This article will introduce how to prepare the Dataset and integrate SageMaker before training AI models, and what problems and challenges are encountered in the process. The team provides an AI platform that allows users to upload their own Dataset to be used with the team’s internal default Dataset for AI model training, and then make the model available to users for download. Simply put, users only need to provide the Dataset and set the AI training parameters, and then they can get the final model for subsequent integration development. Next, we explore the process of uploading Dataset by users.
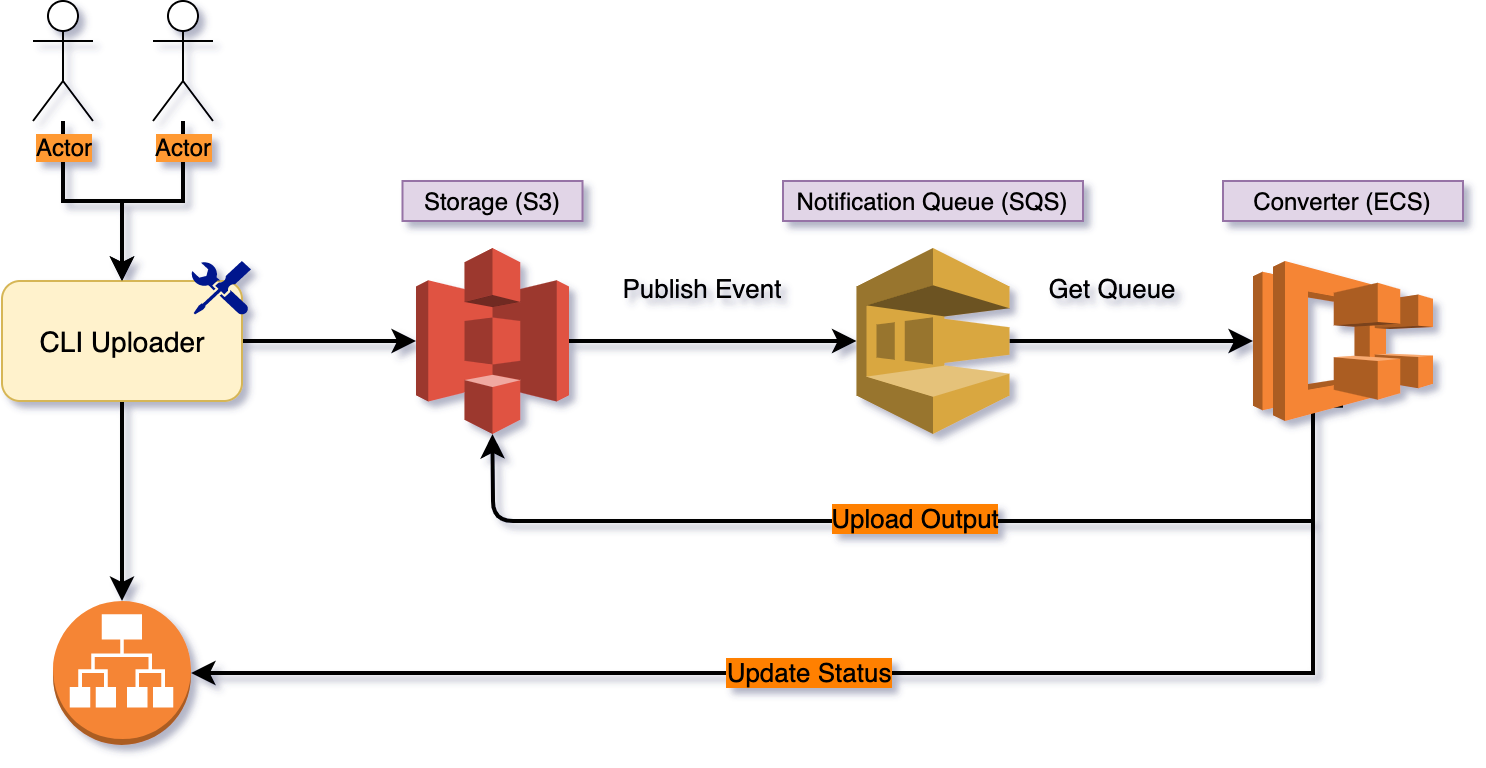
Upload process
After getting the file, it needs to be converted to tfrecord format and then repackaged and uploaded to AWS S3 space. Once the upload is finished, S3 will send Push Event to AWS SQS, and then the backend will provide another service to receive the SQS message. Each time it gets the message, it will download the file for conversion, pack it and upload it back to S3, and send the process message back to the API service to notify the front-end.
File Problem
Before we talk about the problem, let’s take a look at the SageMaker training model process, and the Training Job process first:
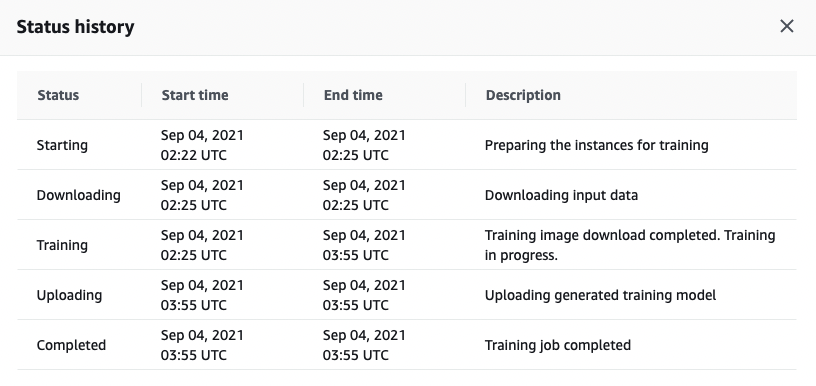
You can see that the second step is Downloading, that is, every time the training process, you need to download from S3, so each training, you need to waste download time, and this time in SageMaker is counted in the training time, that is, the need to spend money, assuming that the file has a 100G, not only let the training model to increase a lot of time outside, but also It costs a lot of extra money.
In addition to the Dataset provided by the user, we also need to add our own 1TB Dataset for training, so if we put the 1TB data on S3, it may take an hour from downloading to decompressing, so this solution through S3 is definitely not possible, wasting time and money. Therefore, we finally discussed with Taiwan AWS team to use AWS FSx for Lustre solution.
Using Amazon FSx for Lustre
First of all, Lustre is a cloud network disk, its biggest advantage is that it can integrate with AWS S3, as long as S3 has added any files, Lustre will sync the files in at any time, but this is limited to one-way sync, that is S3 -> Lustre, if you mount Lustre on EC2 and cut off any files, it will not sync to S3. This point needs to be noted very carefully.
Originally, the team thought that it would be good to synchronize S3 to Lustre, but the problem is that there is an AWS S3 Bucket with ObjectCreated bound to SQS, as in the following HCL syntax example ( Terraform), but as long as you use S3 to sync to Lustre, you need to bind the same Event, which is not configurable at all, and will spray API errors, which means that the developer has to choose one or the other, which is actually quite strange. It is only right that AWS S3 should be able to send the same Event to different Targets, and because of this, the team cancelled the transfer of the user’s Dataset to the Lustre disk.
|
|
In the end, the team only put their own Dataset (800G) on Lustre. As a reminder, the low consumption of Lustre is 1.2TB, so if the team only has a small amount of Dataset, they should not use Lustre.
Using Amazon Elastic File System
The above Lustre integration with SageMaker was quite successful, and the whole training model process was set up smoothly. However, since most of the customers are in China, we moved the entire Global AWS architecture to AWS China Beijing Region. However, during the build process, we received the following error message directly from the SageMaker API.
FSx for Lustre is currently not supported in the region cn-north-1 for SageMaker
I was really dumbfounded to see this message, so I opened AWS Web Console directly to see if there were any missing features, but it turned out that the File System feature was not available from the UI.
We immediately checked with the AWS team to see if Lustre was supported, and the answer was that only EFS was supported, and the UI did not support EFS, but could only be connected through the API. The backend team immediately started to convert Lustre to EFS, and encountered some configuration issues during the conversion process, such as the following:
ClientError: Unable to mount file system: fs-0337a79e, directory path: /efs/mtk. File system connection timed out. Please ensure that mount target IP address of file system is reachable and the security groups you associate with file system must allow inbound access on NFS port.
EFS uses the 2049/TCP port, so a new lower firewall needs to be added and set under the Security Group of EFS.
After fixing the above network problem, I encountered the following problem:
ClientError: Unable to mount file system: fs-0337a79e, directory path: /efs/mtk. No such file or directory: /efs/mtk.
This is a relatively easy problem to solve. The reason is that Lustre itself provides a mount point in a specific location, like /efs, and EFS itself has a mount point preset at /, so you just need to reset it in the API.
|
|
After fixing the above path problem, I encountered another network problem:
ClientError: Data download failed:Please ensure that the subnet’s route table has a route to an S3 VPC endpoint or a NAT device, and both the security groups and the subnet’s network ACL allow outbound traffic to S3.
The main factor for successful access is that this EC2 is in the Public Subnet, which has permission to access the Internet, and the Public Subnet mainly has route table with internet gateway to access the Internet.
The reason for this problem is that the architecture is using Private Subnet and this Subnet cannot access the Internet, so we need to use S3 VPC endpoints to solve this problem. So you can access S3 files by setting S3 VPC Endpoint method.
Summary
A key conclusion here is that if the team really wants to build in AWS China, they need to test Gloabl AWS and also go to China to see if the same features are available or else the whole process will be modified quite a bit. The good thing is that we only encountered AWS Lustre switching to AWS EFS this time.
In addition, when setting up the whole AWS environment, we need to have a certain concept of network, and firewall, the team is very strict for the privilege part, the privilege that is not useful is pulled out, or the privilege on the IAM is opened slowly, not all at once.