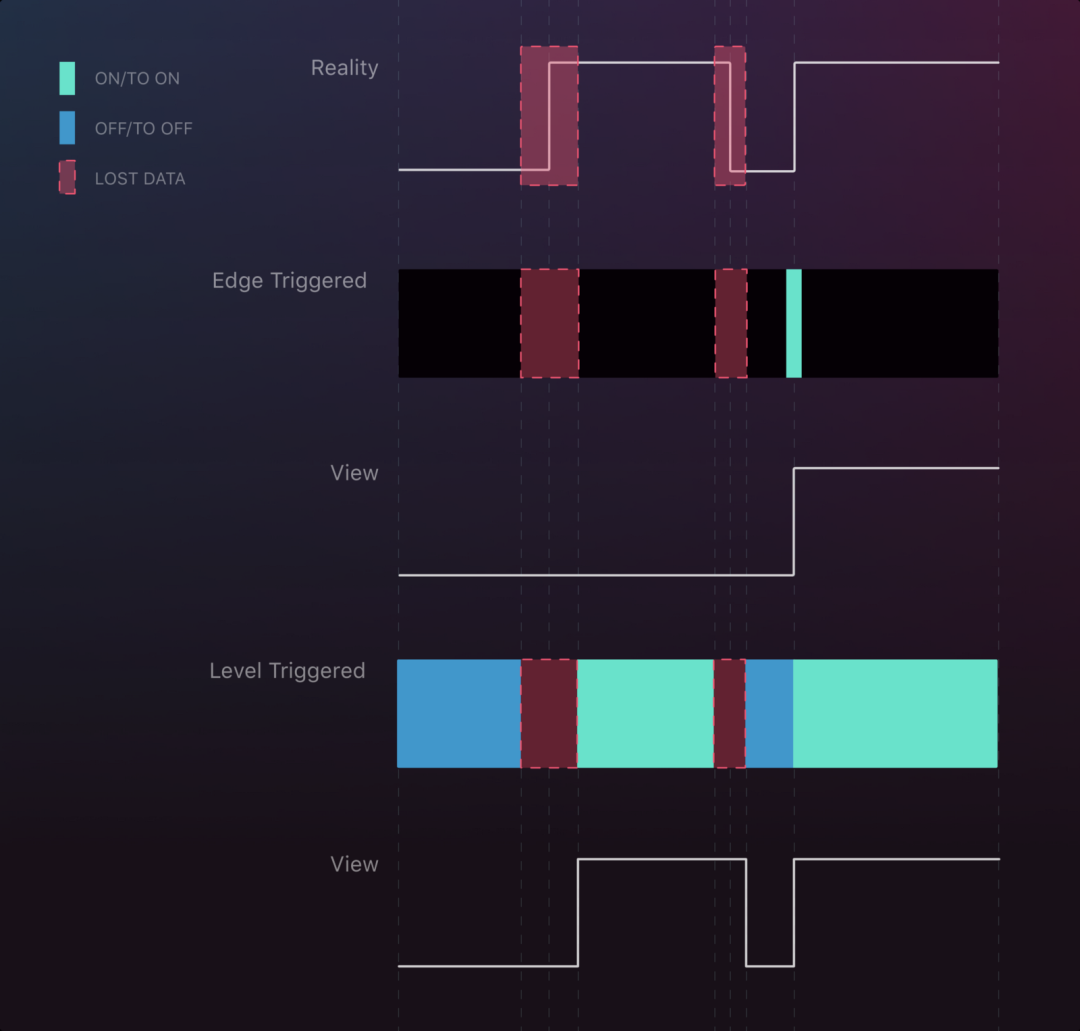
As can be seen from the figure, if there is an interruption during the rise and fall of the signal, Edge trigger loses the rising signal, but the final state is correct.
Two interruptions occur during two changes of the signal state. The difference between the Level Trigger and the Edge trigger is clear: the signal of the Edge trigger misses the first rise, while the Level Trigger keeps the last observed state until the other state is obtained. This mode ensures that the signals obtained are essentially correct, but occur with a delay until after the interrupt is restored.
Representation of the change of two modes by arithmetic
The complete signal.
Edge trigger.
How do I make the desired state the same as the actual state?
In Kubernetes, not only one signal of the object is observed, but also two other signals, the expected state of the cluster and the actual state. The expected state is the state that the user expects the cluster to be in, such as when I run 2 instances (pods). In the most ideal scenario, the actual state of the cluster is the same as the expected state, but this process can be affected by arbitrary external factors that interfere with the actual state and deviate from the ideal state.
Kubernetes must accept the actual state and reconcile it with the desired state. This is done continuously, taking the two states, determining the differences between them, and correcting their constant changes to bring the actual state to the desired state.
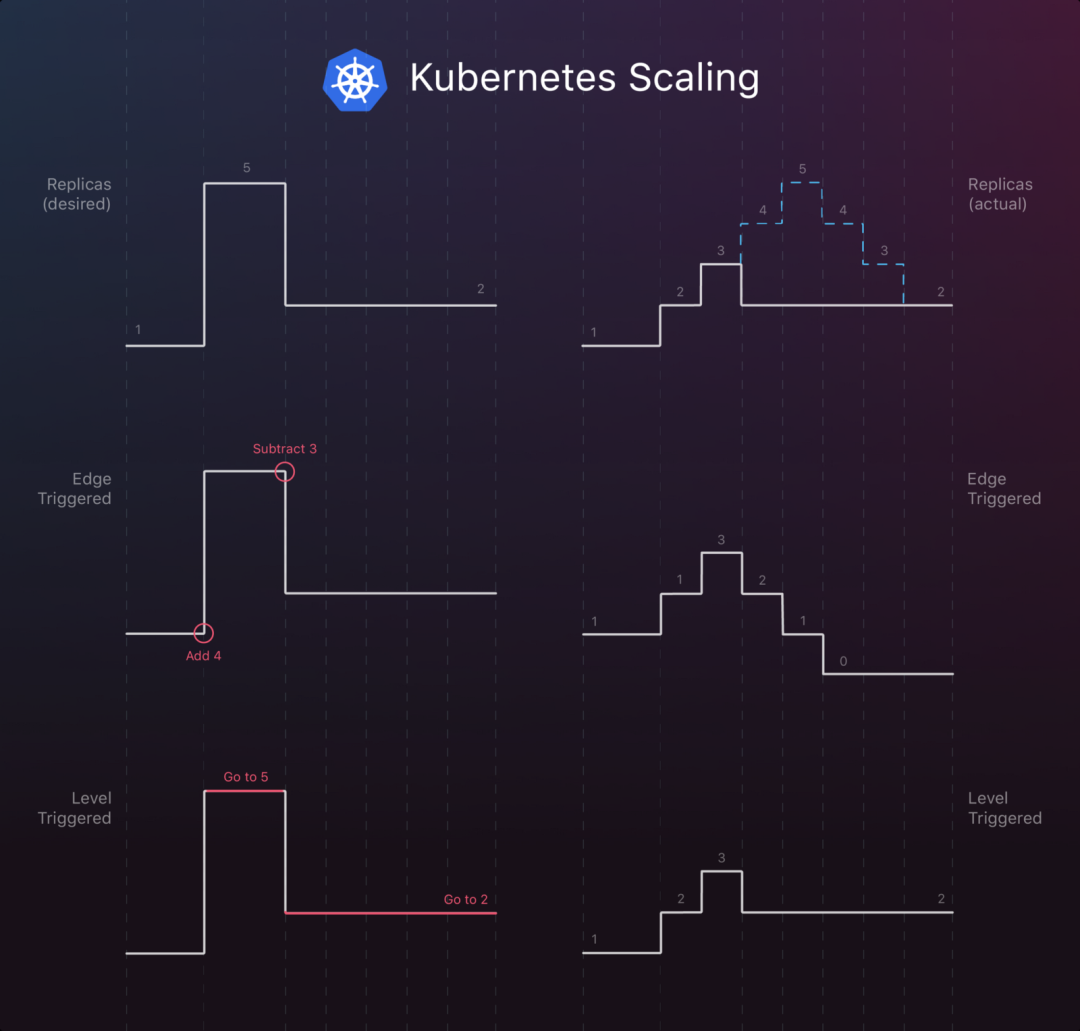
As shown in the figure, in an Edge trigger, the final result is likely to deviate from the desired result.
When the initial instance is 1 and you want to scale to 5 replicas and then down to 2 replicas, the Edge trigger environment will see the following state: The actual state of the system does not immediately respond to these commands. As described in the figure, it may terminate 3 replicas when only 3 are running. This leaves us with 0 copies instead of the required 2 copies.
Instead, when using Level Trigger, the complete desired state and the actual state are always compared until the actual state is the same as the desired state. This greatly reduces the generation of inter-state synchronization (errors).
Summary
There must be a reason for every kind of trigger, Edge trigger itself is not very bad, just different application scenarios, and the use of different models, such as nginx’s high performance is the use of Edge trigger model, such as nginx use Level trigger in the large concurrency, when a change signal waiting to return when a large number of client connections are in the listening queue, which does not happen with the Edge trigger model.
In summary, kubernetes needs to be designed in such a way that the components are aware of the final desired state of the data and do not need to worry about missing the process of data changes. In turn, the design of the kubernentes system message notification mechanism (or data real-time notification mechanism) should also satisfy the following requirements.
-
Real-time (i.e., the faster the relevant components feel when the data changes, the better). Messages must be real-time. Under the
list/watchmechanism, whenever an apiserver resource has a state change event, the event will be pushed to the client in time to ensure the real-time nature of the message. -
Message Sequence: The order of messages is also important. In concurrency scenarios, clients may receive multiple events for the same resource in a short period of time. For kubernetes, which is concerned with final consistency, it needs to know which is the most recent event and ensure that the final state of the resource is consistent with that expressed by the most recent event. kubernetes carries a
resourceVersiontag in each resource event, which is incremental. Thus, clients can compareresourceVersionwhen concurrently processing events for the same resource to ensure that the final state matches the expected state of the most recent event. -
Message reliability to ensure that messages are not lost or that there is a mechanism to reliably reacquire them (e.g., network fluctuations between
kubeletandkube-apisever(network flashover) need to ensure that the kubelet can receive messages generated during network failures after the network has recovered).
It is the use of Level trigger by Kubernetes that makes the cluster more reliable.