K8s’ cpuManager does the CPU resource allocation and isolation on the node side (core pinning and isolation, how to do isolation).
- Discovery of CPU topology on the machine
- Report available resources to K8s tier machines (including kubelet side scheduling)
- Allocate resources for workload execution
- Tracking resource allocation for pods
This article provides a general introduction to the current state and limitations of CPU management in K8s, and analyzes the current community dynamics in conjunction with community documentation.
- the status and limitations of CPU management
- related issues
- community proposals
Status and limitations of CPU management
kubelet divides the system’s cpu into 2 resource pools.
- exclusive pool: only one task can be allocated to the cpu at the same time
- shared pool: multiple processes are allocated to the cpu
The native k8s cpuManager currently only provides a static cpu allocation policy. When k8s creates a pod, the pod is classified as a QoS:
- Guaranteed
- Burstable
- BestEffort
And kubelet allows administrators to specify the reserved CPU for system processes or kube daemons (kubelet, npd) via -reserved-cpus. This reserved resource is primarily available to system processes. It can be allocated to non-Guaranteed pod containers as a shared pool. However, Guaranteed pods cannot allocate these cpus.
Currently the node side of K8s allocates the cpuset of a numa node based on the allocation policy of cpuManager and is able to do the following.
- A container is assigned to a numa node.
- Containers are assigned to a shared set of numa nodes.
cpuManager’s current limitations.
- The maximum number of numa nodes cannot be greater than 8 to prevent state explosion (state explosion).
- The policy only supports static allocation of cpuset, and will support dynamic adjustment of cpuset during the container lifecycle in the future.
- The scheduler does not sense topology information on the nodes. The corresponding proposal is described in the following section.
- For thread placement applications to prevent sharing of physical cores and neighbor interference. cpu manager is not currently supported. The corresponding proposal is described in the following section.
Related issues
-
For the heterogeneous characteristics of the processor, the user can specify the class of hardware required for the service.
https://github.com/kubernetes/kubernetes/issues/106157
The heterogeneous resources of heterogeneous computing have different performance and characteristics and multiple levels. For example, in Intel 11th gen, Performance-cores (P-cores) are high-performance cores, and Efficiency-cores (ECores) are cores with better performance-to-power ratios.
ref:https://www.intel.cn/content/www/cn/zh/gaming/resources/how-hybrid-design-works.html
This issue describes a user scenario where E-cores can be assigned to daemons or background tasks and P-cores can be assigned to more performance demanding application services. Supporting this scenario requires group allocation of CPUs. But issue specific scenarios are discussed. Because of the underlying hardware differences, it is currently not possible to achieve generalization. The current k8s layer needs to be designed to refactor the solution.
The current landing solutions for related requirements are to use extended resources on k8s to identify different heterogeneous resources. This approach generates duplicate statistics for the native cpu/memory resources.
-
topologyManager’s best-effort policy optimization
https://github.com/kubernetes/kubernetes/issues/106270
issue mentions the best-effort strategy, which iterates over each provider hint and aggregates the results based on the bits and arithmetic. If the final result is not preferred, the topologyManager should try to do the preferred choice based on the tendency of the resource. The original idea is that cpu resources are more important than the numa affinity of other peripherals. When multiple provider hints conflict with each other, if the cpu has a preferred single numa node allocation result, the cpu’s allocation result should be satisfied first. For example, the cpu returns the result [‘10’ preferred, ‘11’ non-preferred]) and a device returns the result [‘01 The topologyManager should use ‘10’ preferred as the final result, not ‘01’ not preferred after merging.
The community’s recommendation for this change in scheduling logic is to create new policies to provide an algorithmic system similar to scheduler preference (scoring).
-
Strict kubelet set-aside resources
https://github.com/kubernetes/kubernetes/issues/104147
It is desired to provide the new parameter StrictCPUReservation, indicating strictly reserved resources, and the DefaultCPUSet list will remove ReservedSystemCPUs.
-
Bug: When releasing the resources of the init container, the resources reallocated to the main container were released.
https://github.com/kubernetes/kubernetes/issues/105114
This issue has been fixed: in the RemoveContainer phase, the cpuset of the container that is still in use is excluded. the remaining cpuset can only be released back to DefaultCPUSet.
-
Support in-place vertical scaling: for pod instances that have been deployed to a node, modify the amount of resources of the pod through a resize request.
https://github.com/kubernetes/enhancements/issues/1287
In-place vertical scaling means: when the business adjusts the resources of the service, there is no need to restart the container.
In-place vertical scaling is a complex feature, here is a general introduction to the design ideas. Detailed implementation can be seen in PR: https://github.com/kubernetes/kubernetes/pull/102884.
kube-scheduler still uses the Spec…Resources.Requests of the pod for scheduling. The amount of resources already allocated to the node in the cache is determined based on the pod’s Status.Resize status.
- Status.Resize = “InProgress” or “Infeasible”, based on Status…ResourcesAllocated ( ResourcesAllocated (the value that has been allocated).
- Status.Resize = “Proposed”, based on Spec…Resources.Requests (newly modified value) and Status… ResourcesAllocated (the value already allocated, if resize is appropriate, the kubelet will also update this property with new requests), taking the maximum of the two.
The kubelet side of the core in the admit stage to determine whether the remaining resources to meet the resize, and whether the specific resize requires a container restart, based on container runtime to determine. So this resize function is actually a best-effort type. It is determined by the ResizePolicy field.

It is also worth noting that the current PR mainly supports in-place restart on kata, docker, and windows containers are not yet supported.
Interesting community proposal
Scheduler topology-aware scheduling
Redhat contributed their implementation of a set of topology-aware scheduling to the community: https://github.com/kubernetes/enhancements/pull/2787
Extend cpuManager to prevent cores from not being shared between containers
Prevent interference from virtual allocations of the same physical core.
The design document introduces a new parameter cpumanager-policy-options: full-pcpus-only, which expects the allocation to be exclusive to one physical cpu. when the full-pcpus-only parameter is specified along with the static policy, cpuManager will additionally check when allocating cpusets to ensure that the entire physical core is allocated. to ensure that the entire physical core is allocated when the cpu is allocated. This ensures that containers compete on physical cores.
For example, if a container requests 5 exclusive cores (virtual cores), cpu 0-4 are allocated to the service container. cpu 5 is also locked and cannot be allocated to a container. This is because cpu 5 and cpu 4 are on the same physical core.

Add cpuMananger cross-numa dispersion policy: distribute-cpus-across-numa
full-pcpus-only: Described above:full-pcpus-onlyensures that the physical cores of the cpu allocated to the container are exclusive .distribute-cpus-across-numa: Distribute containers evenly across numa nodes.
When distribute-cpus-across-numa is on, the statie policy allocates cpu evenly across numa nodes when containers need to be allocated across numa nodes. the default logic for non-only is to preferentially fill a numa node. prevent cross-numa node allocations from being done on the one with the least margin of numa node. In terms of overall application performance, the performance bottleneck is received by the worst performing worker (process?) on the numa node with fewer resources remaining. This option provides overall performance.
A few proposals discussed in the community slack are presented next.
- CPU Manager Plugin Model
- Node Resource Interface
- Dynamic resource allocation
CPU Manager Plugin Model
CPU Manager Plugin Model: kubelet cpuManager plug-in framework. Support different cpu allocation scenarios without changing the main resource management process. According to business needs, to achieve more fine-grained control of cpuset.
After a successful binding of pods, kubelet will press the pods into the local scheduling queue and execute the scheduling process of the pod’s cpuset in turn. The scheduling process essentially borrows from the scheduling framework of kube-scheduler.
Plugin extensibility points.
A plugin can implement 1 or more extensibility points.
- Sort: Scheduling to the node to sort the processing of pods. For example, based on the priority of pod QoS determination.
- Filter: Filter the cpu that cannot be assigned to a pod.
- PostFilter: When no suitable cpu is available, it can be pre-processed by PostFilter and then the pods will be reprocessed.
- PreScore: For a single cpu score, provided to later processes to determine the priority of the allocation mix.
- Select: Selects the optimal solution for a cpu combination based on the PreScore, which is structured as a set of cpus.
- Score: Based on the result of Select - the cpu allocation portfolio score.
- Allocate: Call this plugin after assigning cpuset.
- Deallocate: After PostFilter, release the cpu allocation.
The difference between the three scoring plugins.
- PreScore: returns the affinity of a single cpu for a pod container with cpu as key and value.
- Select: Aggregates the scores of cpu combinations based on the domain knowledge of the plugin (e.g. aggregation of cpu allocation structures for the same numa). The return is the best set of cpus.
- Score: Based on all cpu combinations, the score assignment combination is based on the plugin’s strong constraint logic.
The solution proposes two options for extending the plugin. Currently in the container management of kubelet, topologyManager mainly accomplishes the following.
- Scheduling with hintProvider to get the allocations available for each submanagement domain
- Orchestrate overall topology allocation decisions
- Providing “scopes” and policies parameters to influence the overall policy
Other submanagers of the submanagement domain (e.g. cpuManager) provide individual allocation policies as hintProvider. In the CPU Manager Plugin Model, the submanager provides the original functionality as a model plugin interface.
Option 1: Extend the submanager so that the topologyManager senses the cpuset
Go back through the current values of the numa node allocation extension to be able to target individual cpuset allocation tendencies. The extension plugin is executed in the form of hint providers and the main process does not need to be modified.
Disadvantage: Other hintProviders (allocations of other resources) do not sense cpu information, resulting in hintProvider results that do not reference cpu allocations. The final aggregated result is not necessarily the optimal solution.
Option 2: Extend cpuManager to a plug-in model
topologyManager still calls cpuManager through GetTopologyHints() and Allocate(). cpuManager internally extends the scheduling process. The specific extensions can be configured by introducing new policies, or directly extended by means of the scheduling framework.
Disadvantage: the result of cpuManager is not deterministic, topologyManager will combine with other hints to allocate.
As you can see the current proposal for the CPU Manager Plugin Model is still in a very primitive stage and is mainly being pushed by Red Hat people. It has not been fully discussed in the community.
Node Resource Interface
This solution is from containerd, and is mainly an extension of the NRI plugin in CRI.
containerd
containerd works mainly between the platform and the lower level runtime. The platform is the container platform like docker, k8s, etc. and the runtime is the underlying runtime like runc, kata, etc. containerd provides container process management, image management, file system snapshot, and metadata and dependency management in the middle. The following diagram shows an overview of the containerd architecture.
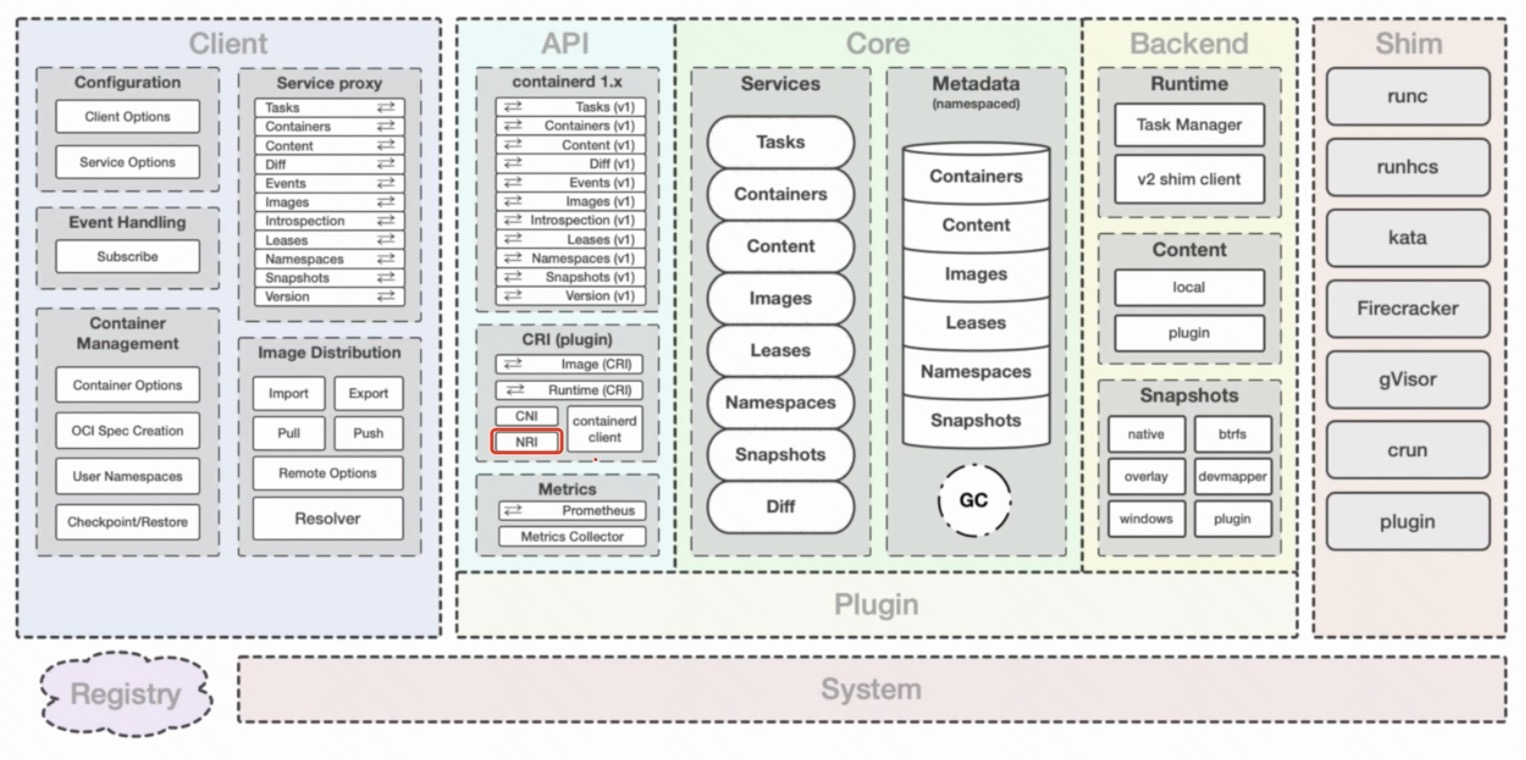
- client is the first layer of user interaction, providing the interface to the caller.
- core defines the core functional interface. All data is stored through core management (metadata store) and all other components/plugins do not need to store data.
- The runtime in backend is responsible for dealing with the underlying runtime through different shim.
- The api layer provides two main types of gRPC services: image, runtime. a variety of plugin extensions are provided.
The CRI layer contains plug-in interfaces of the CRI, CNI, and NRI types.
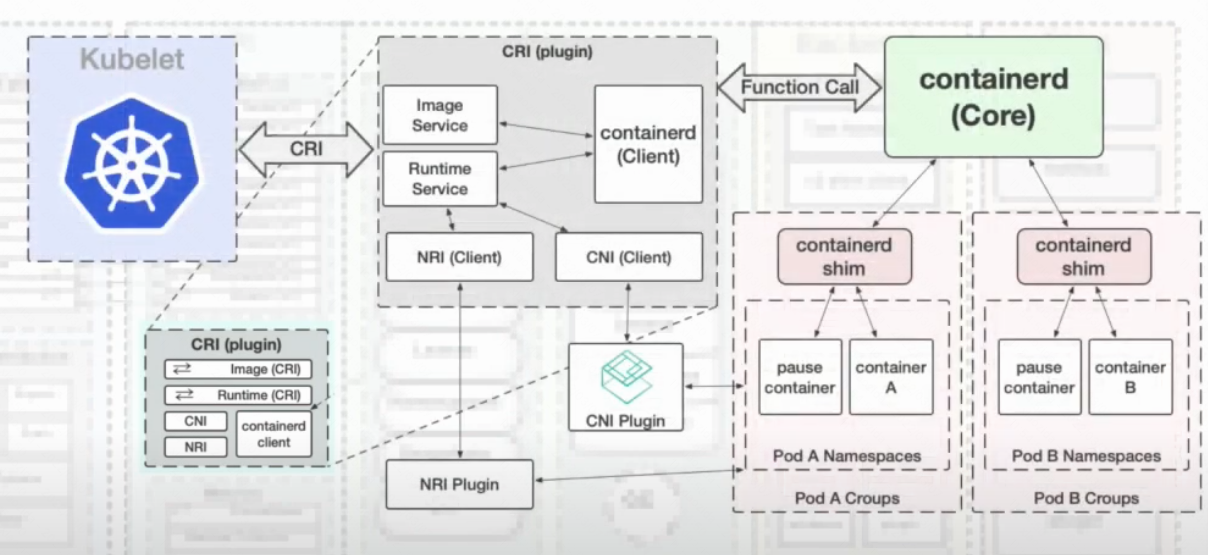
- CRI plugin: container runtime interface plugin, responsible for defining pods by sharing namespace, cgroups to all containers under pods.
- CNI plugin: container network interface plugin, configure container network. After containerd creates the first container, the network is configured through namespace.
- NRI plugin: Node Resource Interface plugin, manages cgroups and topologies.
NRI
NRI is a CRI plugin located in the containerd architecture that provides a plugin framework to manage node resources at the container runtime level.
The cni can be used to address performance issues for batch computing, latency-sensitive services, and to meet user requirements such as service SLA/SLO, prioritization, etc. For example, performance requirements by allocating the container’s cpu to the same numa node to ensure that memory calls within the numa. In addition to numa, of course, there are resource topology affinities such as CPU and L3 cache.
The current implementation of kubelet is through the cpuManager’s processing object can only be the guaranteed class of pod, topologyManager through the cpuManager provides hints to achieve resource allocation.
The kubelet is also currently not suitable for scaling to handle multiple requirements, as adding fine-grained resource allocation to the kubelet leads to an increasingly blurred boundary between the kubelet and the CRI. In contrast, the aforementioned plugins within CRI are invoked during the CRI container lifecycle and are suitable for doing resoruce pinning and topology awareness of nodes. And by doing plugin definition and iteration inside CRI, it is possible to do upper-level kubernetes to adapt changes with minimal cost.
During the container lifecycle, the CNI/NRI plugin can be injected between Create and Start of the container initialization process.
Create->NRI->Start
Take the official example clearcfs: before starting the container, the cgroup command is called based on the qos type, and cpu.cfs_quota_us is - 1 means no upper limit is set.
It can be analyzed that the NRI controls the cgroup directly, so it can have a more bottom-level resource allocation method. However, the closer to the bottom, the higher the complexity of the processing logic.
Dynamic resource allocation
This dynamic resource allocation is turned up in KEP, and the scheme provides a new set of models for managing resources and device resources in k8s. The core idea is similar to that of a storage type (storageclass), where specific device resources are declared and consumed via mounts, rather than being allocated a certain number of device resources via request/limit.
Use cases.
- device initialization: configure the device for workload. Configuration based on container requirements, but this allocation configuration should not be exposed directly to the container.
- device cleanup: clean up the device parameters/data and other information after the container is finished.
- Partial allocation: support partial allocation, a device sharing multiple containers.
- optional allocation: support for containers to declare soft (optional) resource requests. For example: GPU and crypto-offload engines device application scenarios.
- over the fabric devices: support for containers to use the resources of devices on the network.
Dynamic resource allocation is designed to provide more flexible control, user-friendly api, and resource management plug-in without the need to re-build k8s components.
Newly defined k8s resources are managed by defining a resource allocation protocol and gRPC interface for dynamic resource allocation ResourceClass and ResourceClaim.
- ResourceClass specifies the driver and driver parameters for the resource
- ResourceClaim specifies the instance of the business using the resource
Immediate and deferred allocation.
- Immediate allocation: ResourceClaims are allocated when they are created. Allocation can be used efficiently for scarce resources (allocating a resource is expensive). But there is no guarantee that the node will not be scheduled due to other resources (cpu, memory).
- Delayed allocation: allocated only when scheduling is successful. Can handle the problems caused by immediate allocation.
Calling process
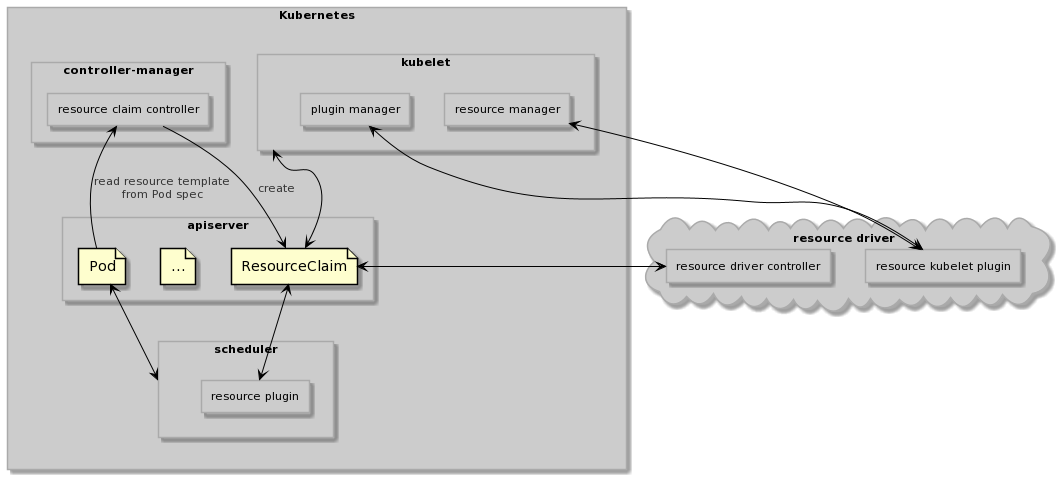
- user creates a pod with resourceClaimTemplate configuration.
- resourceClaim is created by resourceClaim controller.
- immediate allocation and delayed allocation are processed according to the spec of the resourceClaim.
- immediate allocation: the resource driver controller finds out when the resourceClaim is created and claims it.
- delayed allocation: The scheduler first processes and filters the nodes that do not meet the conditions to obtain the candidate node set. The resource driver filters once more the nodes whose candidate node set does not meet the requirements.
- When the resource driver finishes resource allocation, the scheduler sets aside resources and binds nodes.
- the kubelet on the node is responsible for pod execution and resource management (invoking the driver plugin).
- when the pod is deleted, the kubelet is responsible for stopping the pod’s container and reclaiming the resources (invoking the driver plugin).
- After pod deletion, gc is responsible for the corresponding resourceClaim deletion.
This is not specifically described in the documentation: in the immediate allocation scenario, if no scheduler works, resoruce driver controller to node selection mechanism is like.
Summary
You can see that the community will do a refactoring of kubelet container management in the future to support more complex business scenarios. The near future will land on cpu resource management with scheduler topology-aware scheduling, and custom kubelet cpu allocation policies. Among some of the above cases, the one with development potential is the NRI solution.
- Support for custom extensions, kubelet can directly load the extension configuration without modifying its own code.
- By interacting with CRI, kubelet can decentralize some of the complex cpu allocation requirements to runtime.