uber, an early adopter of the Go language, is also a “heavy user” of the Go technology stack. uber’s internal Go code repository has 5000w+ lines of Go code and 2100 Go-implemented standalone services, so the scale of Go applications is estimated to be among the top 3 in the world.
ber not only uses Go, but often exports their experiences and lessons learned from using Go.
The blogs of uber engineers are a vehicle for these high-quality Go articles, which are worth reading and experiencing again and again for gophers who want to “go deeper”.
The blog recently posted two articles about concurrent data races in Go, one on Dynamic Data Race Detection in Go Code and the other on Data Race Patterns in Go. These two articles also originated from the pre-print version of the paper “A Study of Real-World Data Races in Golang” published by uber engineers on arxiv.
Here’s a chat with you about these two condensed versions of blog posts, and hopefully we’ll all get something out of them.
1. Go’s built-in data race detector
We know: concurrent programs are bad to develop and even harder to debug. Concurrency is a breeding ground for problems, and even though Go has built-in concurrency and provides concurrency primitives (goroutine, channel, and select) based on the CSP concurrency model, it turns out that in the real world, Go programs do not cause fewer concurrency problems. “No silver bullet” once again!
But the Go core team has been aware of this for a long time and added the race detector to Go tools in Go 1.1. By adding -race to the execution of go tools commands, the detector can find places in a program where a potential concurrency error is raised by concurrent accesses to the same variable (at least one access is a write operation). the Go standard library was also a beneficiary of the introduction of the race detector. race detector has helped the Go standard library detect 42 data race problems.
race detector based on Google a team to develop tools Thread Sanitizer (TSan) (in addition to thread sanitizer, google has a bunch of sanitizer, such as: AddressSanitizer, LeakSanitizer, MemorySanitizer, etc.). The first version of TSan implementation was released in 2009, and the detection algorithm used “from” the old tool Valgrind.
After its release, TSan helped the Chromium browser team identify nearly 200 potential concurrency problems, but the first version of TSan had one of the biggest problems, and that was slow!
Because of the achievements, the development team decided to rewrite TSan, which led to v2. Compared to v1, v2 has several major changes.
- Compile-time injection of code (Instrumentation).
- Reimplementing runtime libraries and building them into compilers (LLVM and GCC).
- In addition to data race detection, deadlock detection, lock release in locked state, etc. can be done.
- About 20 times performance improvement in v2 compared to v1.
- Support Go language.
So how exactly does TSan v2 work? Let’s move on to the next page.
2. How ThreadSanitizer v2 works
According to the description of the v2 algorithm on the Thread Sanitizer wiki, Thread Sanitizer is divided into two parts:the injection code and the runtime library.
1. Injecting code
The first part is to work with the compiler to inject code into the source code during the compilation phase. So what code to inject at what location? As mentioned before, Thread Sanitizer tracks every memory access in the program, so TSan injects code at every memory access, except for the following cases of course.
- Memory access without data races.
For example: read accesses to global constants, accesses in functions to memory that has been shown not to escape to the heap.
- Redundant accesses: read operations that occur before writing to a memory location
- … …
So what code is being injected? Here is an example of writing a memory operation inside the function foo.

We see that the __tsan_write4 function is injected before the write operation to address p. The entry and exit of function foo are injected with __tsan_func_entry and __tsan_func_exit, respectively. And for memory read operations that require code injection, the injected code is __tsan_read4; atomic memory operations are injected using __tsan_atomic for injection….
2. TSan Runtime Library
Once the code is injected at compile time and a Go program with TSan is built, it is the Tsan runtime library that plays the role of data race detection during the runtime of the Go program. How does TSan detect a data race?
TSan’s detection relies on a concept called Shadow Cell. What is a Shadow Cell? A Shadow Cell itself is an 8-byte memory cell that represents an event of a read/write operation to a memory address, i.e., each write or read operation to a memory block generates a Shadow Cell. obviously the Shadow Cell, as a recorder of memory read/write events, itself stores information related to this event, as follows.
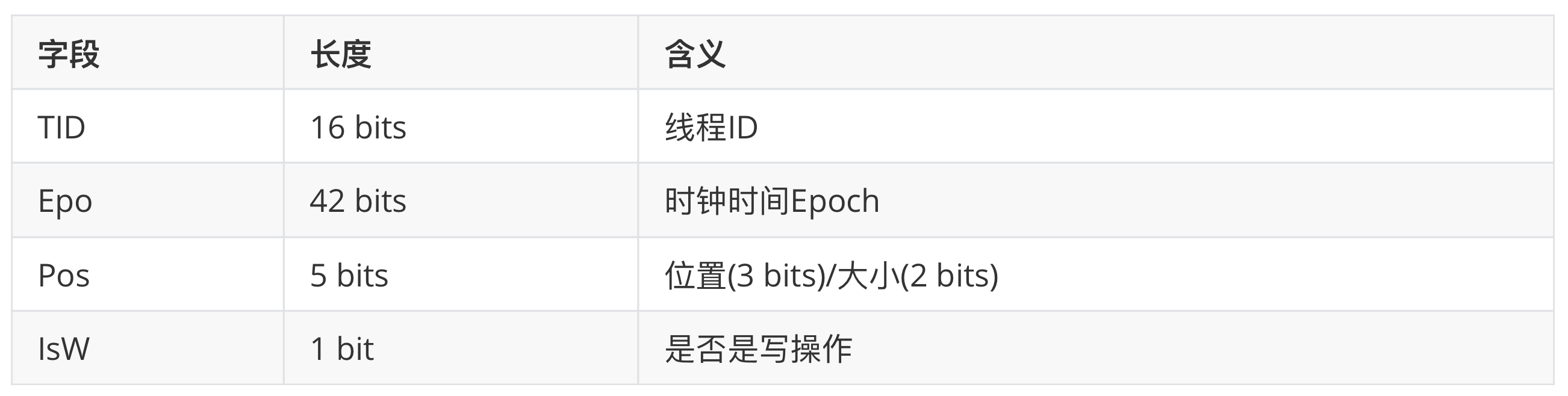
We see that each Shadow Cell records the thread ID, the clock time, the location (offset) and length of the operation accessing the memory and the operation attribute of that memory access event (whether it is a write operation or not). For each application with 8 bytes of memory, TSan corresponds to a set (N) of Shadow Cells , as shown below.
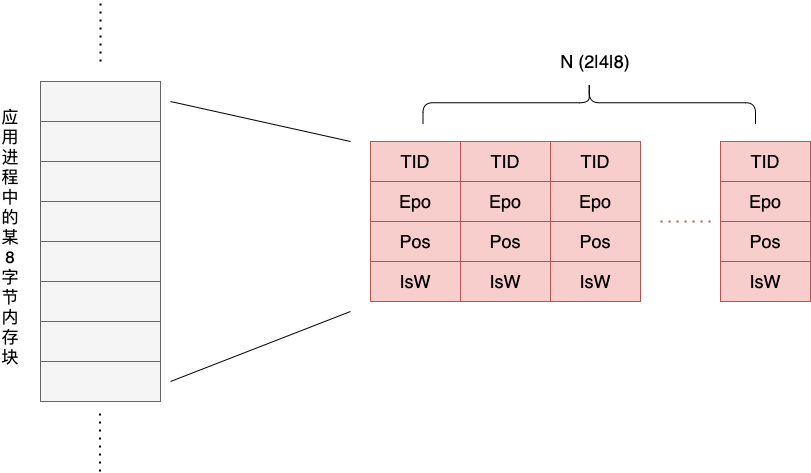
The value of N can be 2, 4, or 8. The value of N directly affects the overhead caused by TSan and the “accuracy” of data race detection.
3. Detection algorithm
With code injection and Shadow Cell, which records memory access events, what logic does TSan use to detect data races? Let’s take a look at how the detection algorithm works with the example given by Google god Dmitry Vyukov in one of his speaks.
Let’s take N=8 as an example (i.e., 8 Shadow Cells are used to track and verify an application’s 8-byte memory block). The following is the initial situation, assuming that there are no read or write operations on the 8-byte application memory block at this time.
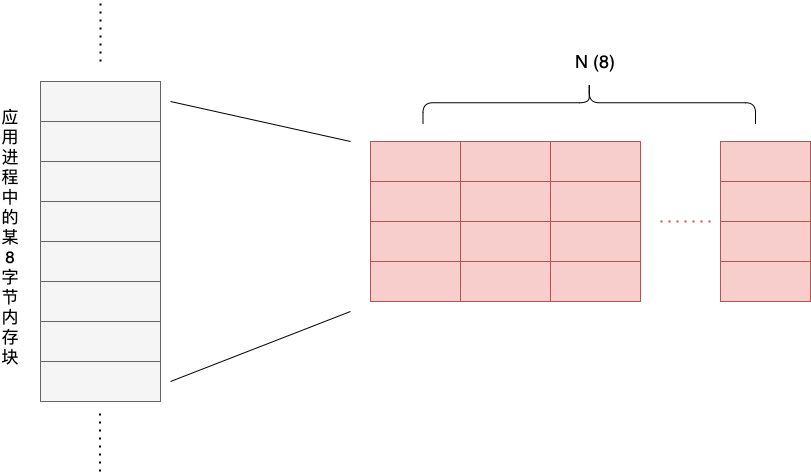
Now, a thread T1 performs a write operation to the first two bytes of that block of memory, and the write operation generates the first Shadow Cell, as shown below.
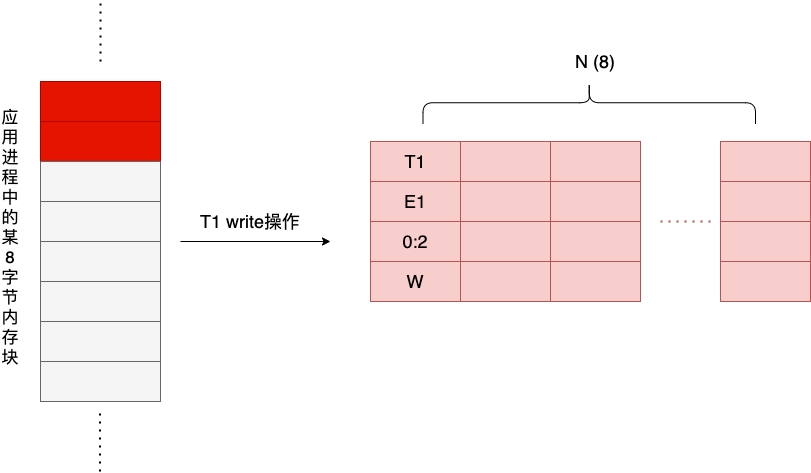
The Pos field describes the starting offset and length of the 8-byte memory cell accessed by the write/read operation, for example, 0:2 here means the starting byte is the first byte and the length is 2 bytes. At this point, the Shadow Cell window has only one Shadow Cell, and there is no possibility of race.
Next, a thread T2 performs another read operation for the last four bytes of the block of memory, and the read operation generates a second Shadow Cell, as shown in the figure below.
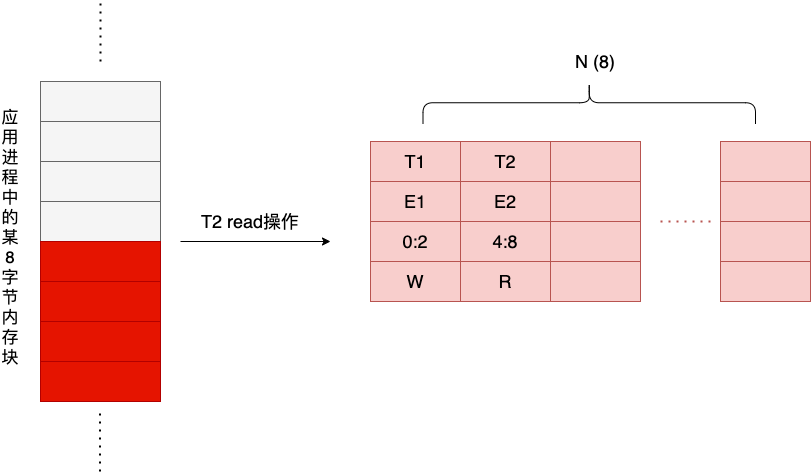
The bytes involved in this read operation do not intersect with the first Shadow Cell, and there is no possibility of a data race.
Next, a thread T3 performs a write operation for the first four bytes of the block of memory, and the write operation generates a third Shadow Cell, as shown in the figure below.
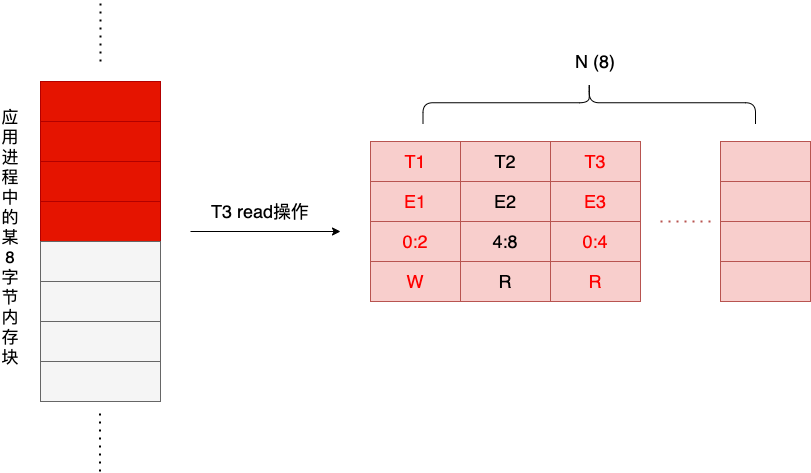
We see that the two threads T1 and T3 have overlapping areas of access to that memory block, and T1 is a write operation, so there is a possibility of data race in this case. TSan’s race detection algorithm is essentially a state machine that is walked through every time a memory access occurs. The logic of the state machine is simple: it goes through all the cells in the Shadow Cell window corresponding to this block of memory, and compares the latest cell with the existing cells one by one, and gives a warning if there is a race.
In this example, T1’s write and T3’s read areas overlap, and if Shallow Cell1’s clock E1 doesn’t have a hapens-before Shadow Cell’s clock E3, then there is a data race. hapens-before is determined by how we can find out from tsan’s implementation We can find out from tsan’s implementation.
In this example, the number of Shadow Cells in a set corresponding to an 8-byte application memory is N=8. However, memory access is a high-frequency event, so soon the Shadow Cell window will be written full, so where is the new Shadow Cell stored? In this case, the TSan algorithm will randomly delete an old Shadow Cell and write the new Shadow Cell. This also confirms what was mentioned earlier: the selection of the N value will affect the detection accuracy of TSan to some extent.
Well, after the initial understanding of the detection principle of TSan v2, let’s go back to uber’s article to see when uber deployed the race detection.
3. When to deploy a dynamic Go data race detector
As we can see from the previous brief description of TSan’s principle, the data race detection brought about by -race has a significant impact on the performance and overhead of the program.
The official Go document “Data Race Detector” shows that Go programs built with -race have 5-10 times more memory overhead and 2-20 times more execution time compared to Go programs built normally. However, we know that the race detector can only detect data contention problems when the program is running. Therefore, Gopher is cautious about using -race, especially in production environments. The 2013 article “Introducing the go race detector”, co-authored by Dmitry Vyukov and Andrew Gerrand, also states outright that it is not practical to keep the race detector in a production environment is impractical. They recommend two times to use race detector: one is to turn on race detector during test execution, especially in integration and stress testing scenarios; the other is to turn on race detector in a production environment, but only one service instance with race detector among many service instances But how much traffic hits this instance is up to you ^_^.
So, how does uber do it internally? As mentioned earlier: uber has a single internal repository containing 5000w+ lines of code, and 10w+ unit test cases in this repository. uber encountered two problems with the timing of deploying the race detector.
- The uncertainty of the -race detection results makes race detection for each pr ineffective.
For example: a certain pr has a data race, but it is not detected when the race detector is executed; the later pr without data race may be detected by the data race in the previous pr when the race detection is executed, which may affect the smooth merging of that pr and the efficiency of the developers concerned.
At the same time, it is impossible to find out all the data race cases in the existing 5000w+ code.
- The overhead of ace detector affects the SLA (I understand that uber’s internal CI pipeline also has a time SLA (a promise to developers) and each PR runs race detect, which may not run on time) and boosts hardware costs.
The deployment strategy for these two problems is to “test after the fact”, i.e. every once in a while, take a snapshot of the code repository and run through all the unit test cases with -race on. Okay, that doesn’t seem like anything new. Many companies probably do it this way.
When a data race problem is found, a report is sent to the appropriate developer. This piece of uber engineers did some work to find out the author most likely to introduce the bug by the information of data race detection results and send the report to him.
However, there is a data worthy of your reference: without data race detection, the p95 digit time to run through all unit tests internally at uber is 25 minutes, while with data race enabled, this time increases 4 times to about 100 minutes.
The above experiment implemented by uber engineers in mid-2021, during which they found the main code patterns that generate data race, and subsequently they may produce static code analysis tools for these patterns to help developers catch data race issues in their code earlier and more effectively. Next, let’s take a look at these code patterns.
4. What are the common data race patterns
uber engineers summarized 7 types of data race patterns, let’s look at them one by one.
1. Closures
The Go language natively provides support for closures. In Go, a closure is a function literal. A closure can refer to variables defined in its wrapping function. These variables are then shared between the wrapping function and the function literal, and these variables continue to exist as long as they can be accessed.
But I don’t know if you realize that Go closures capture variables in their wrapped functions by reference. Unlike languages like C++, you can choose whether to capture by value or by reference. Capture by reference means that once the closure is executed in a new goroutine, there is a high probability of a data race between the two goroutines for access to the captured variables. The “unfortunate” thing is that in Go closures are often used as the execution function of a goroutine.
The uber article gives three examples of data race patterns that result from this undifferentiated capture of variables by reference.
-
Example 1

In this first example, each loop creates a new goroutine based on a closure function. each of these goroutines captures the outside loop variable job, which establishes a race to job between multiple goroutines.
-
Example 2

The combination of the closure and variable declaration scopes in Example 2 creates a new goroutine in which the err variable is the return value of the external Foo function err. This causes the err value to become the “focus” of the race between the two goroutines.
-
Example 3
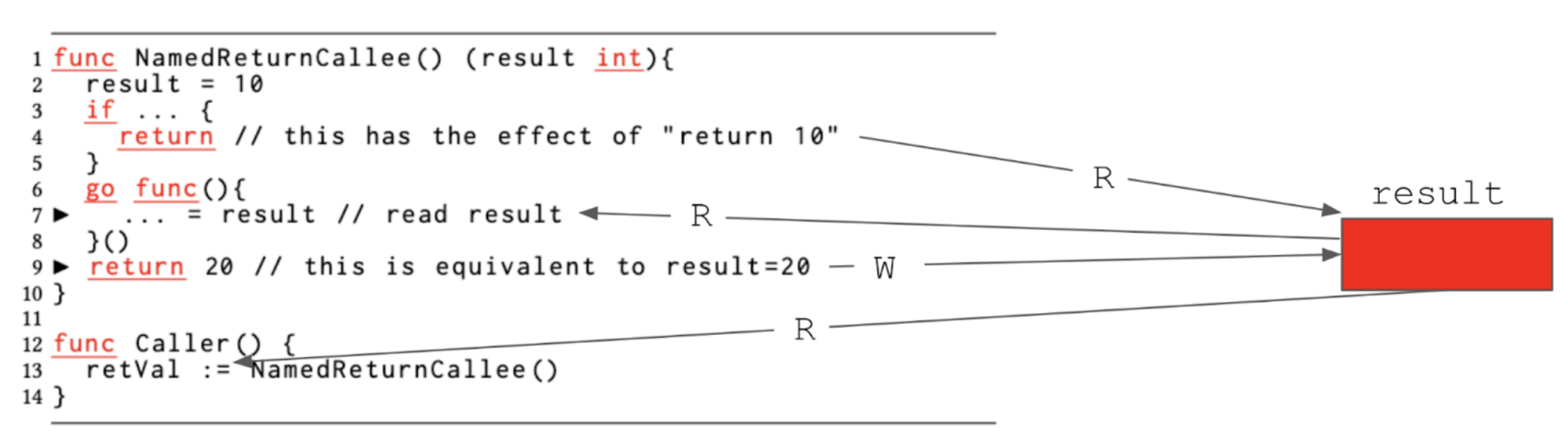
In Example 3, the named return value variable result is caught by the closure of the function executed as a new goroutine, resulting in a data race between the two goroutines on the variable result.
2. Slice
Slices are Go’s built-in composite data type. Compared to traditional arrays, slices have the ability to be dynamically expanded and passed as “slice descriptors” with low and fixed overhead, which makes them widely used in Go. However, while flexible, slices are also one of the most “dodgy” data types in Go, so it is important to be careful when using slices, as mistakes can be made if you are not careful.
Here is an example of forming a data race on a sliced variable.

From this code, it appears that although the developer did synchronize the captured slice variable myResults via mutex, it was protected by not using mutex when passing in the slice when creating a new goroutine later. There seems to be a problem with the example code though, the incoming myResults does not seem to be used additionally.
3. Map
map is the other most commonly used built-in complex data type in go, and is probably second only to slicing in terms of the problems caused by map for go beginners. go map is not goroutine-safe, and go prohibits concurrent reads and writes to map variables. However, because it is a built-in hash table type, map is very widely used in go programming.
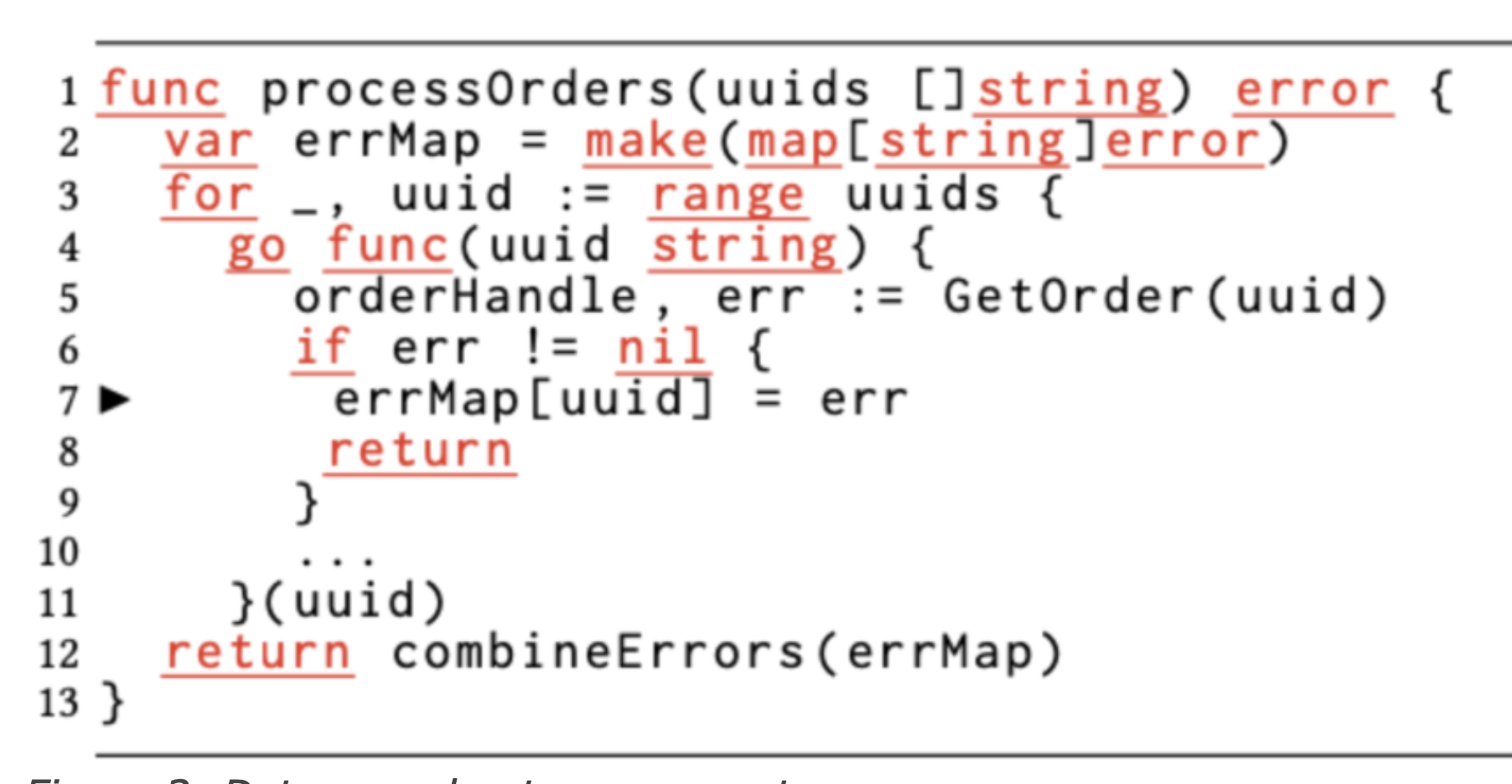
The above example is a concurrent read/write map example, but unlike slice, go has built-in detection of concurrent reads and writes in the map implementation, and even if you don’t add -race, a panic will be thrown once a data race is found.
4. Mistakenly passed values cause trouble
Go recommends using pass-value semantics because it simplifies escape analysis and gives variables a better chance of being assigned to the stack, thus reducing GC pressure. However, there are some types that cannot be passed by passing values, such as sync.Mutex in the example below.

Mutex is a zero-valued available type, we don’t need to do any initial assignment to use Mutex instance. But Mutex type has internal state.

Passing the value would result in a copy of the state and lose the usefulness of synchronizing data access across multiple goroutines, as in the Mutex type variable m in the example above.
5. Misuse of messaging (channel) and shared memory
Go uses the CSP concurrency model, and the channel type acts as the communication mechanism between goroutines. Although the CSP concurrency model is more advanced than shared memory, from a practical point of view, it is very easy to make mistakes when using channels without a good understanding of the CSP model.
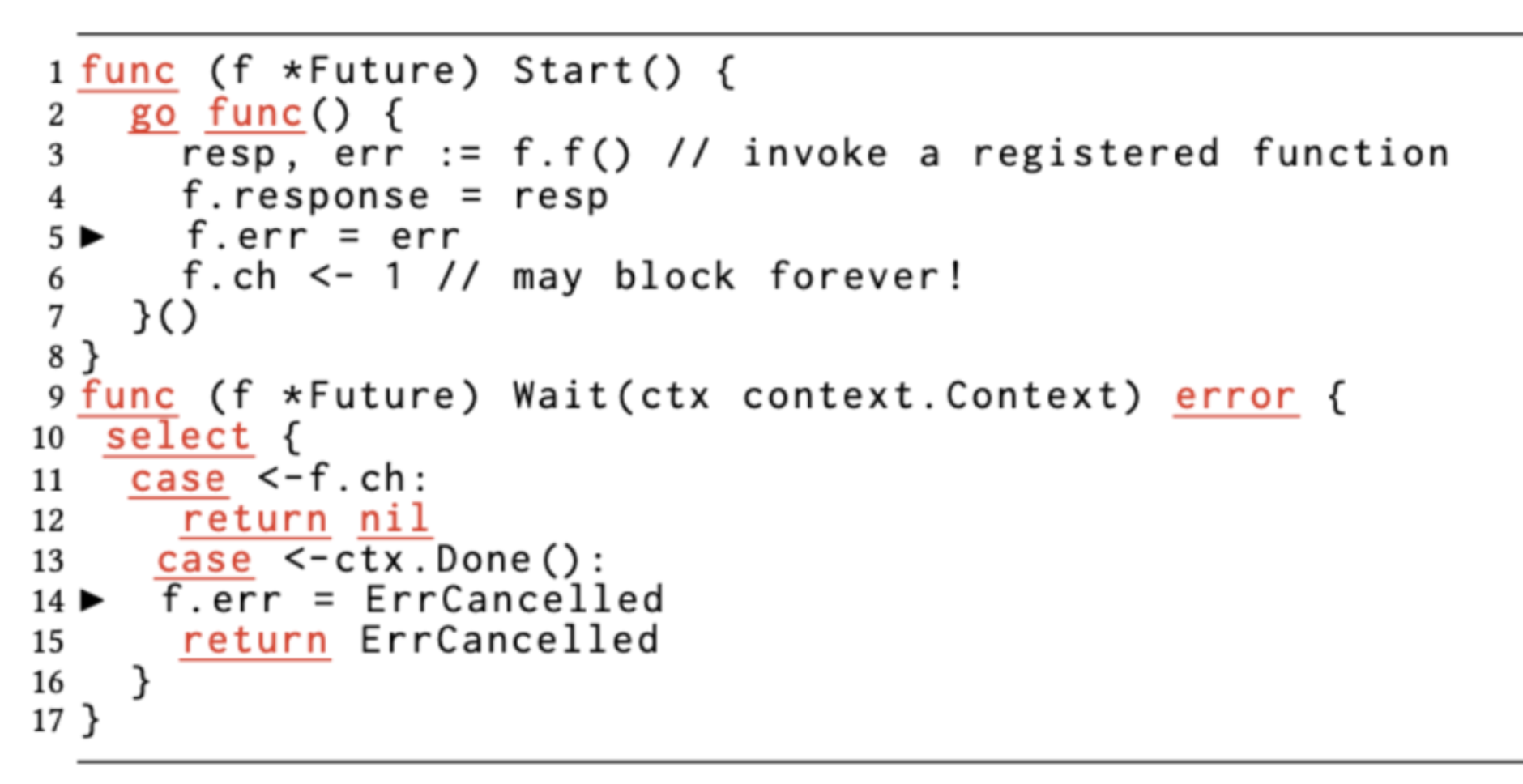
The problem in this example is that the goroutine started by the Start function may block on the f.ch send operation. Because once ctx cancels, Wait will exit and no goroutine will be blocking on f.ch. This will cause the new goroutine started by Start function to block on the line “f.ch <- 1”.
As you can see, problems like this are very subtle and difficult to identify with the naked eye without careful analysis.
6. sync.WaitGroup misuse causes data race problem
sync.WaitGroup is a mechanism commonly used by Go concurrent programs to wait for a group of goroutines to exit. It implements internal count adjustment through the Add and Done methods. And the Wait method is used to wait until the internal counter is 0 before returning. However, misuse of WaitGroup as in the example below can lead to data race problems.

We see that the code in the example places wg.Add(1) in the goroutine execution function, instead of placing Add(1) before the goroutine is created and started, as is the correct method, which results in a data race to the WaitGroup internal counter, likely due to goroutine scheduling problems, making Add(1) may be called before the goroutine has time, resulting in an early Wait return.
The following example is a data race between two goroutines on the locationErr variable due to the order of execution of the defer function when the function returns.

When the main goroutine is determining whether locationErr is nil, doCleanup in another goroutine may or may not be executed.
7. Parallel table-driven tests may trigger a data race
Go has a built-in single test framework and supports parallel testing (testing.T.Parallel()). However, if you use parallel testing, it is extremely easy to cause data race problems. The original article doesn’t give an example, so you can experience it yourself.
5. Summary
About the code pattern of data race, before uber released these two articles, there are also some materials to classify the code pattern of data race problem, such as the following two resources, you can refer to them.
- 《Data Race Detector》- https://go.dev/doc/articles/race_detector
- 《ThreadSanitizer Popular Data Races》- https://github.com/google/sanitizers/wiki/ThreadSanitizerPopularDataRaces
In the just released Go 1.19beta1, the latest -race has been upgraded to TSan v3. The performance of race detection will be improved by 1.5x-2x compared to the previous version, memory overhead is halved, and there is no upper limit on the number of goroutines.
Note: To use -race in Golang, CGO must be enabled.