I’ve been using Rust for more than two years now, and despite countless struggles with the compiler, I still encounter problems from time to time that I can’t understand, not to mention newbies. What could be written in a few hours before may take a day with Rust, so it’s important to document some of the questions you have with Rust to deepen your understanding of the problem.
RAII
A variable is used in Rust not only to hold data, but also to implement RAII (Resource Acquisition as Initialization), which was first introduced when designing C++’s exceptions. RAII is a concept that was first introduced when designing C++ exceptions in order to solve the problem that resources can be safely reclaimed when an exception occurs.
RAII requires that the validity of a resource is strictly bound to the life cycle of the variable, with the resource being acquired at constructor time and released at destructor time.
A resource can normally only be released once, otherwise there is a risk of a similar problem with dangling pointer (dangling pointer), so this requires that a resource can only have one owner, and a variable with ownership A variable with ownership can perform the following two operations.
- derive its reference through the borrow mechanism, which can be subdivided into mutable and immutable references
- transfer its ownership directly through move, which usually occurs during assignment or function calls
Move and Copy
The default for variable assignment is move semantics, which means that the ownership of the previous resource is transferred to the new variable and the moved variable is no longer available, and the drop function is executed when the new variable expires.
|
|
The opposite of the move semantics is the copy semantics, which is a direct copy of the binary bits of the value (bitwise copy), where the ownership of the original variable is not transferred and the newly generated variable has a separate ownership.
A data type that allows a shallow copy is a copy type. For example, &str, only the pointer and length fields can be copied, and since the reference has no ownership, the drop function will not be executed when it is destroyed, just make sure the new reference has the same life cycle as before. But String is not a copy type, because if it is only a shallow copy, it will cause the data in the heap to have two owners, which will lead to the problem of double free.
In general, if a type can be a copy type, try to define it as a copy type. Obviously, the copy type will work better than the move type, as will be shown later.
It’s worth pointing out that the copy type and move type are similar at the implementation level, both being based on memcpy-like operations. It’s understandable that the copy type needs to be copied, after all, a new element is created, but isn’t it a bit heavy for a move? After all, move is more common in Rust, will it have an impact on performance? (Is zero-overhead just a slogan?) There has been a lot of discussion in the community about this.
- Can I trust Rust to optimize move semantics?
- Inherently inefficient calling convention in Rust?
- What are move semantics in Rust?
- Do move forwarding on MIR #32966
The conclusion is that it depends on the situation. In most cases, Rust optimizes the unneeded copies when it does the release compilation, and some of the techniques mentioned in the link above include.
- function inline
- big struct might not be constructed at all due to constant propagation and folding
- returning something by-value might be converted into something more efficient automatically(such as LLVM passing in an out-pointer to the returning function to construct the value in the caller’s frame)
Copy and Clone
In the Rust implementation, the copy type implements the Copy trait, and since the copy type does a simple memcpy when copying, the Copy trait does not have any methods in it.
As you can see from the above definition, Copy inherits from Clone. The Clone trait has a clone method, which can be a simple memcpy-like operation or contain arbitrary assignment operations, so Clone has a broader scope than Copy and is therefore its parent trait.
The main difference between the two is that Copy is called implicitly, while Clone needs to be called explicitly.
Borrow
For Rust beginners, you will basically encounter the borrow checker error from time to time. A typical error example.
The above program will report the following error when compiled.
Although in do_something the argument is the immutable &self and the member property items is not accessed inside the function, the current version of Rust is not that smart about it. There are two ways to solve this problem.
- manually inline and copy the code inside
do_somethingdirectly into the for loop - use a smart pointer with interior mutability (e.g. RefCell) to bypass the compile-time checks of the borrow checker
In View types for Rust, Niko, a core Rust developer, has conceived a solution, similar to a view table in a database. The problem can be avoided by defining multiple type alias to explicitly specify the fields that need to be accessed. But there is no rfc to follow up on this yet, some other discussions in the community are
Closures
Closures are basic types provided in Rust to provide functional programming capabilities, but due to the existence of a lifecycle, closures are subject to some bizarre behavior, such as
|
|
In Rust’s lifecycle elimination rules, one of them is
If there is only one incoming return value, then they have the same lifecycle
That’s why the function fn_elision compiles, but this rule doesn’t apply to closures. The reason for this is that the declaration cycle of a closure is more complicated than that of a function. Unlike a function, which only needs to consider the input parameters, a closure has to consider the life cycle of the variables it binds, which is not a simple task (imagine that the closure then calls another closure.). So the compiler didn’t do it, using the simplest rule, the return value life cycle is greater than the incoming parameters.
Pin
The existence of the move mechanism makes it difficult to properly express ‘self-reference’ structures such as chains, trees, etc. in Rust. The main problem.
move only makes a copy of the value itself, the pointers remain unchanged
If the moved structure has a pointer to another field, then the pointing is illegal after the move, because the original pointing has changed addresses.
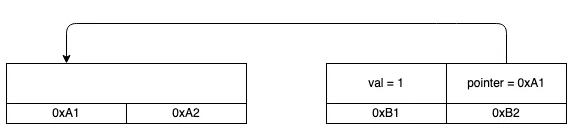
Cloudflare’s Pin, Unpin, and why Rust needs them article explains the solution to this problem in detail, so I won’t repeat it here.
Cow
Cow is probably the trait most easily overlooked by beginners, and the abs_all example in the official documentation does not explain the practical value of copy-on-write very well. In fact, the semantics of Cow can be thought of as ‘potentially owned’, which can be used to avoid unnecessary copies.
The above example looks fine, but it will compile with the following error.
If the return value is changed to String, there will be an additional copy in the else branch, where Cow can come in handy.
Another similar example (playground).
|
|
In the above example, the first property of the structure has a lifecycle of 'a, the second property is a closure, and the parameter has a lifecycle of 'a, and direct compilation will report the following error.
|
|
Similar to the error reported in the first example, Cow can also be used to solve this problem with minimal copying.
index expressions
In Rust, in order to keep code writing clean (ergonomics), some things are done automatically, such as type derivation, operator overloading, etc., but I don’t agree with some of these practices. Here is the reason by index expression.
For arrays and slice types, you can use [index] for element access, and other types can support this syntax by implementing Index trait.
The index method returns a reference type, but when accessed via the syntax container[idx], the return is not a reference type, and Rust automatically converts that form to *container.index(idx), which is a nice way of saying that you can assign a value directly via let value = v[idx]. to copy type assignment.
However, I think this approach is a bit of a complication, as the index argument clearly requires a &self reference, but the index expression returns a reference instead of a reference, and the user must use &v[idx] to return the reference, which may look syntactically uniform, but will make some careful users feel awkward. This kind of implicit compiler operation can easily lead to compiler errors that do not correspond to the user’s code.
|
|
It is also clear from this that the copy type is preferred in Rust. Some discussions in the community.
- Why does the Index trait require returning a reference?
- Extending deref/index with ownership transfer: DerefMove, IndexMove, IndexSet #997
- Why could index take an Idx: ?Sized
Deref trait
Dereference expressions
*expression is a dereference expression in Rust that, when applied to pointer types (mainly: references & , &mut , native pointers *const , * mut), which is consistent with C/C++, but when applied to non-pointer types, it means *std::ops::Deref::deref(&x). For example, String’s Deref is implemented as follows.
Then the type &str can be obtained as follows.
Type autoconversion
Type autoconversion is another implicit operation provided by Rust in the pursuit of language simplicity, for example, the following assignments are all correct.
You can see that no matter how many &s there are, Rust correctly converts them to &str types, because of deref coercions, which allows &T to be automatically converted to &U when T: Deref<U>.
Since the assignment of s2 works by using the principle of deref coercion, what about s3/s4/s5? With a little Rust experience, when a type can call a method that it doesn’t know where it’s defined, it’s probably the blanket implementation of the trait that’s doing the trick, which is the case here.
The above code is a generic implementation of Deref. With this generic implementation in mind, let’s see how the assignment is done later.
- For s3, T is
&&strand U is&str, so s3 can be assigned correctly - For s4, T is
&&strand U is&&str, and then it is converted according to s3, so s4 is also assigned correctly - For s5, this is equivalent to deref coercions three times
In addition, Deref also automatically performs type conversions when methods are called, e.g.
This is handy when you are familiar with the API, but can be confusing for beginners, for example when you see a variable calling a method that is not of that type, it is likely that deref is in play.
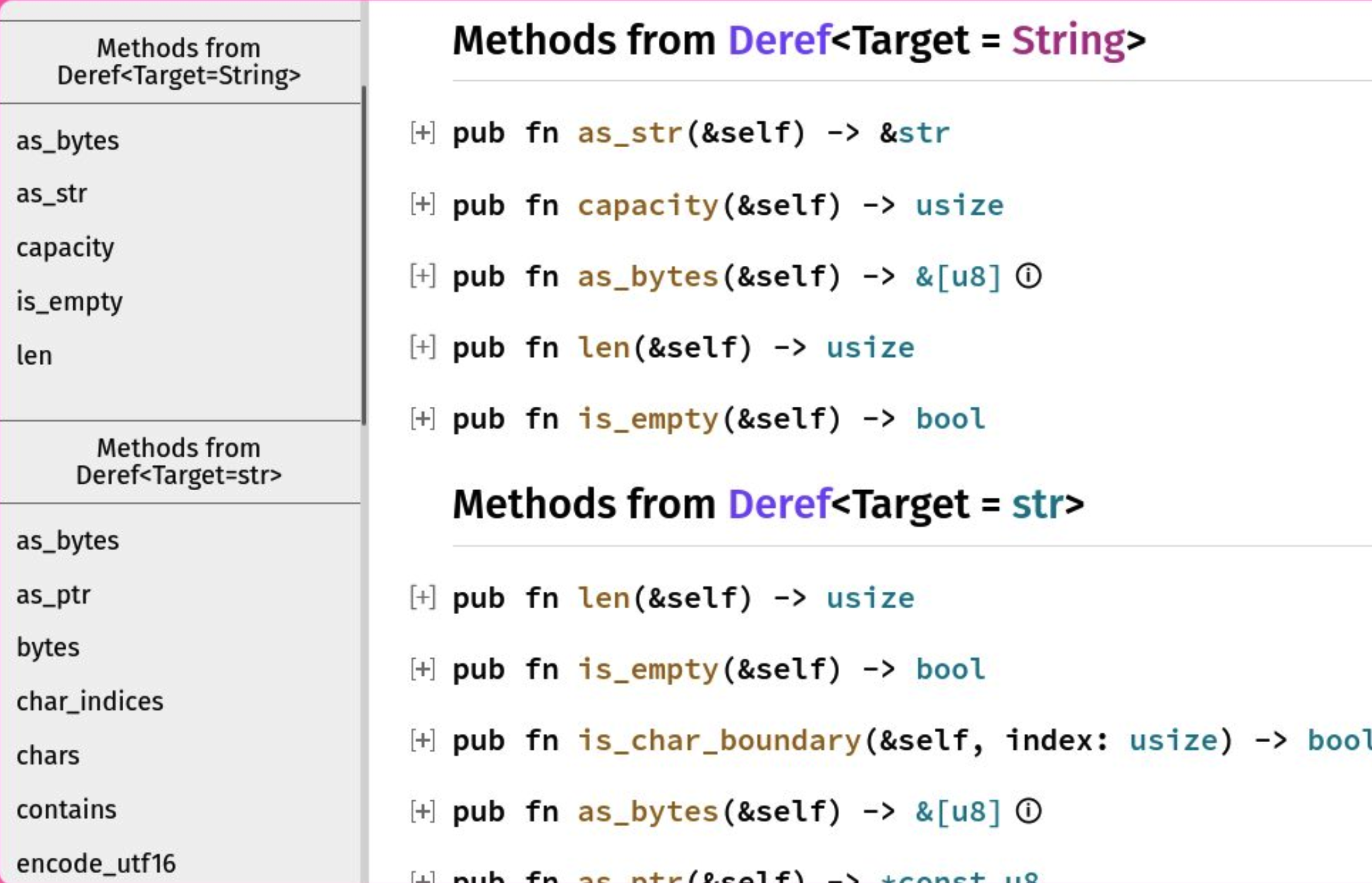
In Rust 1.58 improved documentation, you can show all methods after deref. For example, if a type Foo has Deref<Target = String>, then the documentation will show both String and str methods (source of screenshot).
Unsafe
Unsafe is a backdoor for Rust, as it is likely that some code will not compile when its constraints are applied. But unsafe, as its name implies, can step on its own toes if you’re not careful. In view of the length of this article, the following community practices can be found in unsafe’s usage notes.
Summary
Rust’s unique ownership mechanism brings a lot of complexity to writing programs, and Rust’s pursuit of language simplicity will implicitly do a lot of operations, which add up to something that can easily lead to confusion for beginners when analyzing programs. But these problems are flaws in some people’s eyes, but in other people’s eyes are opportunities. Big companies at home and abroad are now heavily involved in building the Rust community, for example, Google’s new generation Fuchisa operating system makes heavy use of Rust, and Google is also advancing Rust has also become a second language for Linux development, something that C++ has not done. So, Let’s Go Rust!