Distributed Systems and Consistency
Distributed systems have a very important problem to solve. When one machine has a problem, we want the whole cluster to still be able to run normally to meet the requirement of high availability. Because the data of the system is constantly changing, it is important to ensure that the data of the cluster is synchronized, or else there will be data mix-ups or loss. This is the consistency problem.
To put it differently, consistency means that multiple machines end up with the same state for a given set of operations, that is, all machines execute commands in the same order, and to the client, they have to behave as one machine.
The distributed consistency problem can be abstracted into the following diagram (Replicated State Machine).
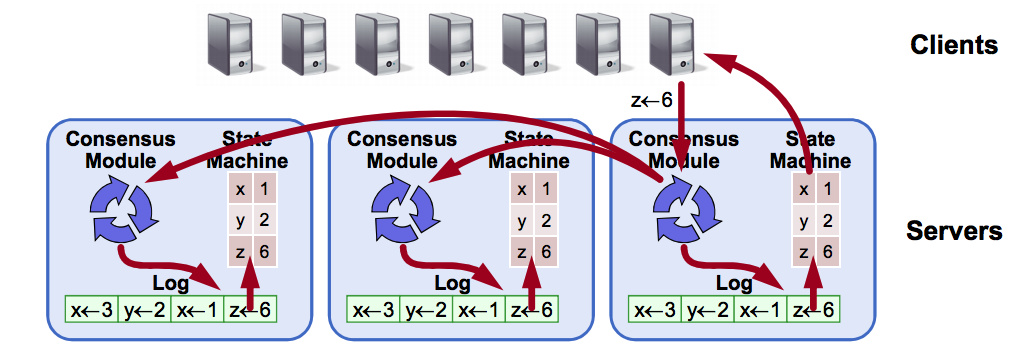
The ultimate goal is that the state machines (file contents) saved on all nodes are the same. This is done through communication between consistency modules on each node, which ensure that the logs are added in order and then the logs are executed to modify the contents of the state machines. If the initial state of the machines is the same, and the order of logging in the logs is the same, then the final state must be the same as well.
Consistency algorithms need to meet the following conditions to work in real systems.
- safety: no incorrect results are returned, even if the network has delays, partitions, packet loss, duplication and disorder
- available: the whole cluster must work as long as more than half of the machines are working (able to communicate with each other and with clients)
- Consistency cannot be guaranteed by time, and incorrect clocking and severe message delays can at best make the cluster unavailable
- As soon as most machines finish executing the command, the command is complete and the result can be returned to the client. Instead of waiting for the few nodes that execute more slowly to complete, their operations can run asynchronously in the background
The best-known algorithm for distributed systems with respect to consistency is paxos, whose publisher, Lamport, is a Turing Award winner. But the paxos algorithm is very complex, and many implementations are special versions of it. Although Lamport later published Paxos Made Simple, an attempt to explain the paxos algorithm in simpler terms, this version is still too complex, which makes it difficult to understand and implement.
The paxos algorithm has a high status in distributed systems, and the Chubby authors have this to say.
There is only one consensus protocol, and that’s Paxos. All other approaches are just broken versions of Paxos.
The raft algorithm is based on the paxos algorithm, mainly to make it more understandable. The paper proposing the raft algorithm is “In search of an Understandable Consensus Algorithm”, which can be easily searched online.
aft algorithm
To make it easy to understand, the draft algorithm is divided into several problems that can be explained separately.
- Leader election: Master node election, choosing one of all nodes in the cluster as the master node
- Log replication: Log replication, the master node is solely responsible for interacting with the client and replicating the logs to other nodes to ensure consistency of the logs
- Safety: security, if a node adds a log record to the saved state, other nodes will not add a different record at the same log index time.
The workflow is like this: the cluster selects a node as the leader, the leader node is responsible for receiving requests (logs) from clients and replicating them to all slave nodes to ensure data synchronization between nodes. If the leader node has a problem and hangs, the other normal nodes will choose the leader again.
Leader election
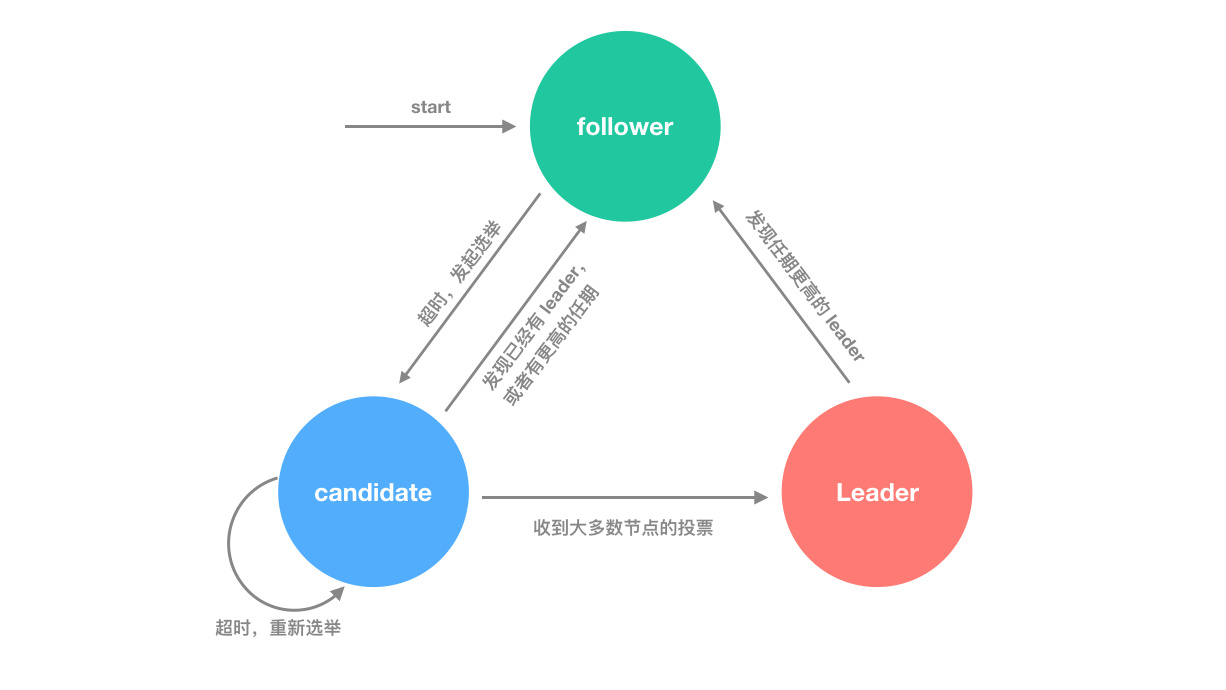
Each node can only have three states to choose from in any given case.
- leader: the leader node, or master node, used to handle requests from clients and ensure that the requested data is synchronized across the cluster, and needs to communicate with follower nodes using heartbeats to inform them of their availability
- follower: the node responsible for handling leader and candidate requests. If a client sends a request to a follower node, it needs to forward the request to the leader, who is responsible for managing it.
- candidate: candidate for leader, a state that appears only briefly during the election process. If the election is passed, it will become leader; if the election fails, it will still return to follower state
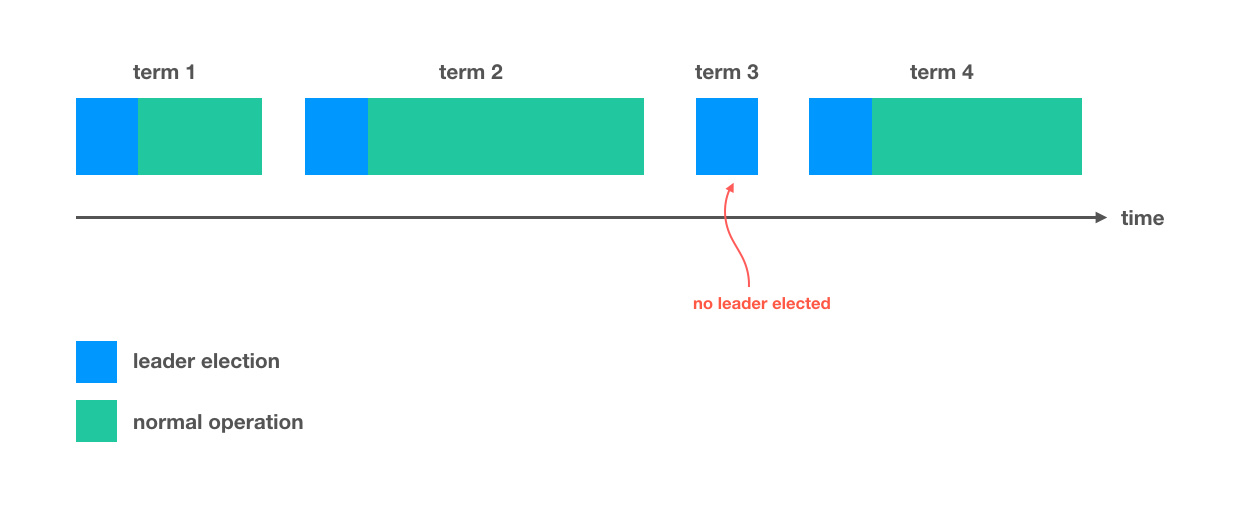
The raft algorithm also has the concept of Term, which is an increasing number of terms. Each election is a new term. There can be at most one leader in a term, which means there can be one leader in a term, indicating normal work, or no leader, indicating a failed election. When a node is successfully elected, it becomes the leader for the current term and is responsible for log replication.
The main purpose of the term is to ensure that all nodes are logically consistent in time, and there is no logical chaos caused by expired requests.
Each node keeps a current tenure value, and when nodes communicate, they interact with each other to update their current tenure value if they find that the current tenure of other nodes is larger than their own; if a leader node finds a tenure value larger than its own, it knows that its own tenure has expired and there is a newer leader node in the cluster, which immediately becomes follower state; if a node receives a request for a historical term, it simply ignores it (this is likely due to network latency or duplicate messages).
When a node is first started, it is in the follower state by default. If it regularly receives heartbeats from the leader or requests for log replication, it stays in that state; if it does not receive messages from the leader within the set timeout (election timeout), it assumes that there is no leader in the current cluster, or that the leader is as well disabled, and immediately initiates a re-vote.
When voting starts, the node increases its current term value, converts to candidate state, and sends a message to other nodes requesting a vote (indicating that it wants to be the leader for the next term). The following states are divided into three cases.
-
The node receives votes from the majority of nodes and becomes the leader for the new term.
Each node can only vote once per term, on a first-come, first-served basis, for the first elector node that receives it. The majority principle guarantees a maximum of one node per term.
-
The node finds that another node has become the leader.
While waiting for the election result, the node receives a heartbeat or log replication message (i.e., it has a leader), and if the leader is legitimate (term higher than its current term), the current node automatically becomes follower; otherwise, it continues to wait.
-
After a while, no node becomes the leader.
For example, there are multiple nodes to elect a leader, and the results are spread out, with no node receiving more than half of the votes.
If nothing is done, then the third scenario keeps occurring and would result in the whole cluster being in a constant state of election, which is of course unacceptable. For this reason, draft takes a random timeout approach.
First, the election timeout is randomized to ensure that one node will time out first and take the lead in the election, and other nodes will not have time to run against it, and it will become the new leader, sending heartbeats and log replication requests.
Second, when the election starts, each candidate node resets its timeout timer and waits for the timer to expire before starting the next election, thus disrupting the order of the next election and ensuring that one node starts the election first and becomes the leader.
It has been shown that these two approaches can ensure that the election is completed in a short time and does not keep looping.
The election timeout is generally set to 150-300ms, which is the empirical value obtained from a large number of experiments.
Log replication
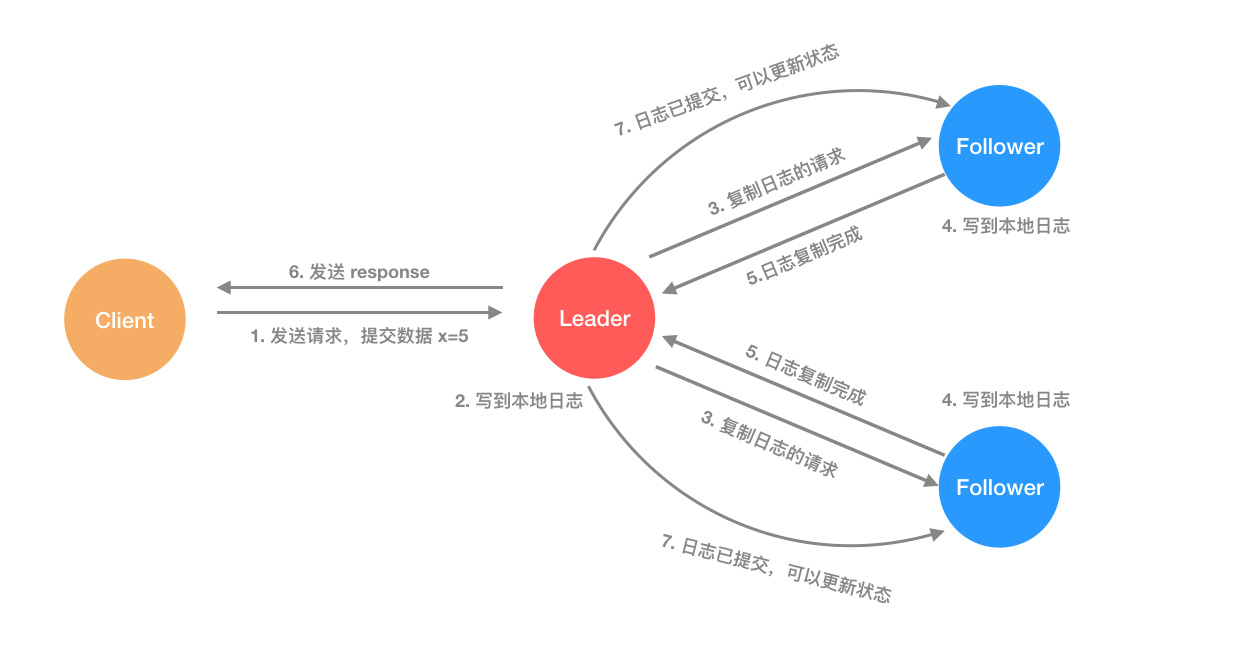
When a node becomes a leader, it is responsible for receiving requests from clients. Each request from a client is a command that the replicate state machine executes to modify its state.
After the master node receives the request, it writes it to its own log as a new record, and then sends a request to all slave nodes for log replication, and when the log replication is complete, the leader node returns the result to the client. If a slave node fails or is slow, the master node keeps retrying until all nodes have saved all log records (to a uniform state).
Each log record stores a state machine command, as well as the term value of the master node when it accepts the request, and an index indicating its location in the log file.
When a log record is executed by the state machine, it is said to be committed (commited). When the master node knows that the log record has been replicated to most nodes, it commits the current record to the local state machine (because the log has been updated to most nodes and all data is safe), i.e., changes the value of the data.
The leader node will record the maximum log index that has been committed (commited), and then subsequent heartbeats and log replication requests will take this value with them, so that the slave nodes will know which records have been committed, and will themselves get the state machine to start executing the records in the log. This results in consistency of data across all state machines!
Such a logging mechanism ensures that if the index and term of a record in the log files of different nodes are the same, then their contents must also be the same, and the previous log records must also be the same.
When the master node sends a request for log replication, it takes the index and term of the previous log record with it, and if the slave node finds that this record does not exist in its own log, it rejects the request.
Under normal circumstances, each log replication completes properly and the nodes all ensure that the log records are identical. However, if the leader node crashes, there may be inconsistent logs (the crashed master node has not fully replicated the records in its log file to other nodes, so some nodes have more logs than others).
For requests with inconsistent log content, draft takes the approach of overwriting the follower node log with the master node log content, first finding the first inconsistency between the follower node log and its own log record, and then overwriting it all the way to the end.
The whole process is like this: when a node is elected leader, it sends a log copy request to the follower node with nextIndex (the index of the next log record to be sent by the master node), if the follower node has inconsistent log records, it rejects the request, then the master node knows the inconsistency, decrements nextIndex, and then sends the request again until the logs are consistent. Then the master node knows the inconsistency, decrements the nextIndex, and sends the request again until the logs are consistent and everything returns to normal, then it continues to send the log copy request and it will overwrite the logs of the slave node with the log contents of the master node.
Safety
The aforementioned master node election and log replication are the core of the raft algorithm, which ensures that the records in the logs are ultimately consistent, but does not yet guarantee that the state machines of all nodes can execute commands sequentially. raft places restrictions on the master node election to achieve correctness of the algorithm.
In summary, the restriction is only one sentence: Only the node that has saved the latest log can be elected as leader, and if the node finds that the log of the candidate node is not as new as its own, it will refuse to vote for it. Since the latest log is saved, the follower node and the new leader are kept in sync so that there is no data conflict after the new leader is created. This also ensures that the leader node does not overwrite the records in the log.
The above latest log refers to the fact that all committed log records are saved, because committed already contains log records that most nodes in the cluster will have corresponding log records, so it is guaranteed that candidates without latest records will not be selected (because most nodes will refuse to vote for it), and at least one node is eligible (as long as the number of cluster nodes exceeds 3).
Summary
In addition to the core elements mentioned above, the raft algorithm also has solutions to ensure data consistency when nodes are added or deleted, as well as log compaction using snapshots, and also requires clients to send requests with an id, and raft clusters to ensure idempotency of request processing.
In general, ease of understanding is at the core of raft’s emphasis, and it is important to ensure that the algorithm and system are easy to understand without losing functionality and performance, which is why raft, which just appeared in 2013, has become the core algorithm for many new distributed systems (e.g., distributed key-value database etcd) compared to the paxos algorithm, which appeared a long time ago.