Kubernetes, a Greek word meaning “helmsman” or “pilot,” is a portable, scalable open source platform that uses declarative configuration to manage orchestration of container services and increase the level of automation and efficiency. At the same time, k8s is supported by a large and still growing ecosystem of available peripheral services, tools and ecological support.
The definition given on the official kubernetes website is as follows.
Kubernetes, also known as K8s, is an open-source system for automating deployment, scaling, and management of containerized applications.
It combines the containers that make up an application into logical units (pods) for easy management and service discovery. kubernetes is derived from Google’s 15 years of operations and maintenance experience in production environments, while bringing together the best ideas and practices of the community.
1. the iterative process of software deployment
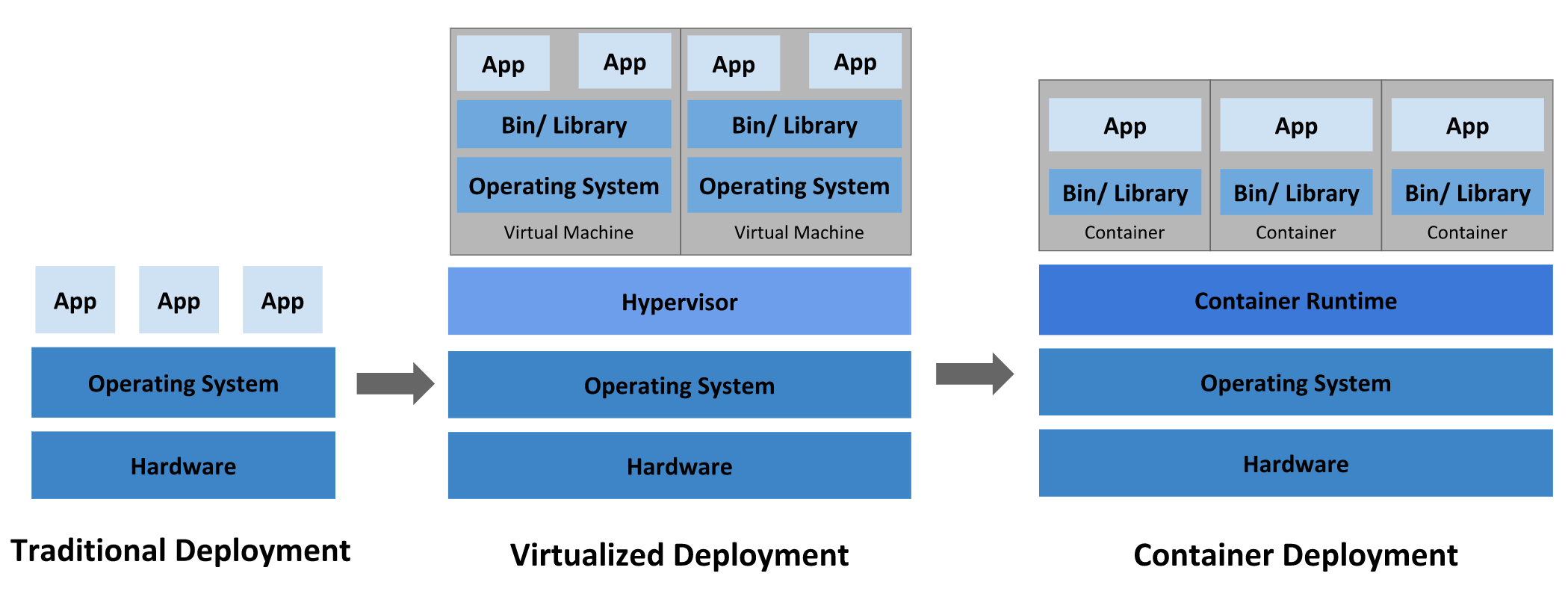
In general, we can divide the software part into three phases:traditional deployment, virtualization deployment, containerization deployment.
Note that although containerization is also a type of virtualization, the virtualization deployment referred to here refers to the deployment of applications through virtual machines created by virtualization methods such as KVM.
-
Traditional Deployment
In the traditional deployment era, all applications run on top of the same physical machine. This caused a lot of trouble for resource segregation. Different applications would compete for system resources and degrade performance, or there might be a situation where one application took up most of the resources while another application had no resources available. At the same time, it is quite troublesome for the operation and maintenance staff to maintain so many physical machines running different applications.
-
Virtualization Deployment
In the era of virtualization deployments, multiple Virtual Machines (VMs) can be created on top of a single physical machine by virtualizing it with the addition of a Hypervisor to the operating system and the support of newer iterations of hardware such as CPUs. Each VM is an independent operating system with its own file system and various resources and virtualized hardware. The operations staff only needs to maintain various VM images.
-
Containerized Deployment
As we said before containerization is technically a kind of virtualization, only containerization goes further and allows different containers to share the operating system of the underlying host through Container Runtime, as containerization is considered as a light virtualization technology. Also, like virtual machines, containers have their own file system, CPU, memory, process space and other resources. And since containers are separated from the underlying operating system, a container can run on different operating systems and cloud environments. Some of the features of containerization technology are as follows.
- decouples the application creation and deployment process: it can provide higher ease of use and efficiency compared to virtual machines
- Continuous development, integration, and deployment (CI/CD): Thanks to the immutability of container images, containerization technology can efficiently and quickly create high-quality container images for deployment and rollback frequently
- Separation of development and operations: The spatio-temporal continuity between creating an application container image and deploying the application is interrupted; instead of deploying it immediately after creation, containers are used as intermediaries to preserve it, thus enabling decoupling of the application from the underlying infrastructure
- Excellent observability: not only system-level metrics information, including application health status and other variables can also be displayed
- Environment Consistency: development, test and production environments can be guaranteed as long as the same image is used
- Cross-cloud and OS: containers can run on a variety of cloud environments and different operating systems
- Application-centric management: The abstraction level of containers rises to the application level, so they can be scheduled and allocated and managed from the logical resource level of the application
- Loosely coupled, distributed, resilient, liberating microservices: applications are broken down into smaller, independent parts that can be dynamically deployed and managed, rather than running as a whole on a large physical or virtual machine
- Resource Isolation: Predictable application performance
- Resource Utilization: high efficiency and density
2. The advantages of k8s
Containers are undoubtedly a good way to run and manage applications. In a production environment, we need to ensure that every container service is running properly, and if a container goes down, a new one needs to be restarted to replace it. What if the above operations could be automated by some system? This is where the advantages of k8s come into play. k8s provides a resilient distributed system framework that takes care of many aspects of application scaling, failover, and deployment patterns. k8s has some key features such as
-
service discovery and load balancing
k8s can expose services in a container via DNS or IP address. If a container’s traffic/requests are particularly high, k8s can actively implement load balancing to reduce the container’s traffic/requests to ensure the container’s stable operation
-
Storage Orchestration
k8s allows us to mount storage systems according to our actual needs and choices, supporting but not limited to local storage, cloud storage and other methods
-
Automatic deployment and rollback
We can use k8s to declare the desired state of a deployed container, and it can switch the actual state to the desired state at a controlled rate. For example, we can declare a desired number of containers running at 10 and k8s will automatically adjust the number of containers to that desired state; we can also use automated Kubernetes to create new containers for deployment, delete existing containers and use all their resources for the new containers
-
Automated Crate Calculation
We can specify the CPU and memory (RAM) required for each container in k8s. When a container specifies a resource request, k8s will perform intelligent scheduling based on the state of each node node and the resources required by each container to ensure maximum resource utilization
-
Self-healing
k8s automatically restarts containers that fail, replaces containers, kills containers that do not respond to ``user-defined operational status checks’’, and does not notify clients until it is ready to serve them, ensuring that client requests are not distributed to faulty containers
-
Key and Configuration Management
k8s allows us to store and manage sensitive information such as passwords, OAuth tokens and ssh keys, and we can deploy and update keys and application configurations without rebuilding the container image or exposing sensitive information such as keys in the configuration
3. What k8s is not
Officials have been emphasizing this point: k8s is not a traditional all-inclusive PaaS platform, it is designed with the idea of providing the most core base framework and necessary core functionality, while ensuring as much diversity and flexibility as possible in other options. Although operating at the container level rather than the hardware level makes k8s provide some features similar to PaaS platforms such as deployment, scaling, load balancing, etc., for many other aspects such as logging, storage, alerting, monitoring, CI/CD, etc., k8s chooses to leave the choice to the user, which is an important part of building a rich ecology of k8s.
- k8s does not limit the types of applications supported: including stateless (nginx, etc.), stateful (database, etc.) and data processing (AI, big data, deep learning, etc.) all kinds of application types, basically any application that can run in a container can run in k8s, and in fact most applications can run in a container, so most applications can run in k8s
- Not responsible for deploying source code, not building programs, no CI/CD: k8s does not cover these parts, and users can choose the right solution according to their preferences
- No application-level services: middleware, database, data storage clusters, etc. are not provided as built-in services, but they can all run well in k8s and can be exposed for use in various ways
- Does not provide solutions such as logging, monitoring and alerting, but provides some concepts and metrics data, etc. for collection and export mechanisms
- Does not provide or require a configuration language/system (e.g. jsonnet), it provides a declarative API that can be composed of any form of declarative specification
- Does not provide or employ any comprehensive machine configuration, maintenance, management or self-healing systems
- In addition, Kubernetes is not just an orchestration system; it actually eliminates the need for orchestration. The technical definition of orchestration is the execution of a defined workflow: first execution A, then execution B, then execution C. In contrast, Kubernetes contains a set of independent, composable control processes that continuously drive the current state to the desired state provided. How you get from A to C is irrelevant and does not require centralized control, which makes the system easier to use and more powerful, robust, resilient, and scalable.
4. k8s basic architecture
Let’s take a look at the official basic architecture diagram. The following diagram contains only the very basic k8s architecture components. Let’s start from here.
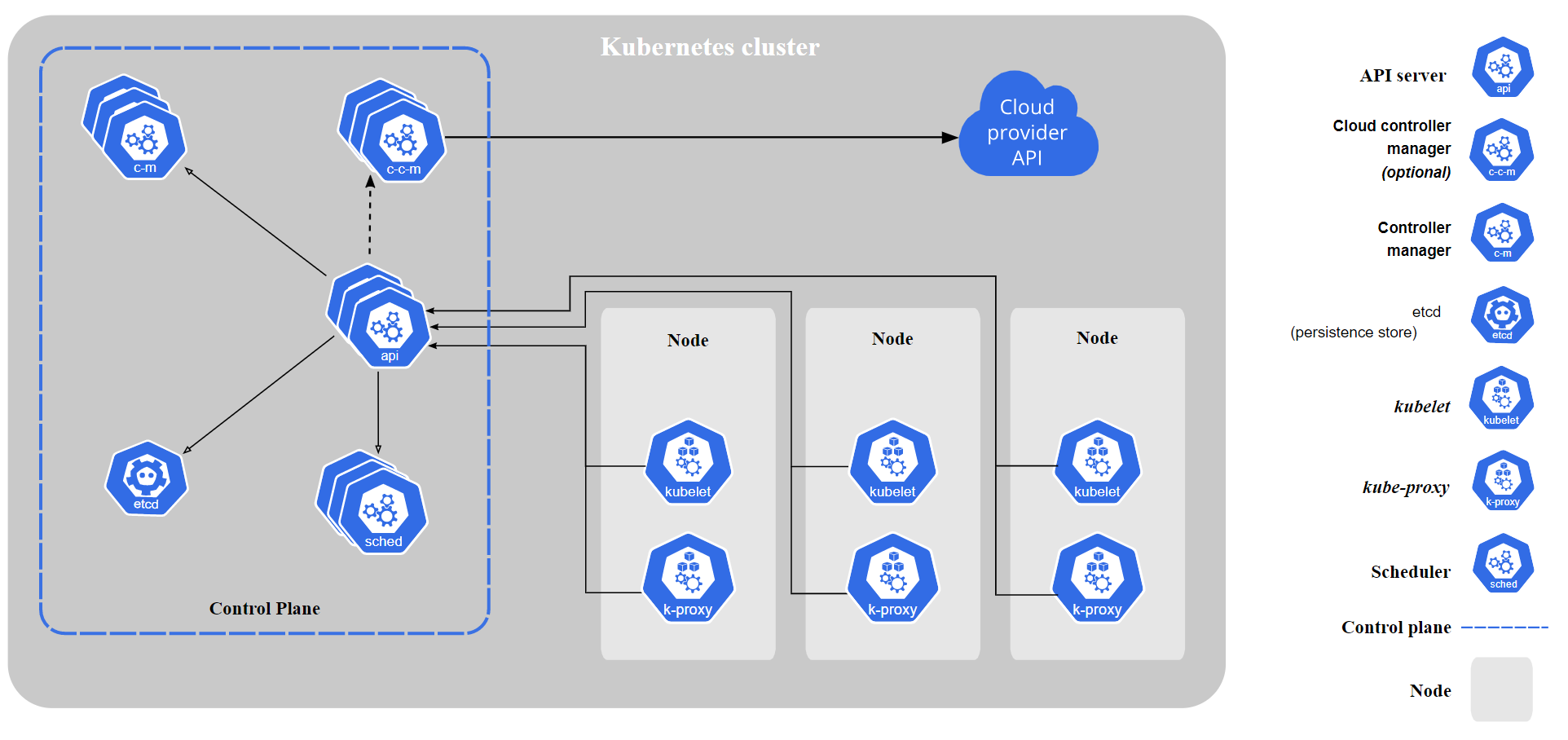
First of all, the gray area above shows a whole k8s cluster. The whole k8s architecture is actually very similar to our common master-worker model, except that it is more complex because it is a distributed cluster.
4.1 Control Plane
First we see the Control Plane in the blue box, which is the control plane of the entire cluster, equivalent to the enhanced version of the master process. k8s’s Control Plane generally runs on top of the Master node. By default, the master node does not run application workloads, all application workloads are left to the Node nodes.
The Master nodes in the Control Plane mainly run the various components of the control plane. Their main role is to maintain the normal operation of the entire k8s cluster, store cluster-related information, and provide the cluster with failover, load balancing, task scheduling, and high availability functions. For Master nodes, there are generally more than one to ensure high availability, while each component in the control plane runs in the form of a container Pod in the Master node, most of the components need to run on each Master node, and a few components such as `DNS’ services only need to ensure a sufficient number of high availability.
4.1.1 kube-apiserver
The core of the k8s cluster’s control plane is the API server, which is mainly implemented by the kube-apiserver component and is designed to be horizontally scalable, i.e., to scale by deploying different numbers of instances to accommodate different traffic flows. The kubernetes API server serves as a front-end to the entire k8s control plane, providing an HTTP API for users, different parts of the cluster and components outside the cluster to communicate with each other.
The kubernetes api is designed with REST in mind, and we can control the k8s cluster by manipulating the API through CLI tools like kubeadm or kubectl, as well as through other Web UI’s.
4.1.2 kube-scheduler
A component on the master node that monitors newly created Pods that do not have a running node assigned to them and selects nodes for Pods to run on.
Scheduling decisions take into account factors such as resource requirements for individual Pods and Pod sets, hardware/software/policy constraints, affinity and anti-affinity specifications, data location, interference between workloads, and deadlines.
4.1.3 kube-controller-manager
Runs the controller component on the master node.
Logically, each controller is a separate process, but to reduce complexity, they are all compiled into the same executable and run in a single process.
These controllers include:
- Node Controller: Responsible for notifying and responding to node failures.
- Replication Controller: Responsible for maintaining the correct number of Pods for each replica controller object in the system.
- Endpoints Controller: Populates the Endpoints object (i.e., joins Service and Pod).
- Service Account & Token Controllers: Create default accounts and API access tokens for new namespaces.
4.1.4 etcd
etcd is a consistent and highly available key-value key-value database that serves as a backend database for all Kubernetes Cluster data, and is responsible for keeping the configuration information of the Kubernetes Cluster and the status information of various resources. When data changes, etcd will quickly notify Kubernetes related components.
The etcd database of a Kubernetes cluster usually requires a backup plan. Another highly available solution for k8s cluster deployments is to pull the etcd database out of the container and deploy it as a separate highly available database, thus providing stable and reliable highly available database storage for k8s.
4.1.5 cloud-controller-manager
cloud-controller-manager only runs control loops specific to the cloud platform. If you are running Kubernetes in your own environment, or running a learning environment on your local machine, the cloud controller manager is not required in the deployed environment. So it can be understood as a cloud service vendor-specific kube-controller-manager, which is not described here.
4.1.6 DNS
Although DNS is classified as a plug-in section in the official k8s documentation, it is easy to see the importance of it from the principles of k8s, so almost all Kubernetes clusters should have cluster DNS, as many examples require DNS services.
A cluster DNS is a DNS server that works with other DNS servers in the environment and provides DNS records for Kubernetes services. containers started by Kubernetes automatically include this DNS server in their DNS search lists.
k8s uses the coreDNS component by default.
4.2 Worker Node
The concept of Worker Node is opposed to Control Plane in the front. The nodes in the cluster can basically be divided into two categories: Control Node (Control Plane/master) and Worker Node (Worker Node/worker). Generally speaking the main workload in the cluster is running on top of the Worker Node, the Master node is not involved in the workload by default, but can be manually set to allow participation in the workload.
4.2.1 Pods
Pods are the smallest unit of work in a k8s cluster. Unlike a single running container inside docker, a Pod can contain multiple containers that share the same compute, network, and storage resources (equivalent to running multiple applications on a single machine).
4.2.2 kubelet
A kubelet is an agent that runs on every node in a k8s cluster (including the master node). It ensures that containers are running in Pods. kubelet will only manage containers created by Kubernetes.
The kubelet receives a set of PodSpecs provided to it through various mechanisms and ensures that the containers described in these PodSpecs are running and healthy. When the Scheduler determines that a Pod is running on a Node, it sends the specific configuration information (image, volume, etc.) of the Pod to the kubelet on that Node. The kubelet creates and runs containers based on this information and reports the operational status to the Master.
4.2.3 kube-proxy
The kube-proxy is a network proxy running on each node in the cluster. kube-proxy implements the Kubernetes service abstraction by maintaining network rules on the host and performing connection forwarding. kube-proxy implements the Kubernetes service abstraction by maintaining network rules on the host and performing connection forwarding.
The service logically represents multiple Pods on the backend, and the outside world accesses the Pods through the service. requests received by the service are forwarded to the Pods through the kube-proxy, and the kube-proxy service is responsible for forwarding the TCP/UDP data streams from the service to the backend containers. If there are multiple replicas, kube-proxy will implement load balancing.