This article will explain in depth how to extend the Kubernetes scheduler with each extension point, and the principles of extending the scheduler, which are required as knowledge points for extending the scheduler. Finally, an experiment will be done to record the scheduler for network traffic.
kubernetes scheduling configuration
Multiple different schedulers are allowed to run in a kubernetes cluster, and it is also possible to specify different schedulers for Pods to be scheduled. This is not mentioned in the general Kubernetes scheduling tutorials, which means that the kubernetes scheduling feature is not actually fully used for affinity, taint, and other policies. Some of the scheduling plugins mentioned in previous articles, such as port-occupancy based scheduling NodePorts and other policies are generally not used, and this section is about This section explains this part, which is also used as a basis for extending the scheduler.
Scheduler Configuration
kube-scheduler provides the resource of a configuration file as a configuration file for kube-scheduler, which is specified at startup with --config=. The KubeSchedulerConfiguration currently used in each kubernetes version is.
- Versions prior to 1.21 use
v1beta1
- 1.22 versions use
v1beta2, but keep v1beta1
- 1.23, 1.24, 1.25 versions use
v1beta3, but keep v1beta2 and remove v1beta1
Here is a simple kubeSchedulerConfiguration example, where kubeconfig has the same effect as the startup parameter -kubeconfig. And kubeSchedulerConfiguration is similar to the configuration files of other components, such as kubeletConfiguration which are used as service startup configuration files.
1
2
3
4
|
apiVersion: kubescheduler.config.k8s.io/v1beta1
kind: KubeSchedulerConfiguration
clientConnection:
kubeconfig: /etc/srv/kubernetes/kube-scheduler/kubeconfig
|
Notes: -kubeconfig and -config cannot be specified at the same time, if -config is specified, the other parameters will be invalid.
kubeSchedulerConfiguration Usage
The configuration file allows the user to customize multiple schedulers, as well as configure extension points for each stage. And it is through these extension points that the plugin provides the scheduling behavior in the whole scheduling context.
The following configuration is an example of the section on configuring extension points, which can be explained in the scheduling context section of the official kubernetes documentation.
1
2
3
4
5
6
7
8
9
10
11
12
|
apiVersion: kubescheduler.config.k8s.io/v1beta1
kind: KubeSchedulerConfiguration
profiles:
- plugins:
score:
disabled:
- name: PodTopologySpread
enabled:
- name: MyCustomPluginA
weight: 2
- name: MyCustomPluginB
weight: 1
|
Notes: If name="*", in this case all plugins corresponding to the extension point will be disabled/enabled
Since kubernetes provides multiple schedulers, it is natural for profiles to support multiple profiles, and profiles are also in the form of lists, so just specify multiple configuration lists. Here is an example of multiple profiles, where multiple extension points can also be configured for each scheduler if they exist.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
apiVersion: kubescheduler.config.k8s.io/v1beta2
kind: KubeSchedulerConfiguration
profiles:
- schedulerName: default-scheduler
plugins:
preScore:
disabled:
- name: '*'
score:
disabled:
- name: '*'
- schedulerName: no-scoring-scheduler
plugins:
preScore:
disabled:
- name: '*'
score:
disabled:
- name: '*'
|
scheduler scheduling plugins
kube-scheduler provides a number of plugins as scheduling methods by default, which are enabled by default without configuration, such as
- ImageLocality: scheduling will be more biased towards the node where the container image exists for the Node. Extension point:
score.
- TaintToleration: enables taint and tolerance functions. Extension points:
filter, preScore, score.
- NodeName: implementation of
NodeName, the simplest scheduling method in the scheduling policy. Extension point: filter.
- NodePorts: scheduling will check if the Node port is occupied. Extensions:
preFilter, filter.
- NodeAffinity: provides node affinity related functions. Extensions:
filter, score.
- PodTopologySpread: implements Pod topology domain functionality. Extensions:
preFilter, filter, preScore, score.
- NodeResourcesFit: This plugin will check if the node has all the resources requested by the Pod. Use one of the following three policies:
LeastAllocated (default) MostAllocated and RequestedToCapacityRatio. Extension points: preFilter, filter, score.
- VolumeBinding: Check if the node has or can bind the requested volume. Extension points:
preFilter, filter, reserve, preBind, score.
- VolumeRestrictions: Checks if the volumes installed in the node meet the limits specific to the volume provider. Extension point:
filter.
- VolumeZone: Checks if the requested volumes meet any zone requirements they may have. Extension point:
filter.
- InterPodAffinity: Implements inter-Pod affinity and anti-affinity functionality. Extension points:
preFilter, filter, preScore, score.
- PrioritySort: Provides sorting based on default priority. Extension point:
queueSort.
For more profile use cases you can refer to the official documentation given
How to extend kube-scheduler
When first thinking about writing a scheduler, it’s common to think that extending kube-scheduler is a very difficult task, something that kubernetes has officially thought about for a long time. kubernetes introduced the concept of frameworks in version 1.15 to make scheduler more scalable.
The framework works by redefining each extension point to be used as plugins and supporting users to register out of tree extensions so that they can be registered to kube-scheduler, and these steps are analyzed below.
Defining the entry point
The scheduler allows for customization, but for that you only need to reference the corresponding NewSchedulerCommand and implement the logic of your own plugins.
1
2
3
4
5
6
7
8
9
10
11
12
13
|
import (
scheduler "k8s.io/kubernetes/cmd/kube-scheduler/app"
)
func main() {
command := scheduler.NewSchedulerCommand(
scheduler.WithPlugin("example-plugin1", ExamplePlugin1),
scheduler.WithPlugin("example-plugin2", ExamplePlugin2))
if err := command.Execute(); err != nil {
fmt.Fprintf(os.Stderr, "%v\n", err)
os.Exit(1)
}
}
|
The NewSchedulerCommand allows injecting out of tree plugins, i.e. injecting external custom plugins, in which case there is no need to define a scheduler by modifying the source code, but simply by implementing a custom scheduler by itself.
1
2
3
4
5
6
|
// WithPlugin is used to inject out of tree plugins so there is no reference to it in the scheduler code.
func WithPlugin(name string, factory runtime.PluginFactory) Option {
return func(registry runtime.Registry) error {
return registry.Register(name, factory)
}
}
|
Plugin implementation
For the plug-in implementation just need to implement the corresponding extension point interface. The following is an analysis of the built-in plug-ins
For the built-in plug-in NodeAffinity, we can see by looking at its structure that the implementation of the plug-in is to implement the corresponding extension point abstraction interface can be.
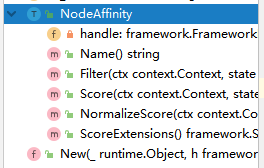
defines the plugin structure
where framework.FrameworkHandle is provided for calls between the Kubernetes API and scheduler, as you can see by the structure contains lister, informer, etc. This parameter is also required to be implemented.
1
2
3
|
type NodeAffinity struct {
handle framework.FrameworkHandle
}
|
implements the corresponding extension points
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
func (pl *NodeAffinity) Score(ctx context.Context, state *framework.CycleState, pod *v1.Pod, nodeName string) (int64, *framework.Status) {
nodeInfo, err := pl.handle.SnapshotSharedLister().NodeInfos().Get(nodeName)
if err != nil {
return 0, framework.NewStatus(framework.Error, fmt.Sprintf("getting node %q from Snapshot: %v", nodeName, err))
}
node := nodeInfo.Node()
if node == nil {
return 0, framework.NewStatus(framework.Error, fmt.Sprintf("getting node %q from Snapshot: %v", nodeName, err))
}
affinity := pod.Spec.Affinity
var count int64
// A nil element of PreferredDuringSchedulingIgnoredDuringExecution matches no objects.
// An element of PreferredDuringSchedulingIgnoredDuringExecution that refers to an
// empty PreferredSchedulingTerm matches all objects.
if affinity != nil && affinity.NodeAffinity != nil && affinity.NodeAffinity.PreferredDuringSchedulingIgnoredDuringExecution != nil {
// Match PreferredDuringSchedulingIgnoredDuringExecution term by term.
for i := range affinity.NodeAffinity.PreferredDuringSchedulingIgnoredDuringExecution {
preferredSchedulingTerm := &affinity.NodeAffinity.PreferredDuringSchedulingIgnoredDuringExecution[i]
if preferredSchedulingTerm.Weight == 0 {
continue
}
// TODO: Avoid computing it for all nodes if this becomes a performance problem.
nodeSelector, err := v1helper.NodeSelectorRequirementsAsSelector(preferredSchedulingTerm.Preference.MatchExpressions)
if err != nil {
return 0, framework.NewStatus(framework.Error, err.Error())
}
if nodeSelector.Matches(labels.Set(node.Labels)) {
count += int64(preferredSchedulingTerm.Weight)
}
}
}
return count, nil
}
|
Finally, after implementing a New function to provide a way to register this extension. This New function can be injected into scheduler as out of tree plugins in main.go.
1
2
3
4
|
// New initializes a new plugin and returns it.
func New(_ runtime.Object, h framework.FrameworkHandle) (framework.Plugin, error) {
return &NodeAffinity{handle: h}, nil
}
|
Experiment: Network Traffic Based Scheduling
Having read above about how to extend the scheduler plug-in, the following experiment will complete a traffic-based scheduling, usually the network traffic used by a Node over a period of time is also used as a very common situation in production environments. For example, in multiple hosts with balanced configurations, Host A runs as a script that pulls transaction data and Host B runs as an ordinary service. Because pulling transaction data requires downloading a large amount of data while the hardware resources are occupied by very little, at this time, if a Pod is dispatched to this node, then both sides’ business may be affected (the front-end agent feels that this node with few connections will be dispatched in large numbers, while the script pulling transaction data reduces its effectiveness because of the network bandwidth occupation).
Experimental environment
- A kubernetes cluster, with at least two nodes guaranteed.
- The provided kubernetes clusters all need to have prometheus node_exporter installed, either inside or outside the cluster, and the one used here is the one outside the cluster.
- Knowledge of promQL and client_golang
The experiment is roughly divided into the following steps.
- Define the plugin API
- Plugin named
NetworkTraffic
- Define extension points
- The Score extension is used here, and the algorithm for scoring is defined
- Define how to get the score (get the corresponding data from the prometheus metrics)
- Define parameter incoming for custom scheduler
- Deploy the project to the cluster (in-cluster deployment vs. out-of-cluster deployment)
- Validation of the results of the experiments
The experiment will be modeled after the built-in plugin nodeaffinity to complete the code, why choose this plugin, just because it is relatively simple and basically the same as our experimental purpose, in fact, other plugins are also the same effect.
The code for the whole experiment is uploaded to github.com/CylonChau/customScheduler.
Start of the experiment
error handling
When initializing the project, go mod tidy and other operations, you will encounter a large number of the following errors
1
2
|
go: github.com/GoogleCloudPlatform/spark-on-k8s-operator@v0.0.0-20210307184338-1947244ce5f4 requires
k8s.io/apiextensions-apiserver@v0.0.0: reading k8s.io/apiextensions-apiserver/go.mod at revision v0.0.0: unknown revision v0.0.0
|
The problem is mentioned in kubernetes issue #79384, but a cursory glance at it does not explain why the problem occurs, and at the bottom there is a script provided by a person who runs it directly when the above problem cannot be solved.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
#!/bin/sh
set -euo pipefail
VERSION=${1#"v"}
if [ -z "$VERSION" ]; then
echo "Must specify version!"
exit 1
fi
MODS=($(
curl -sS https://raw.githubusercontent.com/kubernetes/kubernetes/v${VERSION}/go.mod |
sed -n 's|.*k8s.io/\(.*\) => ./staging/src/k8s.io/.*|k8s.io/\1|p'
))
for MOD in "${MODS[@]}"; do
V=$(
go mod download -json "${MOD}@kubernetes-${VERSION}" |
sed -n 's|.*"Version": "\(.*\)".*|\1|p'
)
go mod edit "-replace=${MOD}=${MOD}@${V}"
done
go get "k8s.io/kubernetes@v${VERSION}"
|
Defining the plugin API
The above description shows that defining a plugin only requires the implementation of the corresponding extension point abstraction interface, then you can initialize the project directory pkg/networtraffic/networktraffice.go.
Define the plugin name and variables.
1
2
|
const Name = "NetworkTraffic"
var _ = framework.ScorePlugin(&NetworkTraffic{})
|
Define the structure of the plug-in.
1
2
3
4
5
6
7
8
|
type NetworkTraffic struct {
// This is used later to get the node network traffic
prometheus *PrometheusHandle
// FrameworkHandle provides the data and some tools that the plugin can use.
// It is passed to the plugin factory class when the plugin is initialized.
// The plugin must store and use this handle to call framework functions.
handle framework.FrameworkHandle
}
|
Defining Extensions
Since the Score extension point is chosen, you need to define the corresponding method to implement the corresponding abstraction.
1
2
3
4
5
6
7
8
9
10
|
func (n *NetworkTraffic) Score(ctx context.Context, state *framework.CycleState, p *corev1.Pod, nodeName string) (int64, *framework.Status) {
// Get the network usage of the node over time via promethes
nodeBandwidth, err := n.prometheus.GetGauge(nodeName)
if err != nil {
return 0, framework.NewStatus(framework.Error, fmt.Sprintf("error getting node bandwidth measure: %s", err))
}
bandWidth := int64(nodeBandwidth.Value)
klog.Infof("[NetworkTraffic] node '%s' bandwidth: %s", nodeName, bandWidth)
return bandWidth, nil // Just return directly here
}
|
The next step is to normalize the result, which brings us back to the execution of the extension point in the scheduling framework. As you can see from the source code, the Score extension point needs to implement more than just this single method.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
// Run NormalizeScore method for each ScorePlugin in parallel.
parallelize.Until(ctx, len(f.scorePlugins), func(index int) {
pl := f.scorePlugins[index]
nodeScoreList := pluginToNodeScores[pl.Name()]
if pl.ScoreExtensions() == nil {
return
}
status := f.runScoreExtension(ctx, pl, state, pod, nodeScoreList)
if !status.IsSuccess() {
err := fmt.Errorf("normalize score plugin %q failed with error %v", pl.Name(), status.Message())
errCh.SendErrorWithCancel(err, cancel)
return
}
})
|
The above code shows that to implement Score you must implement ScoreExtensions, or return it directly if you don’t. And according to the example in nodeaffinity, this method only returns the extension object itself, while the specific normalization, that is, the actual scoring operation, is in NormalizeScore.
1
2
3
4
5
6
7
8
9
|
// NormalizeScore invoked after scoring all nodes.
func (pl *NodeAffinity) NormalizeScore(ctx context.Context, state *framework.CycleState, pod *v1.Pod, scores framework.NodeScoreList) *framework.Status {
return pluginhelper.DefaultNormalizeScore(framework.MaxNodeScore, false, scores)
}
// ScoreExtensions of the Score plugin.
func (pl *NodeAffinity) ScoreExtensions() framework.ScoreExtensions {
return pl
}
|
And in the scheduling framework, the method that actually performs the operation is also NormalizeScore().
1
2
3
4
5
6
7
8
9
|
func (f *frameworkImpl) runScoreExtension(ctx context.Context, pl framework.ScorePlugin, state *framework.CycleState, pod *v1.Pod, nodeScoreList framework.NodeScoreList) *framework.Status {
if !state.ShouldRecordPluginMetrics() {
return pl.ScoreExtensions().NormalizeScore(ctx, state, pod, nodeScoreList)
}
startTime := time.Now()
status := pl.ScoreExtensions().NormalizeScore(ctx, state, pod, nodeScoreList)
f.metricsRecorder.observePluginDurationAsync(scoreExtensionNormalize, pl.Name(), status, metrics.SinceInSeconds(startTime))
return status
}
|
Here is the implementation of the corresponding method
In NormalizeScore need to implement a specific algorithm for selecting node, because the interval of scoring results for node is $[0,100]$, so the formula of the algorithm implemented here will be $Maximum Score - (Current Bandwidth / Maximum Maximum Bandwidth ∗ 100)$, so as to ensure that, the larger the bandwidth occupation of the machine, the lower the score.
For example, if the maximum bandwidth is 200000 and the current Node bandwidth is 140,000, then this Node score is: $max - \frac{140000}{200000}\times 100 = 100 - (0.7\times100)=30$
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
// If you return framework.ScoreExtensions, you need to implement framework.
func (n *NetworkTraffic) ScoreExtensions() framework.ScoreExtensions {
return n
}
// NormalizeScore and ScoreExtensions are fixed format
func (n *NetworkTraffic) NormalizeScore(ctx context.Context, state *framework.CycleState, pod *corev1.Pod, scores framework.NodeScoreList) *framework.Status {
var higherScore int64
for _, node := range scores {
if higherScore < node.Score {
higherScore = node.Score
}
}
// The formula is calculated as, full score - (current bandwidth / highest maximum bandwidth * 100)
// The result of the formula is that the larger the bandwidth consumption of the machine, the lower the score
for i, node := range scores {
scores[i].Score = framework.MaxNodeScore - (node.Score * 100 / higherScore)
klog.Infof("[NetworkTraffic] Nodes final score: %v", scores)
}
klog.Infof("[NetworkTraffic] Nodes final score: %v", scores)
return nil
}
|
Notes: The maximum number of nodes in kubernetes supports 5000, so wouldn’t the loop take up a lot of performance when getting the maximum score, but there is no need to worry. scheduler provides a parameter percentageOfNodesToScore . This parameter determines the number of this deployment loop. More details can be found in the official documentation for this section.
In order for the plugin to be used when registering, you also need to configure a name for it.
1
2
3
4
|
// Name returns name of the plugin. It is used in logs, etc.
func (n *NetworkTraffic) Name() string {
return Name
}
|
defines the parameters to be passed in
There is also a prometheusHandle in the network plugin extension, this is the action that operates the prometheus-server to get the indicator.
First you need to define a PrometheusHandle structure.
1
2
3
4
5
6
|
type PrometheusHandle struct {
deviceName string // Network Interface Name
timeRange time.Duration // Time period for crawling
ip string // The address of the prometheus server connection
client v1.API // Operating the prometheus client
}
|
With the structure comes the need for query actions and metrics, and for metrics, node_network_receive_bytes_total is used here as the calculation to get the network traffic of the Node. Since the environment is deployed outside the cluster, there is no hostname of the node, and it is obtained through promQL, the whole statement is as follows.
1
|
sum_over_time(node_network_receive_bytes_total{device="eth0"}[1s]) * on(instance) group_left(nodename) (node_uname_info{nodename="node01"})
|
The entire Prometheus section is as follows.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
type PrometheusHandle struct {
deviceName string
timeRange time.Duration
ip string
client v1.API
}
func NewProme(ip, deviceName string, timeRace time.Duration) *PrometheusHandle {
client, err := api.NewClient(api.Config{Address: ip})
if err != nil {
klog.Fatalf("[NetworkTraffic] FatalError creating prometheus client: %s", err.Error())
}
return &PrometheusHandle{
deviceName: deviceName,
ip: ip,
timeRange: timeRace,
client: v1.NewAPI(client),
}
}
func (p *PrometheusHandle) GetGauge(node string) (*model.Sample, error) {
value, err := p.query(fmt.Sprintf(nodeMeasureQueryTemplate, node, p.deviceName, p.timeRange))
fmt.Println(fmt.Sprintf(nodeMeasureQueryTemplate, p.deviceName, p.timeRange, node))
if err != nil {
return nil, fmt.Errorf("[NetworkTraffic] Error querying prometheus: %w", err)
}
nodeMeasure := value.(model.Vector)
if len(nodeMeasure) != 1 {
return nil, fmt.Errorf("[NetworkTraffic] Invalid response, expected 1 value, got %d", len(nodeMeasure))
}
return nodeMeasure[0], nil
}
func (p *PrometheusHandle) query(promQL string) (model.Value, error) {
// 通过promQL查询并返回结果
results, warnings, err := p.client.Query(context.Background(), promQL, time.Now())
if len(warnings) > 0 {
klog.Warningf("[NetworkTraffic Plugin] Warnings: %v\n", warnings)
}
return results, err
}
|
Parameters for configuring the scheduler
Since it is necessary to specify the address of prometheus, the name of the NIC, and the size of the data to be fetched, the whole structure is as follows; in addition, the parameter structure must follow the <Plugin Name>Args format of the name.
1
2
3
4
5
|
type NetworkTrafficArgs struct {
IP string `json:"ip"`
DeviceName string `json:"deviceName"`
TimeRange int `json:"timeRange"`
}
|
In order to make this type of data available as a structure that KubeSchedulerConfiguration can resolve, there is one more step that needs to be done, which is to extend the corresponding resource type when extending the APIServer. There are two ways to extend the resource type of KubeSchedulerConfiguration in kubernetes.
One is the old version that provides framework.DecodeInto function to do this.
1
2
3
4
5
6
7
|
func New(plArgs *runtime.Unknown, handle framework.FrameworkHandle) (framework.Plugin, error) {
args := Args{}
if err := framework.DecodeInto(plArgs, &args); err != nil {
return nil, err
}
...
}
|
Another way is to have to implement the corresponding deep copy method, such as NodeLabelArgs in NodeLabel.
Finally register it to register, the whole behavior is similar to extending APIServer.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
// addKnownTypes registers known types to the given scheme
func addKnownTypes(scheme *runtime.Scheme) error {
scheme.AddKnownTypes(SchemeGroupVersion,
&KubeSchedulerConfiguration{},
&Policy{},
&InterPodAffinityArgs{},
&NodeLabelArgs{},
&NodeResourcesFitArgs{},
&PodTopologySpreadArgs{},
&RequestedToCapacityRatioArgs{},
&ServiceAffinityArgs{},
&VolumeBindingArgs{},
&NodeResourcesLeastAllocatedArgs{},
&NodeResourcesMostAllocatedArgs{},
)
scheme.AddKnownTypes(schema.GroupVersion{Group: "", Version: runtime.APIVersionInternal}, &Policy{})
return nil
}
|
Notes: For generating deep copy functions and other files, you can use the script kubernetes/hack/update-codegen.sh in the kubernetes codebase.
The framework.DecodeInto method is used here for convenience.
project deployment
Preparing the scheduler’s profile, you can see that the parameters that we customized can then be recognized as the KubeSchedulerConfiguration resource type.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
apiVersion: kubescheduler.config.k8s.io/v1beta1
kind: KubeSchedulerConfiguration
clientConnection:
kubeconfig: /mnt/d/src/go_work/customScheduler/scheduler.conf
profiles:
- schedulerName: custom-scheduler
plugins:
score:
enabled:
- name: "NetworkTraffic"
disabled:
- name: "*"
pluginConfig:
- name: "NetworkTraffic"
args:
ip: "http://10.0.0.4:9090"
deviceName: "eth0"
timeRange: 60
|
If it needs to be deployed inside a cluster, it can be built as an IMAGE.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
FROM golang:alpine AS builder
MAINTAINER cylon
WORKDIR /scheduler
COPY ./ /scheduler
ENV GOPROXY https://goproxy.cn,direct
RUN \
sed -i 's/dl-cdn.alpinelinux.org/mirrors.ustc.edu.cn/g' /etc/apk/repositories && \
apk add upx && \
GOOS=linux GOARCH=amd64 CGO_ENABLED=0 go build -ldflags "-s -w" -o scheduler main.go && \
upx -1 scheduler && \
chmod +x scheduler
FROM alpine AS runner
WORKDIR /go/scheduler
COPY --from=builder /scheduler/scheduler .
COPY --from=builder /scheduler/scheduler.yaml /etc/
VOLUME ["./scheduler"]
|
List of resources required to deploy inside the cluster.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
|
apiVersion: v1
kind: ServiceAccount
metadata:
name: scheduler-sa
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: scheduler
subjects:
- kind: ServiceAccount
name: scheduler-sa
namespace: kube-system
roleRef:
kind: ClusterRole
name: system:kube-scheduler
apiGroup: rbac.authorization.k8s.io
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: custom-scheduler
namespace: kube-system
labels:
component: custom-scheduler
spec:
selector:
matchLabels:
component: custom-scheduler
template:
metadata:
labels:
component: custom-scheduler
spec:
serviceAccountName: scheduler-sa
priorityClassName: system-cluster-critical
containers:
- name: scheduler
image: cylonchau/custom-scheduler:v0.0.1
imagePullPolicy: IfNotPresent
command:
- ./scheduler
- --config=/etc/scheduler.yaml
- --v=3
livenessProbe:
httpGet:
path: /healthz
port: 10251
initialDelaySeconds: 15
readinessProbe:
httpGet:
path: /healthz
port: 10251
|
Start the custom scheduler, here via a simple binary, so a kubeconfig is needed for the authentication file.
1
2
3
4
5
|
./main --logtostderr=true \
--address=127.0.0.1 \
--v=3 \
--config=`pwd`/scheduler.yaml \
--kubeconfig=`pwd`/scheduler.conf
|
After startup, the original kube-scheduler service is shut down to verify convenience, as the original kube-scheduler is already acting as the master in HA, so no custom scheduler will be used to cause a pod pending.
Verify the results
Prepare a Pod to be deployed, specifying the name of the scheduler to be used.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
replicas: 2
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
schedulerName: custom-scheduler
|
The experimental environment here is a 2-node kubernetes cluster, master and node01, because master has more services than node01, and in this case the scheduling result will always be scheduled to node01 no matter what.
1
2
3
4
|
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-deployment-69f76b454c-lpwbl 1/1 Running 0 43s 192.168.0.17 node01 <none> <none>
nginx-deployment-69f76b454c-vsb7k 1/1 Running 0 43s 192.168.0.16 node01 <none> <none>
|
And the log of the scheduler is as follows.
1
2
3
4
5
6
7
8
9
10
11
|
I0808 01:56:31.098189 27131 networktraffic.go:83] [NetworkTraffic] node 'node01' bandwidth: %!s(int64=12541068340)
I0808 01:56:31.098461 27131 networktraffic.go:70] [NetworkTraffic] Nodes final score: [{master-machine 0} {node01 12541068340}]
I0808 01:56:31.098651 27131 networktraffic.go:70] [NetworkTraffic] Nodes final score: [{master-machine 0} {node01 71}]
I0808 01:56:31.098911 27131 networktraffic.go:73] [NetworkTraffic] Nodes final score: [{master-machine 0} {node01 71}]
I0808 01:56:31.099275 27131 default_binder.go:51] Attempting to bind default/nginx-deployment-69f76b454c-vsb7k to node01
I0808 01:56:31.101414 27131 eventhandlers.go:225] add event for scheduled pod default/nginx-deployment-69f76b454c-lpwbl
I0808 01:56:31.101414 27131 eventhandlers.go:205] delete event for unscheduled pod default/nginx-deployment-69f76b454c-lpwbl
I0808 01:56:31.103604 27131 scheduler.go:609] "Successfully bound pod to node" pod="default/nginx-deployment-69f76b454c-lpwbl" node="no
de01" evaluatedNodes=2 feasibleNodes=2
I0808 01:56:31.104540 27131 scheduler.go:609] "Successfully bound pod to node" pod="default/nginx-deployment-69f76b454c-vsb7k" node="no
de01" evaluatedNodes=2 feasibleNodes=2
|