Split lock is a memory bus lock supported by the CPU to support atomic memory accesses across a cache line.
Some processors like ARM and RISC-V do not allow unaligned memory accesses and do not generate atomic accesses across cache lines, so split lock is not generated, while X86 supports it.
Split lock is convenient for developers because there is no need to consider unaligned memory access, but it also comes at a cost: an instruction that generates split lock will occupy the memory bus exclusively for about 1000 clock cycles, compared to less than 10 clock cycles for a normal ADD instruction, and locking the memory bus so that other CPUs cannot access memory can seriously affect system performance.
Therefore, the detection and handling of split lock is very important. Nowadays, CPUs support the detection capability, and will directly panic if detected in the kernel state, and will try to actively sleep in the user state to reduce the frequency of split lock generation, or kill the user state process, thus alleviating the contention for the memory bus.
With the introduction of virtualization, it will try to handle this on the host side, and KVM will notify the vCPU threads in QEMU to actively sleep to reduce the frequency of split lock generation, or even kill the virtual machine. The above conclusions are only as of 2022/4/19 (same below), the community still has different views on split lock handling in the past 2 years, and the handling has changed many times, so the following analysis only discusses the current situation.
1. Split lock background
1.1 Starting with i++
Let’s assume the simplest computing model, a CPU (single core, no Hyper-threading enabled, no Cache), and a block of memory. A C program is running on it executing i++, which corresponds to the assembly code add 1, i.
Analyzing the semantics of the add instruction here, two operands are required, the source operand SRC and the destination operand DEST, to achieve the function DEST = DEST + SRC. Here SRC is the immediate number 1 and DEST is the memory address of i. The CPU needs to first read the content of i in memory, then add 1, and finally write the result to the memory address where i is located. In total, two serial memory operations are generated.
If the computational architecture is more complex, with 2 CPU cores CoreA and CoreB, the above i++ code has to consider the data consistency problem.
1.1.1 Concurrent Write Problem
What if CoreA is writing to i’s memory address while CoreB is writing to i’s memory address at the same time?
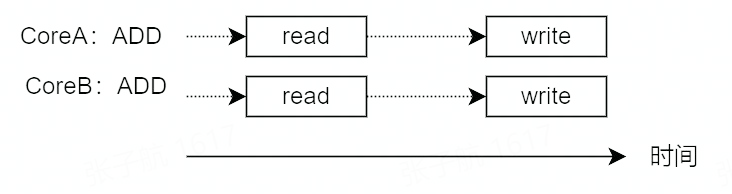
Writing the same memory address concurrently is actually quite simple, and the CPU guarantees the atomicity of the underlying memory operations from hardware.
The specific operations are.
- Read/write 1 byte
- Read/write 16 bit aligned 2 byte
- Read/write 32 bit aligned 4 byte
- Read/write 64 bit aligned 8 byte
1.1.2 Write Overwrite Problem
What if CoreB writes data to i’s memory address during the time after CoreA reads i from memory and before it writes to i’s memory address?
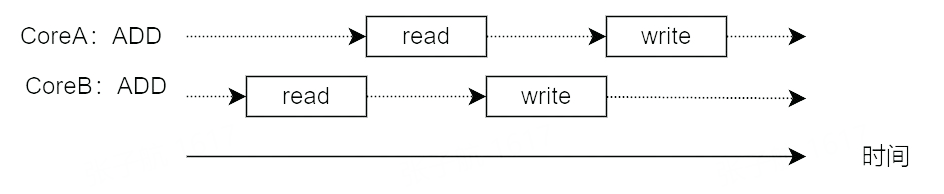
This situation causes the data written by CoreB to be overwritten by the data written by CoreA later, so that the written data of CoreB is lost and CoreA does not know that the written data has been updated after it has been read.
Why does this problem occur? Because the ADD instruction is not an atomic operation and will generate two memory operations.
So how do we solve this problem? Since the ADD instruction is not atomic in hardware, add a lock in software to implement atomic operations so that CoreB’s memory operations cannot be executed until CoreA’s memory operations are complete.

The corresponding method is to declare the instruction prefix LOCK and the assembly code becomes lock add 1, i.
1.2 Bus lock
When the LOCK instruction prefix is declared, the accompanying instruction becomes an atomic instruction. The principle is to lock the system bus during the execution of the accompanying instruction, prohibiting other processors from performing memory operations and making them exclusive to achieve atomic operations.
Here are a few examples.
1.2.1 Atomic Accumulation in QEMU
The function qatomic_inc(ptr) in QEMU adds 1 to the memory data pointed to by the argument ptr.
|
|
The principle is to call the GCC built-in __sync_fetch_and_add function. Let’s write a C program by hand and see the assembly implementation of __sync_fetch_and_add.
|
|
You can see that the assembly implementation of __sync_fetch_and_add declares the lock instruction prefix before the add instruction.
1.2.2 Atomic accumulation in the Kernel
The atomic_inc function in the Kernel adds 1 to the memory data pointed to by the argument v.
|
|
As you can see, the same lock instruction prefix is declared.
1.2.3 CAS (Compare And Swap)
The CAS interface in programming languages provides developers with atomic operations to implement lock-free mechanisms.
Golang’s CAS
Java’s CAS
|
|
As you can see, CAS is also implemented using the lock instruction prefix, so how is the lock instruction prefix implemented specifically?
1.2.4 The LOCK# Signal
Specifically, when a LOCK prefix instruction is declared in front of an instruction in the code, the processor generates the LOCK# signal during the instruction run so that other processors cannot access the memory through the bus.
Let’s try to understand the principle of the LOCK# signal by looking at the pinout diagram of the 8086 CPU.

The 8086 CPU has a LOCK pin (pin 29 in the diagram) that is active low. When the LOCK instruction prefix is declared, the LOCK pin level is pulled low for assert operation, and other devices cannot gain control of the system bus at this time. When the execution of the instruction modified by the LOCK instruction is completed, the LOCK pin level is pulled high for de-assert.
So the whole process is clear. When you want to achieve atomic operation by non-atomic instructions (e.g. add), you need to declare the lock instruction prefix before the instruction when programming, and the lock instruction prefix will be recognized by the processor at runtime and generate the LOCK# signal to make it exclusive to the memory bus, while other processors cannot access the memory through the memory bus, thus achieving atomic operation. So it also solves the above write overwrite problem.
This looks good, but it introduces a new problem.
1.2.5 Performance degradation caused by bus locks
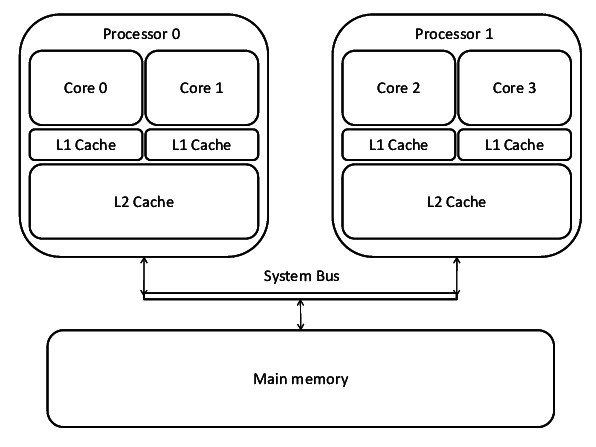
Nowadays there are more and more cores in the processor, what if each core generates LOCK# signals frequently to monopolize the memory bus, so that the rest of the cores cannot access the memory, resulting in a significant performance degradation?
1.3 Cache locking
INTEL introduced the cache locking mechanism on post-P6 processors in order to optimize the performance problems caused by bus locks: the cache coherency protocol guarantees atomicity and consistency of multiple accesses to memory addresses across cache lines by multiple CPU cores without locking the memory bus.
1.3.1 MESI Protocol
Let’s start with a brief introduction to the cache coherency protocol with the common MESI, which is divided into four states:
- Modified (M) The cache line is dirty and has a different value than the main memory. If another CPU core wants to read this data from main memory, the cache line must be written back to main memory and the state becomes shared (S).
- Exclusive (E) The cache line is only in the current cache, but is clean - the cache data is the same as the main memory data. When another cache reads it, the state changes to shared; when the current data is written, the state changes to modified.
- Shared (S) The cache line is also present in other caches and is clean. Cache lines can be discarded at any time.
- Invalid (I) The cache line is invalid.
The MESI protocol state machine is as follows.
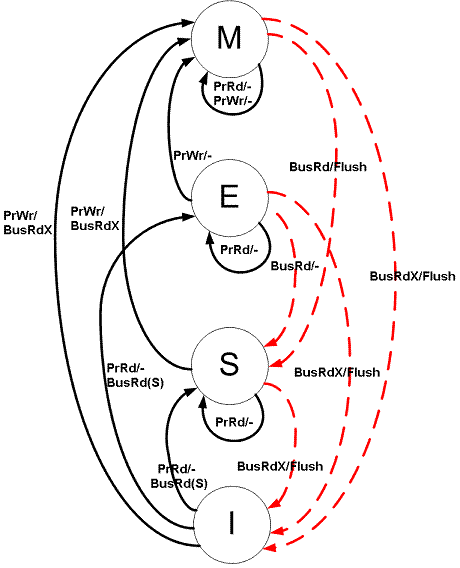
The transition of the state machine is based on two cases.
-
the CPU generates a request for a cache
- a. PrRd: CPU requests to read a cache block
- b. PrWr: CPU requests to write a cache block
-
The bus generates requests to the cache
- a. BusRd: A snooper request indicates that another processor is requesting to read a cache block
- b. BusRdX: A snooper request indicates that another processor is requesting to write a cache block that the processor does not own
- c. BusUpgr: The snooper request indicates that another processor is requesting to write a cache block owned by that processor
- d. Flush: The snooper request indicates that the entire cache is requested to be written back to main memory
- e. FlushOpt: The snooper request indicates that the entire cache block is sent to the bus to be sent to another processor (cache-to-cache copy)
Simply put, through the MESI protocol, each CPU not only knows its own read and write operations to the cache, but also performs bus sniffing (snooping) to know the read and write operations of other CPUs to the cache, so in addition to its own modifications to the cache, it will also change the state of the cache according to the modifications of other CPUs to the cache.
1.3.2 Cache Locking Principle
Cache locking relies on the cache coherency protocol to ensure atomicity of memory accesses, because the cache coherency protocol prevents memory addresses cached by multiple CPUs from being modified by multiple CPUs at the same time.
Here is an example of how cache locking achieves atomicity of memory reads and writes based on the MESI protocol.
Let’s assume that there are two CPU Cores, CoreA and CoreB, for the analysis.
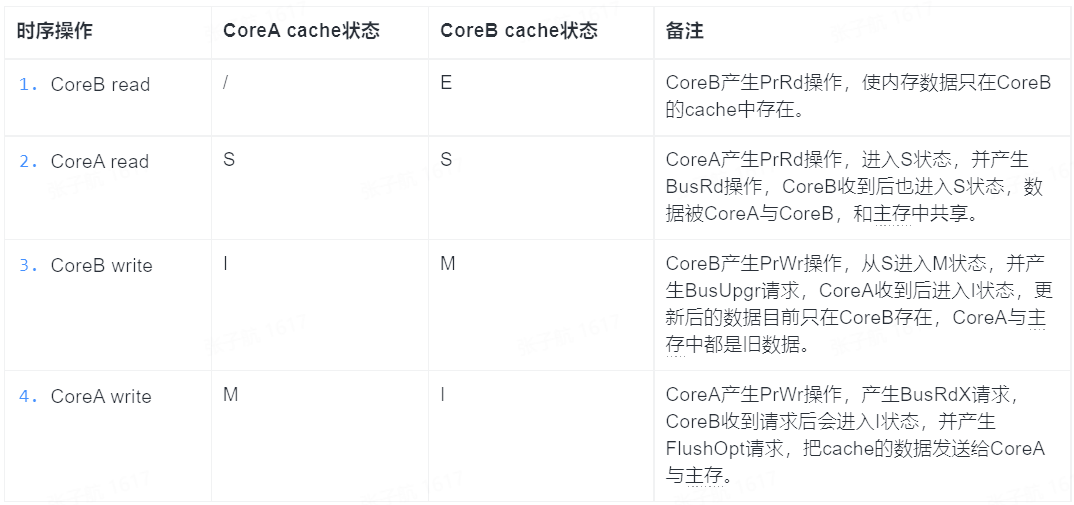
Note the last operation step 4, after CoreB modifies the data in cache, when CoreA wants to modify it again, it will be sniffed by CoreB, and CoreA will modify it only after CoreB’s data is synchronized to main memory and CoreA.
We can see that the data modified by CoreB is not lost and is synchronized to CoreA and main memory. And the above operation is implemented without locking the memory bus, only CoreA’s modification is blocked for a while, which is manageable compared to locking the whole memory bus.
The above is a relatively simple case, where the writes to both CPU Cores are serial. What if CoreA and CoreB send write requests at the same time after operation step 2? Will the cache of both Cores enter the M state?
The answer is no. The MESI protocol ensures that the above scenario of simultaneous M does not happen. According to the MESI protocol, a Core’s PrWr operation can only be freely executed when its cache is in state M or E. If it is in state S, the other Core’s cache must first be set to state I. This is done through a bus broadcast called Request For Ownership (RFO), which is a bus transaction. If two Cores broadcast RFO to the bus at the same time and both want to invalidate each other’s cache, the bus will arbitrate and the final result will be that only one Core will succeed in broadcasting and the other Core will fail and its cache will be set to I state. So we can see that with the introduction of the cache layer, atomic operations are now implemented by bus arbitration instead of locking the memory bus.
If the LOCK instruction prefix is declared, then the corresponding cache address will be locked by the bus. In the above example, other Cores will wait until the end of instruction execution before accessing it, which means that it becomes a serial operation and achieves atomicity for cache reads and writes.
So, to summarize, cache lock: if the LOCK instruction prefix is declared in front of a code instruction to access memory data atomically, and if the memory data can be cached in the CPU’s cache, the runtime usually does not generate the LOCK# signal on the bus, but prevents two or more CPU cores from accessing the same address concurrently through the cache coherency protocol, bus arbitration mechanism and cache locking. The cache coherency protocol, bus arbitration mechanism and cache locking are used to prevent two or more CPU cores from accessing the same address concurrently.
So can all bus locks be optimized for cache locks? The answer is no. The case that cannot be optimized is split lock.
1.4 Split lock
Since the granularity of the cache coherency protocol is a cache line, when the data of an atomic operation crosses a cache line, the cache locking mechanism cannot guarantee data consistency and degenerates to a bus lock to ensure consistency, which is split lock.
For example, there is the following data structure.
When cached in a cache line of 64 bytes in size, the value member will span the cache line.
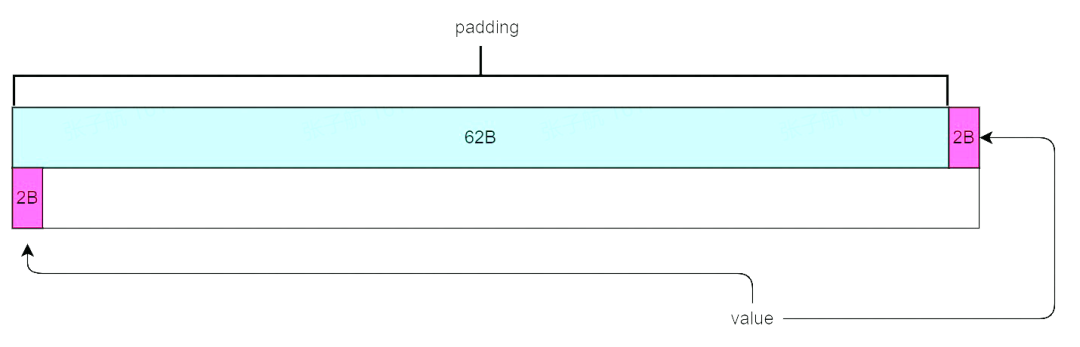
At this point, if you want to manipulate the value members of the Data structure by the LOCK ADD instruction, you cannot solve it by cache locking, and you have to go the old way, locking the bus to ensure data consistency.
Locking the bus causes a serious performance degradation, increasing access latency by a factor of 100, and in memory-intensive operations, performance drops by two orders of magnitude. So in modern X86 processors, it is important to avoid writing code that generates split lock and to have the ability to detect split lock generation.
2. Avoid Split lock
Recall the conditions under which Split lock is generated.
- atomic access to the data is performed
- the data to be accessed is stored across a cache line in the cache
Since atomic operations are relatively basic, let’s take data stored across a cache line as an intervention point.
If the data is stored in only one cache line, the problem can be solved.
2.1 Compiler optimizations
The GCC feature __attribute__((packed)), used in our previous data structure, indicates that no memory alignment optimization is performed.
If __attribute__((packed)) is not introduced, when using memory alignment optimizations, the compiler pads the memory data, for example by filling in 2 bytes after the padding so that the memory address of value can be divided by 4 bytes, thus achieving alignment. When the value is cached in the cache, it will not cross the cache line.
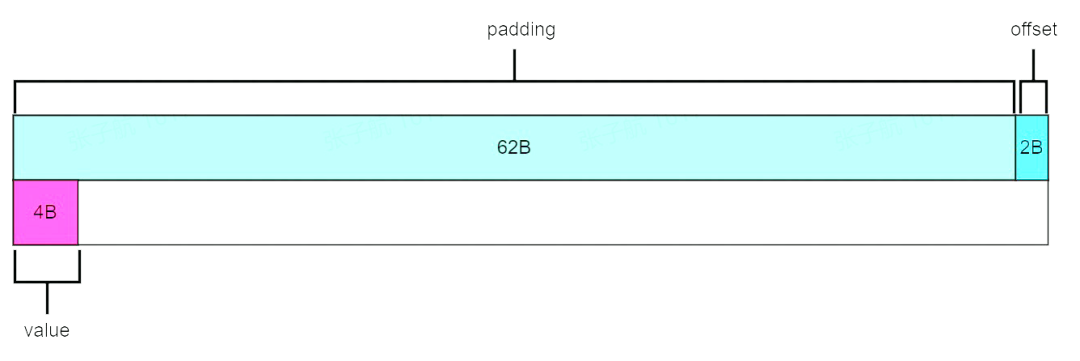
Why did the compiler introduce __attribute__((packed)) when it can be optimized to avoid cross-cache line accesses through memory alignment?
This is because there are benefits to forcing alignment by data structure through __attribute__((packed)). For example, network communication based on data structures, no need to fill extra bytes, etc.
2.2 Precautions
We have the following points to keep in mind when writing code.
- Use the compiler’s memory alignment optimization as much as possible when available.
- When compiler optimization is not available, consider the size and declaration order of structure members.
- When generating potentially unaligned memory accesses, try not to use atomic instructions to do so.
3. Split lock detection and handling
3.1 Usage scenarios
- hard real-time system: When a hard real-time application runs on some cores and another common program runs on other cores, the common program can generate bus lock to break the hard real-time requirement.
- cloud computing: multi-tenant running on a physical machine, bus lock can be generated within a virtual machine to interfere with the performance of other virtual machines.
The following analysis is mainly for the cloud environment, from the bottom up.
3.2 Hardware detection support
An Alignment Check (#AC) exception is generated when a split lock operation is attempted, and a Debug(#DB) trap is generated when a bus lock is acquired and executed.
Hardware distinguishes between split lock and bus lock here.
- split lock is an atomic operation where the operand spans two cache lines.
- bus lock can be generated in two cases, either split lock for writeback memory, or any lock operation for non-writeback memory
Conceptually, split lock is a kind of bus lock, split lock tends to access across cache lines, bus lock tends to lock bus operations.
3.2.1 Related registers (MSR)
Whether or not the corresponding exceptions are generated when split lock and bus lock occur can be controlled by specific registers, the following are the related control registers.
-
MSR_MEMORY_CTRL/MSR_TEST_CTRL: 33H Bit 29 of this MSR controls the #AC exception caused by split lock.
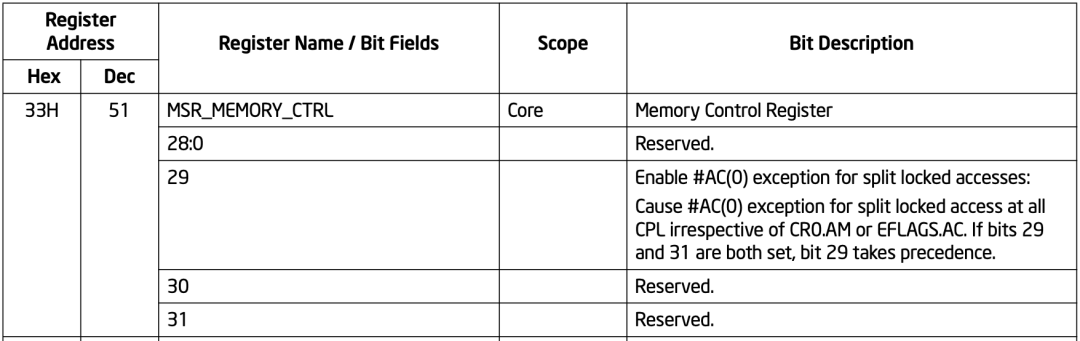
-
IA32_DEBUGCTL: bit 2 of this MSR, controls the #DB exception caused by bus lock.

3.3 Kernel processing support
Take v5.17 as an example for analysis. The current version of the kernel supports a related startup parameter split_lock_detect with the following configuration items and corresponding functions.
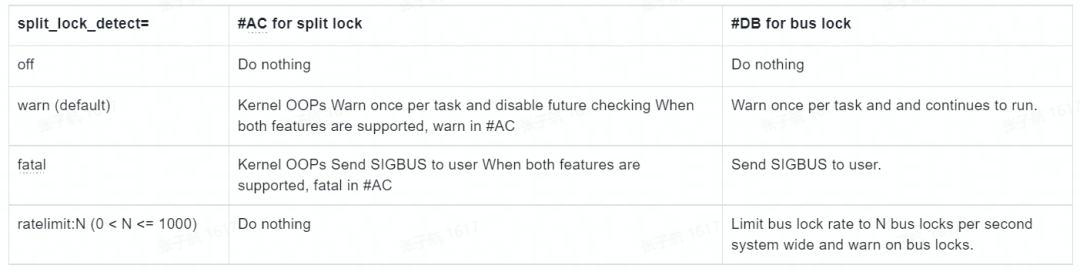
The implementation of split_lock_detect is mainly divided into 3 parts: configuration, initialization, and processing, and we analyze the source code item by item below.
3.3.1 Configuration
When the kernel starts, it will do the setup of sld(split lock detect) first.
|
|
__split_lock_setup tries to enable/disable 33H MSR for verify, and ends without enabling split lock #AC exception, leaving only a global variable msr_test_ctrl_cache to be used as a cache for later manipulation of this MSR.
|
|
What sld_state_setup does is resolve the configuration of the kernel boot parameter split_lock_detect (you can see that the default configuration is at the warn level). In case of ratelimit configuration, a bld_ratelimit global variable is initialized for the handle stage using the kernel’s ratelimit library.
3.3.2 Initialization
After setup completes the basic verify and get the boot parameters configured, a hardware enbale operation is attempted.
3.3.2.1 split lock init
The init of split lock disables hardware detection for split lock if the configured parameter is found to be ratelimit. Other non-off parameters (warn, fatal) will enable the hardware.
3.3.2.2 bus lock init
|
|
In the init of bus lock, if the CPU does not support bus lock, the hardware detection of bus lock will not be enabled, and if the CPU supports both split lock and bus lock hardware detection and the configuration parameter is still warn or fatal, the hardware will not be enabled.
So from the code, there are two cases to enable CPU bus lock detection: one is when the CPU supports bus lock detection and the configuration parameter is specified as ratelimt, and the other is when the CPU does not support split lock detection but supports bus lock detection and the configuration parameter is not off.
3.3.3 Processing
3.3.3.1 split lock handle
|
|
When an #AC exception is generated, if it is not in the user state, it will call die and enter the panic process.
If it is in user state, then configured as fatal, it will send SIGBUS signal to the current user state process, and the user state process will be killed if it does not catch SIGBUS manually.
If the user state is configured as warn, it prints a warning log and outputs the current process information, disable split lock detection, and indicate that the process has been detected once by setting the TIF_SLD bit of the current process flags.
|
|
When context_switch is performed, if the TIF_SLD bits in the flags of the prev process and the next process are different, then a split lock detect switch is performed. The switch is based on the TIF_SLD bit of the next process.
For example, after process A on CPU 0 triggers a split lock warning detection, the split lock detection on CPU 0 is disable to avoid frequent warning logs, and the flags of process A are set to TIF_SLD, and after process A finishes execution, it switches to process B running on CPU 0. The flags of process A and B have different TIF_SLD bits, so we can enable split lock detection according to the flags of process B. When process B finishes execution, it will disable split lock again when it switches to process A again.
The above mechanism achieves the requirement that each process only warn once.
3.3.3.2 bus lock handle
|
|
After the #DB trap is generated, the flow of warn and fatal is basically similar to #AC, we focus here on ratelimit, which is also a strong requirement for the introduction of bus lock.
Forcing the frequency of bus lock generation down to the configured ratelimit. The principle is that if the frequency exceeds the setting, it sleeps for 20 ms until the frequency drops (the frequency here is the frequency at which the whole system generates bus lock).
After the frequency drop, a warning log is generated in the sld_warn case via the compiler’s fallthrough stream.
4. Detection and handling of virtualized environments
The previous analysis was done for the kernel and user state programs (VMX root mode) on the physical machine. In a virtualized environment, we need to consider some more issues, such as how to detect split lock if it comes from the Guest? How to avoid the impact on other Guests? If you enable bus lock ratelimit directly on the Host, it may affect guests who are not ready for it, and if you expose the split lock detection switch directly to the Guest, what happens to the Host or other Guests, etc.
The CPU can support #AC trap for split lock detection in VMX mode, and it is up to the hypervisor to decide what to do later. Most hypervisors forward the trap directly to the Guest, which can cause a crash if the Guest is not ready, as was the case in previous versions of VMX.
So the first step is to get the hypervisor to handle traps correctly.
4.1 Processing flow of virtualized environment
The following is the overall processing flow for split lock and bus lock in a virtualized environment.
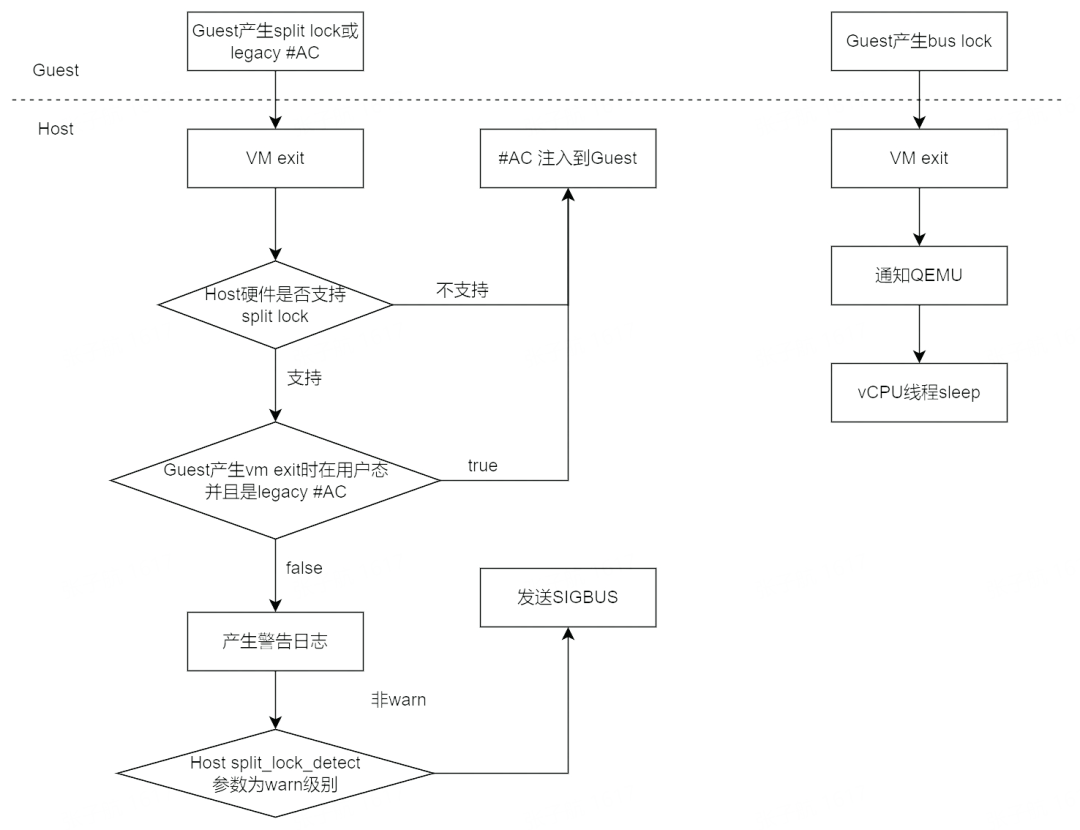
If the hardware does not support split lock detection or is legacy #AC, the #AC will be injected to the Guest for processing, if the hardware supports detection, then a warning will be generated according to the configuration, or even a SIGBUS will be attempted.
After Guest performs bus lock, it will vm exit to kvm, which will notify QEMU and the vCPU thread will actively sleep to downscale.
Let’s analyze this from the bottom up.
4.2 Hardware support
4.2.1 split lock

The #AC exception is included in the NMI exit reason.
4.2.2 bus lock

In VMX non-root mode, the CPU detects the bus lock and generates a VM exit with a reason of 74.
4.3 KVM Support
4.3.1 split lock
|
|
When a split lock operation is generated inside the Guest, the VM will exit because it is an #AC exception.
First of all, there are two types of #AC exceptions themselves.
- legacy #AC exception
- split lock #AC exception
KVM eventually produces two behaviors based on Host and Guest states.
-
Let the Guest process: Inject #AC into the Guest.
- If the hardware does not support split lock detection, inject into Guest unconditionally.
- If the Host enables split lock detection, it will only be injected into the Guest if the #AC exception is generated for the Guest user state and the legacy #AC.
-
Let HOST handle it: generate warnings or even send SIGBUS.
- When not injected into Guest, Host will only warn once per vCPU thread if it is configured to warn, or generate SIGBUS if it is configured to fatal.
4.3.2 bus lock
|
|
After VM exit, the function handle_bus_lock_vmexit is executed according to the reason 74 index, which simply sets bus_lock_detected of exit_reason to bit.
|
|
After executing __vmx_handle_exit. The exit_reason and flags returned to the user state are set after the bus_lock_detected is detected.
4.4 QEMU support
Using the v6.2.0 version as an example for analysis.
|
|
QEMU learns from the KVM return value that bus lock is generated in the Guest and enters kvm_rate_limit_on_bus_lock, which also implements ratelimit through sleep to reduce the frequency of bus lock generated by the Guest.
The ratelimit on the Host is controlled by the split_lock_detect startup parameter, but what about the Guest?
|
|
QEMU ratelimit for Guest bus lock is obtained from the boot parameter bus-lock-ratelimit.
4.5 Libvirt Support
Libvirt supports QEMU’s bus-lock-ratelimit startup parameter which is currently not available from upsteam:
https://listman.redhat.com/archives/libvir-list/2021-December/225755.html
5. Summary
Due to the nature of X86 hardware, which supports atomic semantics across cache lines, implementation requires split lock to maintain atomicity, but this comes at the cost of system-wide access performance. Developers gradually realize that this feature is harmful and try not to use it, for example, kernel developers ensure that they do not generate split lock, even at the expense of kernel panic, while user-state programs generate warnings and then reduce the execution frequency of the program or have the kernel kill it. The virtualized environment has a large software stack, so it is handled by the host-side KVM and QEMU as much as possible to alert or even kill the virtual machine, or to notify QEMU to downscale.