In Kubernetes, components such as Controller Manager, Scheduler, and user-implemented Controllers are highly available by means of multiple replicas. However, multiple replica Controllers working at the same time inevitably trigger a contention condition for the resources they are listening to, so usually only one replica is working between multiple replicas.
In order to avoid this competition, Kubernetes provides a Leader election model, where multiple replicas compete with each other for the Leader, and only the Leader will work, otherwise it will wait. In this article, we will introduce how to achieve high availability of components in Kubernetes from the principle of Leader election and how to use it as a user.
Leader election
The principle of Leader election is to use Lease, ConfigMap, and Endpoint resources to achieve optimistic locking, with Lease resources defining the Leader’s id, preemption time, and other information; ConfigMap and Endpoint defining control-plane.alpha/leader as leader in their annotation. Yes, yes, if we implement it ourselves, we can define our own favorite fields, but here we are actually using resourceVersion to implement optimistic locking.
The principle is shown in the figure below, multiple copies will compete for the same resource, and the lock will become Leader when it is captured and updated periodically; if it is not captured, it will wait in place and keep trying to capture it.
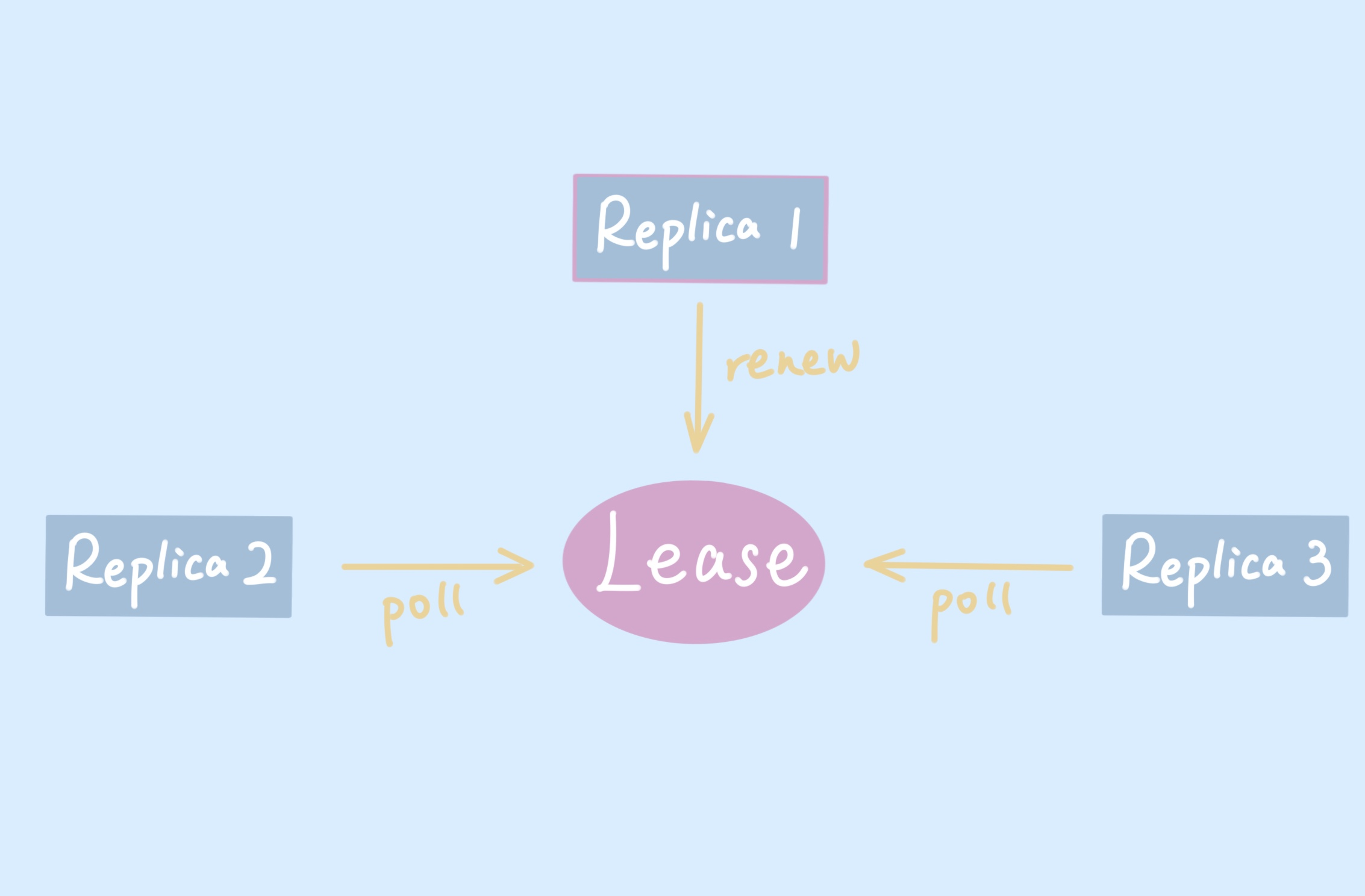
The tooling methods for locks are provided in client-go, and the k8s component is used directly through client-go. Next, we analyze how the tool methods provided by client-go implement Leader elections.
Preemption of locks
First, it will get the lock according to the defined name, and create it if there is none; then it will determine whether there is a Leader and whether the Leader’s lease expires, and seize the lock if there is none, otherwise it will return and wait.
The process of lock seizure inevitably involves the operation of updating resources, and k8s achieves the atomicity of update operation through the optimistic locking of version number. When updating a resource, ApiServer compares the resourceVersion and returns a conflict error if it is inconsistent. In this way, the security of the update operation is guaranteed.
The code for the preemption lock is as follows.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
|
func (le *LeaderElector) tryAcquireOrRenew(ctx context.Context) bool {
now := metav1.Now()
leaderElectionRecord := rl.LeaderElectionRecord{
HolderIdentity: le.config.Lock.Identity(),
LeaseDurationSeconds: int(le.config.LeaseDuration / time.Second),
RenewTime: now,
AcquireTime: now,
}
// 1. obtain or create the ElectionRecord
oldLeaderElectionRecord, oldLeaderElectionRawRecord, err := le.config.Lock.Get(ctx)
if err != nil {
if !errors.IsNotFound(err) {
klog.Errorf("error retrieving resource lock %v: %v", le.config.Lock.Describe(), err)
return false
}
if err = le.config.Lock.Create(ctx, leaderElectionRecord); err != nil {
klog.Errorf("error initially creating leader election record: %v", err)
return false
}
le.setObservedRecord(&leaderElectionRecord)
return true
}
// 2. Record obtained, check the Identity & Time
if !bytes.Equal(le.observedRawRecord, oldLeaderElectionRawRecord) {
le.setObservedRecord(oldLeaderElectionRecord)
le.observedRawRecord = oldLeaderElectionRawRecord
}
if len(oldLeaderElectionRecord.HolderIdentity) > 0 &&
le.observedTime.Add(le.config.LeaseDuration).After(now.Time) &&
!le.IsLeader() {
klog.V(4).Infof("lock is held by %v and has not yet expired", oldLeaderElectionRecord.HolderIdentity)
return false
}
// 3. We're going to try to update. The leaderElectionRecord is set to it's default
// here. Let's correct it before updating.
if le.IsLeader() {
leaderElectionRecord.AcquireTime = oldLeaderElectionRecord.AcquireTime
leaderElectionRecord.LeaderTransitions = oldLeaderElectionRecord.LeaderTransitions
} else {
leaderElectionRecord.LeaderTransitions = oldLeaderElectionRecord.LeaderTransitions + 1
}
// update the lock itself
if err = le.config.Lock.Update(ctx, leaderElectionRecord); err != nil {
klog.Errorf("Failed to update lock: %v", err)
return false
}
le.setObservedRecord(&leaderElectionRecord)
return true
}
|
The client-go repository provides an example, and after we start a process, we can see Its Lease information is as follows.
1
2
3
4
5
6
7
8
9
10
11
|
$ kubectl get lease demo -oyaml
apiVersion: coordination.k8s.io/v1
kind: Lease
metadata:
...
spec:
acquireTime: "2022-07-23T14:28:41.381108Z"
holderIdentity: "1"
leaseDurationSeconds: 60
leaseTransitions: 0
renewTime: "2022-07-23T14:28:41.397199Z"
|
Release the lock
The logic of releasing the lock is to perform an update operation to clear the leader information of the Lease before the Leader exits.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
func (le *LeaderElector) release() bool {
if !le.IsLeader() {
return true
}
now := metav1.Now()
leaderElectionRecord := rl.LeaderElectionRecord{
LeaderTransitions: le.observedRecord.LeaderTransitions,
LeaseDurationSeconds: 1,
RenewTime: now,
AcquireTime: now,
}
if err := le.config.Lock.Update(context.TODO(), leaderElectionRecord); err != nil {
klog.Errorf("Failed to release lock: %v", err)
return false
}
le.setObservedRecord(&leaderElectionRecord)
return true
}
|
After killing the process started in the previous step, look at its Lease information.
1
2
3
4
5
6
7
8
9
10
11
|
$ kubectl get lease demo -oyaml
apiVersion: coordination.k8s.io/v1
kind: Lease
metadata:
...
spec:
acquireTime: "2022-07-23T14:29:26.557658Z"
holderIdentity: ""
leaseDurationSeconds: 1
leaseTransitions: 0
renewTime: "2022-07-23T14:29:26.557658Z"
|
How to use it in Controller
When we implement our own controller, we usually use the controller runtime tool, which has already encapsulated the logic of leader election.
The main logic is in two places, one is the definition of Lease base information, according to the user’s definition to supplement the base information, such as the current running namespace as the leader’s namespace, according to the host to generate a random id, etc..
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
|
func NewResourceLock(config *rest.Config, recorderProvider recorder.Provider, options Options) (resourcelock.Interface, error) {
if options.LeaderElectionResourceLock == "" {
options.LeaderElectionResourceLock = resourcelock.LeasesResourceLock
}
// LeaderElectionID must be provided to prevent clashes
if options.LeaderElectionID == "" {
return nil, errors.New("LeaderElectionID must be configured")
}
// Default the namespace (if running in cluster)
if options.LeaderElectionNamespace == "" {
var err error
options.LeaderElectionNamespace, err = getInClusterNamespace()
if err != nil {
return nil, fmt.Errorf("unable to find leader election namespace: %w", err)
}
}
// Leader id, needs to be unique
id, err := os.Hostname()
if err != nil {
return nil, err
}
id = id + "_" + string(uuid.NewUUID())
// Construct clients for leader election
rest.AddUserAgent(config, "leader-election")
corev1Client, err := corev1client.NewForConfig(config)
if err != nil {
return nil, err
}
coordinationClient, err := coordinationv1client.NewForConfig(config)
if err != nil {
return nil, err
}
return resourcelock.New(options.LeaderElectionResourceLock,
options.LeaderElectionNamespace,
options.LeaderElectionID,
corev1Client,
coordinationClient,
resourcelock.ResourceLockConfig{
Identity: id,
EventRecorder: recorderProvider.GetEventRecorderFor(id),
})
}
|
The second is to start the leader election, register the lock information, lease time, callback function and other information, and then start the election process.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
func (cm *controllerManager) startLeaderElection(ctx context.Context) (err error) {
l, err := leaderelection.NewLeaderElector(leaderelection.LeaderElectionConfig{
Lock: cm.resourceLock,
LeaseDuration: cm.leaseDuration,
RenewDeadline: cm.renewDeadline,
RetryPeriod: cm.retryPeriod,
Callbacks: leaderelection.LeaderCallbacks{
OnStartedLeading: func(_ context.Context) {
if err := cm.startLeaderElectionRunnables(); err != nil {
cm.errChan <- err
return
}
close(cm.elected)
},
OnStoppedLeading: func() {
if cm.onStoppedLeading != nil {
cm.onStoppedLeading()
}
cm.gracefulShutdownTimeout = time.Duration(0)
cm.errChan <- errors.New("leader election lost")
},
},
ReleaseOnCancel: cm.leaderElectionReleaseOnCancel,
})
if err != nil {
return err
}
// Start the leader elector process
go func() {
l.Run(ctx)
<-ctx.Done()
close(cm.leaderElectionStopped)
}()
return nil
}
|
With the controller runtime wrapping the election logic, it is much easier to use. We can define the Lease information when we initialize the controller.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
scheme := runtime.NewScheme()
_ = corev1.AddToScheme(scheme)
// 1. init Manager
mgr, _ := ctrl.NewManager(ctrl.GetConfigOrDie(), ctrl.Options{
Scheme: scheme,
Port: 9443,
LeaderElection: true,
LeaderElectionID: "demo.xxx",
})
// 2. init Reconciler(Controller)
_ = ctrl.NewControllerManagedBy(mgr).
For(&corev1.Pod{}).
Complete(&ApplicationReconciler{})
...
|
Just initialize it with LeaderElection: true and LeaderElectionID, the name of the Lease, to make sure it is unique within the cluster. The rest of the information controller runtime will fill in for you.